Shell 编程基础知识总结
Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
版本说明
本文示例适用于 bash 4.0+ 版本。不同版本的 bash 在某些特性上可能有差异,特别是:
- 数组:bash 2.0+ 支持,纯 POSIX sh(如 dash)不支持。
- 某些字符串操作:如
${var:offset:length}在较旧版本可能不支持。 - 算术扩展
$((...)):bash 2.0+ 支持。
检查你的 bash 版本:
bash --version
# 或
echo $BASH_VERSION走进 Shell 编程的大门
为什么要学 Shell?
学一个东西,我们大部分情况都是往实用性方向着想。从工作角度来讲,学习 Shell 是为了提高我们自己工作效率,提高产出,让我们在更少的时间完成更多的事情。
很多人会说 Shell 编程属于运维方面的知识了,应该是运维人员来做,我们做后端开发的没必要学。我觉得这种说法大错特错,相比于专门做 Linux 运维的人员来说,我们对 Shell 编程掌握程度的要求要比他们低,但是 Shell 编程也是我们必须要掌握的!
目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
两者之间,Shell 几乎是 IT 企业必须使用的运维自动化编程语言,特别是在运维工作中的服务监控、业务快速部署、服务启动停止、数据备份及处理、日志分析等环节里,Shell 是不可缺的。Python 更适合处理复杂的业务逻辑,以及开发复杂的运维软件工具,实现通过 web 访问等。Shell 是一个命令解释器,解释执行用户所输入的命令和程序。一输入命令,就立即回应的交互的对话方式。
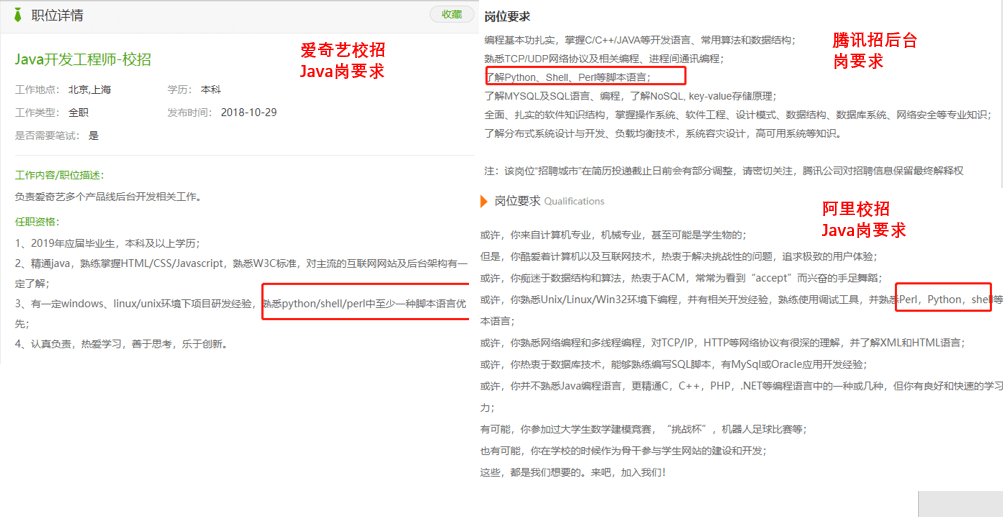
另外,了解 Shell 编程也是大部分互联网公司招聘后端开发人员的要求。下图是我截取的一些知名互联网公司对于 Shell 编程的要求。
什么是 Shell?
