2026 最新高可用系统设计面试题总结:SLA、限流熔断、重试幂等与容灾
这部分内容摘自 JavaGuide 下面几篇文章的重点:
高可用设计:
限流、降级、熔断:
超时、重试、幂等:
高可用基础
⭐️什么是高可用?
高可用(High Availability)指系统在面对机器故障、网络抖动、依赖异常、流量突增等情况时,仍然能够尽可能持续提供服务。
它不是追求系统永远不出故障,而是关注 3 件事:
- 故障尽量少发生:通过测试、评审、容量规划、灰度发布降低故障概率。
- 故障发生后影响尽量小:通过隔离、限流、降级、熔断控制故障范围。
- 故障发生后恢复尽量快:通过监控、告警、预案、自动故障转移缩短恢复时间。
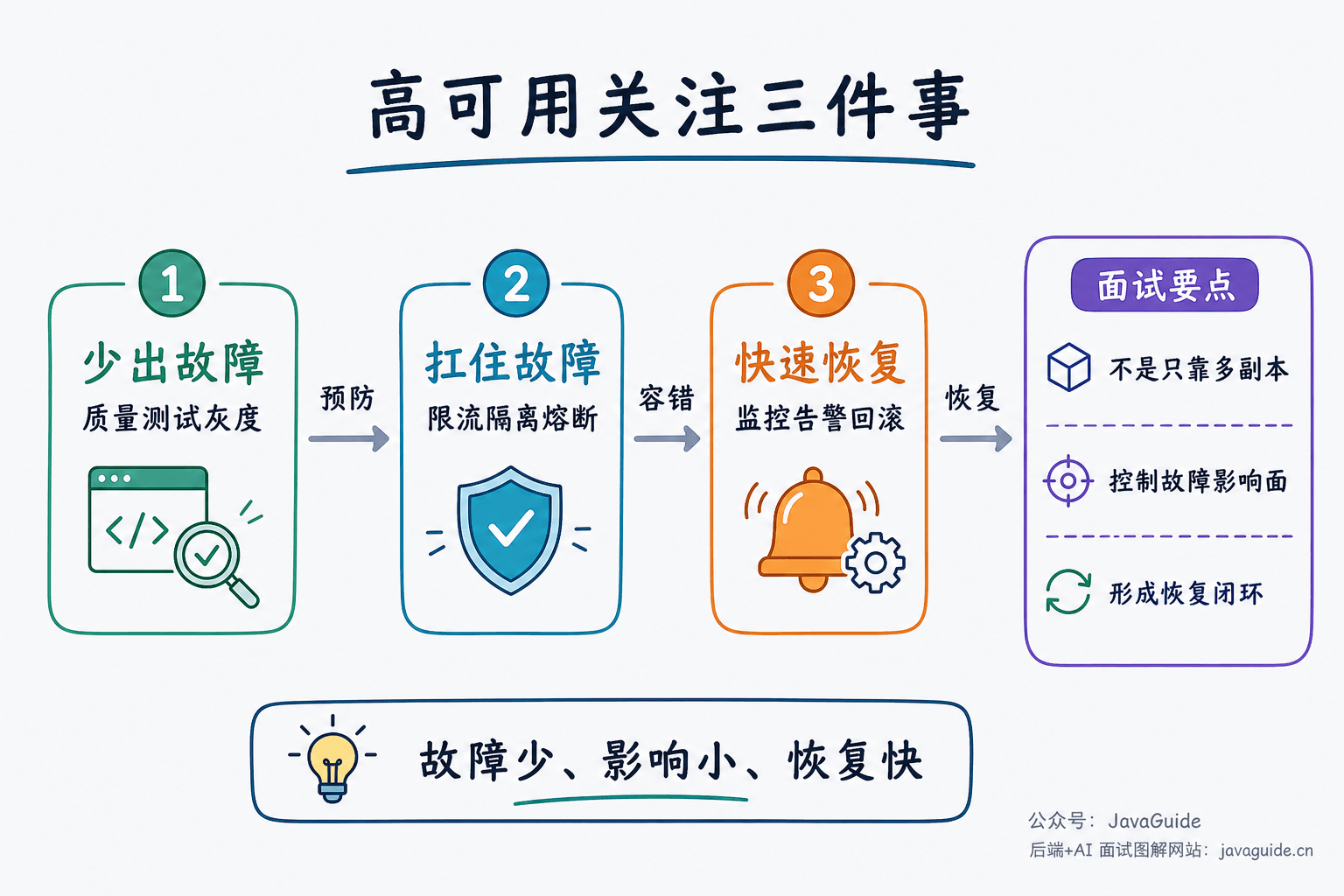
面试里不要把高可用理解成"多部署几台机器"。多副本只能减少单点故障,但真正的高可用还要覆盖流量控制、依赖保护、数据安全、故障发现和恢复闭环。
可用性 99.9%、99.99% 分别意味着什么?
可用性通常用一段时间内系统可正常服务的比例衡量。
粗略换算:
| 可用性 | 年不可用时间量级 |
|---|---|
| 99% | 约 3.65 天 |
| 99.9% | 约 8.76 小时 |
| 99.99% | 约 52.56 分钟 |
| 99.999% | 约 5.26 分钟 |
可用性小数点后每多一个 9,背后都意味着更高的架构复杂度、运维成本和故障治理能力。
哪些情况会导致系统不可用?
常见原因包括:
- 代码 Bug。
- 服务器宕机。
- 网络故障。
- 数据库、缓存、MQ 等中间件故障。
- 外部依赖接口异常。
- 流量突增导致资源耗尽。
- 慢 SQL、大事务、线程池打满。
- 发布变更引入问题。
高可用设计的关键,是假设这些问题一定会发生,然后提前设计隔离和恢复机制。
⭐️提高系统可用性的常见方法有哪些?
常见方法包括:
- 提高代码质量,严格测试和 Code Review。
- 使用集群,减少单点故障。
- 做好限流,避免瞬时流量打垮系统。
- 设置合理超时和重试,避免请求无限堆积。
- 使用熔断机制,防止下游故障拖垮上游。
- 做好服务降级,优先保证核心链路。
- 使用异步调用和消息队列削峰。
- 使用缓存降低核心依赖压力。
- 建立监控、告警、压测和故障演练体系。
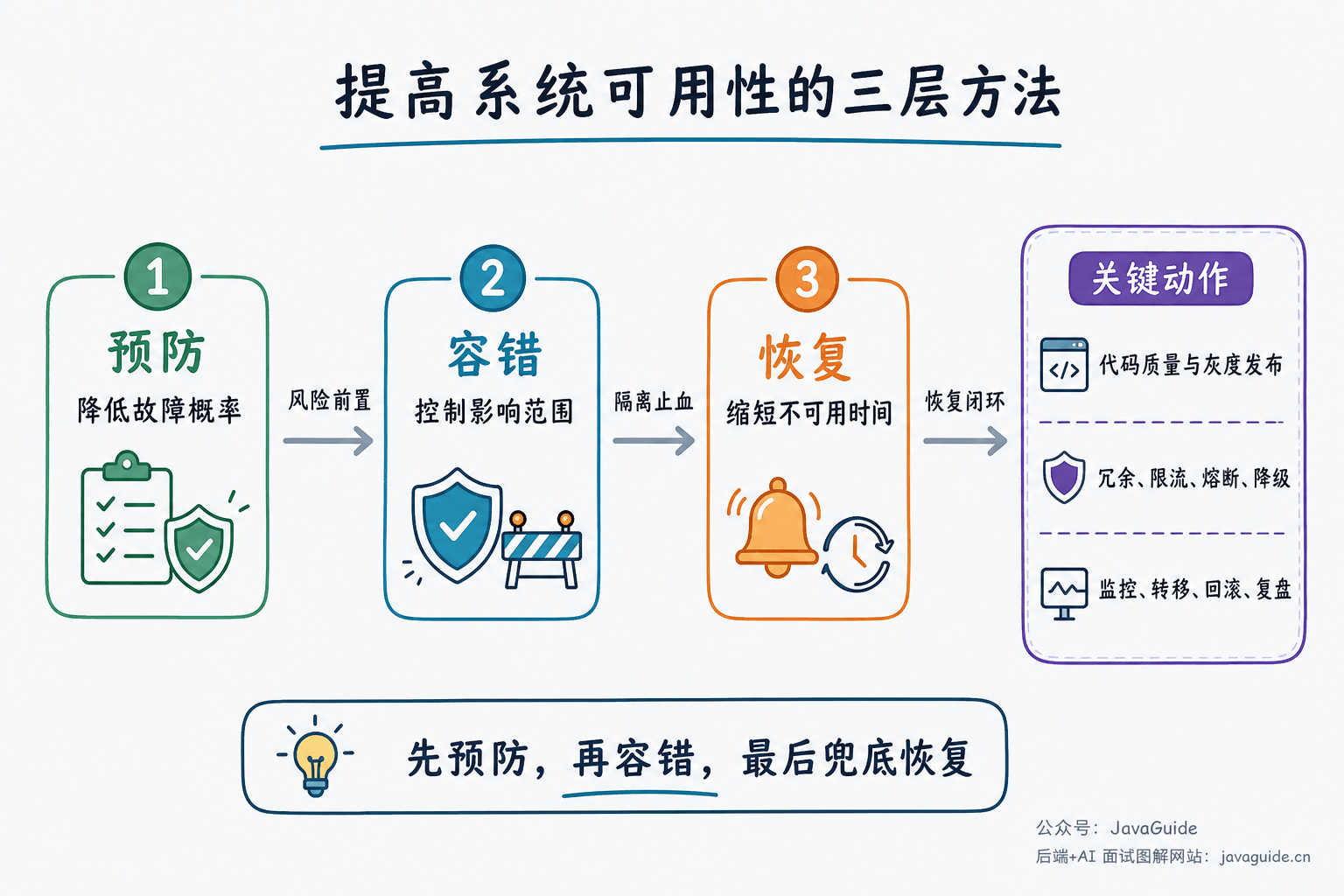
一个比较完整的回答方式是:先按 预防、容错、恢复 三层讲方法,再结合系统实际说明哪些链路是核心链路,哪些功能可以牺牲。
什么是单点故障?如何避免?
