Raft 算法详解:Leader 选举、日志复制、安全性与成员变更
本文由 SnailClimb 和 Xieqijun 共同完成。
1 背景
在如今的互联网架构中,为了扛住海量流量,系统往往需要横向堆机器。机器一多,宕机、断网这些破事就成了家常便饭。怎么让这群随时可能掉线的服务器保持步调一致,不对外提供错乱的数据?这就轮到分布式共识算法出场了。
2014年,Diego Ongaro 等人发表了 Raft 算法。它的诞生有一个很明确的使命:拯救被 Paxos 算法折磨的程序员。Raft 主打一个“易于理解”,它将复杂的共识问题拆解成了几个独立的模块:
- Leader 选举:使用随机化选举超时(工程上常见如 150–300ms 或更大范围,具体取决于网络与故障模型)。
- 日志复制:Leader 通过 AppendEntries RPC 广播日志。
- 安全性:包括选举限制和日志匹配。
Raft 在实际生产中得到了广泛应用,基于 Raft 的实现如 etcd、Consul 等已成为分布式系统的重要组成部分。后续学术界和工业界也对 Raft 进行了多项扩展和优化,包括:
- Pre-Vote(2014):防止网络分区的节点干扰稳定集群的选举
- Read Index(2014):在 Leader 任期内通过线性一致性读优化读性能
- Lease Read:基于租约的线性一致性读方案
- Joint Consensus:用于集群成员变更的联合一致机制(通过引入过渡配置,典型过程为旧配置 → 联合配置 → 新配置)
因此,系统必须在正常操作期间处理服务器的上下线。它们必须对变故做出反应并在几秒钟内自动适应;对客户来说的话,明显的中断通常是不可接受的。
幸运的是,分布式共识可以帮助应对这些挑战。
1.1 非拜占庭条件下的“选主”类比
Raft 有一个前提假设:非拜占庭容错(CFT)。说白了就是,兄弟们可能会死机、会断网,但绝对不会出内鬼传递假情报。
我们可以用“将军选帅”来粗略理解这个过程: 假设有 A、B、C 三个将军,目前群龙无首。每个人心里都有个随机的倒计时(选举超时)。谁的倒计时先结束,谁就站出来大喊:“我要当大将军,请给我投票!” 如果其他将军还没开始竞选,也没把票投给别人,就会顺水推舟同意他。当这位将军拿到过半数的赞成票,他就成了大当家(Leader)。以后打不打仗,全听他的。如果信使半路阵亡,大家都没收到回音,那就重置倒计时,再来一轮。
1.2 到底什么是共识算法?
共识算法的核心目标,就是让一群机器看起来像一台机器。只要集群里超过半数的机器还活着,整个系统就能正常接客。
这通常是通过复制状态机来实现的:给每个节点发一本一模一样的账本(日志)。只要大家按照同样的顺序去执行账本上的命令,最后得到的结果自然完全一样。所以,共识算法本质上干的就是一件事——保证所有节点的账本绝对一致。共识是可容错系统中的一个基本问题:即使面对故障,服务器也可以在共享状态上达成一致。
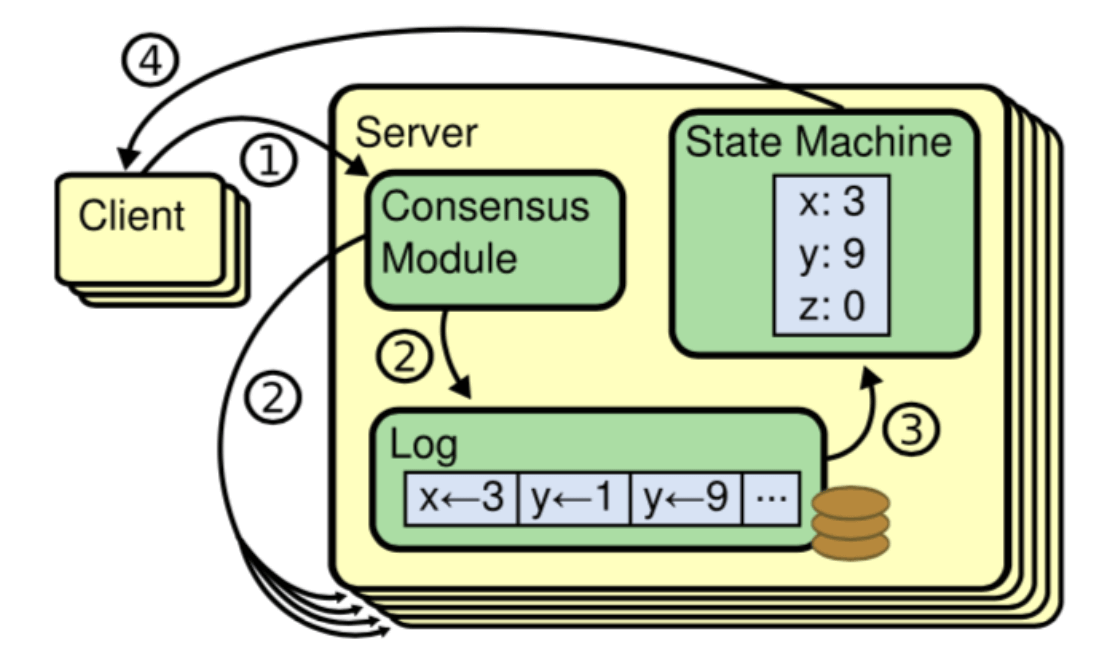
2 基础概念
在深入 Raft 之前,我们得先认识里面的三大核心角色、任期机制和日志结构。
