在微服务架构里,一个请求往往要经过好几个服务的调用链。如果链路上某个服务出了问题——比如响应变慢、超时甚至直接挂掉——很容易把上游的资源也拖垮,最后演变成整条链路雪崩。服务降级和熔断就是应对这类问题的两道防线:降级负责在系统压力大的时候主动"丢车保帅",熔断负责在下游持续异常的时候及时"断路"止损。
这篇文章会把降级和熔断的核心原理讲清楚,包括 Fallback 兜底、降级开关、熔断器状态机、隔离策略,以及 Sentinel、Hystrix、Resilience4j 的选型对比。
什么是降级?
服务降级,说白了就是:系统快扛不住的时候,先牺牲不重要的功能,把资源留给核心链路。
比如电商大促时,推荐模块、广告位、活动氛围图这些非核心功能可以先关掉,但下单、支付、库存扣减这些链路必须尽量保住。用户少看一个推荐还能接受,但下不了单就是真事故。
所以,降级是一套提前设计好的兜底方案,不是系统挂了以后随便返回个默认值。什么时候触发、关哪些功能、返回什么内容、怎么恢复,都应该提前想清楚。
降级一般在什么情况下触发?
很多人会把降级理解成“机器负载太高才降级”,其实不止这一种情况。
常见触发场景有几类:
- 系统整体压力太大,比如 CPU 飙高、线程池打满、接口响应时间明显变长;
- 某个下游服务异常,比如库存服务、价格服务、推荐服务突然大量超时;
- 某个机房、区域或网络链路出问题;
- 大促、秒杀、活动上线前,提前按预案关闭部分非核心功能;
- 运营临时需要控制某些功能入口。
不管触发原因是什么,降级的核心目标都一样:保核心,弃非核心。
降级可以降到什么粒度?
降级的粒度可以粗,也可以细。
粗一点,可以直接降级整个服务。比如推荐服务异常时,所有推荐结果都返回空列表。
细一点,可以只降级页面里的某个区块。比如商品详情页还正常展示,但“猜你喜欢”区域先隐藏。
再细一点,可以只降级某个接口、某个功能开关,甚至某一类用户、某一个业务场景。
实际项目里,通常会给功能分优先级。比如:
- 推荐、广告、排行榜:优先级较低,出问题可以先关;
- 商品详情、购物车:优先级较高,尽量保;
- 下单、支付、库存:核心链路,最后才考虑降级。
这里的 L0-L4、1-10 级都只是团队内部约定,不是行业统一标准。关键不在于怎么命名,而是要提前分清楚:哪些功能可以牺牲,哪些功能必须保。
降级方式有哪些?
1. 延迟处理
有些操作没必要同步完成,可以先放到 MQ 里慢慢处理。
比如评论后发积分、统计用户行为、生成报表,这类操作即使晚几秒完成,用户一般也感知不到。主流程只要先返回成功,后面的事情交给异步任务处理即可。
但这里有个坑:MQ 也可能积压。如果消费者已经处理不过来了,生产者还一直重试,反而会把系统打得更严重。所以重试要加退避和随机抖动,必要时还要限流。
2. 页面片段降级
这是最直观的一种方式:页面主体保留,把非核心区块关掉。
比如商品详情页里,商品标题、价格、库存要保;推荐区、广告位、活动挂件可以先隐藏。
这种方式简单有效,但前提是你提前做好了开关和兜底逻辑。真出问题时再改代码、再发版,基本就来不及了。
3. 接口兜底降级
页面里有些接口是异步加载的,比如配送时效、价格预测、推荐列表。它们如果超时,可以直接返回默认值或缓存值。
比如配送时效接口异常时,可以先展示“预计 2-3 天送达”;推荐接口异常时,可以返回缓存里的热门商品。
这里要注意一点:兜底数据最好提前准备好。不要等接口已经挂了,才临时去查数据库或重新生成缓存,那样很可能把故障继续放大。
4. 页面跳转降级
如果完整页面太重,可以把用户导到一个简版页面或静态页面。
比如大促活动页访问量太大时,可以临时切到静态活动页;系统维护时,可以跳到维护提示页。
这种方案看起来简单,但一定要提前准备好静态页、路由规则和切换开关。线上出事后再临时做,基本不现实。
5. 写降级
写降级适合一些“可以晚一点落库”的场景。
比如积分发放、消息通知、库存流水这类操作,可以先写 Redis、消息表或本地持久化队列,再由 MQ 或定时任务慢慢同步到数据库。
但写降级的代价也比较明显:你要处理最终一致性问题。比如消息有没有丢、数据有没有重复写、同步失败后怎么补偿、对账怎么做,这些都要提前设计。
尤其要注意,纯内存队列不适合保存关键数据。节点一重启,数据就没了。
6. 读降级
读降级通常是“只读缓存,不再访问后端服务”。
比如商品详情、店铺信息、热门榜单这种读多写少的数据,就很适合做缓存兜底。后端服务异常时,先返回缓存里的旧数据,至少页面还能打开。
如果缓存也没命中,就不要继续硬调下游了。可以直接返回默认值、空结果或降级页。否则用户一次请求可能会把一串后端服务都拖进去。
降级开关怎么做?
降级必须能快速打开和关闭。不能每次都靠改代码、发版、重启。
常见方案有这些:
| 方案 | 特点 | 适合场景 |
|---|---|---|
| 配置文件 + 重启 | 简单,但生效慢 | 非紧急、很少变更的开关 |
| 数据库开关表 | 可以做审计,但实时性一般 | 需要记录谁改了、什么时候改的 |
| 配置中心 | 实时性好,生产环境常用 | 核心降级开关、动态开关 |
| Redis 开关 | 实现轻量,接入快 | 简单业务、临时控制 |
生产环境里,更推荐用 Nacos、Apollo 这类配置中心做降级开关。它们比“改配置文件再重启”可靠得多,也更适合应急场景。
不过,这里不要把“实时推送”理解成“所有机器瞬间同时生效”。以 Nacos 为例,2.x 引入了 gRPC 长连接,配置变化可以通过长连接推给客户端,但真正生效仍然受客户端数量、网络、服务端负载、本地缓存刷新等因素影响。
所以降级开关设计时,要默认接受一个事实:不同机器之间可能会有短暂不一致。
用 Nacos 做降级开关时要注意什么?