单点故障(Single Point of Failure,SPOF) 指系统中某个组件一旦挂掉,整个系统就不可用。
常见单点和对应方案:
| 单点组件 | 解决方案 |
|---|---|
| 应用服务器 | 集群部署 + 负载均衡 |
| 数据库 | 主从复制 + 读写分离 |
| 缓存 | Redis Sentinel / Cluster |
| 消息队列 | 多副本 + 主从切换 |
| 负载均衡 | Keepalived + VIP 漂移 / 多实例 |
| 配置中心 | 集群部署 + 本地缓存兜底 |
| DNS | 多 DNS 服务商 + 本地 DNS 缓存 |
面试中不要只说"多部署几台"。要强调 消除单点的前提是流量能自动切换,光有冗余没有故障检测和切换机制,单点还是单点。
灰度发布是什么?为什么重要?
灰度发布(也叫金丝雀发布 / Canary Release)是指新版本不一次性全量推给所有用户,而是先放一小部分流量验证,确认没问题后再逐步扩大范围。
常见策略:
- 按比例放量:先 1% → 5% → 20% → 50% → 100%。
- 按用户特征放量:先内部用户 → 活跃用户 → 全量用户。
- 按地域放量:先非核心地域 → 核心地域。
灰度发布的重要性在于:把"一次大爆炸"变成"多次小实验"。即使新版本有 Bug,影响范围也只限于灰度流量,回滚成本低。没有灰度发布,每次上线都是一次全站赌博。
配合灰度发布还要有 快速回滚能力。灰度发现问题后,能在秒级或分钟级切回旧版本,而不是等运维手动拉代码重新部署。
冗余与容灾
什么是冗余?
冗余就是为系统关键组件准备备用能力。当某个节点、机房或链路出现故障时,系统可以切换到备用资源继续服务。
冗余是提升系统可用性的基础手段,但冗余本身不等于高可用。只有配合故障检测、流量切换、数据复制、恢复演练和监控告警,才能真正降低故障影响。
常见冗余对象包括:
- 服务实例冗余。
- 数据库主从或多副本冗余。
- 缓存集群冗余。
- MQ 多副本冗余。
- 机房和地域冗余。
⭐️RTO 和 RPO 分别是什么?
RTO 和 RPO 是容灾设计里非常重要的两个指标:
- RPO(Recovery Point Objective,恢复点目标):系统在灾难发生后可接受的数据丢失窗口,也可以理解为恢复时数据最多允许回退到多久之前。RPO 越小,对同步复制、日志复制、跨站点一致性和写入延迟的要求越高。RPO = 0 通常意味着写入必须在多个故障域确认后才能返回,或者有等价的强一致提交机制;代价是写入延迟上升,并且在网络分区时需要在可用性和一致性之间做取舍。
- RTO(Recovery Time Objective,恢复时间目标):可容忍的最大恢复时间,即从故障发生到系统恢复正常服务的时间。RTO=0 表示目标上不允许可感知中断,但在真实系统中更常见的表述是接近 0 或用户无感切换,仍要看故障检测、流量切换和客户端重试行为。
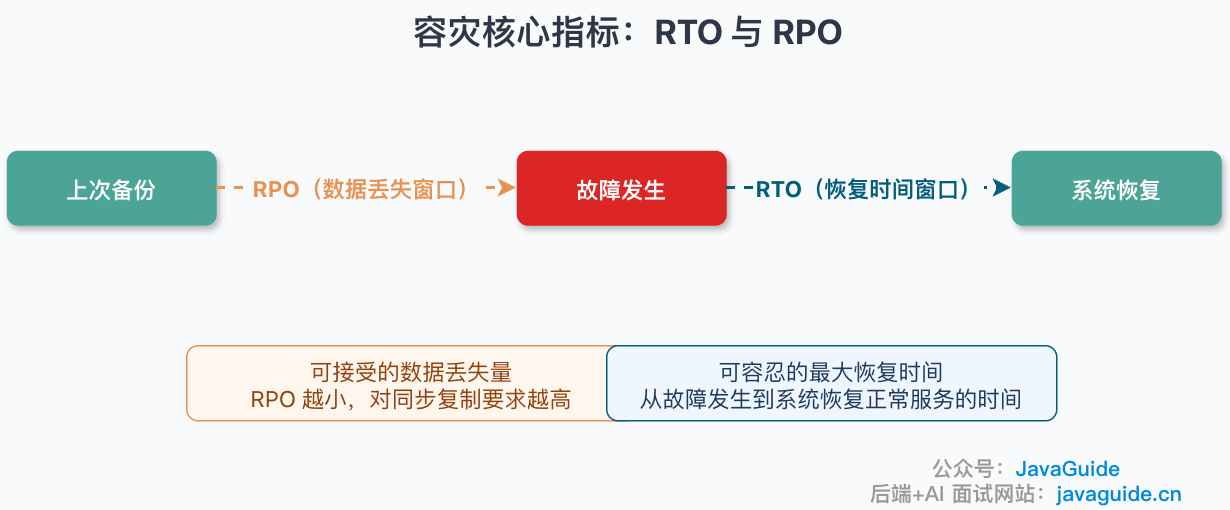
面试加分点:RTO/RPO 是目标,不是结果。声明了某个 RPO/RTO 不等于生产环境一定能做到,必须通过定期演练和压测来验证。不同业务链路可以有不同的 RTO/RPO 要求,不必全站统一。
常见冗余架构有哪些?
常见方案包括:
| 方案 | 特点 | 适用场景 |
|---|---|---|
| 高可用集群 | 多实例部署,故障自动转移 | 大多数在线服务 |
| 同城灾备 | 同城不同机房之间做备份 | 对延迟敏感,又需要机房容灾 |
| 异地灾备 | 异地准备备份系统 | 容忍一定恢复时间的灾备场景 |
| 同城多活 | 同城多机房同时承接流量 | 可用性要求较高的核心系统 |
| 异地多活 | 多地域同时承接流量 | 金融、支付、大型互联网核心链路 |
从容灾等级来看,可以形成如下连续光谱:
| 容灾等级 | 资源状态 | 恢复速度 | 成本 |
|---|---|---|---|
| 冷备 | 备用资源未运行,需手动启动 | 小时~天 | 低 |
| 温备 | 部分资源常驻运行,需扩容接管 | 分钟级 | 中 |
| 热备 | 资源和数据持续同步,可快速切换 | 秒~分钟 | 高 |
| 多活 | 多站点同时承载生产流量 | 接近实时 | 很高 |

越靠后的方案越复杂,尤其是异地多活,需要解决数据一致性、流量调度、跨地域延迟、故障切换和回切等问题。并不是所有业务都需要异地多活,强一致写入频繁且跨地域冲突多、无法按用户/地域/租户切分的数据模型、对账补偿能力不足的资金链路等场景要慎重评估。
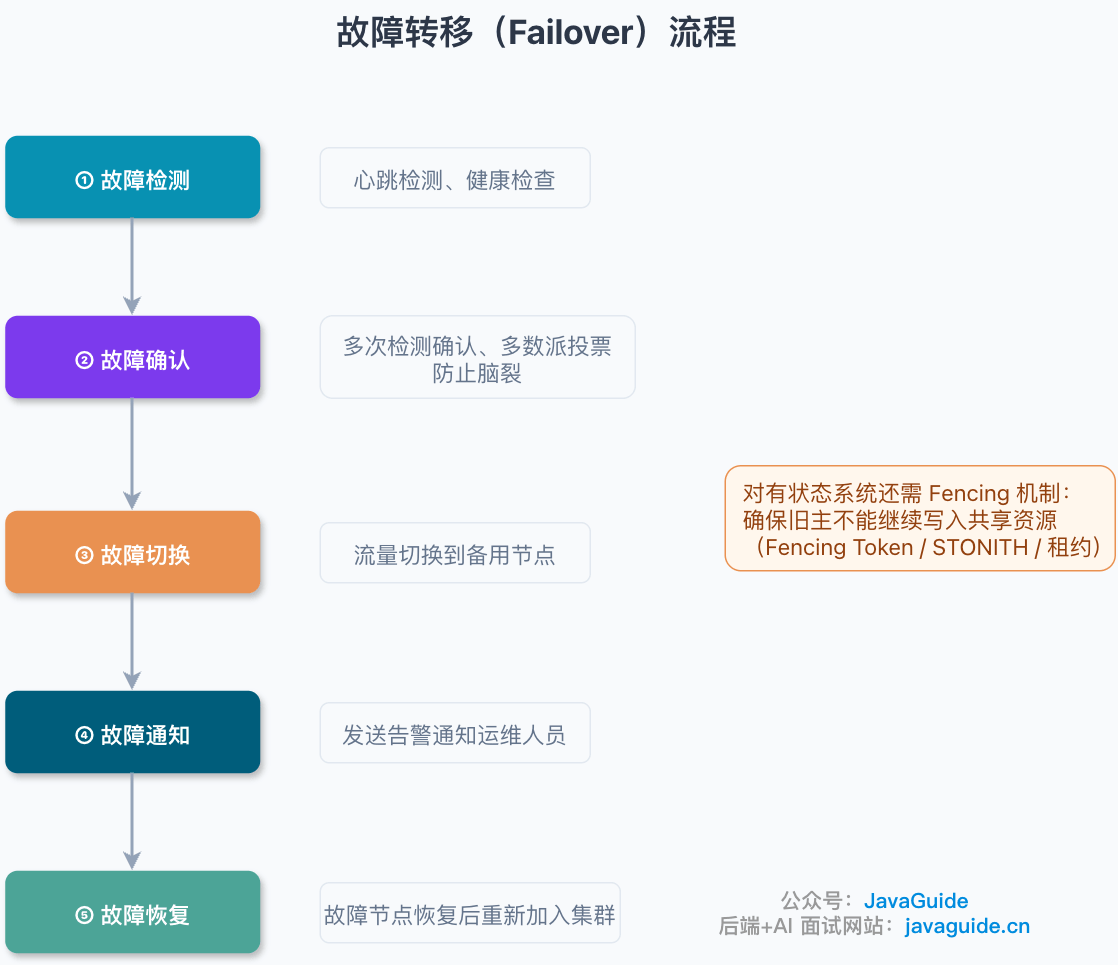
什么是故障转移?