2.1 节点类型
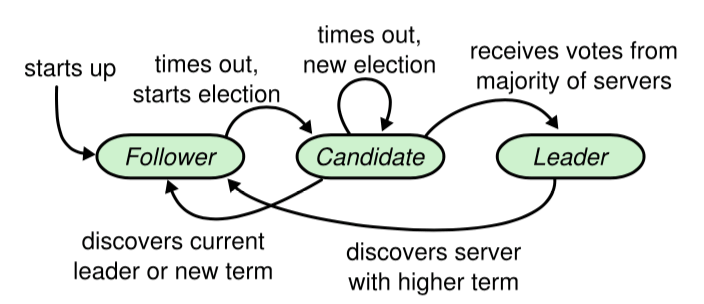
一个 Raft 集群包括若干服务器,以典型的 5 服务器集群举例。在任意的时间,每个服务器一定会处于以下三个状态中的一个:
- Leader(领导者):大当家。全权负责接待客户端、写账本、并把账本同步给小弟。为了防止别人篡位,他必须不断地向全员发送心跳,宣告“我还活着”。
- Follower(跟随者):安分守己的小弟。平时绝对不主动发起请求,只被动接收老大的心跳和账本同步。
- Candidate(候选人):临时状态。如果小弟迟迟等不到老大的心跳,就会觉得自己行了,变身候选人开始拉票。
在正常的情况下,只有一个服务器是 Leader,剩下的服务器是 Follower。Follower 是被动的,它们不会发送任何请求,只是响应来自 Leader 和 Candidate 的请求。
2.2 任期
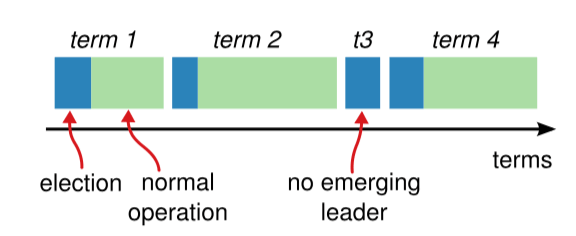
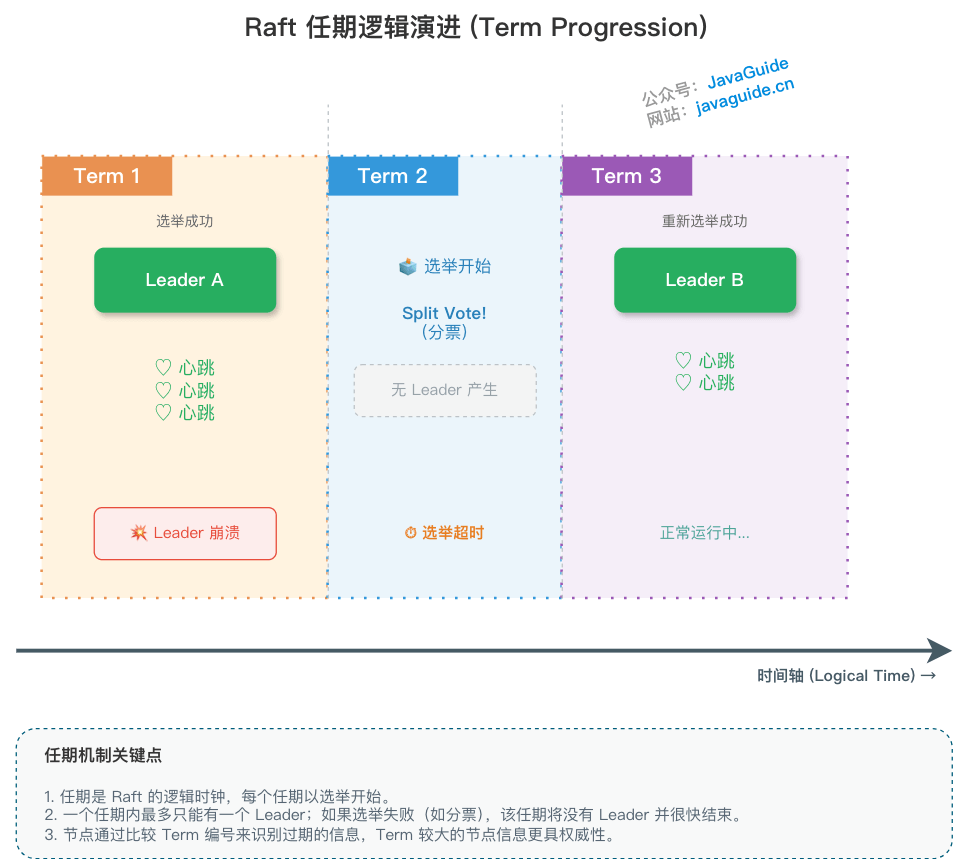
Raft 算法将时间划分为任意长度的任期(term),任期用连续的数字表示,看作当前 term 号。每一个任期的开始都是一次选举,在选举开始时,一个或多个 Candidate 会尝试成为 Leader。如果一个 Candidate 赢得了选举,它就会在该任期内担任 Leader。如果没有选出 Leader(例如出现分票 split vote),该任期可能没有 Leader;随后在新的选举超时后会进入下一个任期并重新发起选举。只要多数节点可用且网络最终可达,系统通常能够在若干轮选举后选出 Leader。
每个节点都会存储当前的 term 号,当服务器之间进行通信时会交换当前的 term 号;如果有服务器发现自己的 term 号比其他人小,那么他会更新到较大的 term 值。如果一个 Candidate 或者 Leader 发现自己的 term 过期了,他会立即退回成 Follower。如果一台服务器收到的请求的 term 号是过期的,那么它会拒绝此次请求。
下面这张图是我手绘的,更容易理解一些,就很贴心:
2.3 日志
只有 Leader 有资格往账本里追加记录(Entry)。一条日志包含三个核心要素:<当前任期, 索引号, 具体操作指令>。
这里有两个非常关键的进度指针:
- commitIndex:大家公认已经安全落地的日志进度(已经被复制到过半数节点)。
- lastApplied:这台机器本地真正执行完的日志进度。
3 领导人选举
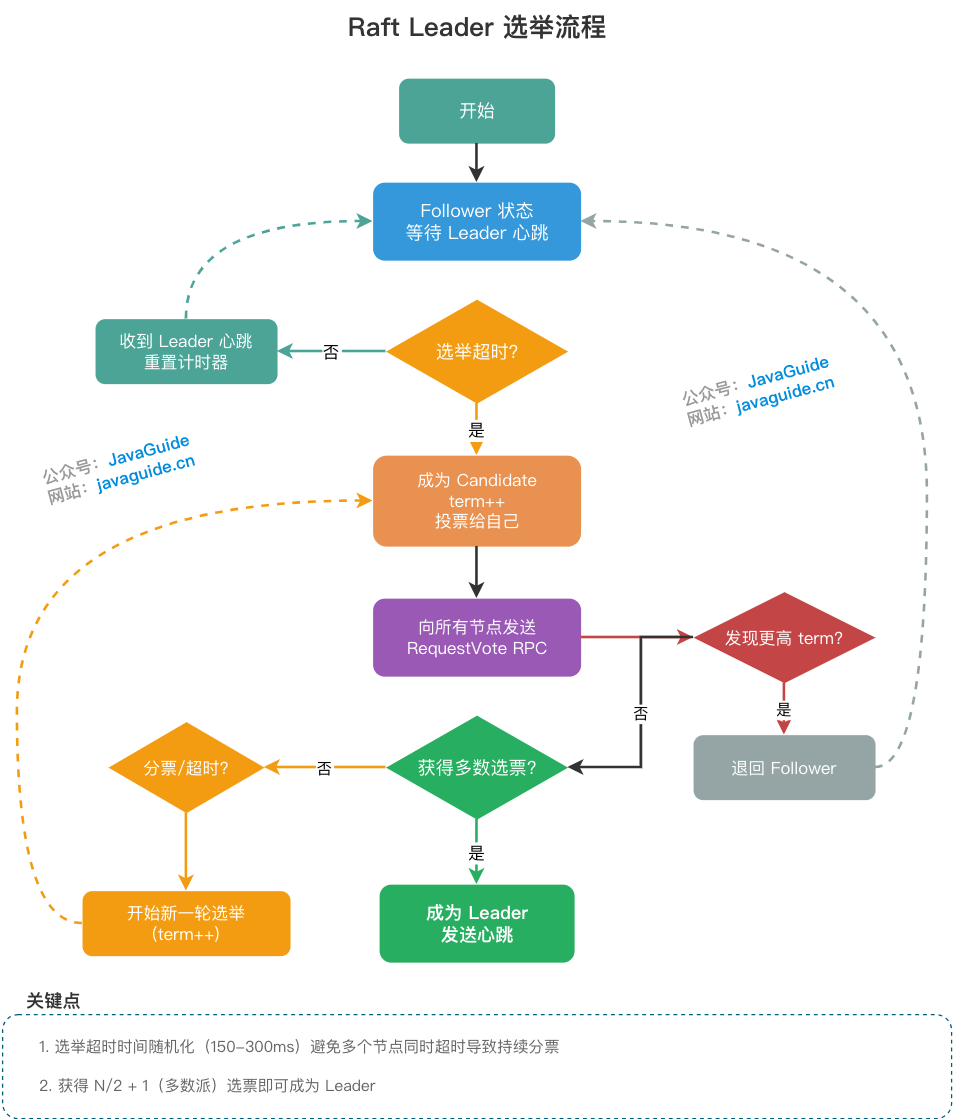
Raft 使用心跳机制来触发 Leader 的选举。
如果一台服务器持续收到来自 Leader 的 AppendEntries(心跳或日志复制)等合法 RPC,它会保持为 Follower 状态并刷新选举计时器。
Leader 会向所有的 Follower 周期性发送心跳来保证自己的 Leader 地位。如果一个 Follower 在一个周期内没有收到心跳信息,就叫做选举超时,然后它就会认为此时没有可用的 Leader,并且开始进行一次选举以选出一个新的 Leader。
