Java基础常见面试题总结(下)
异常
Java 异常类层次结构图概览:
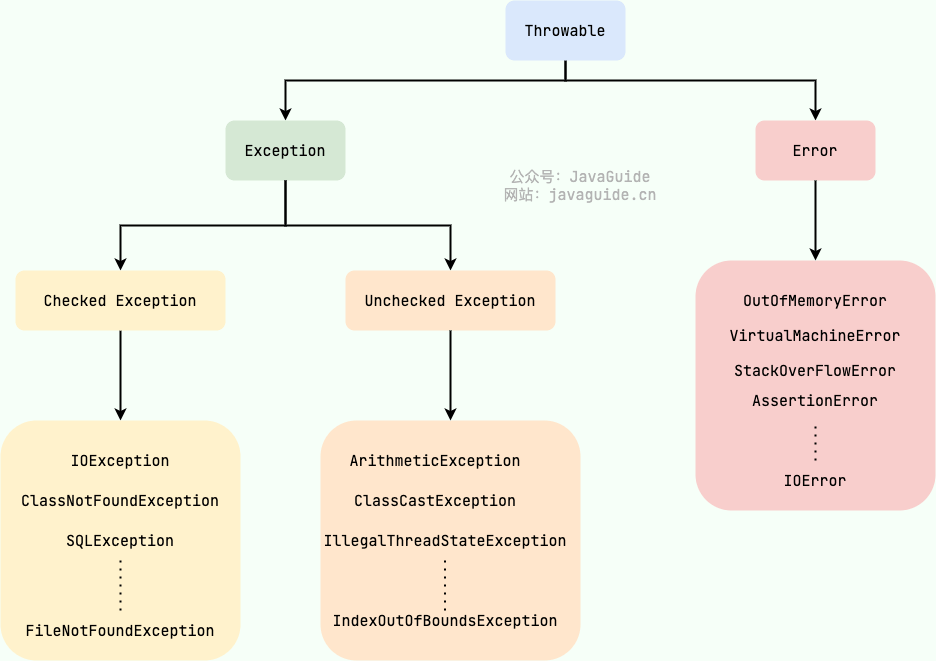
Exception 和 Error 有什么区别?
在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类:
Exception:程序本身可以处理的异常,可以通过catch来进行捕获。Exception又可以分为 Checked Exception(受检查异常,必须处理) 和 Unchecked Exception(不受检查异常,可以不处理)。Error:Error属于程序无法处理的错误,我们没办法通过不建议通过catch来进行捕获catch捕获。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
ClassNotFoundException 和 NoClassDefFoundError 的区别
ClassNotFoundException是 Exception,发生在使用反射等动态加载时找不到类,是可预期的,可以捕获处理。NoClassDefFoundError是 Error,表示 JVM 或类加载器尝试加载类定义时找不到该定义。除了运行时缺少 JAR,还可能由类初始化失败后再次使用该类等情况触发。它通常会终止当前线程,但不等于整个 JVM 必然无法继续运行。
⭐️ Checked Exception 和 Unchecked Exception 有什么区别?
Checked Exception 即 受检查异常,Java 代码在编译过程中,如果受检查异常没有被 catch 或者 throws 关键字处理的话,就没办法通过编译。
比如下面这段 IO 操作的代码:
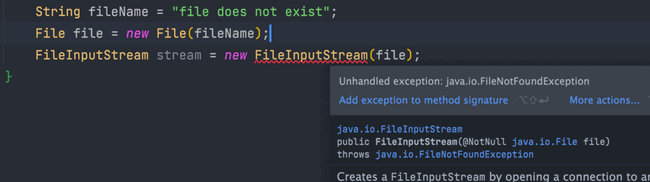
除了 RuntimeException 及其子类以外,其他的 Exception 类及其子类都属于受检查异常。常见的受检查异常有:IO 相关的异常、ClassNotFoundException、SQLException...。
Unchecked Exception 即 不受检查异常,Java 代码在编译过程中,我们即使不处理不受检查异常也可以正常通过编译。
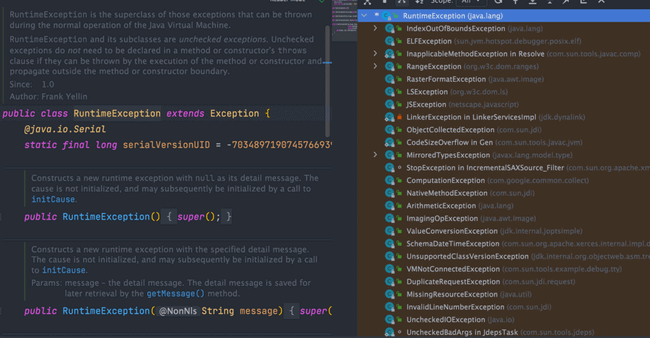
RuntimeException 及其子类属于非受检查异常;从 JLS 的分类来看,Error 及其子类也属于非受检查异常。常见的 RuntimeException 有:
NullPointerException(空指针错误)IllegalArgumentException(参数错误比如方法入参类型错误)NumberFormatException(字符串转换为数字格式错误,IllegalArgumentException的子类)ArrayIndexOutOfBoundsException(数组越界错误)ClassCastException(类型转换错误)ArithmeticException(算术错误)SecurityException(安全错误比如权限不够)UnsupportedOperationException(不支持的操作错误比如重复创建同一用户)- ……
你更倾向于使用 Checked Exception 还是 Unchecked Exception?