故障转移是指主节点或主链路不可用时,系统自动或手动切换到备用节点继续服务。
故障转移可以是自动的,也可以是自动检测后人工确认。对无状态服务和缓存系统,通常追求自动切换;对数据库主切、跨地域切流、资金链路等高风险场景,很多团队会保留人工确认或审批步骤。
常见例子:
- Redis Sentinel 检测 primary 节点不可用后,选举新的 primary。但需要注意 Redis 复制通常是异步的,故障切换时可能丢失尚未复制到 replica 的数据,不保证 RPO=0。
- Nginx + Keepalived 通过 VIP 漂移实现入口高可用。但 Keepalived 不保证已有 TCP 连接无损迁移,切换还受 ARP / 二层网络 / 云厂商 VIP 支持影响。
- 数据库主从切换,让从库提升为主库。
故障转移要特别关注 误判和脑裂 问题。检测太敏感可能误切,检测太迟又会延长故障时间。脑裂通常来自网络分区,两个节点都认为自己是主节点。常见防护手段包括多数派投票(如 Redis Sentinel 的 quorum)、仲裁节点、租约机制和 fencing。
对于有状态系统,还需要 fencing 机制(如 fencing token、STONITH、写入令牌),确保旧主在失联或恢复后不能继续对共享资源写入,避免双主写入。
Redis Sentinel 相关的面试加分点:quorum 只表示多少 Sentinel 同意 primary 客观下线;实际发起 failover 还涉及 Sentinel 多数派和 leader 选举,因此不要把 quorum 简单理解成 Sentinel 总数的一半。
限流
⭐️为什么要做限流?
限流是为了控制进入系统的请求速率,防止瞬时流量超过系统处理能力。
它解决的问题是:系统资源有限,不能让所有请求无条件进入核心链路。
常见场景:
- 秒杀、大促、热点活动。
- 接口被刷。
- 下游服务能力有限。
- 保护数据库、缓存、第三方接口。
限流会牺牲部分请求体验,但换来的是系统整体稳定。
常见限流算法有哪些?
常见算法包括:
| 算法 | 特点 | 问题或适用场景 |
|---|---|---|
| 固定窗口 | 实现简单 | 临界点可能出现流量突刺 |
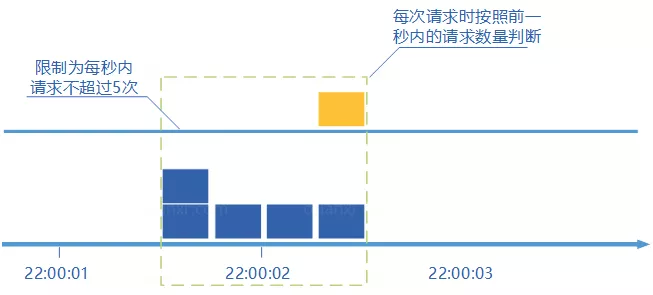
| 滑动窗口 | 比固定窗口更平滑 | 实现复杂度更高 |
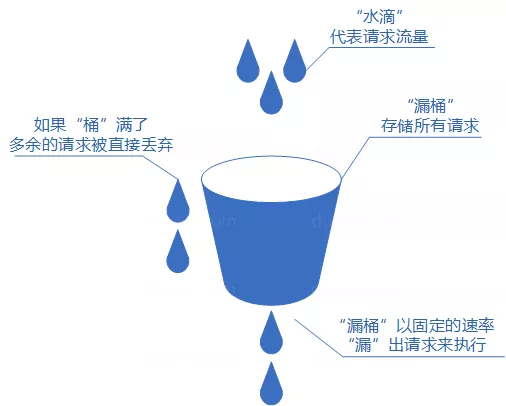
| 漏桶 | 按固定速率匀速处理请求 | 无法利用空闲时积累处理能力应对突发 |
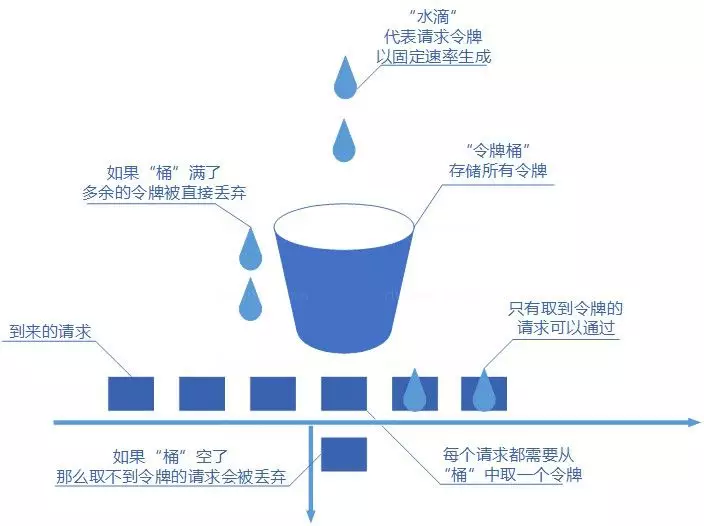
| 令牌桶 | 平均限速,也允许短暂突发 | 实际业务中更常用,突发上限受桶容量限制 |
令牌桶比漏桶更灵活,因为它允许桶里积累一定令牌,短时间内可以处理突发请求。令牌桶有两个核心参数:填充速率(rate)和桶容量(burst),短时间最大突发量不会超过桶内积累的令牌数。
如果面试官追问"网关限流、接口限流、用户维度限流怎么选",可以这样答:网关适合统一入口保护,接口维度适合保护高成本接口,用户/IP/租户维度适合防刷和防单个调用方拖垮系统。
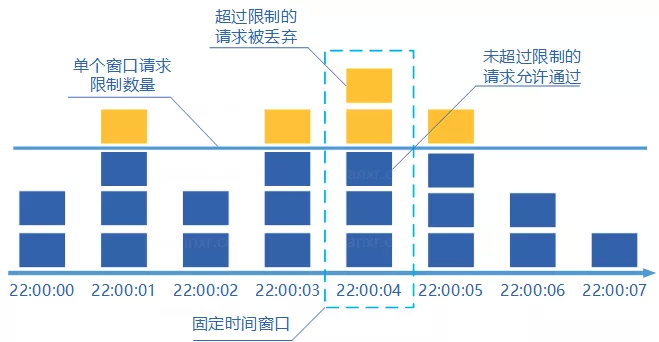
⭐️固定窗口算法有什么问题?
固定窗口的问题是 临界突刺。
比如限制每分钟 100 次请求,如果用户在第 1 分钟最后 1 秒发了 100 次,又在第 2 分钟第 1 秒发了 100 次,从窗口统计看都没超限,但实际上 2 秒内进入了 200 次请求。
这就是固定窗口不够平滑的地方。滑动窗口通过把时间切成更小粒度,可以缓解这个问题。
单机限流和分布式限流有什么区别?
单机限流只统计当前实例上的请求,适合单体应用或每个节点独立保护自己的场景。
分布式限流需要多个实例共享限流状态,常见实现方式包括 Redis + Lua、网关限流、Sentinel 集群限流等。
区别在于:
- 单机限流简单,但无法控制全局总 QPS。
- 分布式限流能控制全局流量,但会引入网络开销和一致性问题。
Redis + Lua 是分布式限流里很常见的实现方式,原因是 Lua 脚本可以把"读取计数、判断阈值、更新计数"放到一次原子执行里,避免并发下计数不准。它的代价是依赖 Redis 可用性,Redis 宕机、主从切换或网络抖动时,限流可能短时间不准甚至失效,所以生产环境要配合 Redis Sentinel/Cluster,并准备本地限流兜底。
面试加分点:不是所有微服务都必须用分布式限流。如果总配额可以按实例数均分(比如 10 个实例,每个承担 1/10),单机限流反而更简单、延迟更低、不依赖外部存储。
⭐️令牌桶和漏桶的核心区别是什么?
两者都能限流,但哲学不同:
- 漏桶:请求以固定速率流出,不管来了多少请求,处理速度恒定。好处是输出平滑,坏处是突发流量来了也只能慢慢处理,没法利用系统空闲时的处理能力。
- 令牌桶:令牌以固定速率放入桶中,桶有容量上限。请求来了拿令牌,拿到就处理,拿不到就拒绝或等待。空闲时令牌会积累,短时间突发可以一次性消耗积累的令牌。
核心区别就一个:令牌桶允许突发,漏桶不允许。实际业务中大多数场景用令牌桶,因为流量本身就是有波动的,完全匀速处理既不现实也没必要。
限流的维度怎么选择?
常见限流维度:
| 维度 | 适用场景 | 注意点 |
|---|---|---|
| IP | 防刷、防攻击 | X-Forwarded-For 可能被伪造,别直接信任 |
| 用户 ID | 防止单个用户过度消耗资源 | 未登录用户需要回退到 IP 维度 |
| 接口 | 保护高成本接口 | 接口粒度太细可能配置爆炸 |
| 服务/网关 | 统一入口保护 | 粒度粗,可能误杀 |
| 业务 ID | 按租户、商户等维度隔离 | 需要业务层配合传递标识 |
选择原则:网关做粗粒度保护,服务内做细粒度保护。不要只在一个层面做限流,否则不是漏了就是误杀了。
Guava RateLimiter 有哪两种模式?
Guava RateLimiter 提供两种常见模式:
- 平滑突发限流(SmoothBursty):令牌按固定速率生成,允许突发。适合大多数普通场景。
- 平滑预热限流(SmoothWarmingUp):刚启动时速率较低,经过预热时间后逐步升到稳定速率。适合系统冷启动时数据库连接池还没热、JIT 还没编译完成等场景。
面试中如果被问到"系统刚重启时为什么会有一波超时",可以提到预热限流:冷启动时缓存是空的,连接池还没建好,如果这时就打满流量,很容易超时。预热限流可以在启动阶段逐步放量,让系统先热起来。
降级与熔断
⭐️什么是服务降级?