Shell 是 Linux/Unix 系统的命令解释器,它充当用户和操作系统内核之间的桥梁,负责接收用户输入的命令并调用相应的程序。
Shell 编程是通过 Shell 解释器(如 bash)将命令、控制结构(if/for/while)、变量和函数组合成自动化脚本的过程。Shell 既是命令解释器,也是一门完整的编程语言(支持变量、数组、函数、流程控制、管道、重定向等)。
常见的 Shell 类型:
- bash(Bourne Again Shell):Linux 系统默认 Shell,最常用。
- sh(Bourne Shell):Unix 传统 Shell,POSIX 标准。
- zsh:功能强大的交互式 Shell。
- dash:轻量级 Shell,Ubuntu 的 /bin/sh 默认指向它。
- csh/tcsh:C 风格的 Shell。
Shell 编程的 Hello World
学习任何一门编程语言第一件事就是输出 HelloWorld 了!下面我会从新建文件到 Shell 代码编写来说下 Shell 编程如何输出 Hello World。
(1)新建一个文件 helloworld.sh:touch helloworld.sh,扩展名为 sh(sh 代表 Shell)(扩展名并不影响脚本执行,见名知意就好,如果你用 php 写 Shell 脚本,扩展名就用 php 好了)。
(2)使脚本具有执行权限:chmod +x helloworld.sh
(3)使用 vim 命令修改 helloworld.sh 文件:vim helloworld.sh(vim 文件------>进入文件----->命令模式------>按 i 进入编辑模式----->编辑文件------->按 Esc 进入底行模式----->输入:wq/q!(输入 wq 代表写入内容并退出,即保存;输入 q! 代表强制退出不保存。))
helloworld.sh 内容如下:
#!/bin/bash
set -euo pipefail # 严格模式:遇错退出、未定义变量报错、管道失败报错
# 第一个 shell 小程序,echo 是 Linux 中的输出命令
echo "helloworld!"Shell 中 # 符号表示注释。Shell 的第一行比较特殊,一般都会以 #! 开始来指定使用的 Shell 类型。在 Linux 中,除了 bash Shell 以外,还有很多版本的 Shell,例如 zsh、dash 等等...不过 bash Shell 还是我们使用最多的。
(4)运行脚本:./helloworld.sh。(注意,一定要写成 ./helloworld.sh,而不是 helloworld.sh,运行其它二进制的程序也一样,直接写 helloworld.sh,Linux 系统会去 PATH 里寻找有没有叫 helloworld.sh 的,而只有 /bin、/sbin、/usr/bin、/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 helloworld.sh 是会找不到命令的,要用 ./helloworld.sh 告诉系统说,就在当前目录找。)

Shell 变量
Shell 编程中的变量介绍
Shell 编程中一般分为三种变量:
- 自定义变量(局部变量):默认仅在当前 Shell 进程内有效,子进程无法访问。若需传递给子进程,需使用
export声明为环境变量。 - 环境变量:例如
PATH、HOME等,可被子进程继承。使用env命令可以查看所有环境变量,set命令可以查看所有变量(包括环境变量和局部变量)。 - Shell 特殊变量:由 Shell 设置的特殊变量(如
$?、$$、$!等),用于保存进程状态、参数等信息。
常用的环境变量:
PATH 决定了 Shell 将到哪些目录中寻找命令或程序。
HOME 当前用户主目录。
HISTSIZE 历史记录数。
LOGNAME 当前用户的登录名。
HOSTNAME 指主机的名称。
SHELL 当前用户 Shell 类型。
LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量。
MAIL 当前用户的邮件存放目录。
PS1 基本提示符,对于 root 用户是 #,对于普通用户是 $。
使用 Linux 已定义的环境变量:
比如我们要看当前用户目录可以使用:echo $HOME 命令;如果我们要看当前用户 Shell 类型可以使用 echo $SHELL 命令。可以看出,使用方法非常简单。
使用自己定义的变量:
#!/bin/bash
#自定义变量hello
hello="hello world"
echo $hello
echo "helloworld!"
Shell 编程中的变量名的命名的注意事项:
- 命名只能使用英文字母、数字和下划线,首个字符不能以数字开头,但是可以使用下划线(_)开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用 bash 里的关键字(可用 help 命令查看保留关键字)。
Shell 字符串入门
字符串是 Shell 编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号。这点和 Java 中有所不同。
在单引号中,所有特殊字符(如 $、反引号、\ 等)都失去特殊含义,被视为字面量。
在双引号中,以下字符保留特殊含义:
$:变量扩展(如$var)和命令替换(如$(cmd)或`cmd`)\:转义字符`或$():命令替换(推荐使用$()语法)!:历史扩展(仅在交互式 Shell 中默认开启)${}:参数扩展
注意:单引号中的字符串是完全字面量,双引号中的字符串会进行变量和命令替换。
单引号字符串:
#!/bin/bash
name='SnailClimb'
hello='Hello, I am $name!'