默认使用 Unchecked Exception,只在必要时才用 Checked Exception。
我们可以把 Unchecked Exception(比如 NullPointerException)看作是代码 Bug。对待 Bug,最好的方式是让它暴露出来然后去修复代码,而不是用 try-catch 去掩盖它。
一般来说,只在一种情况下使用 Checked Exception:当这个异常是业务逻辑的一部分,并且调用方必须处理它时。比如说,一个余额不足异常。这不是 bug,而是一个正常的业务分支,我需要用 Checked Exception 来强制调用者去处理这种情况,比如提示用户去充值。这样就能在保证关键业务逻辑完整性的同时,让代码尽可能保持简洁。
Throwable 类常用方法有哪些?
String getMessage(): 返回异常发生时的详细信息String toString(): 返回异常发生时的简要描述String getLocalizedMessage(): 返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同void printStackTrace(): 在控制台上打印Throwable对象封装的异常信息
try-catch-finally 如何使用?
try块:用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。catch块:用于处理 try 捕获到的异常。finally块:无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return语句时,finally语句块将在方法返回之前被执行。
代码示例:
try {
System.out.println("Try to do something");
throw new RuntimeException("RuntimeException");
} catch (Exception e) {
System.out.println("Catch Exception -> " + e.getMessage());
} finally {
System.out.println("Finally");
}输出:
Try to do something
Catch Exception -> RuntimeException
Finally注意:不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
代码示例:
public static void main(String[] args) {
System.out.println(f(2));
}
public static int f(int value) {
try {
return value * value;
} finally {
if (value == 2) {
return 0;
}
}
}输出:
0finally 中的代码一定会执行吗?
不一定的!在某些情况下,finally 中的代码不会被执行。
就比如说 finally 之前虚拟机被终止运行的话,finally 中的代码就不会被执行。
try {
System.out.println("Try to do something");
throw new RuntimeException("RuntimeException");
} catch (Exception e) {
System.out.println("Catch Exception -> " + e.getMessage());
// 终止当前正在运行的Java虚拟机
System.exit(1);
} finally {
System.out.println("Finally");
}输出:
Try to do something
Catch Exception -> RuntimeException另外,如果 JVM 进程被强制终止,例如调用 Runtime.halt()、操作系统直接结束进程或机器掉电,finally 块也可能来不及执行。普通的未捕获异常即使最终导致当前线程结束,在线程结束前仍会按语言规则执行 finally。
相关 issue:https://github.com/Snailclimb/JavaGuide/issues/190。
🧗🏻 进阶一下:从字节码角度分析 try catch finally 这个语法糖背后的实现原理。
如何使用 try-with-resources 代替 try-catch-finally?
