SQL常见面试题总结(5)
题目来源于:牛客题霸 - SQL 进阶挑战
较难或者困难的题目可以根据自身实际情况和面试需要来决定是否要跳过。
空值处理
统计有未完成状态的试卷的未完成数和未完成率
描述:
现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分),数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
| 3 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
请统计有未完成状态的试卷的未完成数 incomplete_cnt 和未完成率 incomplete_rate。由示例数据结果输出如下:
| exam_id | incomplete_cnt | complete_rate |
|---|---|---|
| 9001 | 1 | 0.333 |
解释:试卷 9001 有 3 次被作答的记录,其中两次完成,1 次未完成,因此未完成数为 1,未完成率为 0.333(保留 3 位小数)
思路:
这题只需要注意一个是有条件限制,一个是没条件限制的;要么分别查询条件,然后合并;要么直接在 select 里面进行条件判断。
答案:
写法 1:
SELECT
exam_id,
(COUNT(*) - COUNT(submit_time)) AS incomplete_cnt,
ROUND((COUNT(*) - COUNT(submit_time)) / COUNT(*), 3) AS incomplete_rate
FROM
exam_record
GROUP BY
exam_id
HAVING
(COUNT(*) - COUNT(submit_time)) > 0;利用 COUNT(*)统计分组内的总记录数,COUNT(submit_time) 只统计 submit_time 字段不为 NULL 的记录数(即已完成数)。两者相减,就是未完成数。
写法 2:
SELECT
exam_id,
COUNT(CASE WHEN submit_time IS NULL THEN 1 END) AS incomplete_cnt,
ROUND(COUNT(CASE WHEN submit_time IS NULL THEN 1 END) / COUNT(*), 3) AS incomplete_rate
FROM
exam_record
GROUP BY
exam_id
HAVING
COUNT(CASE WHEN submit_time IS NULL THEN 1 END) > 0;使用 CASE 表达式,当条件满足时返回一个非 NULL 值(例如 1),否则返回 NULL。然后用 COUNT 函数来统计非 NULL 值的数量。
写法 3:
SELECT
exam_id,
SUM(submit_time IS NULL) AS incomplete_cnt,
ROUND(SUM(submit_time IS NULL) / COUNT(*), 3) AS incomplete_rate
FROM
exam_record
GROUP BY
exam_id
HAVING
incomplete_cnt > 0;利用 SUM 函数对一个表达式求和。当 submit_time 为 NULL 时,表达式 (submit_time IS NULL) 的值为 1 (TRUE),否则为 0 (FALSE)。将这些 1 和 0 加起来,就得到了未完成的数量。
0 级用户高难度试卷的平均用时和平均得分
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间),数据如下:
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 10 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间),数据如下:
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | SQL | easy | 60 | 2020-01-01 10:00:00 |
| 3 | 9004 | 算法 | medium | 80 | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分),数据如下:
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
请输出每个 0 级用户所有的高难度试卷考试平均用时和平均得分,未完成的默认试卷最大考试时长和 0 分处理。由示例数据结果输出如下:
| uid | avg_score | avg_time_took |
|---|---|---|
| 1001 | 33 | 36.7 |
解释:0 级用户有 1001,高难度试卷有 9001,1001 作答 9001 的记录有 3 条,分别用时 20 分钟、未完成(试卷时长 60 分钟)、30 分钟(未满 31 分钟),分别得分为 80 分、未完成(0 分处理)、20 分。因此他的平均用时为 110/3=36.7(保留一位小数),平均得分为 33 分(取整)
思路:这题用IF是判断的最方便的,因为涉及到 NULL 值的判断。当然 case when也可以,大同小异。这题的难点就在于空值的处理,其他的这些查询条件什么的,我相信难不倒大家。
答案:
SELECT UID,
round(avg(new_socre)) AS avg_score,
round(avg(time_diff), 1) AS avg_time_took
FROM
(SELECT er.uid,
IF (er.submit_time IS NOT NULL, TIMESTAMPDIFF(MINUTE, start_time, submit_time), ef.duration) AS time_diff,
