大模型实战项目 + Agent实战项目:Spring AI 面试平台与 RAG 知识库
很多后端同学准备简历项目时都会遇到同一个问题:项目里全是增删改查(CRUD),技术栈看起来不少,但面试官很难继续深挖,也很难体现你对 大模型应用开发、RAG 知识库、Agent 工程落地 这些新方向的理解。
这篇要介绍的就是一个面向 Java 后端的 大模型实战项目 + Agent 实战项目:基于 Spring Boot 4.0、Java 21、Spring AI 2.0 构建 AI 智能面试辅助平台,把简历分析、AI 模拟面试、RAG 知识库问答、语音面试、异步任务处理、分布式限流等能力串成一个完整项目。
如果你想找一个能写进简历、能用于面试讲解、也能系统学习 Spring AI 和 RAG/Agent 实战的项目,这个项目会比单纯堆业务表的 CRUD 项目更适合你。
项目介绍
这是一个基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 的 AI 智能面试辅助平台。系统提供三大核心功能:
- 智能简历分析:上传简历后,AI 自动进行多维度评分并给出改进建议
- 模拟面试系统:基于简历内容生成个性化面试题,支持实时问答和答案评估
- RAG 知识库问答:上传技术文档构建私有知识库,支持向量检索增强的智能问答
项目地址 (欢迎 star 鼓励):
- Github:https://github.com/Snailclimb/interview-guide
- Gitee:https://gitee.com/SnailClimb/interview-guide
完整代码完全免费开源,没有 Pro 版本或者付费版!
简历写法
如何将《SpringAI 智能面试平台+RAG知识库》实战项目写进简历?我一共提供了五大方向版本任选,精准匹配岗位需求:
- 后端方向:提供“架构与分布式能力侧重”、“AI 应用与响应式编程侧重”、“工程化与基础设施侧重”三个版本,无论你面试的是后端、大模型应用还是架构岗位,都能找到最合适的切入点。