如果项目里用的是 Nacos,有几个坑要提前知道。
第一,Nacos 2.x 和 1.x 的通信方式不完全一样。Nacos 2.x 新增了 gRPC 通信,所以除了主端口 8848,还会用到 9848、9849 这类端口。官方文档也明确提到,9848 是客户端 gRPC 请求服务端端口,9849 是服务端之间通信端口。
第二,升级时要注意兼容性。Nacos 2.0 服务端可以兼容 1.x 客户端,但 2.x 客户端不能连接 1.x 服务端,因为 2.x 客户端会使用 gRPC。
第三,如果中间有 Docker、防火墙、安全组、Nginx、VIP 之类的网络层,端口映射一定要提前处理。尤其是 9848 端口没放开时,客户端可能会出现连接不上、配置拉不到的问题。官方文档也提到,使用 VIP/Nginx 时需要配置 TCP 转发,不能按普通 HTTP 转发来处理。
第四,网络分区或客户端长连接异常时,客户端可能只能继续使用本地旧配置。所以预案里要写清楚:如果降级开关没有及时推到所有节点,系统应该怎么处理。
这也是为什么降级不能只依赖一个开关。关键链路最好还要配合超时、熔断、限流、缓存兜底一起做。
服务降级有哪些分类?
降级按照是否自动化可分为:
- 自动开关降级(由规则引擎、熔断器、限流器或监控告警触发)
- 人工开关降级(由值班人员或运营预案通过配置平台触发,如秒杀、电商大促等)
自动降级按触发条件分几种常见类型:
- 超时降级:RT 持续超过阈值(阈值可以参考 P99/P999 监控基线,但具体框架触发是逐请求 RT + 窗口聚合,不是直接拿 P99 比较),触发后返回默认值。需要注意幂等性保护,否则重试风暴比原始故障更麻烦。
- 失败降级:异常率超过阈值(比如 50%)时触发,返回兜底数据。兜底数据得提前预热到缓存里。
- 故障降级:下游返回 HTTP 5xx、RPC 异常、DNS 解析失败等硬性错误时触发,返回缓存数据。缓存没命中就直接返回默认值,别再往下调了。
- 限流降级:QPS 超过阈值时触发,返回排队页、无货提示或错误页。排队页需要防重入(幂等令牌),不然用户狂刷就失去意义了。
重试风暴:服务刚恢复,所有客户端同时重试,服务又被打挂。解决办法:带 Jitter 的指数退避、令牌桶限流、分组分批恢复。
大规模分布式系统如何降级?
在大规模分布式系统中,经常会有成百上千的服务。在大促前往往会根据业务的重要程度和业务间的关系批量降级。
降级平台能力
大型互联网公司通常会有统一的降级平台,需要具备这些能力:
- 分级管理:服务按优先级分级(1-10 级或 L0-L4,看团队约定),核心业务必须经过评审,依赖关系要提前梳理清楚。
- 批量降级:按级别或分组批量执行,编排好执行顺序、版本化推送、一键回滚。灰度、预览、审批走完再动手,别一把全关了才发现砍到核心链路。通常不要求严格 2PC 原子性。
- 动态开关:配置中心(Nacos 2.x gRPC 或 Apollo)实时推送,不需要重启。
- 效果验证:灰度 + 监控,指标对比确认降级生效且没误伤。
- 一键回滚:配置版本化,变更审计,出问题了快速回退。
降级预案制定
- 业务分级:先分清哪些服务不能动(如下单、支付),哪些可以关(如推荐、评论),定义优先级
- 依赖分析:画出调用链,找出关键路径和单点依赖——哪个挂了会连累一片
- 降级策略:给每个非核心服务设计降级方案,别忘了失败路径怎么处理
- 演练验证:定期跑降级演练,纸上预案不跑一遍心里没底
网络分区时别纠结理论,想清楚这几件事就行:各服务在分区期间读本地缓存还是拒绝请求、跨区写入要不要停、核心链路怎么保、要不要切成只读模式。
详细介绍: CAP & BASE理论详解。
什么是 Fallback?
Fallback 可以理解成:兜底结果。
正常情况下,请求会去调用真实的业务逻辑,比如查推荐、查商品详情、查用户信息。但如果这次调用失败了,或者被限流、熔断规则拦住了,系统不能直接把异常甩给用户,而是要返回一个提前准备好的结果。
比如推荐服务挂了,就先返回空列表;商品详情接口超时了,就返回缓存里的旧数据;活动页接口异常了,就切到静态页面。
这就是 Fallback 的作用:别让一次失败,把整个链路都拖垮。