IF (er.submit_time IS NOT NULL,er.score,0) AS new_socre
FROM exam_record er
LEFT JOIN user_info uf ON er.uid = uf.uid
LEFT JOIN examination_info ef ON er.exam_id = ef.exam_id
WHERE uf.LEVEL = 0 AND ef.difficulty = 'hard' ) t
GROUP BY UID
ORDER BY UID高级条件语句
筛选限定昵称成就值活跃日期的用户(较难)
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 1000 | 2 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 进击的 3 号 | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 2500 | 6 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 5 号 | 3000 | 7 | C++ | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
| 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
题目练习记录表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
| id | uid | question_id | submit_time | score |
|---|---|---|---|---|
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
| 5 | 1003 | 8002 | 2021-09-01 19:38:01 | 80 |
请找到昵称以『牛客』开头『号』结尾、成就值在 1200~2500 之间,且最近一次活跃(答题或作答试卷)在 2021 年 9 月的用户信息。
由示例数据结果输出如下:
| uid | nick_name | achievement |
|---|---|---|
| 1002 | 牛客 2 号 | 1200 |
解释:昵称以『牛客』开头『号』结尾且成就值在 1200~2500 之间的有 1002、1004;
1002 最近一次试卷区活跃为 2021 年 9 月,最近一次题目区活跃为 2021 年 9 月;1004 最近一次试卷区活跃为 2021 年 8 月,题目区未活跃。
因此最终满足条件的只有 1002。
思路:
先根据条件列出主要查询语句
昵称以『牛客』开头『号』结尾: nick_name LIKE "牛客%号"
成就值在 1200~2500 之间:achievement BETWEEN 1200 AND 2500
第三个条件因为限定了为 9 月,所以直接写就行:( date_format( record.submit_time, '%Y%m' )= 202109 OR date_format( pr.submit_time, '%Y%m' )= 202109 )
答案:
SELECT DISTINCT u_info.uid,
u_info.nick_name,
u_info.achievement
FROM user_info u_info
LEFT JOIN exam_record record ON record.uid = u_info.uid
LEFT JOIN practice_record pr ON u_info.uid = pr.uid
WHERE u_info.nick_name LIKE "牛客%号"
AND u_info.achievement BETWEEN 1200
AND 2500
AND (date_format(record.submit_time, '%Y%m')= 202109
OR date_format(pr.submit_time, '%Y%m')= 202109)
GROUP BY u_info.uid筛选昵称规则和试卷规则的作答记录(较难)
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 1900 | 2 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 2500 | 6 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 555 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | C++ | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | c# | hard | 80 | 2020-01-01 10:00:00 |
| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
| 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-09-01 11:31:01 | 84 |
找到昵称以"牛客"+纯数字+"号"或者纯数字组成的用户对于字母 c 开头的试卷类别(如 C,C++,c#等)的已完成的试卷 ID 和平均得分,按用户 ID、平均分升序排序。由示例数据结果输出如下:
| uid | exam_id | avg_score |
|---|---|---|
| 1002 | 9001 | 81 |
| 1002 | 9002 | 85 |
| 1005 | 9001 | 84 |
| 1006 | 9001 | 84 |
解释:昵称满足条件的用户有 1002、1004、1005、1006;
c 开头的试卷有 9001、9002;