echo $hello输出内容:
Hello, I am $name!双引号字符串:
#!/bin/bash
name='SnailClimb'
hello="Hello, I am $name!"
echo $hello输出内容:
Hello, I am SnailClimb!Shell 字符串常见操作
拼接字符串:
#!/bin/bash
name="SnailClimb"
# 使用双引号拼接
greeting="hello, "$name" !"
greeting_1="hello, ${name} !"
echo $greeting $greeting_1
# 使用单引号拼接
greeting_2='hello, '$name' !'
greeting_3='hello, ${name} !'
echo $greeting_2 $greeting_3输出结果:

获取字符串长度:
#!/bin/bash
# 获取字符串长度
name="SnailClimb"
# 第一种方式(推荐):bash 内置
echo ${#name} # 输出 10
# 第二种方式:外部命令(性能较差)
expr length "$name"输出结果:
10
10说明:
- 推荐使用
${#var}语法,这是 bash 内置功能,性能更好。 expr是外部命令,需要 fork 进程,性能较差。expr length是 GNU 扩展,非 POSIX 标准。在 macOS 的 BSD expr 或其他系统上可能不支持。- 如需可移植性,推荐使用
${#var}或expr "$var" : '.*'(POSIX 兼容)。
使用 expr 命令时,表达式中的运算符左右必须包含空格:
expr 5+6 # 直接输出 5+6(无空格)
expr 5 + 6 # 输出 11(有空格)
# 更推荐使用 bash 算术扩展:
echo $((5 + 6)) # 输出 11对于某些运算符,还需要我们使用符号 \ 进行转义:
expr 5 * 6 # 输出错误(未转义)
expr 5 \* 6 # 输出 30(正确转义)截取子字符串:
简单的字符串截取:
#从字符串第 0 个字符开始往后截取 10 个字符(索引从 0 开始)
str="SnailClimb is a great man"
echo ${str:0:10} #输出:SnailClimb根据表达式截取:
#!/bin/bash
# author: amau
var="https://www.runoob.com/linux/linux-shell-variable.html"
# %表示删除从后匹配, 最短结果
# %%表示删除从后匹配, 最长匹配结果
# #表示删除从头匹配, 最短结果
# ##表示删除从头匹配, 最长匹配结果
# 注: *为通配符, 意为匹配任意数量的任意字符
s1=${var%%t*} #h
s2=${var%t*} #https://www.runoob.com/linux/linux-shell-variable.h
s3=${var%%.*} #https://www
s4=${var#*/} #/www.runoob.com/linux/linux-shell-variable.html
s5=${var##*/} #linux-shell-variable.htmlShell 数组
bash 2.0+ 支持一维数组(不支持多维数组),并且没有限定数组的大小。
重要提示:数组是 bash 的非 POSIX 扩展特性,纯 POSIX sh(如 dash)不支持数组。若需编写可移植脚本,应避免使用数组。
下面是一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
#!/bin/bash
array=(1 2 3 4 5);
# 获取数组长度
length=${#array[@]}
# 或者
length2=${#array[*]}
#输出数组长度
echo $length #输出:5
echo $length2 #输出:5
# 输出数组第三个元素
echo ${array[2]} #输出:3
unset 'array[1]' # 删除下标为 1 的元素,也就是第二个元素
for i in "${array[@]}"; do echo "$i"; done # 遍历数组,输出:1 3 4 5
unset array; # 删除数组中的所有元素
for i in "${array[@]}"; do echo "$i"; done # 遍历数组,数组元素为空,没有任何输出内容重要说明:数组索引空洞:
使用 unset array[1] 删除元素后,数组会产生索引空洞:
#!/bin/bash
array=(1 2 3 4 5)
echo "删除前: ${array[@]}" # 输出: 1 2 3 4 5
echo "索引1的值: ${array[1]}" # 输出: 2