- 适用范围(资源的定义): 任何实现
java.lang.AutoCloseable或者java.io.Closeable的对象 - 关闭资源和 finally 块的执行顺序: 在
try-with-resources语句中,任何 catch 或 finally 块在声明的资源关闭后运行
《Effective Java》中明确指出:
面对必须要关闭的资源,我们总是应该优先使用
try-with-resources而不是try-finally。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。try-with-resources语句让我们更容易编写必须要关闭的资源的代码,若采用try-finally则几乎做不到这点。
Java 中类似于 InputStream、OutputStream、Scanner、PrintWriter 等的资源都需要我们调用 close() 方法来手动关闭,一般情况下我们都是通过 try-catch-finally 语句来实现这个需求,如下:
//读取文本文件的内容
Scanner scanner = null;
try {
scanner = new Scanner(new File("D://read.txt"));
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (scanner != null) {
scanner.close();
}
}使用 Java 7 之后的 try-with-resources 语句改造上面的代码:
try (Scanner scanner = new Scanner(new File("test.txt"))) {
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException fnfe) {
fnfe.printStackTrace();
}当然多个资源需要关闭的时候,使用 try-with-resources 实现起来也非常简单,如果你还是用 try-catch-finally 可能会带来很多问题。
通过使用分号分隔,可以在 try-with-resources 块中声明多个资源。
try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt")));
BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) {
int b;
while ((b = bin.read()) != -1) {
bout.write(b);
}
}
catch (IOException e) {
e.printStackTrace();
}⭐️ 异常使用有哪些需要注意的地方?
- 不要把异常定义为静态变量,因为这样会导致异常栈信息错乱。每次手动抛出异常,我们都需要手动 new 一个异常对象抛出。
- 抛出的异常信息一定要有意义。
- 建议抛出更加具体的异常,比如字符串转换为数字格式错误的时候应该抛出
NumberFormatException而不是其父类IllegalArgumentException。 - 避免重复记录日志:如果在捕获异常的地方已经记录了足够的信息(包括异常类型、错误信息和堆栈跟踪等),那么在业务代码中再次抛出这个异常时,就不应该再次记录相同的错误信息。重复记录日志会使得日志文件膨胀,并且可能会掩盖问题的实际原因,使得问题更难以追踪和解决。
- ……
泛型
什么是泛型?有什么作用?
Java 泛型(Generics) 是 JDK 5 中引入的一个新特性。使用泛型参数,可以增强代码的可读性以及稳定性。
编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型。比如 ArrayList<Person> persons = new ArrayList<Person>() 这行代码就指明了该 ArrayList 对象只能传入 Person 对象,如果传入其他类型的对象就会报错。
ArrayList<E> extends AbstractList<E>并且,原生 List 返回类型是 Object,需要手动转换类型才能使用,使用泛型后编译器自动转换。
泛型的使用方式有哪几种?
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
1.泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}如何实例化泛型类:
Generic<Integer> genericInteger = new Generic<Integer>(123456);2.泛型接口:
public interface Generator<T> {
public T method();
}实现泛型接口,不指定类型:
class GeneratorImpl<T> implements Generator<T>{
@Override
public T method() {
return null;
}
}实现泛型接口,指定类型:
class GeneratorImpl implements Generator<String> {
@Override
public String method() {
return "hello";
}
}3.泛型方法:
public static < E > void printArray( E[] inputArray )
{
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}使用:
// 创建不同类型数组:Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { "Hello", "World" };
printArray( intArray );
printArray( stringArray );注意:
public static <E> void printArray(E[] inputArray)是静态泛型方法。静态上下文没有当前实例,因此不能引用类声明的类型参数;这与“静态方法先加载”无关。静态方法可以声明并使用自己的类型参数<E>。
项目中哪里用到了泛型?
- 自定义接口通用返回结果
CommonResult<T>通过参数T可根据具体的返回类型动态指定结果的数据类型 - 定义
Excel处理类ExcelUtil<T>用于动态指定Excel导出的数据类型 - 构建集合工具类(参考
Collections中的sort,binarySearch方法)。 - ……
⭐️ 反射
关于反射的详细解读,请看这篇文章 Java 反射机制详解。
什么是反射?
简单来说,Java 反射 (Reflection) 是一种在程序运行时,动态地获取类的信息并操作类或对象(方法、属性)的能力。
通常情况下,我们写的代码在编译时类型就已经确定了,要调用哪个方法、访问哪个字段都是明确的。但反射允许我们在运行时才去探知一个类有哪些方法、哪些属性、它的构造函数是怎样的,并在访问控制和模块边界允许的情况下动态创建对象、调用方法或修改属性。
正是这种在运行时“反观自身”并进行操作的能力,使得反射成为许多通用框架和库的基石。它让代码更加灵活,能够处理在编译时未知的类型。
反射有什么优缺点?