满足上述条件的作答记录中,1002 完成 9001 的得分有 81、80,平均分为 81(80.5 取整四舍五入得 81);
1002 完成 9002 的得分有 90、82、83,平均分为 85;
思路:
还是老样子,既然给出了条件,就先把各个条件先写出来
找到昵称以"牛客"+纯数字+"号"或者纯数字组成的用户: 我最开始是这么写的:nick_name LIKE '牛客%号' OR nick_name REGEXP '^[0-9]+$',如果表中有个 “牛客 H 号” ,那也能通过。
所以这里还得用正则: nick_name LIKE '^牛客[0-9]+号'
对于字母 c 开头的试卷类别: e_info.tag LIKE 'c%' 或者 tag regexp '^c|^C' 第一个也能匹配到大写 C
答案:
SELECT UID,
exam_id,
ROUND(AVG(score), 0) avg_score
FROM exam_record
WHERE UID IN
(SELECT UID
FROM user_info
WHERE nick_name RLIKE "^牛客[0-9]+号 $"
OR nick_name RLIKE "^[0-9]+$")
AND exam_id IN
(SELECT exam_id
FROM examination_info
WHERE tag RLIKE "^[cC]")
AND score IS NOT NULL
GROUP BY UID,exam_id
ORDER BY UID,avg_score;根据指定记录是否存在输出不同情况(困难)
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 进击的 3 号 | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 555 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
| 6 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
| 7 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
| 8 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
| 9 | 1002 | 9003 | 2020-02-02 12:11:01 | (NULL) | (NULL) |
| 10 | 1002 | 9002 | 2021-05-05 18:01:01 | (NULL) | (NULL) |
| 11 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
| 12 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
| 13 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
请你筛选表中的数据,当有任意一个 0 级用户未完成试卷数大于 2 时,输出每个 0 级用户的试卷未完成数和未完成率(保留 3 位小数);若不存在这样的用户,则输出所有有作答记录的用户的这两个指标。结果按未完成率升序排序。
由示例数据结果输出如下:
| uid | incomplete_cnt | incomplete_rate |
|---|---|---|
| 1004 | 0 | 0.000 |
| 1003 | 1 | 0.500 |
| 1001 | 4 | 0.667 |
解释:0 级用户有 1001、1003、1004;他们作答试卷数和未完成数分别为:6:4、2:1、0:0;
存在 1001 这个 0 级用户未完成试卷数大于 2,因此输出这三个用户的未完成数和未完成率(1004 未作答过试卷,未完成率默认填 0,保留 3 位小数后是 0.000);
结果按照未完成率升序排序。
附:如果 1001 不满足『未完成试卷数大于 2』,则需要输出 1001、1002、1003 的这两个指标,因为试卷作答记录表里只有这三个用户的作答记录。
思路:
先把可能满足条件“0 级用户未完成试卷数大于 2”的 SQL 写出来
SELECT ui.uid UID
FROM user_info ui
LEFT JOIN exam_record er ON ui.uid = er.uid
WHERE ui.uid IN
(SELECT ui.uid
FROM user_info ui
LEFT JOIN exam_record er ON ui.uid = er.uid
WHERE er.submit_time IS NULL
AND ui.LEVEL = 0 )
GROUP BY ui.uid
HAVING sum(IF(er.submit_time IS NULL, 1, 0)) > 2然后再分别写出两种情况的 SQL 查询语句:
情况 1. 查询存在条件要求的 0 级用户的试卷未完成率
SELECT
tmp1.uid uid,
sum(
IF
( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 )) incomplete_cnt,
round(
sum(
IF
( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 ))/ count( tmp1.uid ),
3
) incomplete_rate
FROM
(
SELECT DISTINCT
ui.uid
FROM
user_info ui
LEFT JOIN exam_record er ON ui.uid = er.uid
WHERE
er.submit_time IS NULL
AND ui.LEVEL = 0
) tmp1
LEFT JOIN exam_record er ON tmp1.uid = er.uid