不过要注意,Fallback 不是用来“修好问题”的,它只是让系统在异常情况下还能勉强可用。用户看到的内容可能不完整,也可能不是最新的,但至少页面不会直接炸掉。
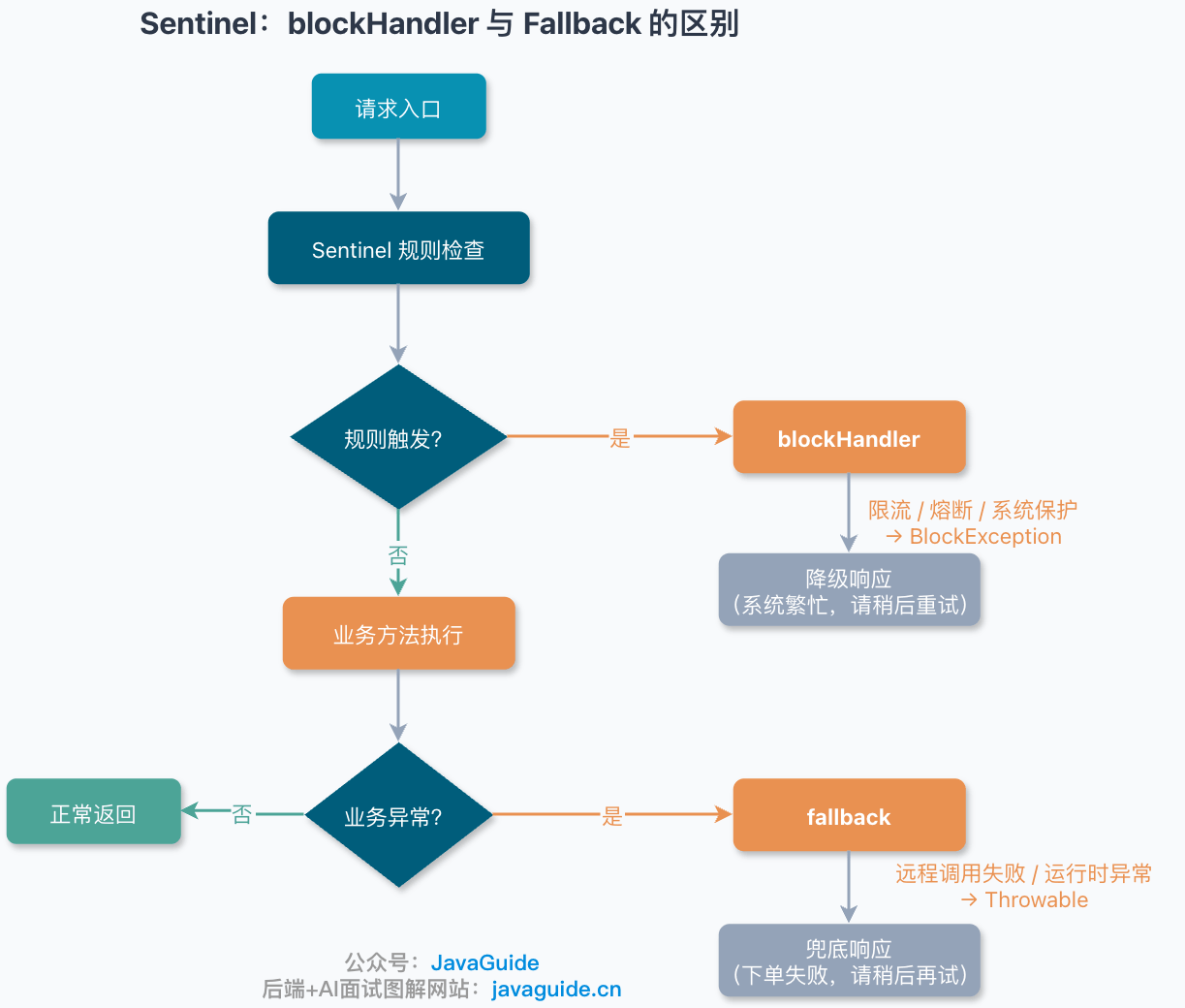
Sentinel 里的 blockHandler 和 fallback 有什么区别?
在 Sentinel 里,blockHandler 和 fallback 很容易被混在一起。它们都像是在“兜底”,但触发原因不一样。
简单说:
| 场景 | 走哪个方法 | 常见异常 |
|---|---|---|
| 被 Sentinel 规则拦住,比如限流、熔断、系统保护 | blockHandler | BlockException |
| 业务代码自己抛异常,比如空指针、远程调用失败、运行时异常 | fallback | Throwable |
举个例子。
接口被限流了,Sentinel 判断这个请求不能继续往下走,这时候进入 blockHandler。
如果请求已经进入业务方法了,但是业务里调用库存服务失败,抛了 RuntimeException,这时候才会进入 fallback。
如果 blockHandler 和 fallback 都配置了,Sentinel 规则触发的异常会优先进入 blockHandler;业务异常才进入 fallback。这一点别搞反,不然排查线上问题时会很绕。
常见的 Fallback 做法
常见的 Fallback 做法有这么几种:
- 默认值返回:直接返回一个静态默认对象。推荐列表为空就返回
[],配置查不到就返回默认配置。注意默认值的结构要跟正常返回一致,别返回 null,不然上游拿到 null 直接 NPE。 - 缓存兜底:读本地缓存或 Redis 里最近一次成功的结果。商品详情、用户信息这种读场景很适合。缓存可能过期,返回的时候最好标注一下数据时效;缓存穿透时别硬撑,兜底到默认值。
- 降级页面:返回静态 HTML 或简化版页面,活动页、营销模块经常这么干。但静态资源本身也要有容灾——CDN 回源失败时的处理得提前想好。
- 写降级:先写 Redis 或本地消息表,异步同步到 DB。秒杀扣减、积分发放等高并发写场景常用。代价是需保证最终一致性(对账/补偿),纯内存队列在节点宕机时会丢数据。
Fallback 常见的坑
Fallback 本身也可能出问题,而且这种问题比正常故障更难发现。常见的坑有这几个:
- Fallback 里面藏了远程调用:兜底逻辑里调了 Redis、DB 或其他服务,结果这些依赖也挂了,雪崩反而加剧。优先用 Caffeine、本地 Map 或静态默认值;非得访问 Redis 的话,用独立连接池、独立超时和独立熔断器,缓存没命中就返回默认值,别再往下串了。
- Fallback 返回 null:上游拿到 null 直接 NPE,引发新的异常链。返回结构要跟正常返回一致,用空对象(Empty Object)而不是 null。
- Fallback 逻辑太复杂:兜底本身变慢,拖垮调用线程。Fallback 逻辑必须极简,禁止复杂业务处理。
- 多个 Fallback 共用同一个缓存:缓存被打满,所有兜底同时失效。按业务维度隔离缓存,核心链路独立缓存实例。
说白了:Fallback 是最后一道防线,必须比正常调用更快更简单。如果兜底里面还藏着同步远程调用且没超时保护,那不是兜底,是埋雷。
什么是熔断?
熔断,名字听起来有点抽象,简单理解就是及时止损。它就是应对微服务雪崩效应的一种链路保护机制,类似电路中的保险丝。
在微服务里,一个服务经常要调用另一个服务。正常情况下,请求一路往下走:
服务 A -> 服务 B -> 服务 C如果服务 C 突然变慢,服务 B 调 C 的线程就会一直等。B 的线程被占满后,A 调 B 也开始超时。再往上,调用 A 的服务也会被拖住。
最后就会出现一种很典型的情况:明明只是服务 C 出了问题,结果整条链路都被拖垮了。
熔断器就是为了解决这个问题。
它的思路很简单:如果发现下游已经明显不正常,就先别继续打它了,直接返回兜底结果。等一段时间后,再放少量请求过去试探一下。如果下游恢复了,再慢慢恢复正常调用。
这有点像电路里的保险丝。电流异常时先断开,避免把后面的设备一起烧坏。
雪崩是怎么发生的?