优点:
- 灵活性和动态性:反射允许程序在运行时动态地加载类、创建对象、调用方法和访问字段,根据实际需求(如配置文件、用户输入、注解等)动态地适应和扩展程序的行为。许多现代 Java 框架(如 Spring、Hibernate、MyBatis)正是基于这一特性来实现依赖注入(DI)、面向切面编程(AOP)、对象关系映射(ORM)、注解处理等核心功能,可以说反射是框架开发不可或缺的基础。
- 解耦合和通用性:通过反射,可以编写更通用、可重用和高度解耦的代码,降低模块之间的依赖。例如,可以通过反射实现通用的对象拷贝、序列化、Bean 工具等。
缺点:
- 性能开销:反射操作通常比直接代码调用要慢。因为涉及到动态类型解析、方法查找以及 JIT 编译器的优化受限等因素。不过,对于大多数框架场景,这种性能损耗通常是可以接受的,或者框架本身会做一些缓存优化。
- 安全性问题:反射在满足访问检查、模块开放关系等条件时,可以抑制部分 Java 语言访问检查(如访问
private字段和方法),可能破坏封装性。此外,反射还可能绕过编译期泛型检查,带来类型安全隐患。Java 9 及之后的模块边界可能拒绝此类深层反射访问并抛出InaccessibleObjectException。 - 代码可读性和维护性:过度使用反射会使代码变得复杂、难以理解和调试。错误通常在运行时才会暴露,不像编译期错误那样容易发现。
相关阅读:Java Reflection: Why is it so slow?。
反射的应用场景?
我们平时写业务代码可能很少直接跟 Java 的反射(Reflection)打交道。但你可能没意识到,你天天都在享受反射带来的便利!很多流行的框架,比如 Spring/Spring Boot、MyBatis 等,底层都大量运用了反射机制,这才让它们能够那么灵活和强大。
下面简单列举几个最常见的场景帮助大家理解。
1.依赖注入与控制反转(IoC)
以 Spring/Spring Boot 为代表的 IoC 框架,会在启动时扫描带有特定注解(如 @Component, @Service, @Repository, @Controller)的类,利用反射实例化对象(Bean),并通过反射注入依赖(如 @Autowired、构造器注入等)。
2.注解处理
注解本身只是个“标记”,得有人去读这个标记才知道要做什么。反射就是那个“读取器”。框架通过反射检查类、方法、字段上有没有特定的注解,然后根据注解信息执行相应的逻辑。比如,看到 @Value,就用反射读取注解内容,去配置文件找对应的值,再用反射把值设置给字段。
3.动态代理与 AOP
想在调用某个方法前后自动加点料(比如打日志、开事务、做权限检查)?AOP(面向切面编程)就是干这个的,而动态代理是实现 AOP 的常用手段。JDK 自带的动态代理(Proxy 和 InvocationHandler)就离不开反射。代理对象在内部调用真实对象的方法时,就是通过反射的 Method.invoke 来完成的。
public class DebugInvocationHandler implements InvocationHandler {
private final Object target; // 真实对象
public DebugInvocationHandler(Object target) { this.target = target; }
// proxy: 代理对象, method: 被调用的方法, args: 方法参数
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("切面逻辑:调用方法 " + method.getName() + " 之前");
// 通过反射调用真实对象的同名方法
Object result = method.invoke(target, args);
System.out.println("切面逻辑:调用方法 " + method.getName() + " 之后");
return result;
}
}4.对象关系映射(ORM)
像 MyBatis、Hibernate 这种框架,能帮你把数据库查出来的一行行数据,自动变成一个个 Java 对象。它是怎么知道数据库字段对应哪个 Java 属性的?还是靠反射。它通过反射获取 Java 类的属性列表,然后把查询结果按名字或配置对应起来,再用反射调用 setter 或直接修改字段值。反过来,保存对象到数据库时,也是用反射读取属性值来拼 SQL。
代理
关于 Java 代理的详细介绍,可以看看笔者写的 [Java 代理模式详解](https://javaguide.cn/java/basis/proxy.html “Java 代理模式详解”)这篇文章。
如何实现动态代理?