- 测试/测开方向:专门设计了“单元测试与 TDD”以及“功能/异常场景覆盖”两个版本,突出测试工程师在 AI 质量保障中的核心竞争力。

每一条描述都紧扣项目真实逻辑,严格遵守项目介绍规范。不仅教你怎么写,更教你怎么补,例如针对本项目未涉及的“用户认证与鉴权”给出补充建议,教你如何基于 SpringSecurity/Sa-Token 包装主流的认证授权方案。
并且,我还补充了面试官可深挖的技术难点(如 Redis Stream vs 传统消息队列、分布式限流的实现细节)以及项目难点与解决方案模板。
教程概览
带大家看看我写的配套教程,用心程度一切都在文字中!整个项目教程,我手绘了几十张技术配图帮助理解。
例如,RAG 面试题总结这篇,耗时一周终于完成了第一版,一共 3.4 万字,包含 35 道高频 RAG 面试题,光校对都进行了三次。而且,这还只是第一版,后续还会继续完善优化!
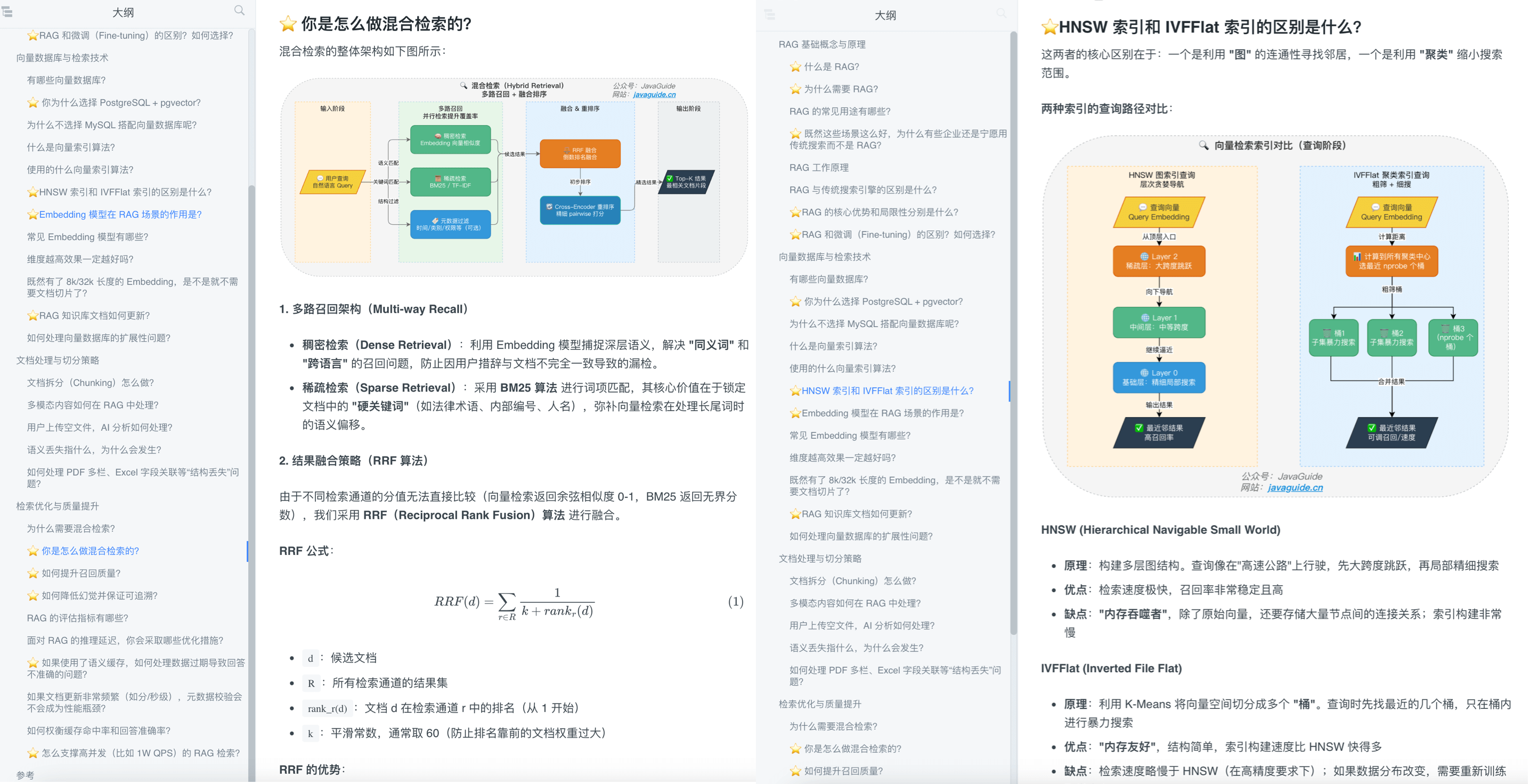
这篇是对应的 RAG 知识库详细开发思路的介绍。
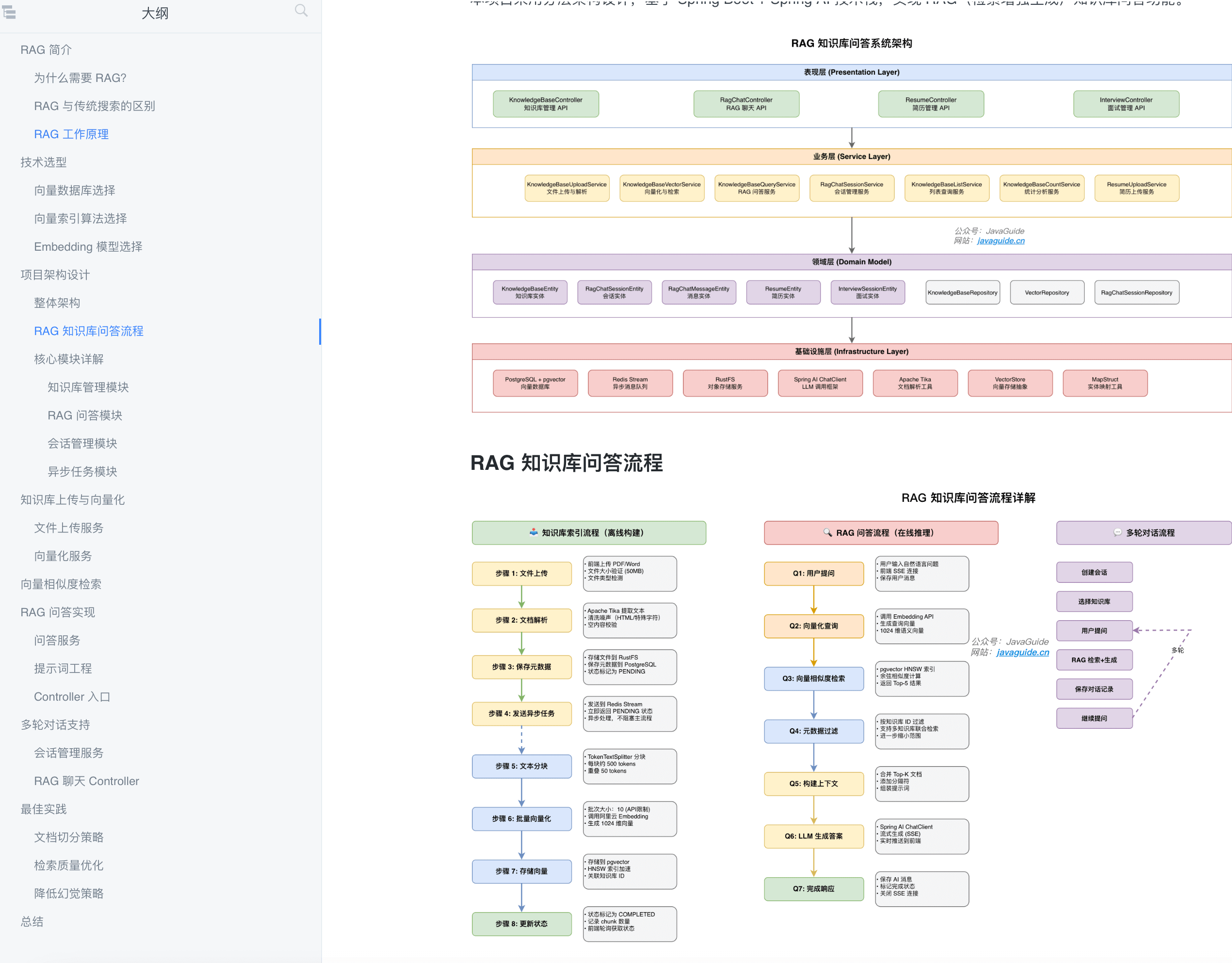
不仅教你“如何写出代码”,更教你“为什么这么设计”以及“在企业真实场景中如何应对复杂挑战”。
配套教程内容安排
这个项目当前实现的功能比较简单,学习门槛极低,但涉及到的知识点比较丰富。通过保姆级教程,我们将从零构建一个融合了 LLM 集成、RAG(检索增强生成)、向量数据库、分布式限流及异步处理的完整后端架构。
无论你是想学习 Spring AI 的前沿应用,还是需要一个高含金量的简历项目,本项目都将为你提供从基建搭建、业务攻坚到面试话术复盘的全方位指导。
配套项目教程需要付费(后文/文末有加入方法),但请大家理解,主要是想覆盖一些时间成本。而且,收费和提供的服务相比绝对是超级良心了。这辈子不可能干割韭菜的事!
内容安排如下(已经更完,一共 13w+ 字):

环境搭建
- 本地搭建 PostgreSQL + PGvector 向量数据库