为了开始新的选举,Follower 会自增自己的 term 号并且转换状态为 Candidate。然后他会向所有节点发起 RequestVote RPC 请求, Candidate 的状态会持续到以下情况发生:
- 赢得选举
- 其他节点赢得选举
- 一轮选举结束,无人胜出
赢得选举的条件是:一个 Candidate 在一个任期内收到了来自集群内的多数选票(N/2+1),就可以成为 Leader。
在 Candidate 等待选票的时候,它可能收到其他节点声明自己是 Leader 的心跳,此时有两种情况:
- 该 Leader 的 term 号大于等于自己的 term 号,说明对方已经成为 Leader,则自己回退为 Follower。
- 该 Leader 的 term 号小于自己的 term 号,那么会拒绝该请求并让该节点更新 term。
由于可能同一时刻出现多个 Candidate,导致没有 Candidate 获得大多数选票,如果没有其他手段来重新分配选票的话,那么可能会无限重复下去。
Raft 使用了随机的选举超时时间来避免上述情况。每一个 Candidate 在发起选举后,都会随机化一个新的选举超时时间,这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时;它会在其他服务器超时之前赢得选举。
4 日志复制
一旦选出了 Leader,它就开始接受客户端的请求。每一个客户端的请求都包含一条需要被复制状态机(Replicated State Machine)执行的命令。
Leader 收到客户端请求后,会生成一个 entry,包含<index,term,cmd>,再将这个 entry 添加到自己的日志末尾后,向所有的节点广播该 entry,要求其他服务器复制这条 entry。
如果 Follower 接受该 entry,则会将 entry 添加到自己的日志后面,同时返回给 Leader 同意。
如果 Leader 收到了多数 Follower 对该日志复制成功的响应,Leader 会推进自己的 commitIndex,并在随后将这些已提交(committed)的日志按顺序应用(apply)到状态机后再向客户端返回结果。
需要注意一个关键限制:Leader 只能基于“当前任期(current term)内产生的日志在多数派上复制成功”来推进 commitIndex。对于之前任期遗留的日志,即使它们已经被复制到多数节点,Leader 也不应仅凭多数派直接提交;通常会通过提交当前任期的一条新日志(常见做法是当选后追加并提交一条 no-op 日志)来间接推动历史日志一并提交。
Follower 不会自行决定提交点;它们从 Leader 的 AppendEntries RPC 中携带的 leaderCommit 得知当前可提交的最大索引,并将本地 commitIndex 更新为 min(leaderCommit, lastLogIndex),再按序 apply 到状态机。