动态代理是一种非常强大的设计模式,它允许我们在不修改源代码的情况下,对一个类或对象的方法进行功能增强(Enhancement)。
在 Java 中,实现动态代理最主流的方式有两种:JDK 动态代理 和 CGLIB 动态代理。
第一种:JDK 动态代理
Java 官方提供的,其核心要求是目标类必须实现一个或多个接口。JDK 动态代理在运行时,会利用 Proxy.newProxyInstance() 方法,动态地创建一个实现了这些接口的代理类的实例。这个代理类在内存中生成,你看不到它的 .java 或 .class 文件。
当你调用代理对象的任何一个方法时,这个调用都会被转发到我们提供的一个 InvocationHandler 接口的 invoke 方法中。在 invoke 方法里,我们就可以在调用原始方法(目标方法)之前或之后,加入我们自己的增强逻辑。
第二种:CGLIB 动态代理
CGLIB 是一个第三方的代码生成库。它的原理与 JDK 完全不同,它不要求被代理的类实现接口。它在运行时,动态生成目标类的子类作为代理类(通过 ASM 字节码操作技术)。然后,它会重写父类(也就是被代理类)中所有非 final、private 和 static 的方法。
当你调用代理对象的任何一个方法时,这个调用会被 CGLIB 的 MethodInterceptor 接口的 intercept 方法拦截。和 InvocationHandler 的 invoke 方法一样,我们可以在 intercept 方法里,在调用原始的父类方法之前或之后,加入我们的增强逻辑。
静态代理和动态代理有什么区别?
静态代理和动态代理的核心差异在于 代理关系的确定时机、实现灵活性及维护成本。
| 对比维度 | 静态代理 (Static Proxy) | 动态代理 (Dynamic Proxy) |
|---|---|---|
| 代理关系确定时机 | 编译期(编译后生成固定的 .class 字节码文件) | 运行时(动态生成代理类字节码并加载到 JVM) |
| 实现方式 | 在编译前手动编写代理类,常通过组合和委托调用目标对象 | 无需手动编写具体代理类,通过 Handler/Interceptor 封装增强逻辑 |
| 接口依赖 | 不是必须;基于接口的静态代理通常让代理类与目标类遵循同一接口 | JDK 动态代理面向接口,CGLIB 等子类代理面向可继承的实现类 |
| 代码量与维护性 | 代码量大(目标类越多,代理类越多),维护成本高;接口新增方法时,目标类与代理类需同步修改 | 代码量极少(通用增强逻辑可复用),维护性好;与接口解耦,接口变更不影响代理逻辑 |
| 核心优势 | 实现简单、逻辑直观,无额外框架依赖 | 灵活性强、复用性高,降低重复编码,适配复杂场景 |
| 典型应用场景 | 简单的装饰器模式、少量固定类的增强需求 | Spring AOP、RPC 框架(如 Dubbo)、ORM 框架 |
⭐️ JDK 动态代理和 CGLIB 动态代理有什么区别?
- JDK 动态代理是官方的,它要求被代理的类必须实现接口。它的原理是动态生成一个接口的实现类来作为代理。CGLIB 是第三方的,它不需要接口。它的原理是动态生成一个被代理类的子类来作为代理。但也正因为是继承,所以它不能代理
final的类,被代理的方法也不能是final或private。 - 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
⭐️ 介绍一下动态代理在框架中的实际应用场景
动态代理最典型的应用场景就是Spring AOP。
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
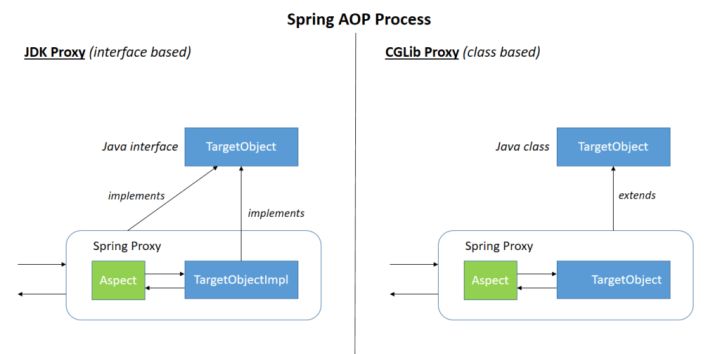
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
注解
何谓注解?