- Spring Boot + RustFS 构建高性能 S3 兼容的对象存储服务
- ⭐大模型 API 申请和 Ollama 部署本地模型
- 环境搭建终章与项目启动
核心功能开发
- 基于 Tika 实现多格式内容提取与解析
- ⭐Spring AI 与大模型集成
- ⭐Spring AI + pgvector 实现 RAG 知识库问答
- 基于 SSE 实现打字机效果输出
- 手把手教你写出生产级结构化 Prompt
- AI 模拟面试功能
- 基于 iText 8 实现 PDF 报告导出
进阶优化
- MapStruct 实体映射最佳实践
- ⭐基于 Redis Stream 的异步任务处理实现
- 封装 Redis + Lua 多维度分布式限流组件
- ⭐Skill 架构设计
- Spring Boot 4.0 升级指南
- Docker Compose 一键部署
面试
- ⭐简历编写与项目经历深度包装指南
- 面试官问“这个项目哪里来的”时,如何回答?
- ⭐Spring AI 面试问题挖掘
- ⭐知识库 RAG 面试问题挖掘
- Redis 面试问题挖掘
- 文件上传解析与 PDF 导出面试问题挖掘
加入学习
本项目为 JavaGuide 知识星球 内部专属实战项目,通过语雀文档在线阅读学习,不单独对外开放。
之所以选择在星球内部发布,是为了确保每一位学习者都能获得深度的技术答疑和完整的求职配套服务。
整个项目教程预计在 1-2 个月内更完。每一篇文章(不提供视频,浪费时间且不利于学习能力提高)都经过反复推敲,确保高质量、零门槛,即便是基础薄弱的同学也能跟着文档从零跑通。
这只是开始。后续星球还会持续推出更多贴合企业真实业务场景的 Java 实战项目,带你始终站在技术前沿(预告一下,下一个项目是企业级智能客服系统,会带大家实践更多AI能力)。
并且,我的星球还有很多其他服务,比如一对一提问、简历修改、后端系统面试资料(包含高频系统设计&场景题)、学习打卡等,其中任何一项服务单独拎出来的价值都已远超星球门票。欢迎详细了解我的知识星球!