4.1 日志匹配属性(Log Matching Property)
Raft 通过 日志匹配属性(Log Matching Property) 保证日志绝对不会分叉,这是 Raft 安全性的基石之一。该属性包含两个核心保证:
- 保证一:如果两个日志在相同 index 位置的 entry 具有相同的 term,那么它们存储的 cmd 一定相同
- 保证二:如果两个日志在相同 index 位置的 entry 具有相同的 term,那么该位置之前的所有 entry 也完全相同
归纳法证明
日志匹配属性通过归纳法得以保证:
- 基础情况:日志为空时,属性自然成立
- 归纳步骤:假设日志在 index N 之前完全一致,当 Leader 尝试追加 entry N+1 时,通过 AppendEntries RPC 的一致性检查 确保:
AppendEntries RPC 参数:
- prevLogIndex:前一条日志的索引(Leader 认为与 Follower 对齐的位置)
- prevLogTerm:前一条日志的任期
- entries[]:待追加的新日志条目一致性检查逻辑:
- Follower 收到 AppendEntries 请求后,检查本地日志中 index = prevLogIndex 的位置
- 如果该位置的 entry.term == prevLogTerm,说明Leader和Follower在prevLogIndex之前的日志完全一致,通过检查
- 如果不存在或 term 不匹配,拒绝追加,返回失败
关键点:通过检查 prevLogIndex 和 prevLogTerm 的配对,Leader 和 Follower 能够数学上确保它们对日志历史达成一致。只有当“最后一个已知一致点”确实一致时,才会追加新日志。这形成了归纳证明的传递链条:
entry[0] 一致 → entry[1] 一致 → entry[2] 一致 → ... → entry[N] 一致
↑_____________通过 prevLogIndex/prevLogTerm 递归验证_____________↑因此,日志绝不会出现两个不同的值在同一 index 位置被“提交”的情况——即日志不分叉。
工程实现优化
在实际生产实现(如 etcd 3.5.x)中,除了上述基础的一致性检查外,还包含多项工程优化:
快速回退(Fast Backup):当 AppendEntries 一致性检查失败时,Follower 返回冲突日志对应的 term 及其边界索引(该 term 的第一条和最后一条 index),Leader 据此一次性跳过整段冲突区间,而非逐条递减 nextIndex 重试。
重试风暴防护:高负载下可能出现大量 AppendEntries 失败重试,实现中通常会加入:
- Jitter 退避:重试间隔加入随机抖动,避免多个 Follower 同时重试
- 背压机制:限制单个 Follower 的重试速率,防止占用过多网络带宽
这些优化不影响日志匹配属性的理论正确性,而是提升了系统在异常场景下的恢复效率。
4.2 日志不一致的恢复