服务降级是当系统负载过高或部分依赖异常时,主动降低非核心功能的服务质量,优先保证核心链路可用。
典型例子:
- 大促时关闭商品推荐,保留下单和支付。
- 评论、排行榜、广告位返回默认值。
- 非核心写操作先写入 MQ,后续异步处理。
降级的核心思想是:保核心,弃非核心。
降级不只是"负载太高才触发",下游服务异常、机房故障、大促预案、运营控制等都可能触发。降级粒度可以从粗到细:服务级 → 页面区块级 → 接口级 → 功能开关级。
常见降级方式有哪些?
常见方式包括:
- 页面片段降级:关闭推荐区、广告位等非核心模块。
- 读降级:只读缓存,后端不可用时返回默认值。
- 写降级:先写缓存或 MQ,后续补偿同步。
- 异步降级:非实时操作改为异步处理。
- 页面跳转降级:跳转到静态页或简版页。
降级预案需要提前设计,不应该等故障发生时临时拍脑袋。大型系统通常会建设统一的降级平台,支持按功能开关、接口、服务维度灵活控制降级状态。
⭐️什么是熔断?它解决什么问题?
熔断是当下游服务异常或响应过慢时,调用方暂时停止调用下游,直接返回失败或兜底结果,防止故障沿调用链扩散。
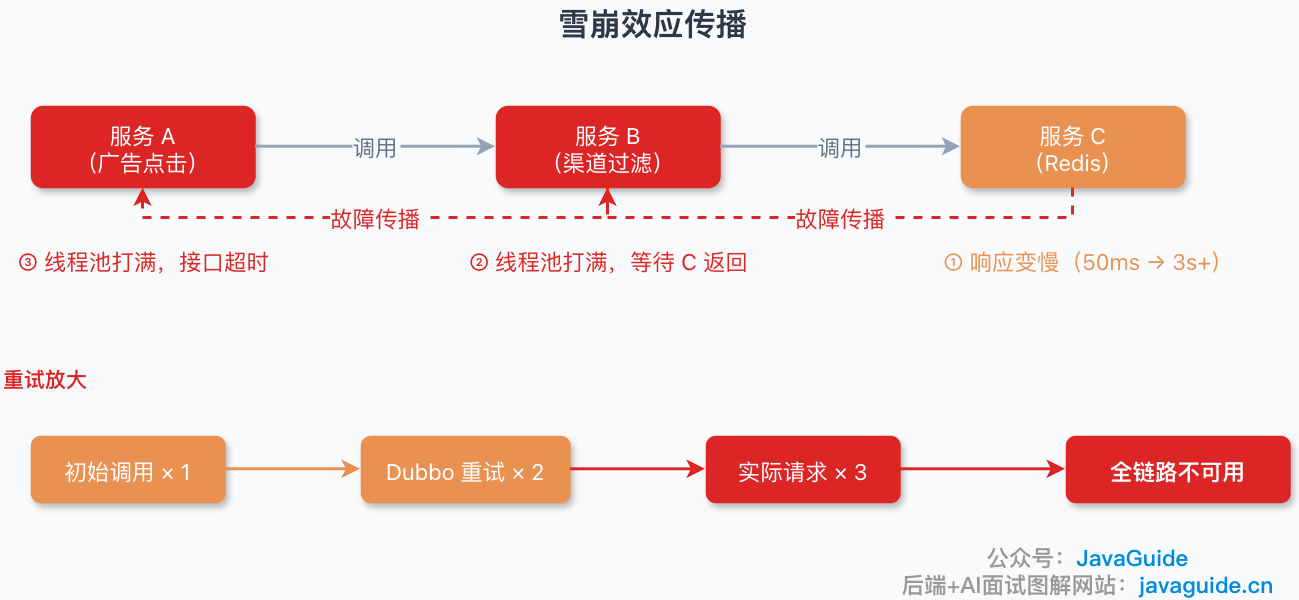
它解决的是 雪崩效应。
比如服务 A 调用服务 B,服务 B 调用服务 C。服务 C 变慢后,B 的线程被拖住,A 的请求也开始堆积,最终整个链路都被拖垮。熔断就是在发现 C 明显异常后,主动切断对 C 的调用,保护 A 和 B。
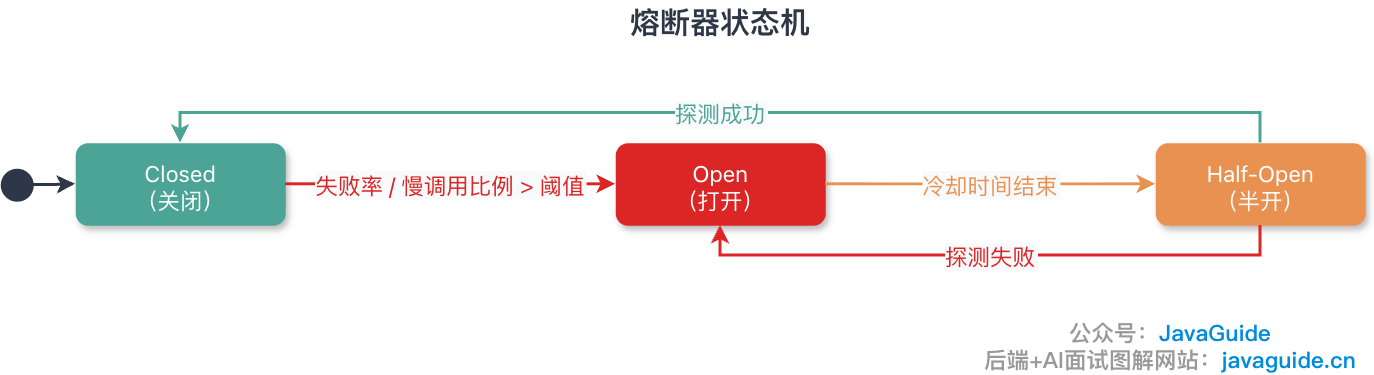
熔断器有哪些状态?
常见状态有 3 个:
- Closed:正常状态,请求正常通过。
- Open:熔断打开,请求不再调用下游,直接走 fallback。
- HalfOpen:半开状态,放少量探测请求检查下游是否恢复。
如果 HalfOpen 探测成功,熔断器回到 Closed;如果失败,继续 Open。
Closed 不是"永远安全",它只是正常放行;Open 不是"下游一定挂了",它代表调用方基于阈值判断继续调用风险太高;HalfOpen 是恢复探测窗口,不能一下子把全量流量放回去。
面试加分点:Sentinel 1.8.0 之后提供三种熔断策略——慢调用比例、异常比例、异常数。注意 P99 延迟不能直接当熔断条件,熔断看的是在 一个统计时间窗口内 慢调用或异常的比例是否超过阈值,而不是单个请求的延迟。
⭐️降级和熔断有什么区别?
区别如下:
| 维度 | 降级 | 熔断 |
|---|---|---|
| 关注点 | 主动牺牲非核心功能 | 阻断异常依赖 |
| 触发方式 | 可以人工触发,也可自动触发 | 通常由失败率、慢调用比例触发 |
| 目标 | 保核心链路 | 防止故障扩散 |
| 恢复方式 | 手动恢复或自动恢复 | 通过 HalfOpen 探测恢复 |
一句话区分:降级是主动降低服务质量,熔断是被下游故障逼出来的链路保护。
超时、重试、熔断、限流、隔离怎么配合?
只设置超时和重试还不够。超时和重试是弹性手段,但如果下游持续异常,重试反而会放大故障。生产环境通常需要多种机制组合使用:
| 机制 | 职责 | 关键点 |
|---|---|---|
| 超时(Timeout) | 及时释放等待资源 | 避免请求无限堆积 |
| 重试(Retry) | 处理瞬态失败 | 必须限制次数、退避、加 Jitter |
| 限流(Rate Limit) | 限制进入系统的请求量 | 保护下游不被流量冲垮 |
| 熔断(Circuit Breaker) | 避免继续打异常下游 | 快速失败,给下游恢复时间 |
| 隔离(Bulkhead) | 限制故障影响面 | 线程池 / 信号量隔离,防止级联失败 |
面试中如果被问到"怎么设计一个高可用的调用链",可以按这个组合关系回答:入口限流 → 超时保护 → 可重试的瞬态错误用重试 + 退避 → 下游持续异常用熔断 → 写操作必须幂等。
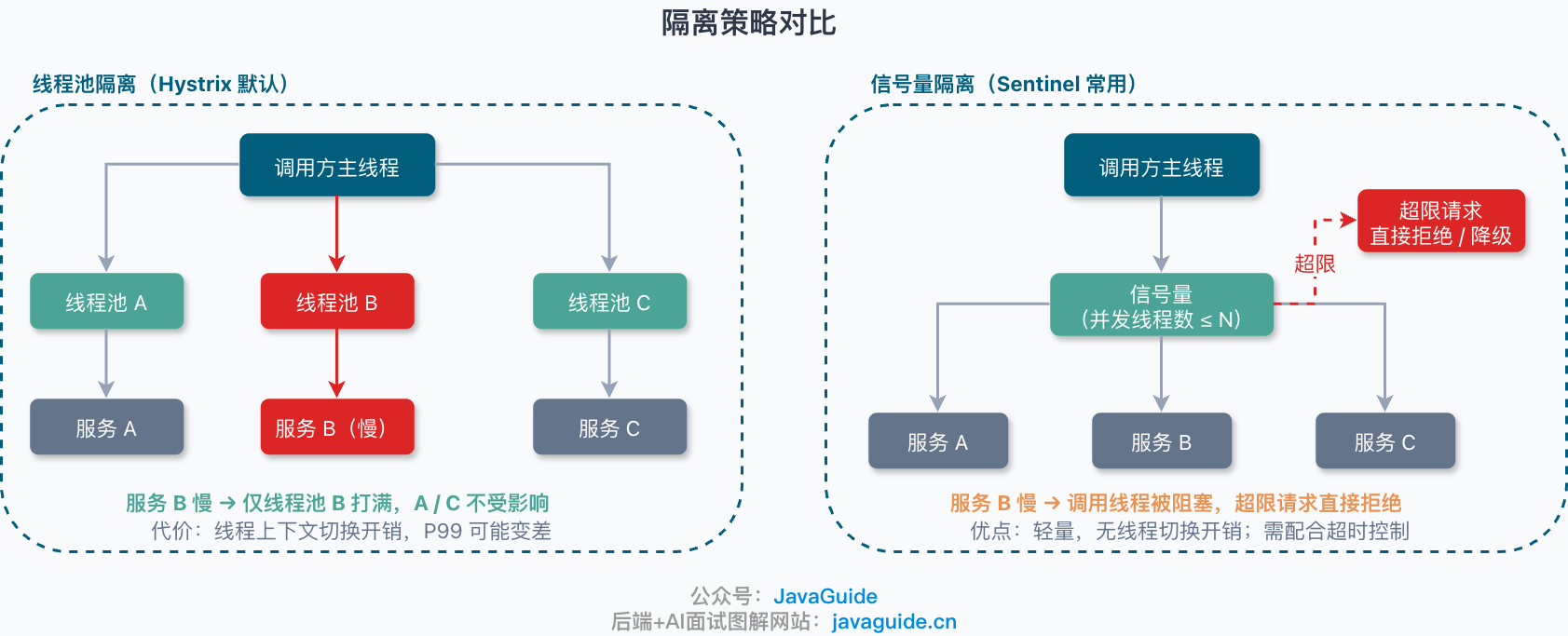
线程池隔离和信号量隔离有什么区别?