unset array[1] # 删除索引1的元素
echo "删除后: ${array[@]}" # 输出: 1 3 4 5
echo "索引1的值: ${array[1]}" # 输出: (空值)
echo "索引2的值: ${array[2]}" # 输出: 3 (索引2仍在)
# 遍历时索引不连续
for index in "${!array[@]}"; do
echo "索引[$index] = ${array[$index]}"
done
# 输出:
# 索引[0] = 1
# 索引[2] = 3
# 索引[3] = 4
# 索引[4] = 5注意:删除元素后,如果使用 ${array[1]} 访问会得到空值。遍历数组时建议使用 "${!array[@]}" 获取有效索引,或使用 "${array[@]}" 直接遍历值。
Shell 基本运算符
Shell 编程支持下面几种运算符:
- 算数运算符
- 关系运算符
- 布尔运算符
- 字符串运算符
- 文件测试运算符
算数运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $a + $b |
| - | 减法 | expr $a - $b |
| * | 乘法 | expr $a \* $b(注意星号需要转义) |
| / | 除法 | expr $b / $a |
| % | 取余 | expr $b % $a |
| = | 赋值 | a=$b 将变量 b 的值赋给 a |
| == | 相等 | [ "$a" == "$b" ] 用于字符串比较,相同返回 true |
| != | 不相等 | [ "$a" != "$b" ] 用于字符串比较,不同返回 true |
推荐使用 bash 内置算术扩展:
#!/bin/bash
a=3; b=3
val=$((a + b)) # bash 算术扩展(推荐)
# 输出:Total value: 6
echo "Total value: $val"说明:
$((...))是 bash 内置功能,无需 fork 外部进程,性能更好。- 不推荐使用
expr命令(需 fork 进程,且运算符两边必须有空格)。 - 不推荐使用反引号
`...`(已过时),应使用$(...)语法。
如果需要兼容 POSIX sh,可以使用:
val=$(expr "$a" + "$b") # POSIX 兼容,但性能较差关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
| 运算符 | 说明 | 对应英文 |
|---|---|---|
| -eq | 检测两个数是否相等 | equal |
| -ne | 检测两个数是否不相等 | not equal |
| -gt | 检测左边的数是否大于右边的 | greater than |
| -lt | 检测左边的数是否小于右边的 | less than |
| -ge | 检测左边的数是否大于等于右边的 | greater equal |
| -le | 检测左边的数是否小于等于右边的 | less equal |
通过一个简单的示例演示关系运算符的使用,下面 Shell 程序的作用是当 score=100 的时候输出 A 否则输出 B。
#!/bin/bash
score=90;
maxscore=100;
if [[ $score -eq $maxscore ]]
then
echo "A"
else
echo "B"
fi输出结果:
B逻辑运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]](全真才为真) |
| || | 逻辑的 OR | [[ $a -lt 100 || $b -gt 100 ]](一真即为真) |
算术扩展中的逻辑运算:
#!/bin/bash
a=$(( 1 && 0))
# 输出:0;逻辑与运算只有相与的两边都是1,与的结果才是1;否则与的结果是0
echo $a;命令短路执行(生产环境常用):
在运维自动化和 CI/CD 管道中,经常使用 && 和 || 来控制命令链路的执行流程,这称为短路执行:
#!/bin/bash
set -euo pipefail
# &&:前一个命令成功(返回 0)时才执行后一个命令
mkdir -p "/tmp/app_data" && echo "目录就绪"
# ||:前一个命令失败(返回非 0)时才执行后一个命令
mkdir -p "/tmp/app_data" || echo "目录创建失败"
# 组合使用:生产环境典型的防御姿势
mkdir -p "/tmp/app_data" && echo "目录就绪" || exit 1
# 实际场景示例
# 1. 检查文件存在后再删除
[ -f "/tmp/old_file.log" ] && rm "/tmp/old_file.log"