正常运作时,大当家(Leader)和小弟(Follower)的账本是完全同步的。然而,一旦老 Leader 突然宕机,新老交替之际往往会在集群中遗留大量未对齐的脏数据。
这时,新 Leader 发起 AppendEntries 同步请求就会触发“一致性检查报错”。Raft 解决数据冲突的逻辑非常霸道:一切以现任 Leader 的账本为最高准则,Follower 本地任何不一致的记录都必须被无情抹除并强行覆盖。
具体怎么做呢?Leader 会像“拉链”一样顺藤摸瓜,往前倒推寻找双方最后一次完美吻合的历史节点。找到这个“分叉点”后,Follower 会把分叉点之后的烂摊子全部咔嚓掉,老老实实地拷贝 Leader 提供的最新日志。
在代码层面,Leader 会在内存里给每个 Follower 单独记一本账,核心指针叫 nextIndex(预估要发给该小弟的下一条日志位置)。新官上任三把火,Leader 刚接盘时,会盲目自信地把所有小弟的 nextIndex 都预设为自己最新日志的索引加一。如果小弟的数据其实比较落后或者有冲突,第一发 AppendEntries 必然惨遭拒绝。接下来就是找分叉点的两种流派:
- 传统的朴素做法(逐条试探):撞了南墙就退一步。Leader 会把
nextIndex减一,再发一次 RPC 试探。如果还不行,就继续减一,犹如乌龟漫步般逐条往前回退,直到彻底对上暗号。 - 工业级提速优化(Fast Backup 快速回退):在真实的生产环境中,逐条回退绝对是性能灾难。因此,工业界引入了快速回退机制。小弟在拒绝同步时不再是单纯地摇摇头,而是直接亮出底牌:“我这批错乱日志属于哪个历史任期(term),以及这个任期的头尾边界在哪里”。Leader 拿到这份情报,直接大刀阔斧地一次性跨越整段错误任期,极大地削减了冗余的网络重试次数。
经过这番拉扯,nextIndex 终将精准锚定双方的共识起点。此时,AppendEntries 终于收获成功回执,Follower 上的冲突数据被彻底清空,缺失的正统日志被严丝合缝地填补。一旦跨过这个坎,双方的账本就能在整个任期内保持如影随形、高度一致。
5 安全性
5.1 选举限制
Leader 需要保证自己存储全部已经提交的日志条目。这样才可以使日志条目只有一个流向:从 Leader 流向 Follower,Leader 永远不会覆盖已经存在的日志条目。
每个 Candidate 发送 RequestVote RPC 时,都会带上最后一个 entry 的信息。所有节点收到投票信息时,会对该 entry 进行比较,如果发现自己的更新,则拒绝投票给该 Candidate。
判断日志新旧的方式:如果两个日志的 term 不同,term 大的更新;如果 term 相同,更长的 index 更新。
5.2 提交规则(只提交当前任期日志)
Leader 推进 commitIndex 时,需要满足“当前任期产生的某条日志已复制到多数派”这一条件。对于旧任期遗留的日志,即使它们已经复制到多数派,Leader 也不应仅凭此直接提交;通常通过提交当前任期的一条新日志(常见为 no-op)来间接提交历史日志。这一限制用于避免 Leader 频繁切换时出现已提交日志被覆盖的安全性问题。