很多线上雪崩不是一瞬间发生的,而是一层一层传开的。
比如还是这条链路:
服务 A -> 服务 B -> 服务 C一开始可能只是服务 C 响应变慢。比如原来 50ms 返回,现在要 3 秒。
接着,服务 B 调 C 的线程开始排队。线程池里的线程都在等 C 返回,新的请求进来只能继续排队。
再往后,服务 A 调 B 也开始超时。A 自己的线程也被占住,接口响应越来越慢。
如果这时候客户端、RPC 框架或者业务代码还在不停重试,请求量会被进一步放大。最后不是一个服务慢,而是一串服务都慢,整条链路都开始不可用。
这就是雪崩效应。
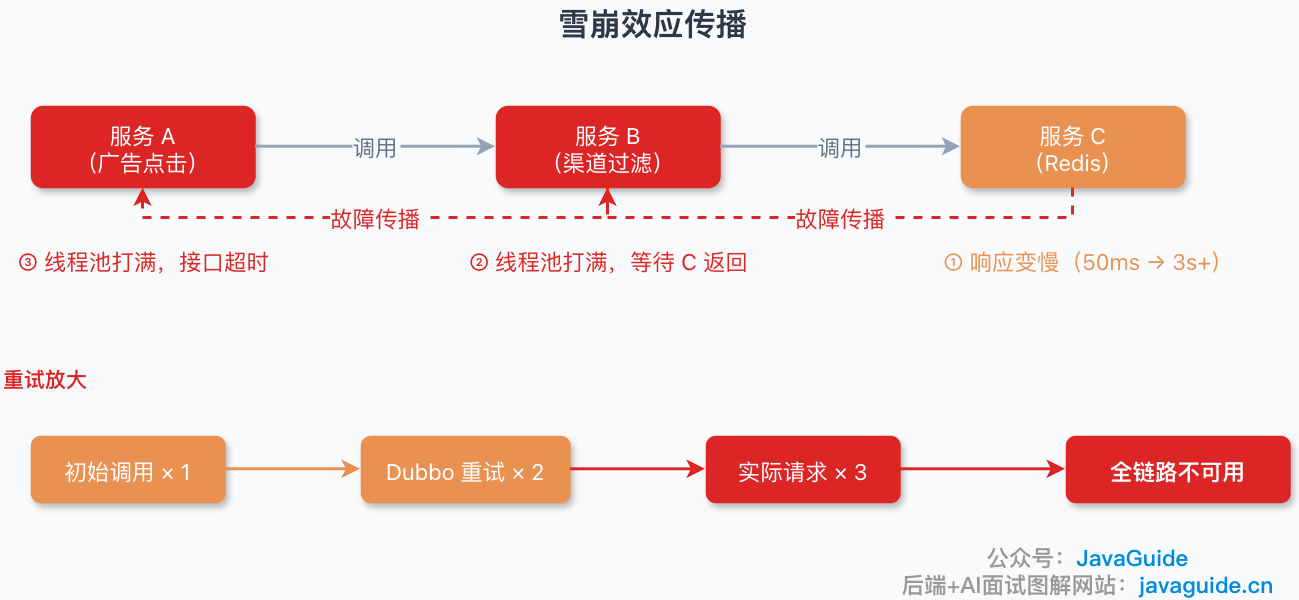
一个更接近真实情况的例子
假设有一个广告点击链路:
广告点击服务 A -> 渠道过滤服务 B -> Redis正常情况下,A 每分钟处理 3-4 万次点击。有一天流量突然涨到 8 万多。
问题一开始出在 B。B 需要从 Redis 里读一段过滤数据,但这个 value 太大,get 一次要 3 秒多。
于是 A 调 B 开始大量超时。
如果 Dubbo 这类 RPC 接口还配置了失败重试,比如一次初始调用后又重试 2 次,那原本 1 次调用就可能变成 3 次调用。这里要注意,具体会不会这样,取决于 Dubbo 版本、接口配置和调用类型。尤其是写接口,一般不建议默认重试,至少要非常谨慎。
重试一多,B 收到的请求更多,线程池更快被打满,然后开始拒绝请求。A 这边继续收到超时和异常,连接、文件句柄、线程资源也被消耗。
最后,原本只是 Redis 读取慢,结果一路拖垮了 A、B 和上游链路。
这类事故里,重试经常是“加速器”。没有限流和熔断时,它会把一个局部故障放大成全链路故障。
所以线上不是不能重试,而是重试必须有边界:要有超时时间、最大次数、退避策略,还要配合限流和熔断。
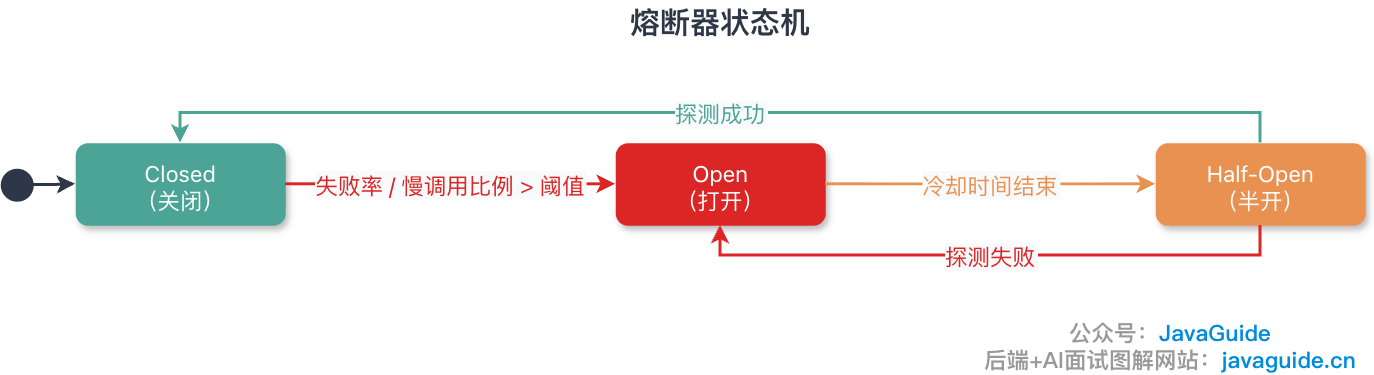
熔断器有哪几种状态?