已经坚持维护六年,内容持续更新,虽白菜价(0.4 元/天)但质量很高,主打一个良心!
目前星球正在做活动,两本书的价格,就能让你拥有上万培训班的服务!这里再提供一张 30 元 的优惠券(价格马上上调,老用户扫码续费半价):

用心做内容,坚持本心,不割韭菜,其他交给时间!共勉!
系统架构
提示:架构图采用 draw.io 绘制,导出为 svg 格式,在 Dark 模式下的显示效果会有问题。
系统采用前后端分离架构,整体分为三层:前端展示层、后端服务层、数据存储层。
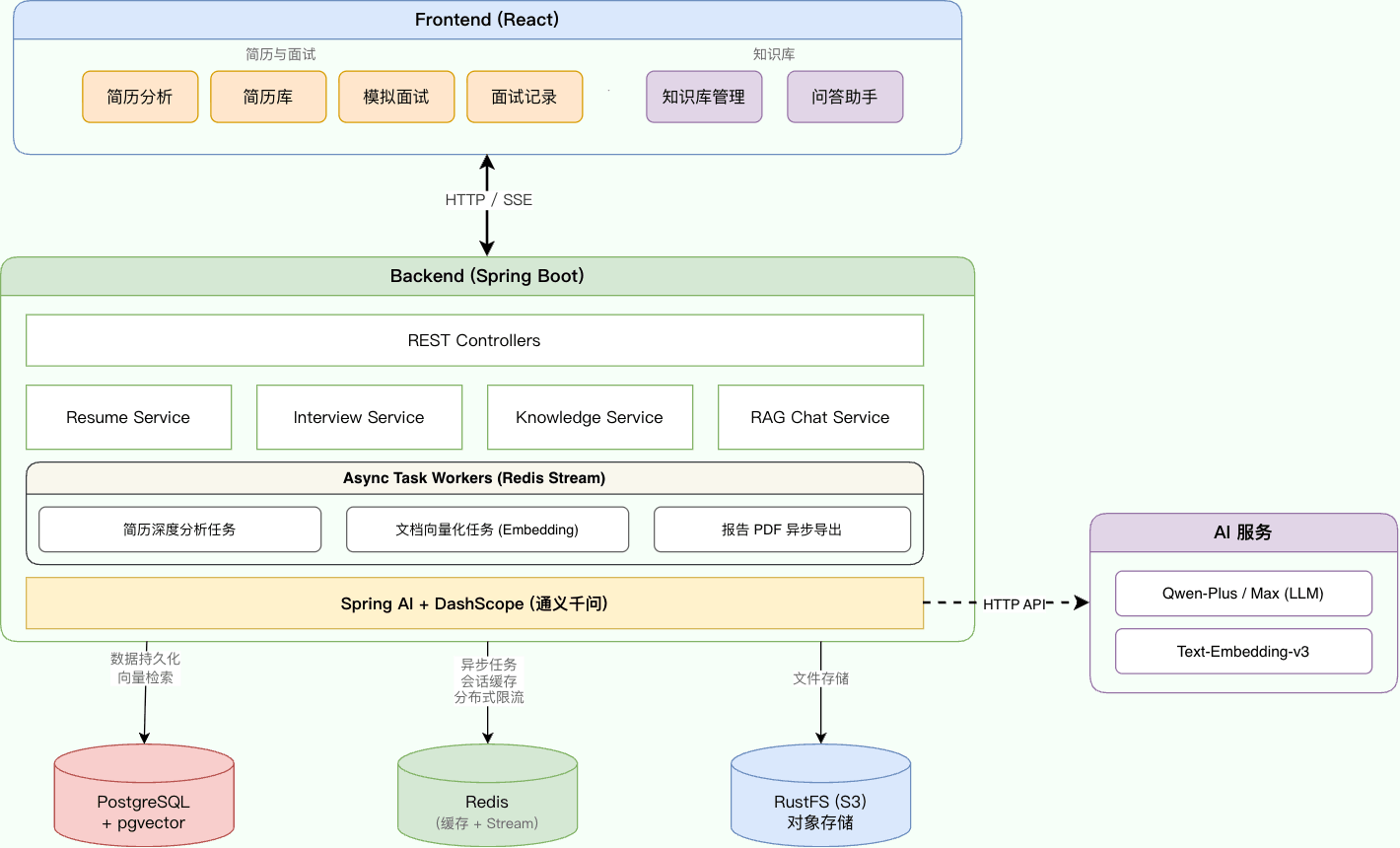
后端层:
- REST Controllers:统一的 API 入口,处理 HTTP 请求
- 业务服务层:
- Resume Service:简历上传、解析、AI 分析
- Interview Service:面试会话管理、问题生成、答案评估
- Knowledge Service:知识库上传、文本分块、向量化
- RAG Chat Service:检索增强生成,流式问答
- Resume Service:简历上传、解析、AI 分析
- 异步处理层:基于 Redis Stream 的消费者,异步处理耗时的 AI 任务(如简历分析、向量化、面试评估)
- AI 集成层:Spring AI + DashScope(通义千问)。统一的 LLM 调用接口,支持对话生成和文本向量化。
数据存储层:
PostgreSQL + pgvector:
- 关系数据:简历、面试记录、知识库元数据
- 向量检索:存储文档向量,支持相似度搜索
Redis:
- 会话缓存:面试会话状态
- 消息队列:Redis Stream 实现异步任务队列
RustFS/MinIO (S3):原始文件(简历 PDF、知识库文档)
异步处理流程:
简历分析、知识库向量化和面试报告生成采用 Redis Stream 异步处理,这里以简历分析和知识库向量化为例介绍一下整体流程:
上传请求 → 保存文件 → 发送消息到 Stream → 立即返回
↓
Consumer 消费消息
↓
执行分析/向量化任务
↓
更新数据库状态
↓
前端轮询获取最新状态状态流转: PENDING → PROCESSING → COMPLETED / FAILED
知识库问答处理流程:
知识库问答 → 问题向量化 → pgvector 相似度搜索 → 检索相关文档
↓
构建 Prompt → LLM 生成回答 → SSE 流式返回技术栈
后端技术
| 技术 | 版本 | 说明 |
|---|---|---|
| Spring Boot | 4.0.1 | 应用框架 |
| Java | 21 | 开发语言(虚拟线程) |