5.3 节点崩溃与网络分区
如果 Follower 和 Candidate 崩溃,处理方式会简单很多。之后发送给它的 RequestVote RPC 和 AppendEntries RPC 会失败。由于 Raft 的所有请求都是幂等的,所以失败的话会无限的重试。如果崩溃恢复后,就可以收到新的请求,然后选择追加或者拒绝 entry。
如果 Leader 崩溃,节点在 electionTimeout 内收不到心跳会触发新一轮选主;在选主完成前,系统通常无法对外提供线性一致的写入(以及线性一致读),表现为一段不可用窗口。
量化分析:在 5 节点集群中,Leader 崩溃后的不可用窗口通常小于 1 秒(P99 < 500ms 选举超时 + 一轮选举时间)。这是 PACELC 定理的体现:发生分区(P)时,系统选择牺牲可用性(A)以保证一致性(C)。幂等重试机制确保节点恢复后能安全追赶数据状态。
单节点隔离与 Term 暴增问题
在标准 Raft 算法中,单节点网络隔离可能导致 Term 暴增(Term Inflation) 问题,造成“劣币驱逐良币”——一个被隔离的少数派节点在恢复后破坏健康集群的稳定性。
场景推演:
假设一个 5 节点集群,Leader 为节点 A,Follower 为 B、C、D、E。此时节点 E 发生网络分区,被彻底隔离:
正常区域:{A, B, C, D} (Leader A + 多数派,可正常服务)
隔离区域:{E} (单节点隔离,无法收到心跳)| 时间线 | 正常区域 {A, B, C, D} | 隔离区域 {E} |
|---|---|---|
| T0 | Leader A 正常服务,Term = 5 | E 收不到心跳,选举超时 |
| T1 | 集群继续正常工作 | E 自增 Term 发起选举(Term 6),但无响应 |
| T2 | ... | E 继续自增(Term 7, 8, ...),假设涨到 Term 99 |
| T3 | 网络恢复,E 带着 Term 99 接入集群 | E 向 {A, B, C, D} 广播 RequestVote (Term 99) |
| T4 | 节点 A 收到 Term 99 > 自己的 Term 5,被迫退位 | E 的“高 Term”破坏了健康集群 |
问题分析:
- {A, B, C, D} 是合法的多数派(4/5),系统本应继续正常工作
- 节点 E 是少数派(1/5),它的隔离不应影响集群整体
- 关键问题:E 的 Term 暴涨导致健康的 Leader A 被迫下线
- 后果:整个集群需要重新选举,造成不必要的写入中断
这是标准 Raft 的一个已知边界问题:少数派节点的“疯狂选举”会干扰多数派的正常运行。
Pre-Vote 机制
为了解决上述问题,Raft 的扩展方案 Pre-Vote 被提出。Pre-Vote 要求节点在真正发起选举前,先进行一次“预投票”:
- 预投票阶段:Candidate 向其他节点发送 PreVoteRequest,携带自己的日志信息