GROUP BY
tmp1.uid
ORDER BY
incomplete_rate情况 2. 查询不存在条件要求时所有有作答记录的 yong 用户的试卷未完成率
SELECT
ui.uid uid,
sum( CASE WHEN er.submit_time IS NULL AND er.start_time IS NOT NULL THEN 1 ELSE 0 END ) incomplete_cnt,
round(
sum(
IF
( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 ))/ count( ui.uid ),
3
) incomplete_rate
FROM
user_info ui
JOIN exam_record er ON ui.uid = er.uid
GROUP BY
ui.uid
ORDER BY
incomplete_rate拼在一起,就是答案
WITH host_user AS
(SELECT ui.uid UID
FROM user_info ui
LEFT JOIN exam_record er ON ui.uid = er.uid
WHERE ui.uid IN
(SELECT ui.uid
FROM user_info ui
LEFT JOIN exam_record er ON ui.uid = er.uid
WHERE er.submit_time IS NULL
AND ui.LEVEL = 0 )
GROUP BY ui.uid
HAVING sum(IF (er.submit_time IS NULL, 1, 0))> 2),
tt1 AS
(SELECT tmp1.uid UID,
sum(IF (er.submit_time IS NULL
AND er.start_time IS NOT NULL, 1, 0)) incomplete_cnt,
round(sum(IF (er.submit_time IS NULL
AND er.start_time IS NOT NULL, 1, 0))/ count(tmp1.uid), 3) incomplete_rate
FROM
(SELECT DISTINCT ui.uid
FROM user_info ui
LEFT JOIN exam_record er ON ui.uid = er.uid
WHERE er.submit_time IS NULL
AND ui.LEVEL = 0 ) tmp1
LEFT JOIN exam_record er ON tmp1.uid = er.uid
GROUP BY tmp1.uid
ORDER BY incomplete_rate),
tt2 AS
(SELECT ui.uid UID,
sum(CASE
WHEN er.submit_time IS NULL
AND er.start_time IS NOT NULL THEN 1
ELSE 0
END) incomplete_cnt,
round(sum(IF (er.submit_time IS NULL
AND er.start_time IS NOT NULL, 1, 0))/ count(ui.uid), 3) incomplete_rate
FROM user_info ui
JOIN exam_record er ON ui.uid = er.uid
GROUP BY ui.uid
ORDER BY incomplete_rate)
(SELECT tt1.*
FROM tt1
LEFT JOIN
(SELECT UID
FROM host_user) t1 ON 1 = 1
WHERE t1.uid IS NOT NULL )
UNION ALL
(SELECT tt2.*
FROM tt2
LEFT JOIN
(SELECT UID
FROM host_user) t2 ON 1 = 1
WHERE t2.uid IS NULL)V2 版本(根据上面做出的改进,答案缩短了,逻辑更强):
SELECT
ui.uid,
SUM(
IF
( start_time IS NOT NULL AND score IS NULL, 1, 0 )) AS incomplete_cnt,#3.试卷未完成数
ROUND( AVG( IF ( start_time IS NOT NULL AND score IS NULL, 1, 0 )), 3 ) AS incomplete_rate #4.未完成率
FROM
user_info ui
LEFT JOIN exam_record USING ( uid )
WHERE
CASE
WHEN (#1.当有任意一个0级用户未完成试卷数大于2时
SELECT
MAX( lv0_incom_cnt )
FROM
(
SELECT
SUM(
IF
( score IS NULL, 1, 0 )) AS lv0_incom_cnt
FROM
user_info
JOIN exam_record USING ( uid )
WHERE
LEVEL = 0
GROUP BY
uid
) table1
)> 2 THEN
uid IN ( #1.1找出每个0级用户
SELECT uid FROM user_info WHERE LEVEL = 0 ) ELSE uid IN ( #2.若不存在这样的用户,找出有作答记录的用户
SELECT DISTINCT uid FROM exam_record )
END
GROUP BY
ui.uid
ORDER BY
incomplete_rate #5.结果按未完成率升序排序各用户等级的不同得分表现占比(较难)
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 555 号 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 75 |
| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:11:01 | 60 |
| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | 2021-09-02 12:41:01 | 90 |
| 6 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
| 7 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
| 8 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
| 9 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
| 10 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
| 11 | 1002 | 9003 | 2020-02-02 12:11:01 | 2020-02-02 12:41:01 | 76 |
为了得到用户试卷作答的定性表现,我们将试卷得分按分界点[90,75,60]分为优良中差四个得分等级(分界点划分到左区间),请统计不同用户等级的人在完成过的试卷中各得分等级占比(结果保留 3 位小数),未完成过试卷的用户无需输出,结果按用户等级降序、占比降序排序。
由示例数据结果输出如下:
| level | score_grade | ratio |
|---|---|---|
| 3 | 良 | 0.667 |
| 3 | 优 | 0.333 |
| 0 | 良 | 0.500 |
| 0 | 中 | 0.167 |
| 0 | 优 | 0.167 |
| 0 | 差 | 0.167 |
解释:完成过试卷的用户有 1001、1002;完成了的试卷对应的用户等级和分数等级如下:
| uid | exam_id | score | level | score_grade |
|---|---|---|---|---|
| 1001 | 9001 | 80 | 0 | 良 |
| 1001 | 9002 | 75 | 0 | 良 |
| 1001 | 9002 | 60 | 0 | 中 |
| 1001 | 9003 | 90 | 0 | 优 |
| 1001 | 9001 | 20 | 0 | 差 |
| 1001 | 9002 | 89 | 0 | 良 |
| 1002 | 9001 | 99 | 3 | 优 |
| 1002 | 9003 | 82 | 3 | 良 |
| 1002 | 9003 | 76 | 3 | 良 |
因此 0 级用户(只有 1001)的各分数等级比例为:优 1/6,良 1/6,中 1/6,差 3/6;3 级用户(只有 1002)各分数等级比例为:优 1/3,良 2/3。结果保留 3 位小数。
思路:
先把 “将试卷得分按分界点[90,75,60]分为优良中差四个得分等级”这个条件写出来,这里可以用到case when
CASE
WHEN a.score >= 90 THEN
'优'
WHEN a.score < 90 AND a.score >= 75 THEN
'良'
WHEN a.score < 75 AND a.score >= 60 THEN
'中' ELSE '差'
END这题的关键点就在于这,其他剩下的就是条件拼接了
答案:
SELECT a.LEVEL,
a.score_grade,
ROUND(a.cur_count / b.total_num, 3) AS ratio
FROM
(SELECT b.LEVEL AS LEVEL,
(CASE
WHEN a.score >= 90 THEN '优'
WHEN a.score < 90
AND a.score >= 75 THEN '良'
WHEN a.score < 75
AND a.score >= 60 THEN '中'
ELSE '差'
END) AS score_grade,
count(1) AS cur_count
FROM exam_record a
LEFT JOIN user_info b ON a.uid = b.uid
WHERE a.submit_time IS NOT NULL
GROUP BY b.LEVEL,
score_grade) a
LEFT JOIN
(SELECT b.LEVEL AS LEVEL,
count(b.LEVEL) AS total_num
FROM exam_record a
LEFT JOIN user_info b ON a.uid = b.uid
WHERE a.submit_time IS NOT NULL
GROUP BY b.LEVEL) b ON a.LEVEL = b.LEVEL
ORDER BY a.LEVEL DESC,
ratio DESC限量查询
注册时间最早的三个人
描述:
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-02-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-02 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 5 | 1005 | 牛客 555 号 | 4000 | 7 | C++ | 2020-01-11 10:00:00 |
| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-11-01 10:00:00 |
请从中找到注册时间最早的 3 个人。由示例数据结果输出如下:
| uid | nick_name | register_time |
|---|---|---|
| 1001 | 牛客 1 | 2020-01-01 10:00:00 |