# 2. 命令失败时输出错误信息并退出
cd /app/config || { echo "无法进入配置目录"; exit 1; }
# 3. 条件执行命令
command1 && command2 || command3
# ⚠️ 注意:此写法有陷阱!
# - 当 command1 成功时,执行 command2
# - 当 command1 失败时,执行 command3
# - 但如果 command1 成功但 command2 失败,command3 仍会执行!
#
# ✅ 更安全的写法(推荐):
if command1; then
command2
else
command3
fi
#
# 或明确知道 command2 不会失败时才使用 && || 组合重要提示:
- 短路执行依赖命令的退出码(Exit Code):成功返回 0,失败返回非 0。
- 这与
[[ ]]内部的&&和||不同,后者用于条件测试。 command1 && command2 || command3存在陷阱:若 command1 成功但 command2 失败,command3 仍会执行。- 生产环境中强烈建议使用 if-then-else 结构,确保逻辑清晰。
布尔运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| ! | 将表达式的结果取反。如果表达式为 true,则返回 false;否则返回 true。 | [ ! false ] 返回 false,因为 false 是非空字符串。 |
| -o | 有一个表达式为 true,则返回 true。 | [ "$a" -lt 20 -o "$b" -gt 100 ] 返回 true。 |
| -a | 两个表达式都为 true 才会返回 true。 | [ "$a" -lt 20 -a "$b" -gt 100 ] 返回 false。 |
字符串运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 检测两个字符串是否相等 | [ "$a" = "$b" ] |
| != | 检测两个字符串是否不相等 | [ "$a" != "$b" ] |
| -z | 检测字符串长度是否为 0 (zero) | [ -z "$a" ] 为空返回 true |
| -n | 检测字符串长度是否不为 0 | [ -n "$a" ] 不为空返回 true |
| str | 直接检测字符串是否为空 | [ "$a" ] 不为空返回 true |
简单示例:
#!/bin/bash
a="abc";
b="efg";
if [[ "$a" = "$b" ]]
then
echo "a 等于 b"
else
echo "a 不等于 b"
fi输出:
a 不等于 b文件相关运算符
用于检测 Unix/Linux 文件的各种属性(如权限、类型等)。
- 存在与类型检测:
- -e file:检测文件(包括目录)是否存在。
- -f file:检测是否为普通文件(既不是目录也不是设备文件)。
- -d file:检测是否为目录。
- -s file:检测文件是否非空(文件大小大于 0 返回 true)。
- -b/-c/-p:分别检测是否为块设备、字符设备、有名管道。
- 权限检测:
- -r file:检测文件是否可读。
- -w file:检测文件是否可写。
- -x file:检测文件是否可执行。
- 特殊标识检测:
- -u / -g / -k:分别检测文件是否设置了 SUID、SGID 或粘着位(Sticky Bit)。
使用方式很简单,比如我们定义好了一个文件路径 file="/usr/learnshell/test.sh",如果我们想判断这个文件是否可读,可以这样 if [ -r $file ];如果想判断这个文件是否可写,可以这样 -w $file,是不是很简单。
Shell 流程控制
if 条件语句
简单的 if else-if else 的条件语句示例:
#!/bin/bash
a=3;
b=9;
if [[ $a -eq $b ]]
then
echo "a 等于 b"
elif [[ $a -gt $b ]]
then
echo "a 大于 b"
else
echo "a 小于 b"
fi输出结果:
a 小于 b相信大家通过上面的示例就已经掌握了 Shell 编程中的 if 条件语句。
空语句的处理:Shell 中空语句可以使用 :(冒号命令)或 true 命令实现:
if [[ condition ]]; then
: # 空语句(什么都不做)
fi
# 或
if [[ condition ]]; then
true # 空语句
fi这在某些场景下很有用,例如在 while 循环中作为占位符。
for 循环语句
通过下面三个简单的示例认识 for 循环语句最基本的使用,实际上 for 循环语句的功能比下面你看到的示例展现的要大得多。
输出当前列表中的数据:
for loop in 1 2 3 4 5
do
echo "The value is: $loop"
done产生 10 个随机数:
#!/bin/bash
for i in {0..9};
do
echo $RANDOM;
done输出 1 到 5:
通常情况下 Shell 变量调用需要加 $,但是 for 的 (()) 中不需要,下面来看一个例子:
#!/bin/bash
length=5
for((i=1;i<=length;i++));do
echo $i;
done;while 语句
基本的 while 循环语句:
#!/bin/bash
int=1
while (( int <= 5 )) # 算术上下文内变量无需 $
do
echo $int
(( int++ )) # 推荐使用 (( )) 替代 let
donewhile 循环可用于读取键盘信息:
echo '按下 <CTRL-D> 退出'
echo -n '输入你最喜欢的电影: '
while read -r FILM # -r 选项禁止反斜杠转义,提高安全性
do
echo "是的!$FILM 是一个好电影"
done输出内容:
按下 <CTRL-D> 退出
输入你最喜欢的电影: 变形金刚
是的!变形金刚 是一个好电影无限循环:
while true
do
command
doneShell 函数
不带参数没有返回值的函数
#!/bin/bash
hello(){
echo "这是我的第一个 shell 函数!"