隔离是防止某个下游故障把整个服务拖垮的关键手段。常见的两种隔离策略:
| 维度 | 线程池隔离 | 信号量隔离 |
|---|---|---|
| 实现方式 | 给下游调用分配独立线程池 | 限制同时执行的请求数 |
| 隔离程度 | 彻底,调用在独立线程中执行 | 轻量,调用在当前线程中执行 |
| 开销 | 线程上下文切换,资源占用较高 | 低开销,不需要额外线程池 |
| 适用场景 | 调用延迟不可控、需要完整隔离 | 调用延迟可控、需要低开销保护 |
Hystrix 默认使用线程池隔离;Sentinel 的并发线程数控制更接近信号量隔离的思路。
线程池隔离的代价不是很多人以为的"GC 扫描",而是 上下文切换。线程多了以后 CPU 在线程间频繁调度,sy 飙高,P99 尾延迟跟着恶化。到底严不严重,得看线程数、CPU sy/us 比例、队列等待时间和 P99 指标,别光凭感觉。
Sentinel 的系统自适应保护是什么?
普通限流通常是手动设置一个阈值,比如 QPS 超过 1000 就限流。但真实系统不是这么简单,CPU、Load、RT、线程数、入口 QPS 都会影响系统是否已经接近极限。
Sentinel 的系统自适应保护从整个系统负载角度判断要不要拒绝部分请求。官方文档里说这个思路受 TCP BBR 启发,目标是在保证系统可靠的前提下维持较高吞吐。可以粗略理解成:
当前并发请求数 > 系统最大 QPS × 最小 RT
如果当前在途请求已经超过系统估算的承载能力,就开始拒绝一部分流量。系统规则可以按这些指标配置:Load、CPU 使用率、总体 RT、并发线程数、入口 QPS。
注意别把它理解成完整的 TCP BBR——Sentinel 是借鉴思路,结合实时统计和规则阈值做保护,不是像 TCP 那样动态探测带宽、调整拥塞窗口。
Fallback 设计有哪些常见坑?
Fallback(兜底逻辑)写起来简单,但生产环境踩坑的概率很高:
- Fallback 里藏远程调用:兜底方法里又调了另一个服务,如果这个服务也挂了呢?Fallback 应该尽量本地返回,不引入新的远程依赖。
- 返回 null 或空对象不处理:调用方拿到的 Fallback 结果是 null,后续逻辑空指针异常,比不降级还严重。
- Fallback 逻辑太复杂:兜底方法里写了一堆 if-else 和业务逻辑,容易出 Bug 还难测试。Fallback 越简单越好。
- 多个 Fallback 共用同一个缓存:缓存被打满,所有兜底同时失效。按业务维度隔离缓存,核心链路独立缓存实例。
一句话总结:Fallback 的目标是让系统"有尊严地失败",而不是把问题藏起来。
Hystrix、Sentinel、Resilience4j 怎么选?
简单建议:
- 新项目使用 Spring Cloud Alibaba,优先考虑 Sentinel。
- 响应式或轻量级项目,可以考虑 Resilience4j。
- 老项目已经使用 Hystrix,可以继续维护,但要规划迁移,因为 Hystrix 已经停止维护。
Sentinel 的优势是限流、熔断、降级、系统自适应保护能力比较完整,并且有控制台支持。需要注意的是,Sentinel 集群限流的 Token Server 需要单独部署,存在可用性和性能瓶颈;如果只做单机实例自保护,单机限流模式反而更简单。
选型时还要看项目栈:Spring Cloud Alibaba 体系下 Sentinel 接入成本低;轻量服务或响应式链路可以考虑 Resilience4j;已经历史使用 Hystrix 的系统通常不建议继续大规模扩展新能力。
面试加分点:Sentinel 中 blockHandler 和 fallback 是不同的概念。blockHandler 处理的是 Sentinel 规则拦截(如限流、熔断触发),fallback 处理的是业务异常。两者不要混用。
超时、重试与幂等
⭐️为什么所有远程调用都要设置超时?
远程调用可能因为网络抖动、下游慢、连接池耗尽、服务故障等原因一直不返回。如果不设置超时,请求线程会长期阻塞,最终导致连接数、线程数、队列全部被打满。
超时机制的作用是让失败尽快暴露,避免慢请求无限堆积。
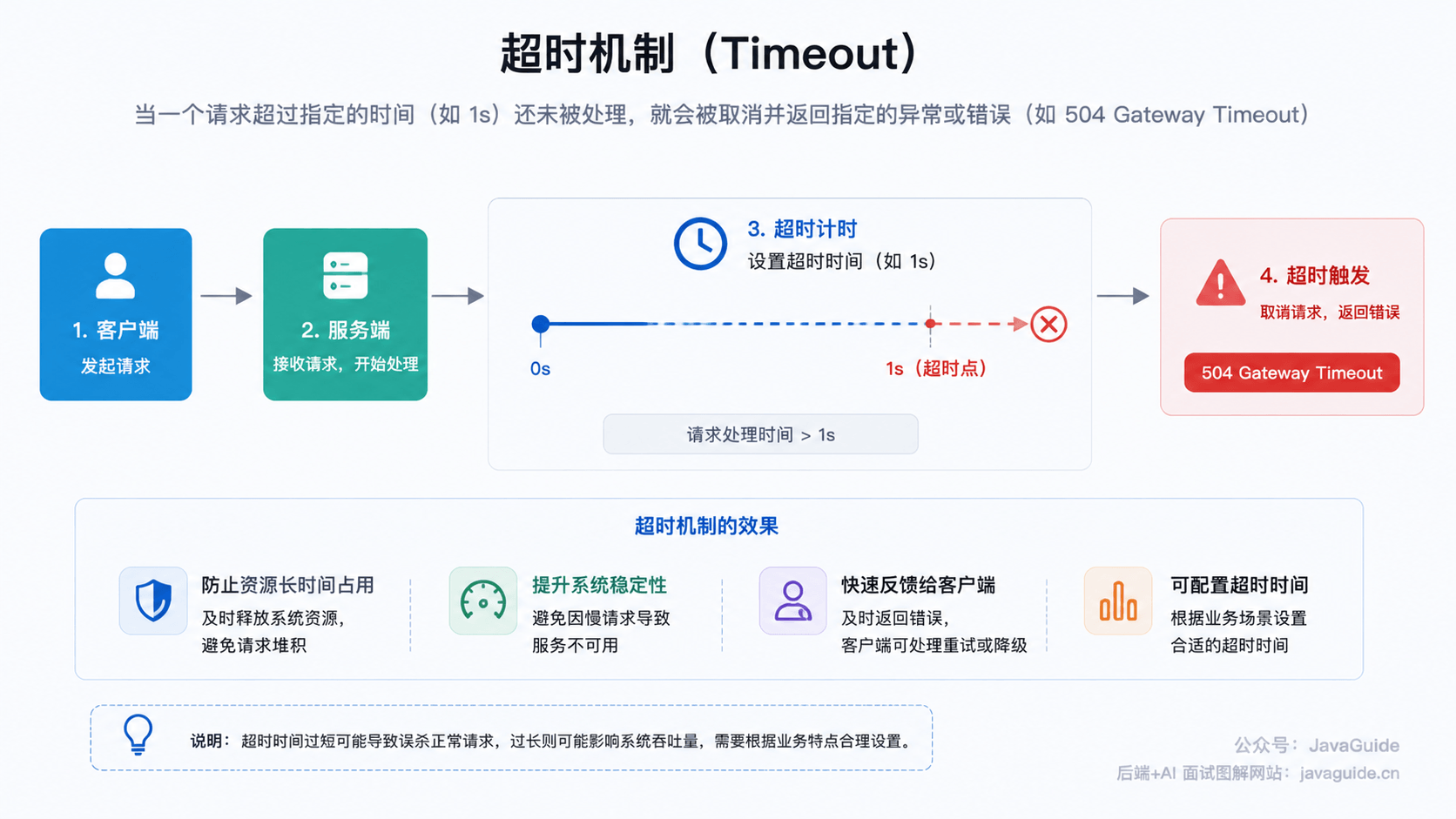
常见超时类型:
- 连接超时(Connect Timeout):建立 TCP 连接的最长等待时间。
- 读取超时(Read Timeout):连接建立后等待响应数据的最长等待时间。
- 获取连接超时:从连接池拿连接的最长等待时间。
入门时理解这三种就够了,但生产环境还要看客户端是否支持更多维度:DNS 解析超时、TLS 握手超时、Write Timeout、Call Timeout / Deadline(整个调用的总超时)、空闲连接清理超时等。不同 HTTP/RPC 客户端对这些超时字段的覆盖范围不同,配置时必须绑定具体客户端实现的文档。
超时时间应该如何设置?