| Spring AI | 2.0.0-M4 | AI 集成框架 |
| PostgreSQL + pgvector | 14+ | 关系数据库 + 向量存储 |
| Redis + Redisson | 6+ / 4.0.0 | 缓存 + 消息队列(Stream) |
| Apache Tika | 2.9.2 | 文档解析 |
| iText 8 | 8.0.5 | PDF 导出 |
| MapStruct | 1.6.3 | 对象映射 |
| SpringDoc OpenAPI | 3.0.2 | API 接口文档 |
| DashScope SDK | 2.22.7 | 语音识别/合成(Qwen3 ASR/TTS) |
| spring-ai-agent-utils | 0.7.0 | Spring AI Agent Skills 工具库 |
| WebSocket | - | 语音面试实时双向通信 |
| Gradle | 8.14 | 构建工具 |
技术选型常见问题解答:
- 数据存储为什么选择 PostgreSQL + pgvector?PG 的向量数据存储功能够用了,精简架构,不想引入太多组件。
- 为什么引入 Redis?
- Redis 替代
ConcurrentHashMap实现面试会话的缓存。 - 基于 Redis Stream 实现简历分析、知识库向量化等场景的异步(还能解耦,分析和向量化可以使用其他编程语言来做)。不使用 Kafka 这类成熟的消息队列,也是不想引入太多组件。
- Redis 替代
- 构建工具为什么选择 Gradle?个人更喜欢用 Gradle,也写过相关的文章:Gradle核心概念总结。
前端技术
| 技术 | 版本 | 说明 |
|---|---|---|
| React | 18.3 | UI 框架 |
| TypeScript | 5.6 | 开发语言 |
| Vite | 5.4 | 构建工具 |
| Tailwind CSS | 4.1 | 样式框架 |
| React Router | 7.11 | 路由管理 |
| Framer Motion | 12.23 | 动画库 |
| Recharts | 3.6 | 图表库 |
| Lucide React | 0.468 | 图标库 |
| React Big Calendar | 1.19 | 面试日历组件 |
| React Markdown | 9.0 | Markdown 渲染 |
| React Virtuoso | 4.18 | 虚拟滚动列表 |
技术选型常见问题解答
这里只是简单介绍,后续我会分享文章详细拷打技术选型。
为什么选择 Spring AI?