| 1003 | 牛客 3 号 ♂ | 2020-01-02 10:00:00 |
| 1004 | 牛客 4 号 | 2020-01-02 11:00:00 |
解释:按注册时间排序后选取前三名,输出其用户 ID、昵称、注册时间。
答案:
SELECT uid, nick_name, register_time
FROM user_info
ORDER BY register_time
LIMIT 3注册当天就完成了试卷的名单第三页(较难)
描述:现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 10:00:00 |
| 5 | 1005 | 牛客 555 号 | 4000 | 7 | 算法 | 2020-01-11 10:00:00 |
| 6 | 1006 | 牛客 6 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 7 | 1007 | 牛客 7 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 8 | 1008 | 牛客 8 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 9 | 1009 | 牛客 9 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 10 | 1010 | 牛客 10 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
| 11 | 1011 | 666666 | 3000 | 6 | C++ | 2020-01-02 10:00:00 |
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | 算法 | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
| 3 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
| 4 | 1003 | 9002 | 2020-01-01 19:01:01 | 2020-01-01 19:30:01 | 75 |
| 5 | 1004 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:11:01 | 60 |
| 6 | 1005 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:41:01 | 90 |
| 7 | 1006 | 9001 | 2020-01-02 19:01:01 | 2020-01-02 19:32:00 | 20 |
| 8 | 1007 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
| 9 | 1008 | 9003 | 2020-01-02 12:01:01 | 2020-01-02 12:20:01 | 99 |
| 10 | 1008 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 98 |
| 11 | 1009 | 9002 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 82 |
| 12 | 1010 | 9002 | 2020-01-02 12:11:01 | 2020-01-02 12:41:01 | 76 |
| 13 | 1011 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
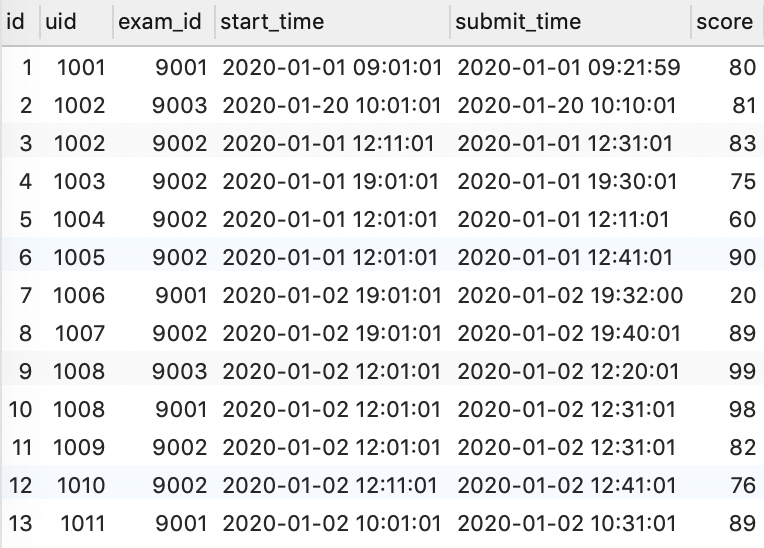
找到求职方向为算法工程师,且注册当天就完成了算法类试卷的人,按参加过的所有考试最高得分排名。排名榜很长,我们将采用分页展示,每页 3 条,现在需要你取出第 3 页(页码从 1 开始)的人的信息。
由示例数据结果输出如下:
| uid | level | register_time | max_score |
|---|---|---|---|
| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
解释:除了 1011 其他用户的求职方向都为算法工程师;算法类试卷有 9001 和 9002,11 个用户注册当天都完成了算法类试卷;计算他们的所有考试最大分时,只有 1002 和 1008 完成了两次考试,其他人只完成了一场考试,1002 两场考试最高分为 81,1008 最高分为 99。
按最高分排名如下:
| uid | level | register_time | max_score |
|---|---|---|---|
| 1008 | 0 | 2020-01-02 11:00:00 | 99 |
| 1005 | 7 | 2020-01-01 10:00:00 | 90 |
| 1007 | 0 | 2020-01-02 11:00:00 | 89 |
| 1002 | 3 | 2020-01-01 10:00:00 | 83 |
| 1009 | 0 | 2020-01-02 11:00:00 | 82 |
| 1001 | 0 | 2020-01-01 10:00:00 | 80 |
| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
| 1006 | 0 | 2020-01-02 11:00:00 | 20 |
每页 3 条,第三页也就是第 7~9 条,返回 1010、1003、1004 的行记录即可。
思路:
每页三条,即需要取出第三页的人的信息,要用到
limit统计求职方向为算法工程师且注册当天就完成了算法类试卷的人的信息和每次记录的得分,先求满足条件的用户,后用 left join 做连接查找信息和每次记录的得分