Annotation(注解) 是 Java5 开始引入的新特性,可以看作是一种特殊的注释,主要用于修饰类、方法或者变量,提供某些信息供程序在编译或者运行时使用。
注解本质是一个继承了 Annotation 的特殊接口:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
public interface Override extends Annotation{
}JDK 提供了很多内置的注解(比如 @Override、@Deprecated),同时,我们还可以自定义注解。
注解的解析方法有哪几种?
注解只有被解析之后才会生效,常见的解析方法有两种:
- 编译期直接扫描:编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用
@Override注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。 - 运行期通过反射处理:像框架中自带的注解(比如 Spring 框架的
@Value、@Component)都是通过反射来进行处理的。
⭐️ SPI
关于 SPI 的详细解读,请看这篇文章 Java SPI 机制详解。
何谓 SPI?
SPI 即 Service Provider Interface,字面意思就是:“服务提供者的接口”,我的理解是:专门提供给服务提供者或者扩展框架功能的开发者去使用的一个接口。
SPI 将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。修改或者替换服务实现并不需要修改调用方。
很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及 Dubbo 的扩展实现等等。

SPI 和 API 有什么区别?
那 SPI 和 API 有啥区别?
说到 SPI 就不得不说一下 API(Application Programming Interface) 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
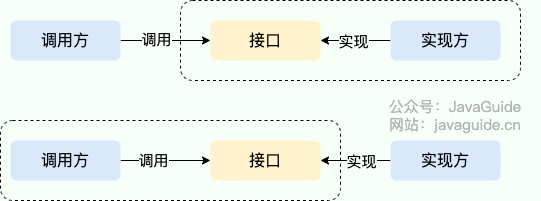
一般模块之间都是通过接口进行通讯,因此我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
- 当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API。这种情况下,接口和实现都是放在实现方的包中。调用方通过接口调用实现方的功能,而不需要关心具体的实现细节。
- 当接口存在于调用方这边时,这就是 SPI。由接口调用方确定接口规则,然后由不同的厂商根据这个规则对这个接口进行实现,从而提供服务。
举个通俗易懂的例子:公司 H 是一家科技公司,新设计了一款芯片,然后现在需要量产了,而市面上有好几家芯片制造业公司,这个时候,只要 H 公司指定好了这芯片生产的标准(定义好了接口标准),那么这些合作的芯片公司(服务提供者)就按照标准交付自家特色的芯片(提供不同方案的实现,但是给出来的结果是一样的)。
SPI 的优缺点?
通过 SPI 机制能够大大地提高接口设计的灵活性,但是 SPI 机制也存在一些缺点,比如:
ServiceLoader会按需定位并实例化提供者;如果调用方为了选择实现而遍历全部提供者,才会触发对全部可用提供者的加载。- 单个
ServiceLoader实例不保证多线程安全;不同实例之间并不存在“同时load就必然冲突”的规则。
⭐️ 序列化和反序列化
关于序列化和反序列化的详细解读,请看这篇文章 Java 序列化详解,里面涉及到的知识点和面试题更全面。
什么是序列化?什么是反序列化?
如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。
简单来说:
- 序列化:将数据结构或对象转换成可以存储或传输的形式,通常是二进制字节流,也可以是 JSON, XML 等文本格式
- 反序列化:将在序列化过程中所生成的数据转换为原始数据结构或者对象的过程
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。
下面是序列化和反序列化常见应用场景:
- 对象在进行网络传输(比如远程方法调用 RPC 的时候)之前需要先被序列化,接收到序列化的对象之后需要再进行反序列化;
- 将对象存储到文件之前需要进行序列化,将对象从文件中读取出来需要进行反序列化;
- 将对象存储到数据库(如 Redis)之前需要用到序列化,将对象从缓存数据库中读取出来需要反序列化;
- 将对象转换为需要长期保存或跨组件传递的字节表示时,通常需要序列化;普通 Java 对象在 JVM 内存中使用并不需要序列化。
维基百科是如是介绍序列化的:
序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。
综上:序列化的主要目的是把对象转换为适合网络传输或持久化到文件系统、数据库、缓存等介质的表示。
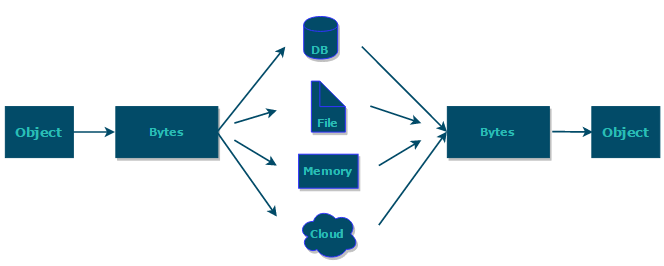
https://www.corejavaguru.com/java/serialization/interview-questions-1
序列化协议对应于 TCP/IP 4 层模型的哪一层?