Spring AI 是 Spring 官方推出的 AI 集成框架,提供了统一的 LLM 调用抽象。选择它的原因:
- 统一抽象:一套代码支持多种 LLM 提供商(OpenAI、阿里云 DashScope、Ollama 等),切换模型只需修改配置
- Spring 生态集成:与 Spring Boot 无缝集成,支持自动配置、依赖注入、声明式调用
- 内置向量存储支持:原生支持 pgvector、Milvus、Pinecone 等向量数据库,简化 RAG 开发
- 结构化输出:通过
BeanOutputConverter将 LLM 输出直接映射为 Java 对象,无需手动解析 JSON
// 示例:Spring AI 结构化输出
var converter = new BeanOutputConverter<>(ResumeAnalysisDTO.class);
String result = chatClient.prompt()
.system(systemPrompt)
.user(userPrompt + converter.getFormat())
.call()
.content();
return converter.convert(result); // 直接得到 Java 对象数据存储为什么选择 PostgreSQL + pgvector?
本项目需要同时存储结构化数据(简历、面试记录)和向量数据(文档 Embedding)。方案对比:
| 方案 | 优点 | 缺点 |
|---|---|---|
| PostgreSQL + pgvector | 一套数据库搞定,运维简单 | 向量检索性能不如专业向量库 |
| PostgreSQL + Milvus | 向量检索性能更好 | 多一个组件,运维复杂度增加 |
| PostgreSQL + Pinecone | 云托管,无需运维 | 成本高,数据在第三方 |
选择 pgvector 的理由:
- 架构简单:不引入额外组件,降低部署和运维复杂度
- 性能够用:HNSW 索引支持毫秒级检索,万级文档场景完全够用
- 事务一致性:向量数据和业务数据在同一数据库,天然支持事务
- SQL 查询:可以结合 WHERE 条件过滤,比如“只在某个分类的知识库中检索”
-- pgvector 相似度搜索示例
SELECT content, 1 - (embedding <=> \$1) as similarity
FROM vector_store
WHERE metadata->>'category' = 'Java'
ORDER BY embedding <=> \$1
LIMIT 5;为什么不选择 MySQL 搭配向量数据库呢?
PostgreSQL 最大的优势,也是它在 AI 时代甩开对手的“王牌”,就是其强大的可扩展性。开发者可以在不修改内核的情况下,像“即插即用”一样为数据库安装各种功能强大的插件,这让 PostgreSQL 变成了一个无所不能的“数据瑞士军刀”。
- AI 向量检索? 有官方推荐的 pgvector 扩展,性能强大,生态成熟,足以媲美专业的向量数据库。
- 全文搜索? 内置支持(能满足基础需求),或使用 pg_bm25 等扩展。
- 时序数据? 有顶级的 TimescaleDB 扩展。
- 地理信息? 有行业标准的 PostGIS 扩展。
这种“一站式”解决能力,正是其魅力所在。它意味着许多项目不再需要依赖 Elasticsearch、Milvus 等大量外部中间件,仅凭一个增强版的 PostgreSQL 即可满足多样化需求,从而极大地简化了技术栈,降低了开发和运维的复杂度与成本。
关于 MySQL 和 PostgreSQL 的详细对比,可以参考我写的这篇文章:MySQL vs PostgreSQL,如何选择?。
为什么引入 Redis?
本项目主要有两个场景用到了 Redis:
- Redis 替代
ConcurrentHashMap实现会话的缓存。 - 基于 Redis Stream 实现简历分析、知识库向量化等场景的异步(还能解耦,分析和向量化可以使用其他编程语言来做)。
为什么引入 Redis Stream?为何不选择 Kafka、RabbitMQ 等更成熟的消息队列?