超时时间太短,正常慢请求也会被误杀;太长,又无法及时释放资源。
一般建议:
- 根据接口 P99、P999 延迟设置,而不是拍脑袋定一个固定值。比如 AWS 的经验是:先确定可接受的 false timeout 比例(例如 0.1%),再选择对应延迟百分位(如 P99.9)作为超时起点。
- 结合业务可接受等待时间。
- 区分核心链路和非核心链路。
- 放到配置中心,支持动态调整。
微服务调用链中更推荐传递 deadline 或 timeout budget:入口请求有一个总时间预算,每经过一层都要扣除本地处理、排队、网络和下游调用时间。下游超时应小于调用方剩余预算,而不是每层拍脑袋固定 3s、2s、1s。
超时配置动态调整要灰度发布,并观察 P99/P999 延迟、超时率、线程池队列、连接池等待时间和重试量,不能大范围直接推全量。
⭐️为什么重试可能导致故障放大?
重试的本意是解决瞬态故障,但如果下游已经过载,大量上游同时重试,会让下游压力更大,形成 重试风暴。
重试风险包括:
- 放大下游流量。
- 增加请求延迟。
- 导致重复操作。
- 触发雪崩效应。
所以,重试必须配合超时、限流、熔断、幂等和退避策略一起使用。
常见重试策略有哪些?
常见策略:
- 固定间隔重试。
- 线性退避重试。
- 指数退避重试。
- 带随机抖动(Jitter)的指数退避。
分布式系统里更推荐 带 Jitter 的指数退避。指数退避能逐步降低重试频率,Jitter 能避免大量客户端在同一时间点一起重试。Jitter 的具体实现可以是 full jitter(完全随机)、equal jitter(等分抖动)或 decorrelated jitter(去相关抖动),目标都是打散多个客户端的同步重试。
在线同步请求的重试次数通常要很克制,常见是 1~3 次。异步任务或 MQ 消费可以更多,但必须配合退避、最大重试次数、死信队列、告警和人工补偿。
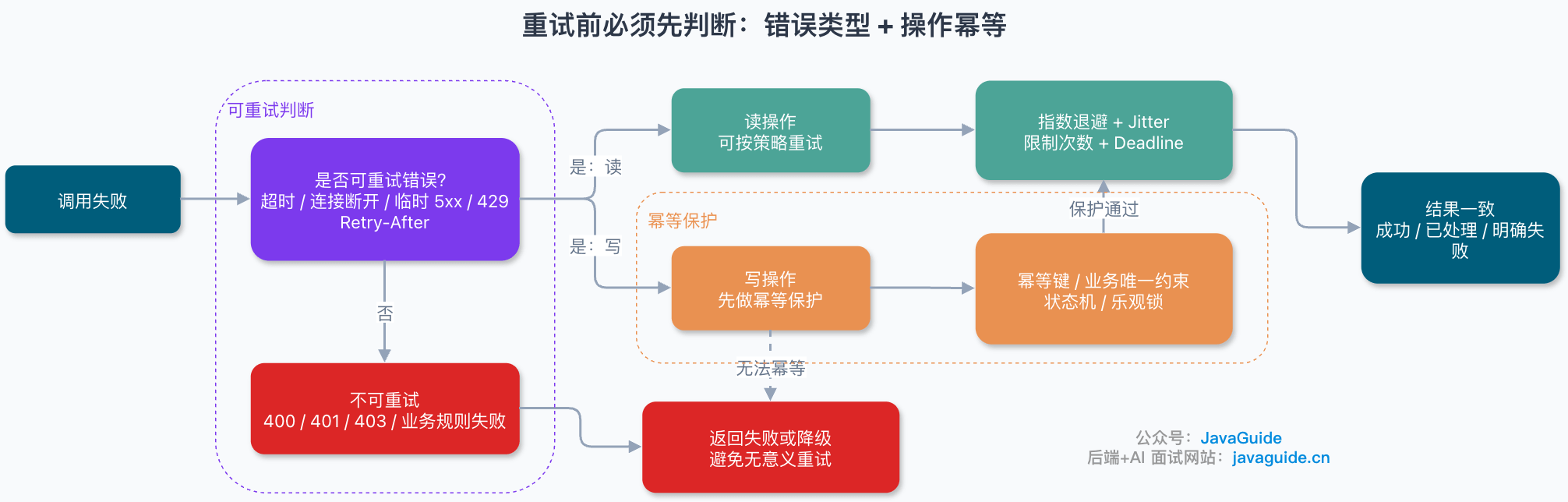
⭐️哪些请求可以重试?哪些不适合重试?
| 分类 | 典型场景 | 处理方式 |
|---|---|---|
| 可重试 | 连接超时、读超时、连接重置、临时 502/503/504 | 配合退避策略重试 |
| 可重试 | 限流后带 Retry-After 的 429 | 按 Retry-After 等待后重试 |
| 谨慎重试 | 支付、下单、库存扣减、发券等写操作 | 必须有幂等键或业务唯一约束 |
| 不应重试 | 参数错误(400)、权限失败(401/403)、业务规则失败 | 直接返回错误 |
| 不应重试 | 余额不足、库存不足等业务异常 | 直接返回错误 |
一般只重试超时、连接断开、临时 5xx、限流后明确允许重试的响应;不要重试参数校验失败、权限失败、业务规则失败、明确的 4xx,以及无法保证幂等的写操作。
写操作如果要重试,必须先做好幂等。
什么是重试预算(Retry Budget)?
重试预算(Retry Budget) 是一种有效的规避策略:限制在一定时间窗口内的重试次数占总请求数的比例,如不超过 10%。落地时可以按调用方、接口或下游维度统计原始请求数和重试请求数,当重试比例超过预算时,后续请求快速失败或只允许首试,不再重试。
什么是幂等?
幂等指同一个操作执行一次和执行多次,最终结果一致。
从 HTTP 语义上看,RFC 9110 定义 PUT、DELETE 以及 safe methods(GET、HEAD、OPTIONS、TRACE)为幂等方法。POST 默认不具备幂等语义,但可以通过幂等键、业务唯一约束等方式实现业务幂等。但协议语义不等于服务端实现一定安全,涉及创建订单、扣款、发券、发消息等副作用操作时,服务端仍然需要显式设计幂等。
常见幂等方案:
- 请求唯一 ID(幂等键)。
- 数据库唯一索引。
- Redis 去重。
- 乐观锁版本号。
- 状态机流转控制。
- 业务防重表。
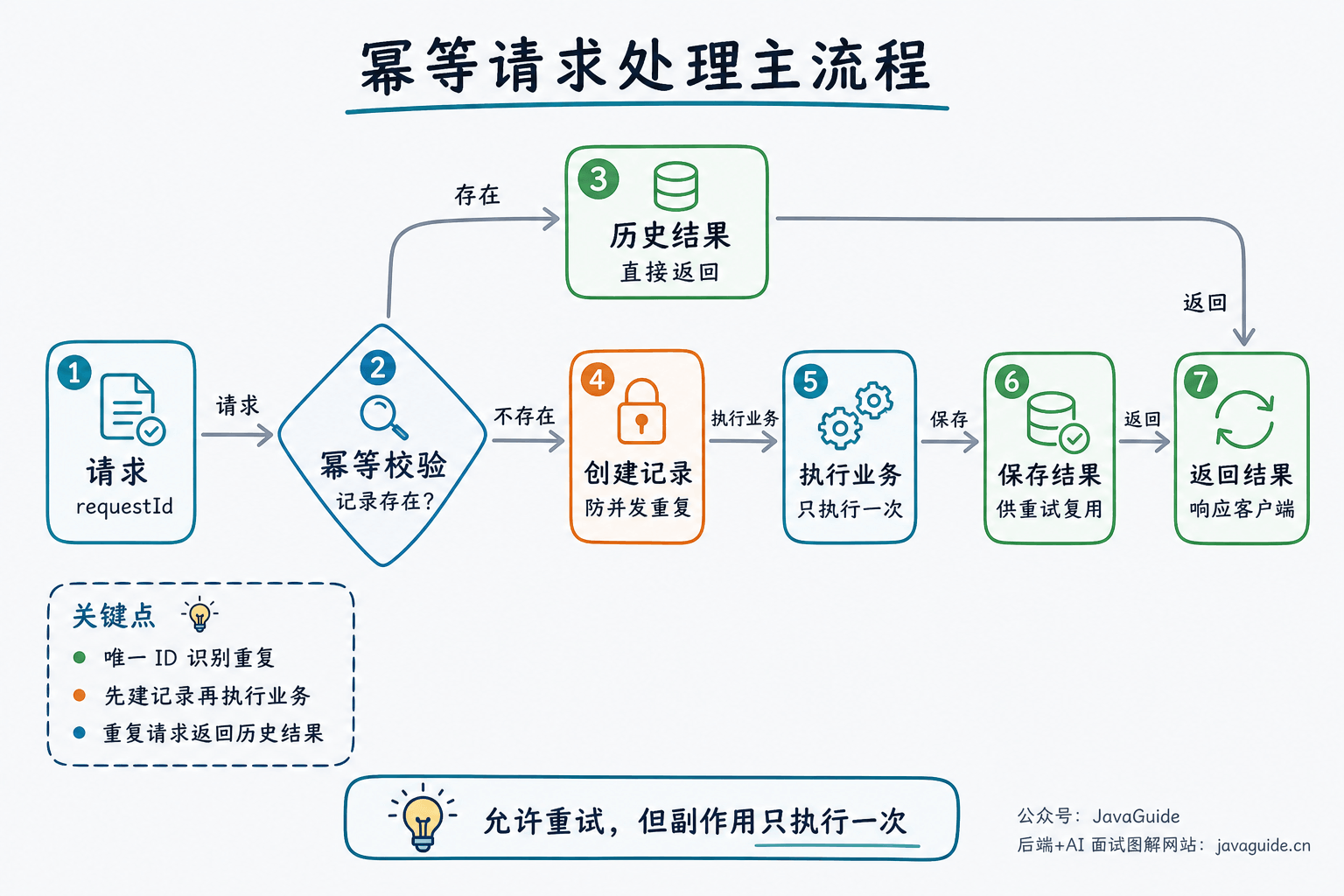
幂等的难点不在"识别重复请求"这句话,而在并发下第一次请求和重复请求同时到达时,如何保证只有一个请求真正执行副作用操作。常见解法是利用数据库唯一索引或防重表:先插入幂等记录,插入成功的请求执行业务,插入失败的重复请求查询已有结果返回;插入幂等记录和业务操作最好放在同一个事务中。
面试加分点:赋值更新(如 set status = "PAID")比累加更新(如 set balance = balance - 100)更容易做到幂等,累加更新必须额外控制重复执行。
⭐️支付接口如何保证幂等?