熔断器包含三种状态:
| 状态 | 说明 | 行为 | 状态转换条件 |
|---|---|---|---|
| Closed(关闭) | 正常状态,允许请求通过 | 记录失败率/慢调用比例 | 失败率/慢调用比例 > 阈值 → Open |
| Open(打开) | 熔断触发,拒绝请求 | 快速返回 Fallback,不再调用下游 | 经过冷却时间(不同框架名称不同,如 Hystrix 的 sleepWindow、Resilience4j 的 waitDurationInOpenState,典型值 10s) → HalfOpen |
| HalfOpen(半开) | 探测服务是否恢复 | 放行少量探路请求(数量取决于框架实现) | 探测请求满足成功条件 → Closed;失败 → Open |
Half-Open 和 Warm Up 不是一回事
这两个概念很容易混。
Half-Open 解决的是:下游到底恢复没有?
Warm Up 解决的是:恢复以后,流量要不要慢慢放?
也就是说,Half-Open 更像“探测”,Warm Up 更像“预热放量”。
比如服务刚重启,缓存还没热,JIT 也没完全稳定,数据库连接池也刚开始建立。这时候即使探测成功,也不代表马上能扛住全部流量。
所以更稳的做法是:
- Half-Open 先放少量请求探测;
- 探测成功后,不要立刻打满流量;
- 再用 Warm Up、限流或者分批放量,让服务慢慢恢复。
Sentinel 的 Warm Up 属于流控里的冷启动策略,默认 coldFactor 是 3,也就是一开始从 threshold / 3 左右的 QPS 慢慢升到配置阈值。
恢复期间不要只看平均耗时。平均值很容易掩盖少量极慢请求。更建议同时盯 P99、P999、线程池活跃数、数据库连接池活跃数和错误率。
Sentinel 支持哪些熔断策略?
Sentinel 1.8.0 之后,熔断降级主要有三类策略:慢调用比例、异常比例、异常数。官方文档里的 DegradeRule 也说明了这些字段,比如 count、timeWindow、minRequestAmount、statIntervalMs、slowRatioThreshold 等。
1. 慢调用比例
这种策略看的是慢请求占比。
比如你设置最大 RT 是 500ms,那么超过 500ms 的请求就算慢调用。接着 Sentinel 会在一个统计窗口里计算慢调用比例。
如果窗口里的请求数达到最小请求数,并且慢调用比例超过阈值,就触发熔断。
这个策略适合处理“下游没报错,但越来越慢”的情况。
2. 异常比例
这种策略看的是失败请求占比。
比如最近一段时间里,请求数量达到最低要求,并且异常比例超过 50%,就触发熔断。
它适合那种下游开始大量报错的场景,比如 RPC 异常、运行时异常、服务端 5xx。
3. 异常数
这种策略看的是异常次数。
比如 1 分钟内异常数超过 50 次,就触发熔断。
它比异常比例更直观,但对流量大小比较敏感。高 QPS 接口和低 QPS 接口不能套同一套阈值。
P99 能不能直接当熔断条件?
不建议这么理解。
P99 是监控指标,适合用来观察接口整体表现,也适合辅助你设置熔断阈值。
但 Sentinel 触发熔断时,不是简单拿 P99 跟阈值比较。它的逻辑更接近:
- 先看单次请求是不是慢调用或异常;
- 再放到统计窗口里计算比例或数量;
- 请求数达到最小阈值后,再判断是否触发熔断。
所以 P99 更适合回答这个问题:我的阈值设得合不合理?
比如某接口平时 P99 是 120ms,你把慢调用阈值设成 100ms,那很可能误伤。
如果平时 P99 是 120ms,突然涨到 800ms,那就说明下游可能真的有问题,熔断阈值也需要结合这个基线来评估。
低 QPS 接口尤其要小心。如果窗口太短、最小请求数太小,一两个偶发慢请求就可能触发熔断。更稳的做法是适当拉长统计窗口,或者提高最小请求数。
降级和熔断有什么区别?
降级和熔断经常被放在一起说,但它们解决的问题不一样。
降级关注的是:系统出问题后,还能以什么方式继续服务用户。
比如推荐服务挂了,商品详情页别跟着白屏,可以先隐藏推荐区;活动接口超时了,可以先展示静态活动页;用户标签查不到,可以先按普通用户处理。
也就是说,降级更像是业务层面的取舍:哪些功能可以先牺牲,哪些核心链路必须保住。
熔断关注的是:下游已经不正常了,还要不要继续调用。
比如订单服务调用库存服务,库存服务已经大量超时。这时候如果还继续打请求,只会让库存服务更慢,也会把订单服务自己的线程池拖死。熔断器发现下游异常后,会先拦住请求,快速返回兜底结果,等一段时间后再放少量请求过去探测。
一句话记:降级是"出了问题后怎么继续服务",熔断是"异常依赖还要不要继续调"。
限流、熔断、降级分别管什么?