简历分析、知识库向量化等 AI 任务耗时较长(10-60 秒),不适合同步处理。需要消息队列实现异步解耦。
| 维度 | Redis Stream | RabbitMQ | Kafka | 内存队列 |
|---|---|---|---|---|
| 吞吐量 | 高(十万级 QPS) | 中(万级 QPS) | 极高(百万级,水平扩展) | 极高(千万级/秒,受限于 CPU/内存) |
| 延迟 | 极低(亚毫秒级) | 低(毫秒级) | 中(毫秒到十毫秒级) | 极低(纳秒/微秒级) |
| 持久化 | 支持(RDB/AOF) | 支持(Mnesia/磁盘) | 强支持(原生分段日志) | 无(进程终止即失) |
| 消息堆积能力 | 一般(受限于内存) | 中(磁盘堆积,性能下降明显) | 极强(TB 级磁盘存储) | 差(受限于堆内存) |
| 消费模式 | 发布订阅 / 消费者组 | 灵活路由 / 多种交换机模式 | 发布订阅 / 消费者组 | 点对点 / 多消费者(取决于实现) |
| 消息回溯 | 支持(按 ID / 时间范围) | 不支持 | 强支持(按 Offset / 时间戳) | 不支持 |
| 消息顺序性 | 单 Stream 有序 | 单队列有序 | 单 Partition 有序 | 有序(单队列) |
| 可靠性 | 中(异步复制可能丢失) | 高(Publisher Confirm / 事务) | 极高(多副本 ISR + acks) | 低(无持久化、无确认) |
| 运维复杂度 | 低 | 中 | 高(KRaft 模式已简化) | 极低 |
| 适用场景 | 轻量级流处理、已有 Redis 基础设施 | 复杂路由、企业级集成 | 大数据流、事件溯源、日志聚合 | 进程内解耦、极致性能场景 |
选择 Redis Stream 的理由:
- 复用现有组件:Redis 已用于会话缓存,无需引入新中间件。
- 功能满足需求:支持消费者组、消息确认(ACK)、持久化。
- 运维简单:对于中小型项目,Redis Stream 完全够用。
构建工具为什么选择 Gradle?
Spring Boot 官方现在用的就是 Gradle,加上国内现在都是 Maven 更多,换个 Gradle 还更新颖一些。
个人也更喜欢用 Gradle,也写过相关的文章:Gradle 核心概念总结。
为什么使用 MapStruct?
项目中有大量 Entity ↔ DTO 转换需求,MapStruct 是编译时代码生成的对象映射框架:
| 方案 | 性能 | 类型安全 | 使用复杂度 |
|---|---|---|---|
| MapStruct | 零反射,最快 | 编译时检查 | 定义接口即可 |
| BeanUtils | 反射,慢 | 运行时报错 | 一行代码 |
| ModelMapper | 反射,较慢 | 运行时报错 | 配置复杂 |
| 手写转换 | 最快 | 编译时检查 | 重复代码多 |
为什么使用 Apache Tika?
系统需要解析多种格式的文档(PDF、Word、TXT),Apache Tika 是 Apache 基金会的文档解析库:
- 格式支持全:PDF、DOCX、DOC、TXT、HTML、Markdown 等上百种格式
- 自动识别:根据文件内容自动检测格式,无需依赖文件扩展名
- 文本提取:统一的 API 提取纯文本,屏蔽格式差异
// Tika 解析示例
Tika tika = new Tika();
String content = tika.parseToString(inputStream); // 自动识别格式并提取文本为什么使用 SSE 而不是 WebSocket?
知识库问答需要流式输出(像 ChatGPT 那样逐字显示),有两种技术选择:
| 方案 | 优点 | 缺点 |
|---|---|---|
| SSE | 简单,基于 HTTP,单向推送 | 仅支持服务端 → 客户端 |
| WebSocket | 双向通信,功能强大 | 协议复杂,需要维护连接状态 |
选择 SSE 的理由:
- 场景匹配:LLM 流式输出是单向的(服务端 → 客户端),不需要双向通信
- 实现简单:基于 HTTP,天然支持重连、跨域
- Spring 支持好:
Flux<ServerSentEvent<String>>一行代码搞定
前端为什么选择 React + TypeScript + Tailwind CSS?