我们知道网络通信的双方必须要采用和遵守相同的协议。TCP/IP 四层模型是下面这样的,序列化协议属于哪一层呢?
- 应用层
- 传输层
- 网络层
- 网络接口层

如上图所示,OSI 七层协议模型中,表示层做的事情主要就是对应用层的用户数据进行处理转换为二进制流。反过来的话,就是将二进制流转换成应用层的用户数据。这不就对应的是序列化和反序列化么?
因为,OSI 七层协议模型中的应用层、表示层和会话层对应的都是 TCP/IP 四层模型中的应用层,所以序列化协议属于 TCP/IP 协议应用层的一部分。
如果有些字段不想进行序列化怎么办?
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
transient只能修饰变量,不能修饰类和方法。transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0。static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化。
常见序列化协议有哪些?
JDK 自带的序列化方式一般不会用,因为序列化效率低并且存在安全问题。比较常用的序列化协议有 Hessian、Kryo、Protobuf、ProtoStuff,这些都是基于二进制的序列化协议。
像 JSON 和 XML 这种属于文本类序列化方式。虽然可读性比较好,但是性能较差,一般不会选择。
为什么不推荐使用 JDK 自带的序列化?
我们很少或者说几乎不会直接使用 JDK 自带的序列化方式,主要原因有下面这些原因:
- 不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了。
- 性能差:相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
- 存在安全问题:序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。相关阅读:应用安全:JAVA 反序列化漏洞之殇。
I/O
关于 I/O 的详细解读,请看下面这几篇文章,里面涉及到的知识点和面试题更全面。
Java IO 流了解吗?
IO 即 Input/Output,输入和输出。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。数据传输过程类似于水流,因此称为 IO 流。IO 流在 Java 中分为输入流和输出流,而根据数据的处理方式又分为字节流和字符流。
Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
I/O 流为什么要分为字节流和字符流呢?
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
个人认为主要有两点原因:
- 字符流是由 Java 虚拟机将字节转换得到的,这个过程还算是比较耗时;
- 如果我们不知道编码类型的话,使用字节流的过程中很容易出现乱码问题。
Java IO 中的设计模式有哪些?
参考答案:Java IO 设计模式总结
⭐️ BIO、NIO 和 AIO 的区别?
参考答案:Java IO 模型详解
语法糖
什么是语法糖?
语法糖(Syntactic sugar) 代指的是编程语言为了方便程序员开发程序而设计的一种特殊语法,这种语法对编程语言的功能并没有影响。实现相同的功能,基于语法糖写出来的代码往往更简单简洁且更易阅读。
举个例子,Java 中的 for-each 就是一个常用的语法糖,其原理其实就是基于普通的 for 循环和迭代器。
String[] strs = {"JavaGuide", "公众号:JavaGuide", "博客:https://javaguide.cn/"};
for (String s : strs) {
System.out.println(s);
}不过,JVM 其实并不能识别语法糖,Java 语法糖要想被正确执行,需要先通过编译器进行解糖,也就是在程序编译阶段将其转换成 JVM 认识的基本语法。这也侧面说明,Java 中真正支持语法糖的是 Java 编译器而不是 JVM。如果你去看 com.sun.tools.javac.main.JavaCompiler 的源码,你会发现在 compile() 中有一个步骤就是调用 desugar(),这个方法就是负责解语法糖的实现的。
Java 中有哪些常见的语法糖?
Java 中最常用的语法糖主要有泛型、自动拆装箱、变长参数、枚举、内部类、增强 for 循环、try-with-resources 语法、lambda 表达式等。
关于这些语法糖的详细解读,请看这篇文章 Java 语法糖详解。
写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。