这三个概念也很容易混。
限流管入口。 它解决的是"流量太多,要不要都放进来"。比如秒杀时 10 万个请求同时打进来,系统只能扛 1 万个,那就必须拦掉一部分。
熔断管下游。 它解决的是"下游已经慢了或挂了,要不要继续调"。如果继续调,下游恢复不了,自己也会被拖垮。
降级管结果。 它解决的是"请求被限流了、下游被熔断了、业务出异常了,接下来给用户返回什么"。可以返回默认值、缓存数据、静态页面,也可以关闭某个非核心功能。
更口语一点说:
- 限流:别让太多请求进来
- 熔断:别再打已经异常的下游
- 降级:出问题后换一种方式继续服务
- Fallback:真正返回的兜底结果
Fallback 不是一个独立的治理策略,它更像是限流、熔断、降级触发后的"兜底动作"。
打个比方:把系统想象成一个商场。限流就是控制进商场的人数,人太多了先在门口排队;降级就是商场临时关闭餐饮区和电影院,但超市、药店这些核心区域继续营业;熔断就是发现某个供应商出问题了,先暂停向它下单,过一会儿再少量试几单看看恢复没有。
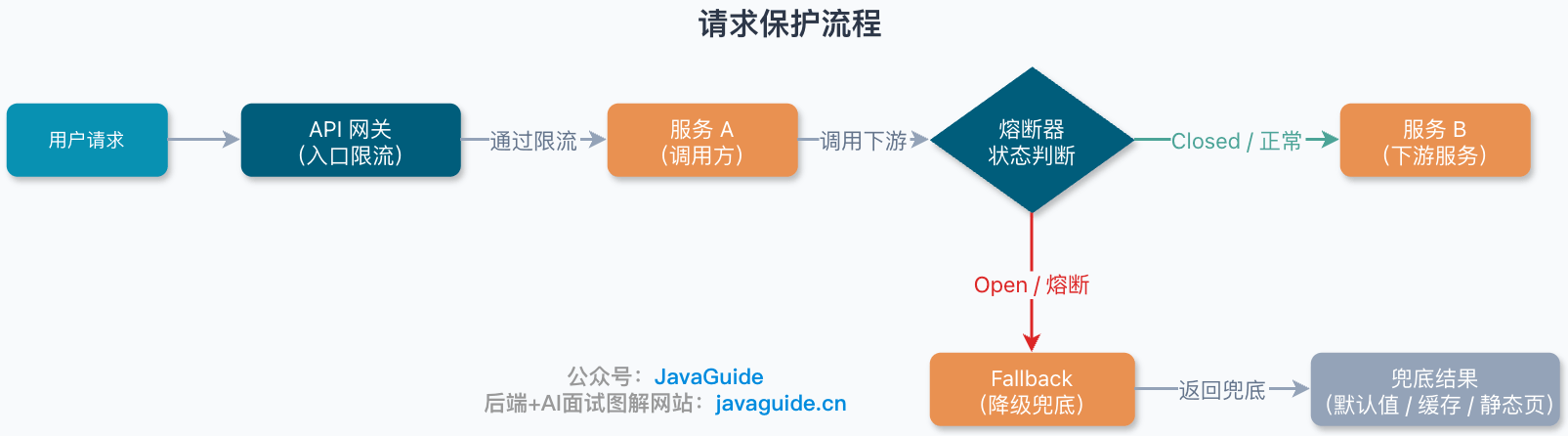
一次请求里它们怎么协同?
一条真实请求链路里,限流、熔断、降级通常是分层生效的。
- 网关/入口限流:请求刚进来时,先判断入口流量有没有超过系统承载能力。如果超过了,直接返回"系统繁忙,请稍后再试",不要让流量继续往后打。
- 服务内限流:有些请求过了网关,但某个服务自己的线程池、连接池、数据库已经快扛不住了,这时服务内部也可以做限流,保护自己的关键资源。
- 熔断器判断:服务准备调用下游之前,先看这个下游是不是已经处于熔断状态。如果已经熔断,就不要继续调了,直接走兜底逻辑。
- 业务执行与 Fallback:下游调用失败、业务代码抛异常,或者规则拦截了请求,就返回提前准备好的兜底结果。比如空列表、缓存数据、默认对象、静态页面。
一句话总结:限流拦入口,熔断断下游,降级保核心,Fallback 给兜底结果。
Sentinel 注解方式的最小示例
下面这个例子先看懂 blockHandler 和 fallback 的分工就行:
@RestController
public class OrderController {
@SentinelResource(
value = "createOrder",
blockHandler = "createOrderBlockHandler",
fallback = "createOrderFallback",
exceptionsToIgnore = {IllegalArgumentException.class}
)
@PostMapping("/order")
public OrderVO createOrder(@RequestBody OrderDTO dto) {
return orderService.create(dto);
}
// 限流、熔断、系统保护等 Sentinel 规则触发时,进入 blockHandler
public OrderVO createOrderBlockHandler(OrderDTO dto, BlockException ex) {
return OrderVO.degraded("当前下单人数过多,请稍后重试");
}
// 业务异常进入 fallback
// 方法签名需要和原方法一致,或者额外多一个 Throwable 参数
public OrderVO createOrderFallback(OrderDTO dto, Throwable t) {
return OrderVO.failure("下单失败,请稍后再试");
}
}有几个点要讲清楚:
blockHandler 处理的是 Sentinel 拦截类异常,比如限流、熔断、系统保护触发后的 BlockException。fallback 处理的是业务代码里抛出来的异常,比如远程调用失败、运行时异常等。它的方法签名要和原方法一致,或者额外加一个 Throwable 参数。
如果 blockHandler 和 fallback 同时配置,Sentinel 规则触发的异常只会进入 blockHandler,不会进入 fallback。这个地方很容易写错。
另外,不是所有业务异常都应该 fallback。比如参数校验失败、权限不足、库存不足,这些本来就应该明确告诉上游,不应该被统一兜底成"系统繁忙"。这类异常可以用 exceptionsToIgnore 排除掉。
有哪些现成解决方案?
Spring Cloud 体系里,常见的熔断、限流、降级方案主要有这几个:
- Hystrix 1.5.18:老牌组件,很多早期 Spring Cloud Netflix 项目都用过。但它已经进入维护模式,不再主动迭代,新项目一般不建议再选。
- Sentinel 1.8.x:阿里开源的流量治理组件,国内 Spring Cloud Alibaba 项目里很常见。它不只是熔断,还包含限流、流量整形、热点参数限流、系统自适应保护等能力。
- Resilience4j 2.x:轻量级容错库,模块拆得比较细,包含熔断、限流、重试、舱壁隔离等能力。Spring Boot 3 / Java 17 项目里经常会考虑它。
- Spring Retry:主要解决重试问题,本身不是完整的熔断降级框架。一般会配合 Spring Cloud CircuitBreaker 或业务超时策略一起用。
版本号最好不要写死。Sentinel、Resilience4j 都还在更新,本文基于发文时可查的 Release,具体以各项目 GitHub Release 页面和版本矩阵为准。
Hystrix、Sentinel、Resilience4j 怎么选?