- 预投票条件:
- 候选人的日志至少与接收者一样新(选举限制)
- 接收者确认自己与 Leader 的连接已断开(超过 electionTimeout 未收到心跳)
- 正式选举:只有收到多数节点的 PreVote 响应后,才真正增加 term 并发起 RequestVote
Pre-Vote 如何防止 Term 暴增:
- 在上述单节点隔离场景中,E 在隔离期间发起 Pre-Vote 时,其他节点仍能收到 Leader A 的心跳
- 因此其他节点会拒绝 E 的 PreVote 请求(因为与 Leader 连接正常)
- E 无法获得多数 PreVote 响应,不会真正增加 Term
- 网络恢复后,E 的 Term 仍然较低,不会干扰健康的 Leader A
核心思想:只有确认自己与 Leader 失去连接后,节点才开始真正增加 Term。这有效防止了少数派节点的 Term 暴涨干扰多数派。
Pre-Vote 机制已广泛应用于 etcd、TiKV、Consul 等生产级 Raft 实现。
5.4 时间与可用性
Raft 的要求之一就是安全性不依赖于时间:系统不能仅仅因为一些事件发生的比预想的快一些或者慢一些就产生错误。为了保证上述要求,最好能满足以下的时间条件:
broadcastTime << electionTimeout << MTBF
broadcastTime:向其他节点并发发送消息的平均响应时间;electionTimeout:选举超时时间;MTBF(mean time between failures):单台机器的平均健康时间;
broadcastTime应该比electionTimeout小一个数量级,为的是使Leader能够持续发送心跳信息(heartbeat)来阻止Follower开始选举;
electionTimeout也要比MTBF小几个数量级,为的是使得系统稳定运行。当Leader崩溃时,大约会在整个electionTimeout的时间内不可用;我们希望这种情况仅占全部时间的很小一部分。
由于broadcastTime和MTBF是由系统决定的属性,因此需要决定electionTimeout的时间。
一般来说,broadcastTime 一般为 0.5~20ms,electionTimeout 可以设置为 10~500ms(工程上常见如 150–300ms),MTBF 一般为一两个月。
6 参考
- https://tanxinyu.work/raft/
- https://github.com/OneSizeFitsQuorum/raft-thesis-zh_cn/blob/master/raft-thesis-zh_cn.md
- https://github.com/ongardie/dissertation/blob/master/stanford.pdf
- https://knowledge-sharing.gitbooks.io/raft/content/chapter5.html
写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。