}
echo "-----函数开始执行-----"
hello
echo "-----函数执行完毕-----"输出结果:
-----函数开始执行-----
这是我的第一个 shell 函数!
-----函数执行完毕-----有返回值的函数
输入两个数字之后相加并输出结果:
#!/bin/bash
set -euo pipefail
funWithReturn(){
local aNum
local anotherNum
echo "输入第一个数字: "
read -r aNum
echo "输入第二个数字: "
read -r anotherNum
echo "两个数字分别为 $aNum 和 $anotherNum !"
result=$((aNum + anotherNum))
}
result=0
funWithReturn
echo "输入的两个数字之和为 $result"重要说明:
local关键字:将变量限制在函数作用域内,避免污染全局命名空间。read -r:-r选项禁止反斜杠转义,提高安全性。- 函数返回值:
return设置的是 0-255 的退出状态,不适合传递计算结果。需要传递数据时,可以使用标准输出或变量。
为什么使用 local?
- 在复杂脚本或引入多个外部脚本时,非 local 变量可能被意外覆盖。
- 全局变量污染会导致难以排查的配置漂移或逻辑越权。
- 使用
local是函数编程的最佳实践,类似于其他编程语言的局部变量概念。
输出结果:
输入第一个数字:
1
输入第二个数字:
2
两个数字分别为 1 和 2 !
输入的两个数字之和为 3带参数的函数
#!/bin/bash
funWithParam(){
echo "第一个参数为 $1"
echo "第二个参数为 $2"
echo "脚本名称为 $0"
echo "第十个参数为 ${10}" # 注意:参数 ≥ 10 时必须用 ${n}
echo "第十一个参数为 ${11}"
echo "参数总数有 $# 个"
echo "所有参数为 $*" # 作为单个字符串输出
echo "所有参数为 $@" # 作为独立的参数输出(推荐)
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73输出结果:
第一个参数为 1
第二个参数为 2
脚本名称为 ./script.sh
第十个参数为 34
第十一个参数为 73
参数总数有 11 个
所有参数为 1 2 3 4 5 6 7 8 9 34 73
所有参数为 1 2 3 4 5 6 7 8 9 34 73重要提示:
- 位置参数
$n当n >= 10时必须使用${n}语法。 - 例如:
$10会被解析为$1和字面量0的拼接,而非第十个参数。 $0表示脚本本身的名称。$#表示参数总数。
$* 与 $@ 的核心区别:
| 表达式 | 未引用 | 双引号包裹 |
|---|---|---|
$* | 展开为所有参数 | 展开为单个字符串(所有参数合并) |
$@ | 展开为所有参数 | 展开为独立的参数(每个参数保持独立) |
示例对比:
#!/bin/bash
test_args() {
echo "--- 使用 \$* (无引号)---"
for arg in $*; do
echo "参数: [$arg]"
done
echo -e "\n--- 使用 \$@ (无引号)---"
for arg in $@; do
echo "参数: [$arg]"
done
echo -e "\n--- 使用 \"\$*\" (双引号)---"
for arg in "$*"; do
echo "参数: [$arg]"
done
echo -e "\n--- 使用 \"\$@\" (双引号,推荐)---"
for arg in "$@"; do
echo "参数: [$arg]"
done
}
# 调用函数,传递包含空格的参数
test_args "hello world" "foo bar"输出结果:
--- 使用 $* (无引号)---
参数: [hello]
参数: [world]
参数: [foo]
参数: [bar]
--- 使用 $@ (无引号)---
参数: [hello]
参数: [world]
参数: [foo]
参数: [bar]
--- 使用 "$*" (双引号)---
参数: [hello world foo bar] # 所有参数合并为一个字符串
--- 使用 "$@" (双引号,推荐)---
参数: [hello world] # 每个参数保持独立
参数: [foo bar]结论:在传递参数时,始终使用 "$@" 以确保每个参数的独立性(特别是当参数包含空格时)。
Shell 编程最佳实践
在掌握了 Shell 编程的基础知识后,了解一些最佳实践能帮助你编写更安全、更高效的脚本。
脚本基础规范
1. Shebang 规范:
#!/usr/bin/env bash
# 通过 PATH 查找 bash
set -euo pipefailShebang 两种写法:
#!/bin/bash:直接指定 bash 路径,适用于你知道 bash 位置的固定环境。#!/usr/bin/env bash:通过 env 查找 bash,更可移植,适合不同系统(如 macOS / Linux)。
本文示例选择:
- 教程示例使用
#!/bin/bash:简洁明了,适合初学者理解。 - 生产级示例使用
#!/usr/bin/env bash:强调可移植性。
2. 变量引用:
# 始终用双引号包裹变量
echo "$var" # 推荐
echo $var # 可能导致 word splitting 和 globbing 问题3. 使用 shellcheck:
shellcheck your_script.sh # 静态分析,发现常见问题4. 推荐语法:
- 使用
[[ ]]而非[ ](更安全、支持模式匹配)。 - 使用
$((...))而非expr(性能更好)。 - 使用
$(...)而非反引号(可嵌套、更清晰)。 - 使用
${n}访问位置参数 n >= 10。
pipefail 工作原理
默认情况下,管道命令的返回值只取决于最后一个命令。启用 pipefail 后,管道的返回值将是最后一个失败命令的返回值,这能避免隐藏中间步骤的错误。
示例对比:
# 默认模式(危险)
cat huge_file.txt | grep "pattern" | head -n 10
# 即使 cat 失败(文件不存在),只要 head 成功,返回码就是 0
# pipefail 模式(安全)
set -o pipefail
cat huge_file.txt | grep "pattern" | head -n 10
# cat 失败会立即返回错误码,不会被忽略把 Shell 脚本放进生产环境前
基础语法写对只是第一步。脚本进入定时任务、部署流程或线上机器后,还要处理失败退出、临时文件、网络超时和后台任务退出码。下面用几个完整的小例子说明。
set -u 和 set -o pipefail 的行为相对明确;set -e 的例外较多,在条件判断、函数、子 Shell 和命令替换中的行为都可能让人意外。可以把 set -euo pipefail 当作新脚本的起点,但不能用它代替显式的 if ! command; then ... fi 错误处理。变量展开仍应按场景加双引号,函数内部变量用 local 限定作用域。
给网络请求设置总预算
一次请求要同时限制连接阶段和整个传输时间。重试只能放在一层:如果外层循环和 curl --retry 同时启用,真实请求次数会相乘,总耗时也很难估算。下面的函数由外层统一控制尝试次数,并在每次失败后加入 0~2 秒的整数随机延迟:
#!/usr/bin/env bash
retry_request() {
local url="$1"
local max_attempts=5
local attempt=1
local delay
local jitter
while (( attempt <= max_attempts )); do
if curl --fail --silent --show-error \
--connect-timeout 3 \
--max-time 10 \
"$url"; then
return 0
fi
if (( attempt == max_attempts )); then
break
fi
delay=$((1 << (attempt - 1)))
(( delay > 16 )) && delay=16
jitter=$((RANDOM % 3))
delay=$((delay + jitter))
printf '第 %d 次请求失败,%d 秒后重试\n' "$attempt" "$delay" >&2
sleep "$delay"
((attempt += 1))
done
return 1
}
command -v curl >/dev/null 2>&1 || {
echo "curl 未安装" >&2
exit 1
}
[[ $# -eq 1 ]] || {
echo "用法: $0 <url>" >&2
exit 1
}
retry_request "$1" || {
echo "请求失败" >&2
exit 1
}真实脚本还要根据接口语义决定哪些错误可以重试。非幂等写请求、认证失败和参数错误通常不应直接重放。
临时文件和互斥锁
不要用 /tmp/data_$$ 这类可预测路径。mktemp 会原子创建文件或目录,配合 trap 可以在正常退出和收到常见信号时清理:
#!/usr/bin/env bash
temp_dir=$(mktemp -d "${TMPDIR:-/tmp}/myapp.XXXXXXXX") || {