可以这样设计:
- 客户端或服务端生成唯一支付请求号。
- 服务端用请求号建立唯一索引或幂等记录。
- 第一次请求执行支付流程。
- 重复请求直接返回第一次处理结果。
- 支付状态通过状态机控制,只允许合法状态流转。
核心原则是:扣款、入账、发券这类副作用操作,必须能识别重复请求。
状态机也很重要。比如支付单只能从 INIT 流转到 PAYING,再流转到 SUCCESS 或 FAILED,不能让重复通知把已经成功的支付单再次扣款,也不能让失败状态覆盖成功状态。
幂等设计完成后,建议通过并发压测、重试测试、异常测试、数据校验等方式验证,不能只在正常流程下测一下就上线。
幂等和去重有什么区别?
这两个概念经常被混用,但侧重点不同:
- 去重:防止重复请求到达服务端。比如消息队列的 dedup 机制、客户端的防重复提交。
- 幂等:允许重复请求到达,但保证多次执行的结果和一次执行一致。
去重是"不让它来",幂等是"来了也不怕"。生产中两者经常配合使用:先尽量在入口去重,兜底还是靠幂等。因为去重不可能 100% 挡住(比如网络分区导致去重记录丢失),最终还是得靠服务端幂等保证数据安全。
⭐️Token 机制怎么做幂等?
Token 机制是防重复提交的常见方案,基本流程:
- 客户端先请求一个 Token(服务端生成并存入 Redis,设过期时间)。
- 客户端提交业务请求时携带这个 Token。
- 服务端收到请求后,验证并消费 Token(原子操作)。
- Token 消费成功后执行业务逻辑。
关键问题是 Token 消费和业务执行谁先谁后:
- 先删 Token 再执行业务:如果业务执行失败,Token 已经没了,客户端重试会被拒。需要在业务失败时把 Token 放回去。
- 先执行业务再删 Token:如果业务执行成功但删 Token 失败,客户端重试会再执行一次业务。必须保证业务本身幂等。
推荐做法是 先原子消费 Token,再执行业务。Redis 6.2.0 及以上版本可以使用 GETDEL 命令,低版本可以用 Lua 脚本保证"校验 + 删除"的原子性。如果业务执行失败,再根据情况决定是否恢复 Token。
悲观锁做幂等有什么坑?
用 SELECT ... FOR UPDATE 做幂等控制时,常见坑:
- RR 隔离级别下的 Next-Key Lock:MySQL 在 RR 隔离级别下,
SELECT ... FOR UPDATE可能会锁住不只是一行,而是一个范围(Next-Key Lock = Gap Lock + Record Lock)。如果查询条件不是唯一索引,可能锁住大量记录,导致并发性能骤降。 - 死锁风险:多个请求以不同顺序获取锁,可能互相等待,形成死锁。
- 锁超时:如果事务持有锁的时间太长(比如事务里还有远程调用),其他请求会等待超时。
建议:用悲观锁做幂等时,查询条件必须命中唯一索引,事务尽量短,不要在事务里做远程调用。更好的做法是优先用唯一索引或防重表替代悲观锁。
性能测试与故障治理
性能测试常见指标有哪些?
常见指标包括:
- 响应时间 RT:请求从发出到收到响应的时间。
- QPS:每秒查询数。
- TPS:每秒事务数。
- 并发数:同一时间正在处理的请求数量。
- 吞吐量:单位时间内系统处理的数据量。
- 错误率:失败请求占比。
- 资源使用率:CPU、内存、磁盘、网络、连接池、线程池等。
QPS 通常用于衡量读接口或网关层流量;TPS 更适合衡量一次完整业务事务(如下单包含扣库存、创建订单、写流水等)。面试中两者经常被混用,但主动区分会更严谨。
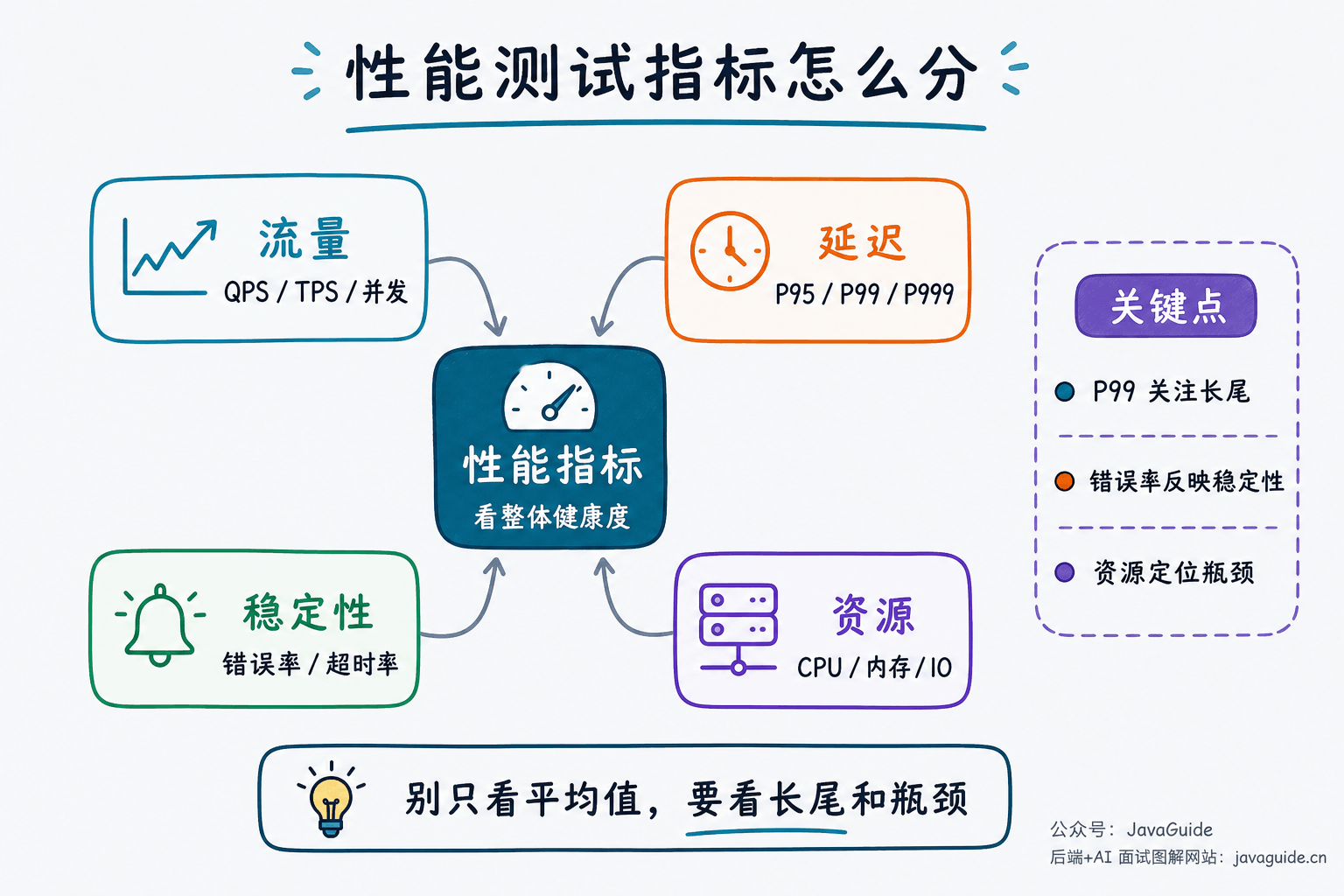
面试里不要只说平均 RT,P95、P99 更能反映长尾延迟。
⭐️性能测试、负载测试、压力测试、稳定性测试有什么区别?