不用一上来就背功能表,先按项目情况判断。
老项目 Hystrix:能稳定跑就先别急着动,但要规划迁移。
Hystrix 当年很火,线程池隔离、熔断、Fallback 都是它带起来的。但 Netflix 官方已经说明,Hystrix 现在处于维护模式,不再活跃开发。
如果是老项目已经用了 Hystrix,不需要为了"新"马上推倒重来。只要系统稳定,可以先继续用,同时把迁移排进后续 Spring Boot / Spring Cloud 升级计划里。但新项目就没必要再从 Hystrix 开始了,后面升级 Java、Spring Boot、Spring Cloud 时,兼容性成本会越来越高。
Spring Cloud Alibaba / Dubbo 项目:优先看 Sentinel。
Sentinel 的优势不是单纯"能熔断",而是它围绕流量治理做得比较完整。它支持限流、熔断降级、热点参数限流、系统自适应保护,也有控制台可以看实时监控和配置规则。对 Spring Cloud Alibaba、Dubbo 这类项目来说,接入成本通常更低。
但也别把 Sentinel Dashboard 当成生产配置中心。Dashboard 更适合做规则管理和查看效果,生产环境通常还要接 Nacos、Apollo 等数据源做规则持久化,否则重启后规则可能丢。
Spring Boot 3 / Java 17+ 新项目:可以优先看 Resilience4j。
Resilience4j 的特点是轻量、模块化。你需要熔断,就引 CircuitBreaker;需要限流,就引 RateLimiter;需要重试,就引 Retry;需要隔离,就引 Bulkhead。
它和函数式编程、Reactor、Spring Boot 3 的组合会更自然一些。如果你的项目是 Spring Boot 3、Java 17+,又不依赖 Spring Cloud Alibaba 生态,Resilience4j 通常是更干净的选择。
简单对比
| 维度 | Sentinel | Hystrix | Resilience4j |
|---|---|---|---|
| 维护状态 | 活跃维护 | 维护模式 | 活跃维护 |
| 主要定位 | 流量治理组件 | 熔断降级组件 | 轻量级容错库 |
| 熔断能力 | 慢调用比例、异常比例、异常数 | 异常比例为主 | 异常比例、慢调用、异常数等 |
| 限流能力 | 强,支持 QPS、并发线程、热点参数等 | 较弱 | 有 RateLimiter 模块 |
| 隔离能力 | 并发线程数控制 | 线程池隔离 / 信号量隔离 | SemaphoreBulkhead / ThreadPoolBulkhead |
| 流量整形 | 支持 Warm Up、匀速排队 | 不突出 | 不突出 |
| 系统自适应保护 | 支持 | 不支持 | 不支持 |
| 控制台 | 有 Sentinel Dashboard | Hystrix Dashboard 已过时 | 通常自行接监控体系 |
| 适合场景 | Spring Cloud Alibaba、Dubbo、国内 Java 项目 | 存量老项目 | Spring Boot 3、Java 17+、轻量化项目 |
初学者只要记住三点:老项目 Hystrix 能稳定跑就先别急着动;Spring Cloud Alibaba / Dubbo 项目优先看 Sentinel;Spring Boot 3 / Java 17+ 新项目可以优先看 Resilience4j。
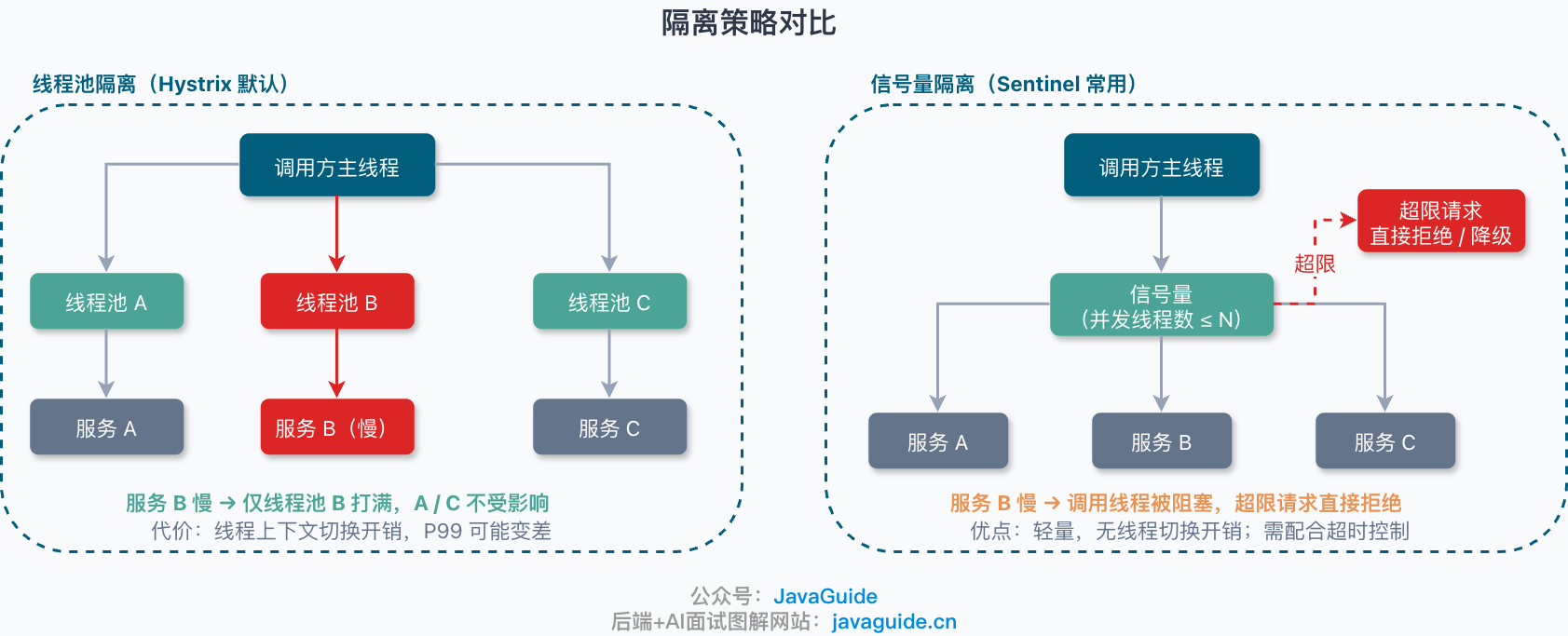
隔离策略怎么理解?