echo "无法创建临时目录" >&2
exit 1
}
cleanup() {
rm -rf -- "$temp_dir"
}
trap cleanup EXIT
trap 'exit 129' HUP
trap 'exit 130' INT
trap 'exit 143' TERM
temp_file="$temp_dir/result.txt"
printf 'temporary data\n' > "$temp_file"
cat "$temp_file"同一台机器上需要阻止脚本重复运行时,可以对应用自己管理的锁文件使用 flock:
exec 9>/var/lock/myapp.lock || exit 1
flock -n 9 || {
echo "脚本已在运行" >&2
exit 1
}flock 是协作式锁,其他进程可以选择不遵守。Linux 的 NFS 客户端可以把它模拟为整文件 fcntl 锁,但实际行为还受客户端内核、服务端和 local_lock 等挂载选项影响。锁文件放在网络文件系统时,应在目标部署环境用两个独立客户端验证,不能预设一定有效或一定失效。跨机器互斥也不能只写一句 Redis SET NX PX:实现还要处理唯一 token、条件删除、租约续期和故障模型。
收集后台任务的退出码
不带参数的 wait 会等待所有后台任务,但 Bash 返回 0,无法告诉你其中哪个任务失败。下面的脚本并发统计多个文件的字节数,并逐个收集子进程状态:
#!/usr/bin/env bash
set -u
pids=()
for file in "$@"; do
wc -c -- "$file" &
pids+=("$!")
done
exit_code=0
for pid in "${pids[@]}"; do
if ! wait "$pid"; then
echo "后台任务 $pid 执行失败" >&2
exit_code=1
fi
done
exit "$exit_code"直接写 while wait -n; do ...; done 也不完整:某个任务失败时 wait -n 返回非 0,循环会立即结束,剩余任务可能没有被收集。
常见误区
不要把整条命令的标准输出和标准错误都长期重定向到 /dev/null,否则失败时只剩退出码,没有诊断信息。只屏蔽确认不需要的输出,错误信息写入日志或保留在标准错误中。脚本依赖 curl、jq 等外部命令时,启动阶段先用 command -v 检查;管道需要感知中间命令失败时,再启用 set -o pipefail。
上线前怎么验证
验证内容应贴着脚本真实依赖来定。网络脚本至少覆盖连接失败、超时和不可重试的 HTTP 状态;并发脚本检查每个子进程的退出码;会创建临时资源的脚本还要验证正常退出和信号中断后是否完成清理。故障注入命令会修改防火墙、系统时间或挂载状态,不适合当作可直接复制的通用示例,应在隔离测试环境中按实际基础设施单独设计。
总结
Shell 适合把已有命令串成小型自动化流程。先掌握变量引用、条件、循环、函数和退出状态,再根据脚本实际使用的网络、文件和并发资源补上超时、清理与错误处理。
核心知识点回顾
| 知识模块 | 关键要点 |
|---|---|
| 变量 | 区分局部变量、环境变量和特殊变量;使用 local 避免全局污染;始终用双引号包裹变量 |
| 字符串 | 推荐使用双引号;理解单引号和双引号的区别;掌握 ${#var} 获取长度 |
| 数组 | bash 2.0+ 支持数组(非 POSIX);注意删除元素后的索引空洞 |
| 运算符 | 优先使用 $((...)) 进行算术运算;[[ ]] 比 [ ] 更安全 |
| 流程控制 | 使用 [[ ]] 进行条件测试;避免 command1 && command2 || command3 的陷阱 |
| 函数 | 使用 local 限制变量作用域;函数只能返回 0-255 的退出码 |
| 命令替换 | 使用 $(...) 替代反引号;使用 read -r 提高安全性 |
学习建议
从日志筛选、批量改名、文件统计这类短任务开始,写完先用 bash -n 检查语法,再用 ShellCheck 找未引用变量、错误重定向等常见问题。脚本开始管理后台进程或系统服务后,再继续学习信号、作业控制、sed、awk 和 grep。超过几百行、需要复杂数据结构或异常恢复时,Python 等通用语言通常更容易维护。
参考资源
- 官方文档:Bash Reference Manual(GNU)
- 代码检查:ShellCheck - Shell Script Analysis Tool
- 编码规范:Google Shell Style Guide
- 常见陷阱:Bash Pitfalls (http://mywiki.wooledge.org/BashPitfalls)