答案:
SELECT t1.uid,
LEVEL,
register_time,
max(score) AS max_score
FROM exam_record t
JOIN examination_info USING (exam_id)
JOIN user_info t1 ON t.uid = t1.uid
AND date(t.submit_time) = date(t1.register_time)
WHERE job = '算法'
AND tag = '算法'
GROUP BY t1.uid,
LEVEL,
register_time
ORDER BY max_score DESC
LIMIT 6,3文本转换函数
修复串列了的记录
描述:现有试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | 算法 | hard | 60 | 2021-01-01 10:00:00 |
| 2 | 9002 | 算法 | hard | 80 | 2021-01-01 10:00:00 |
| 3 | 9003 | SQL | medium | 70 | 2021-01-01 10:00:00 |
| 4 | 9004 | 算法,medium,80 | 0 | 2021-01-01 10:00:00 |
录题同学有一次手误将部分记录的试题类别 tag、难度、时长同时录入到了 tag 字段,请帮忙找出这些录错了的记录,并拆分后按正确的列类型输出。
由示例数据结果输出如下:
| exam_id | tag | difficulty | duration |
|---|---|---|---|
| 9004 | 算法 | medium | 80 |
思路:
先来学习下本题要用到的函数
SUBSTRING_INDEX 函数用于提取字符串中指定分隔符的部分。它接受三个参数:原始字符串、分隔符和指定要返回的部分的数量。
以下是 SUBSTRING_INDEX 函数的语法:
SUBSTRING_INDEX(str, delimiter, count)str:要进行分割的原始字符串。delimiter:用作分割的字符串或字符。count:指定要返回的部分的数量。- 如果
count大于 0,则返回从左边开始的前count个部分(以分隔符为界)。 - 如果
count小于 0,则返回从右边开始的前count个部分(以分隔符为界),即从右侧向左计数。
- 如果
下面是一些示例,演示了 SUBSTRING_INDEX 函数的使用:
提取字符串中的第一个部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 1); -- 输出结果:'apple'提取字符串中的最后一个部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -1); -- 输出结果:'cherry'提取字符串中的前两个部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 2); -- 输出结果:'apple,banana'提取字符串中的最后两个部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -2); -- 输出结果:'banana,cherry'
答案:
SELECT
exam_id,
substring_index( tag, ',', 1 ) tag,
substring_index( substring_index( tag, ',', 2 ), ',',- 1 ) difficulty,
substring_index( tag, ',',- 1 ) duration
FROM
examination_info
WHERE
difficulty = ''对过长的昵称截取处理
描述:现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客 1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
| 4 | 1004 | 牛客 4 号 | 25 | 0 | 算法 | 2020-01-01 11:00:00 |
| 5 | 1005 | 牛客 5678901234 号 | 4000 | 7 | 算法 | 2020-01-11 10:00:00 |
| 6 | 1006 | 牛客 67890123456789 号 | 25 | 0 | 算法 | 2020-01-02 11:00:00 |
有的用户的昵称特别长,在一些展示场景会导致样式混乱,因此需要将特别长的昵称转换一下再输出,请输出字符数大于 10 的用户信息,对于字符数大于 13 的用户输出前 10 个字符然后加上三个点号:『...』。
由示例数据结果输出如下:
| uid | nick_name |
|---|---|
| 1005 | 牛客 5678901234 号 |
| 1006 | 牛客 67890123... |
解释:字符数大于 10 的用户有 1005 和 1006,长度分别为 13、17;因此需要对 1006 的昵称截断输出。
思路:
这题涉及到字符的计算,要计算字符串的字符数(即字符串的长度),可以使用 LENGTH 函数或 CHAR_LENGTH 函数。这两个函数的区别在于对待多字节字符的方式。
LENGTH函数:它返回给定字符串的字节数。对于包含多字节字符的字符串,每个字符都会被当作一个字节来计算。
示例:
SELECT LENGTH('你好'); -- 输出结果:6,因为 '你好' 中的每个汉字每个占3个字节CHAR_LENGTH函数:它返回给定字符串的字符数。对于包含多字节字符的字符串,每个字符会被当作一个字符来计算。
示例:
SELECT CHAR_LENGTH('你好'); -- 输出结果:2,因为 '你好' 中有两个字符,即两个汉字答案:
SELECT