熔断只是"不继续调异常下游",隔离解决的是"别让一个依赖把所有资源吃光"。
线程池隔离:给某个下游依赖单独分一个线程池。比如订单服务要调用库存服务,就让库存调用走自己的线程池。库存服务慢了,最多把这个线程池打满,不会把订单服务的主线程池一起拖死。优点是隔离更彻底,坏处是成本更高——线程多了以后会有上下文切换开销,线程池大小也不好估,P99 可能变差。Hystrix 默认就是线程池隔离。
信号量隔离:限制同时进来的请求数量。比如最多允许 100 个请求同时调用库存服务,超过就直接拒绝或降级。优点是轻量,不需要把业务调用切到另一个线程池里。缺点是如果下游调用本身一直阻塞,业务线程还是会被占住,所以通常要配合超时控制一起用。Sentinel 常见的并发线程数控制更接近信号量隔离的思路。
线程池隔离的代价不是很多人以为的"GC 扫描",而是上下文切换。线程多了,CPU 在线程间频繁调度唤醒和挂起,sy 飙高,P99 尾延迟跟着恶化。到底严不严重,得看线程数、CPU sy/us 比例、队列等待时间和 P99 指标,别光凭感觉。
Sentinel 的系统自适应保护是什么?
普通限流通常是手动设置一个阈值,比如 QPS 超过 1000 就限流。但真实系统不是这么简单,CPU、Load、RT、线程数、入口 QPS 都会影响系统是否已经接近极限。
Sentinel 的系统自适应保护就是想解决这个问题:不只看单个接口,而是从整个系统负载角度判断要不要拒绝部分请求。官方文档里说这个思路受 TCP BBR 启发,目标是在保证系统可靠的前提下维持较高吞吐。但别把它理解成完整的 TCP BBR——Sentinel 是借鉴思路,结合实时统计和规则阈值做保护,不是像 TCP 那样动态探测带宽、调整拥塞窗口。
可以粗略理解成:
当前并发请求数 > 系统最大 QPS × 最小 RT
如果当前在途请求已经超过系统估算的承载能力,就开始拒绝一部分流量。系统规则还可以按这些指标配置:
| 指标 | 说明 | 常见用法 |
|---|---|---|
| Load | Linux load1 值 | Load 明显高于 CPU 核数时触发保护 |
| 平均 RT | 入口流量平均响应时间 | 平均耗时持续升高时保护系统 |
| 并发线程数 | 当前处理中的请求数 | 防止线程资源被打满 |
| 入口 QPS | 入口流量大小 | 控制整体入口压力 |
有个坑要注意:Sentinel 系统规则看的是平均 RT,不是 P99。平均值会掩盖长尾延迟,所以生产环境最好额外接 P99、P999、线程池、连接池、错误率这些监控。
选型建议
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 存量 Hystrix 项目 | 先继续用,规划迁移 | 不要为了替换而替换,优先保证稳定 |
| Spring Cloud Alibaba 项目 | Sentinel | 生态适配好,控制台和规则模型更完整 |
| Dubbo 项目 | Sentinel | 接入和流量治理能力比较成熟 |
| Spring Boot 3 / Java 17+ 新项目 | Resilience4j 或 Sentinel | Resilience4j 更轻量,Sentinel 治理能力更完整 |
| 只需要重试 | Spring Retry / Resilience4j Retry | 不要为了重试引完整治理框架 |
| 需要系统级过载保护 | Sentinel,或网关 / Service Mesh / 自研平台 | Sentinel 三者里更完整,但不是唯一方案 |
如果团队已经在用 Nacos、Spring Cloud Alibaba,选 Sentinel 的成本会比较低。如果团队偏原生 Spring Boot 3、Micrometer、Prometheus 这套监控体系,Resilience4j 往往更自然。
Hystrix 迁移到 Sentinel 要注意什么?
老项目从 Hystrix 迁到 Sentinel,不是简单把注解换一下。
1. Fallback 要拆开。 Hystrix 里很多项目只有一个 fallbackMethod,限流、熔断、业务异常最后都走同一套兜底。Sentinel 里要分清:blockHandler 处理 Sentinel 规则拦截(限流、熔断、系统保护),fallback 处理业务代码抛出的异常。迁移时,原来的 fallback 逻辑最好拆一拆,不要混在一起。
2. 隔离模型不一样。 Hystrix 默认线程池隔离,很多调用实际是在 Hystrix 线程池里跑的。Sentinel 更常见的是并发线程数控制,不会天然把下游调用切到独立线程池里。迁移后要重新检查超时、中断、线程池隔离这些能力,尤其是慢下游调用,如果没有单独超时控制,只靠 Sentinel 并发线程数限制不够。
3. 规则配置方式不一样。 Hystrix 很多规则写在代码或配置文件里。Sentinel 更推荐把规则动态化,比如通过 Dashboard 管理,再接 Nacos、Apollo 等数据源做持久化和推送。生产环境不要只依赖 Dashboard 内存规则,否则服务重启、控制台重启后可能有规则丢失风险。
4. 监控体系要重新接。 Hystrix 时代常见的是 Hystrix Dashboard + Turbine。迁到 Sentinel 后,可以先用 Sentinel Dashboard 看实时调用和规则效果,但生产上通常还要把指标接到 Prometheus、Grafana 或公司内部监控平台。如果用了集群限流,还要额外考虑 Token Server 的部署和可用性。
迁移最好跟着 Spring Boot / Spring Cloud 大版本升级一起做,单独迁移容易踩兼容性坑。如果存量系统到处都是 Hystrix 注解,可以先试 Sentinel 的 Hystrix adapter 过渡一下,但这个 adapter 本身的维护状态也要看一眼再决定。
小结
新项目一般不建议再选 Hystrix,它已经进入维护模式,更适合作为存量系统的过渡方案。如果项目在 Spring Cloud Alibaba、Nacos、Dubbo 这条技术线上,Sentinel 通常更顺手。如果是 Spring Boot 3 / Java 17+ 的新项目,团队又更偏 Micrometer、Prometheus、Reactor 这套生态,Resilience4j 会更轻量。
真正选型时别只看"谁功能多",要看团队技术栈、Spring Cloud 版本、监控体系、规则是否要动态下发,以及后续谁来维护。