区别如下:
| 类型 | 目标 |
|---|---|
| 性能测试 | 评估系统在预期负载下的性能表现 |
| 负载测试 | 逐步增加负载,观察性能变化 |
| 压力测试 | 找到系统极限和崩溃点 |
| 稳定性测试 | 长时间运行,观察是否有资源泄漏 |
如果面试官问"怎么证明系统能扛住大促",只回答压测工具不够,还要说明压测模型、流量比例、数据准备、监控指标和瓶颈定位方法。
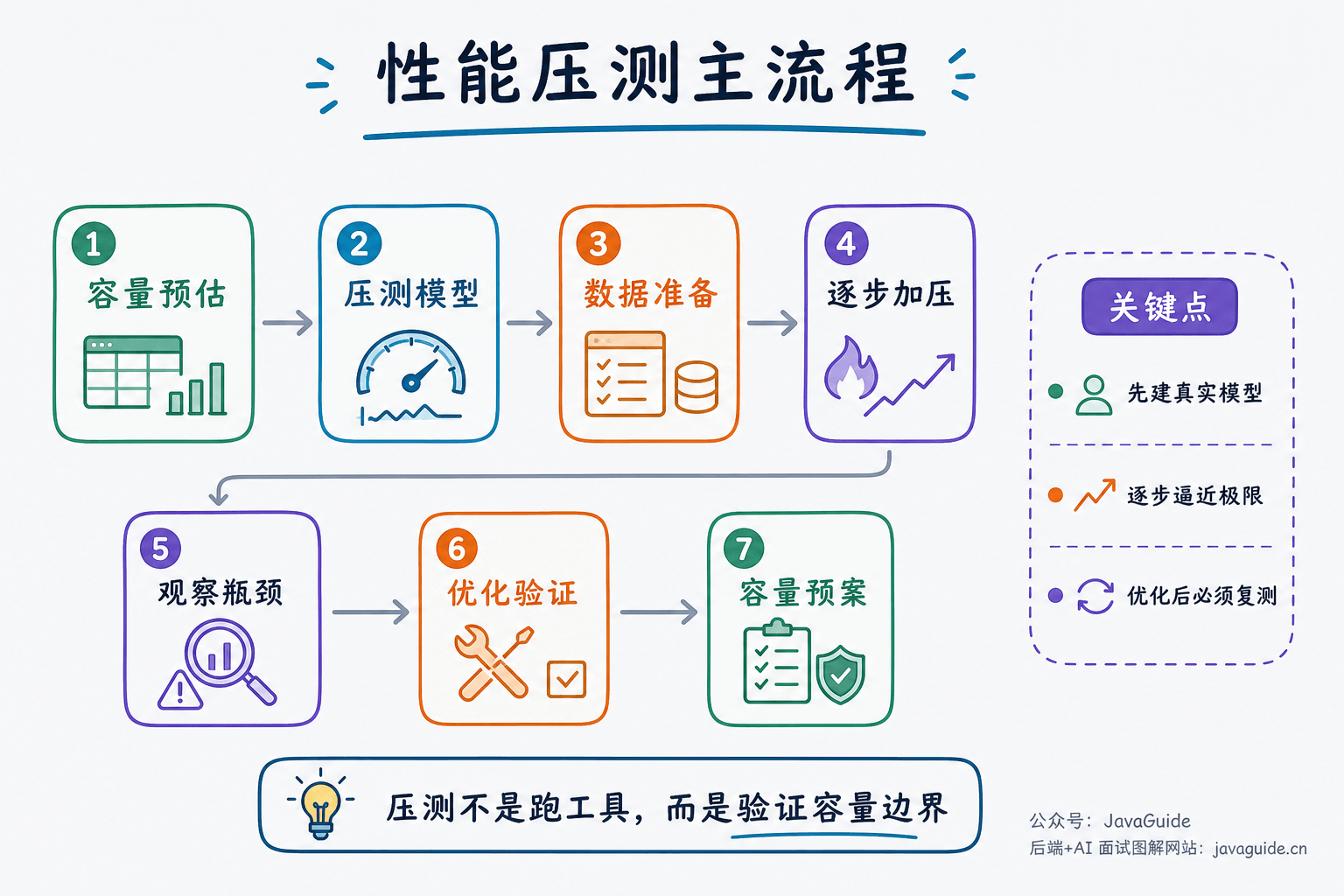
如何做容量评估?
容量评估一般需要:
- 估算峰值 QPS、TPS、并发数。
- 梳理核心接口和流量比例。
- 准备接近真实的数据量。
- 通过压测得到单机能力和集群能力。
- 预留安全水位,比如只使用 60% 到 70% 的容量。
- 对数据库、缓存、MQ、第三方接口分别评估瓶颈。
容量评估不是只看应用服务器,很多系统真正的瓶颈在数据库、缓存热点、连接池或下游接口。
⭐️缓存穿透、缓存击穿、缓存雪崩分别是什么?
这是缓存高可用的三个经典问题:
| 问题 | 触发条件 | 常见方案 |
|---|---|---|
| 穿透 | 查询一个数据库里也不存在的数据 | 布隆过滤器 / 缓存空值 |
| 击穿 | 某个热点 Key 过期,大量请求瞬间打到数据库 | 互斥锁 / 永不过期 + 异步刷新 |
| 雪崩 | 大量 Key 同时过期,或者缓存节点宕机 | 过期时间加随机抖动 / 缓存高可用集群 / 限流降级 |
面试中容易混淆的是击穿和雪崩。区分关键:击穿是一个 Key,雪崩是一批 Key。击穿是"狙击手",雪崩是"地毯式轰炸"。
缓存穿透用布隆过滤器的代价是会有一定的误判率(说存在不一定存在,说不存在一定不存在),而且布隆过滤器不支持删除。如果数据集变化频繁,要考虑用 Counting Bloom Filter 或定期重建。
什么是故障演练?
故障演练(Chaos Engineering / 混沌工程)是 主动在生产或预发环境注入故障,验证系统的容错和恢复能力。
和普通压测不同,压测验证的是"系统能扛多少流量",故障演练验证的是"系统出了问题能不能自动恢复"。
常见演练场景:
- 随机关停一个服务实例,看流量是否自动切换。
- 给某个接口注入延迟,看超时和熔断是否生效。
- 模拟网络分区,看脑裂防护是否工作。
- 模拟 Redis 主节点宕机,看 Sentinel 切换耗时和数据丢失。
故障演练的目的是 在真正的故障发生之前,提前发现系统的薄弱环节。很多公司只在出事后才知道"原来我们的 Sentinel 配置有问题"或者"原来超时是 30 秒而不是 3 秒",这就是缺少故障演练的代价。
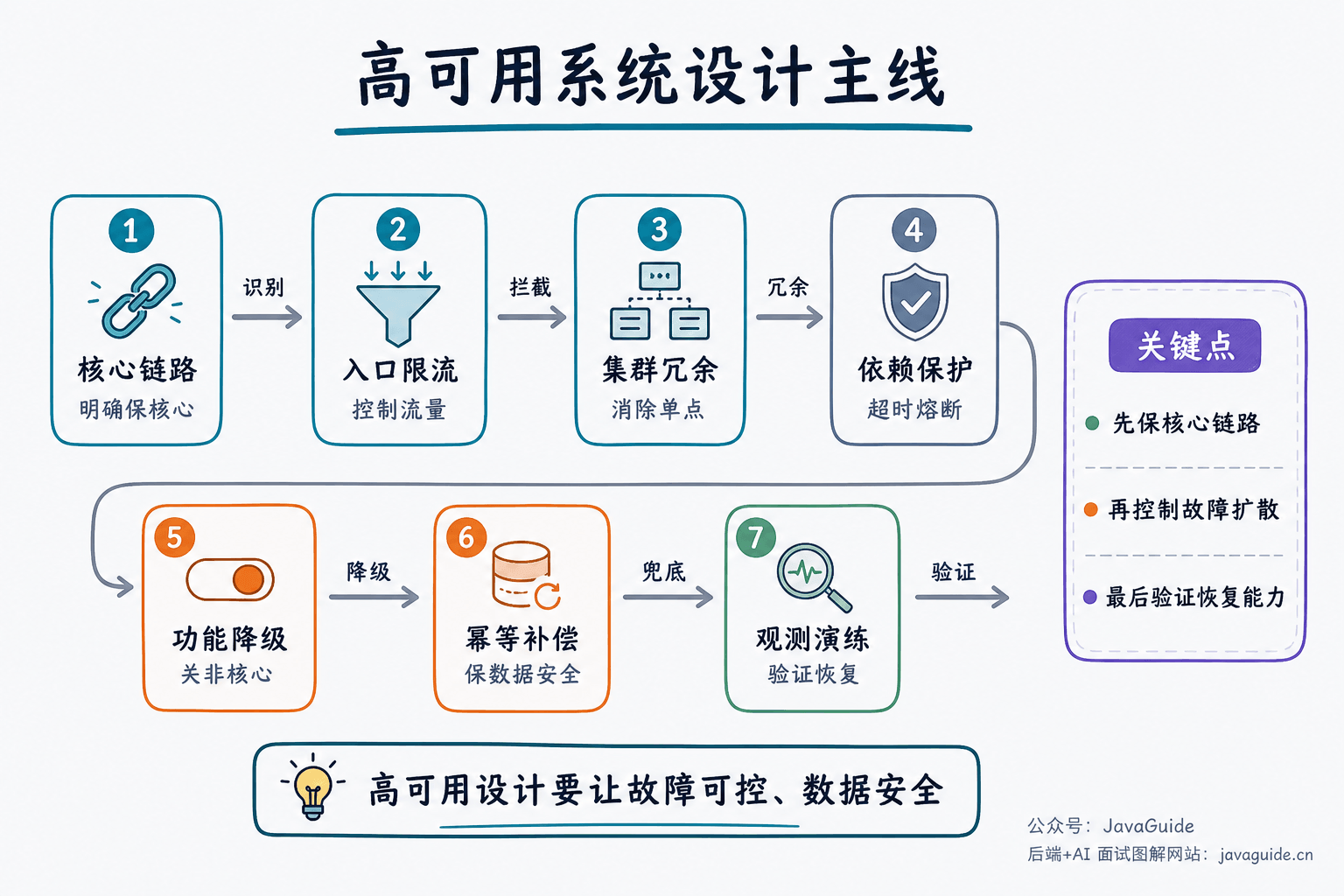
⭐️如何设计一个高可用系统?
可以按这条主线回答:
- 识别核心链路:明确哪些功能必须可用,哪些功能可以降级。
- 消除单点故障:服务、数据库、缓存、MQ、入口网关都要考虑冗余。
- 控制入口流量:限流、排队、削峰,避免流量打穿系统。
- 保护下游依赖:超时、重试、熔断、隔离,避免故障扩散。
- 保证写操作安全:幂等、防重、状态机,避免重复执行。
- 准备降级预案:非核心功能可关闭,核心链路优先保障。
- 建立观测体系:监控、日志、Trace、告警、压测和故障演练。
高可用设计的核心不是承诺系统不会挂,而是让故障发生时影响可控、恢复可控、数据风险可控。
超时和重试上线后,应该关注哪些观测指标?
光配置好超时和重试还不够,上线后必须靠指标验证。关键指标:
| 指标类别 | 具体指标 |
|---|---|
| 请求量 | 原始请求 QPS、重试请求 QPS、重试比例 |
| 延迟 | P99 / P999 延迟、超时率 |
| 成功率 | 最终成功率、首次成功率 |
| 下游健康 | 下游 5xx 数量、限流次数、熔断器状态 |
| 资源 | 线程池队列深度、连接池等待时间、活跃连接数 |
| 重试预算 | Retry Budget 消耗比例 |
其中 首次成功率 vs 最终成功率 的差值特别值得看:如果首次成功率很低但最终成功率还行,说明系统在靠重试续命,下游可能已经不太健康了。这不是"重试做得好",而是"问题被重试掩盖了"。