uid,
CASE
WHEN CHAR_LENGTH( nick_name ) > 13 THEN
CONCAT( SUBSTR( nick_name, 1, 10 ), '...' ) ELSE nick_name
END AS nick_name
FROM
user_info
WHERE
CHAR_LENGTH( nick_name ) > 10
GROUP BY
uid;大小写混乱时的筛选统计(较难)
描述:
现有试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | 算法 | hard | 60 | 2021-01-01 10:00:00 |
| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 3 | 9003 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 4 | 9004 | sql | medium | 70 | 2021-01-01 10:00:00 |
| 5 | 9005 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 6 | 9006 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 7 | 9007 | C++ | hard | 80 | 2021-01-01 10:00:00 |
| 8 | 9008 | SQL | medium | 70 | 2021-01-01 10:00:00 |
| 9 | 9009 | SQL | medium | 70 | 2021-01-01 10:00:00 |
| 10 | 9010 | SQL | medium | 70 | 2021-01-01 10:00:00 |
试卷作答信息表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 80 |
| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
| 3 | 1002 | 9002 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
| 4 | 1003 | 9002 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
| 5 | 1004 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
| 6 | 1005 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
| 7 | 1006 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 20 |
| 8 | 1007 | 9003 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
| 9 | 1008 | 9004 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
| 10 | 1008 | 9001 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 98 |
| 11 | 1009 | 9002 | 2020-02-02 12:01:01 | 2020-01-02 12:43:01 | 81 |
| 12 | 1010 | 9001 | 2020-01-02 12:11:01 | (NULL) | (NULL) |
| 13 | 1010 | 9001 | 2020-02-02 12:01:01 | 2020-01-02 10:31:01 | 89 |
试卷的类别 tag 可能出现大小写混乱的情况,请先筛选出试卷作答数小于 3 的类别 tag,统计将其转换为大写后对应的原本试卷作答数。
如果转换后 tag 并没有发生变化,不输出该条结果。
由示例数据结果输出如下:
| tag | answer_cnt |
|---|---|
| C++ | 6 |
解释:被作答过的试卷有 9001、9002、9003、9004,他们的 tag 和被作答次数如下:
| exam_id | tag | answer_cnt |
|---|---|---|
| 9001 | 算法 | 4 |
| 9002 | C++ | 6 |
| 9003 | c++ | 2 |
| 9004 | sql | 2 |
作答次数小于 3 的 tag 有 c++和 sql,而转为大写后只有 C++本来就有作答数,于是输出 c++转化大写后的作答次数为 6。
思路:
首先,这题有点混乱,9004 根据示例数据查出来只有 1 次,这里显示有 2 次。
先看一下大小写转换函数:
1.UPPER(s)或UCASE(s)函数可以将字符串 s 中的字母字符全部转换成大写字母;
2.LOWER(s)或者LCASE(s)函数可以将字符串 s 中的字母字符全部转换成小写字母。
难点在于相同表做连接要查询不同的值
答案:
WITH a AS
(SELECT tag,
COUNT(start_time) AS answer_cnt
FROM exam_record er
JOIN examination_info ei ON er.exam_id = ei.exam_id
GROUP BY tag)
SELECT a.tag,
b.answer_cnt
FROM a
INNER JOIN a AS b ON UPPER(a.tag)= b.tag #a小写 b大写
AND a.tag != b.tag
WHERE a.answer_cnt < 3;写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。