| 技术 | 选择理由 |
|---|---|
| React | 生态最成熟,组件化开发,社区资源丰富 |
| TypeScript | 类型安全,IDE 智能提示,减少运行时错误 |
| Vite | 开发服务器启动快(秒级),HMR 热更新体验好 |
| Tailwind CSS | 原子化 CSS,快速开发,无需写 CSS 文件 |
功能特性
简历管理模块
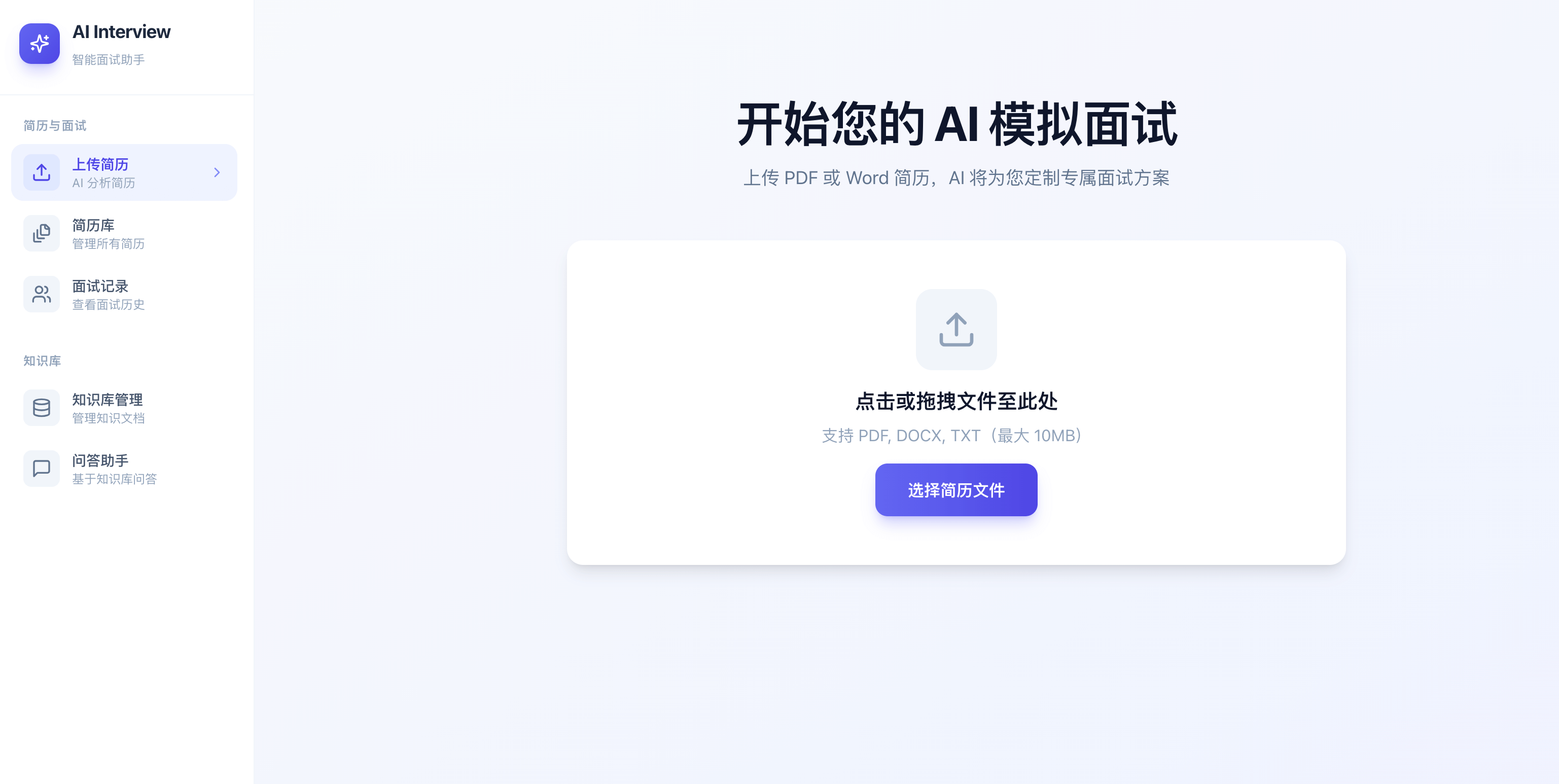
- 多格式解析:支持 PDF、DOCX、DOC、TXT 等多种简历格式。
- 异步处理流:基于 Redis Stream 实现异步简历分析,支持实时查看处理进度(待分析/分析中/已完成/失败)。
- 稳定性保障:内置分析失败自动重试机制(最多 3 次)与基于内容哈希的重复检测。
- 分析报告导出:支持将 AI 分析结果一键导出为结构化的 PDF 简历分析报告。
模拟面试模块
- Skill 驱动出题:内置 10+ 面试方向(Java 后端、阿里/字节/腾讯专项、前端、Python、算法、系统设计、测开、AI Agent 等),每个方向由
SKILL.md定义考察范围、难度分布和参考知识库。基于spring-ai-agent-utils的 Progressive Disclosure 机制实现按需加载。 - 并行双路出题:有简历时,60% 简历项目深挖题(独立 Prompt)+ 40% 方向基础题(Skill 驱动),使用 Java 21 虚拟线程并行生成后合并,物理隔离避免 Prompt 冲突。
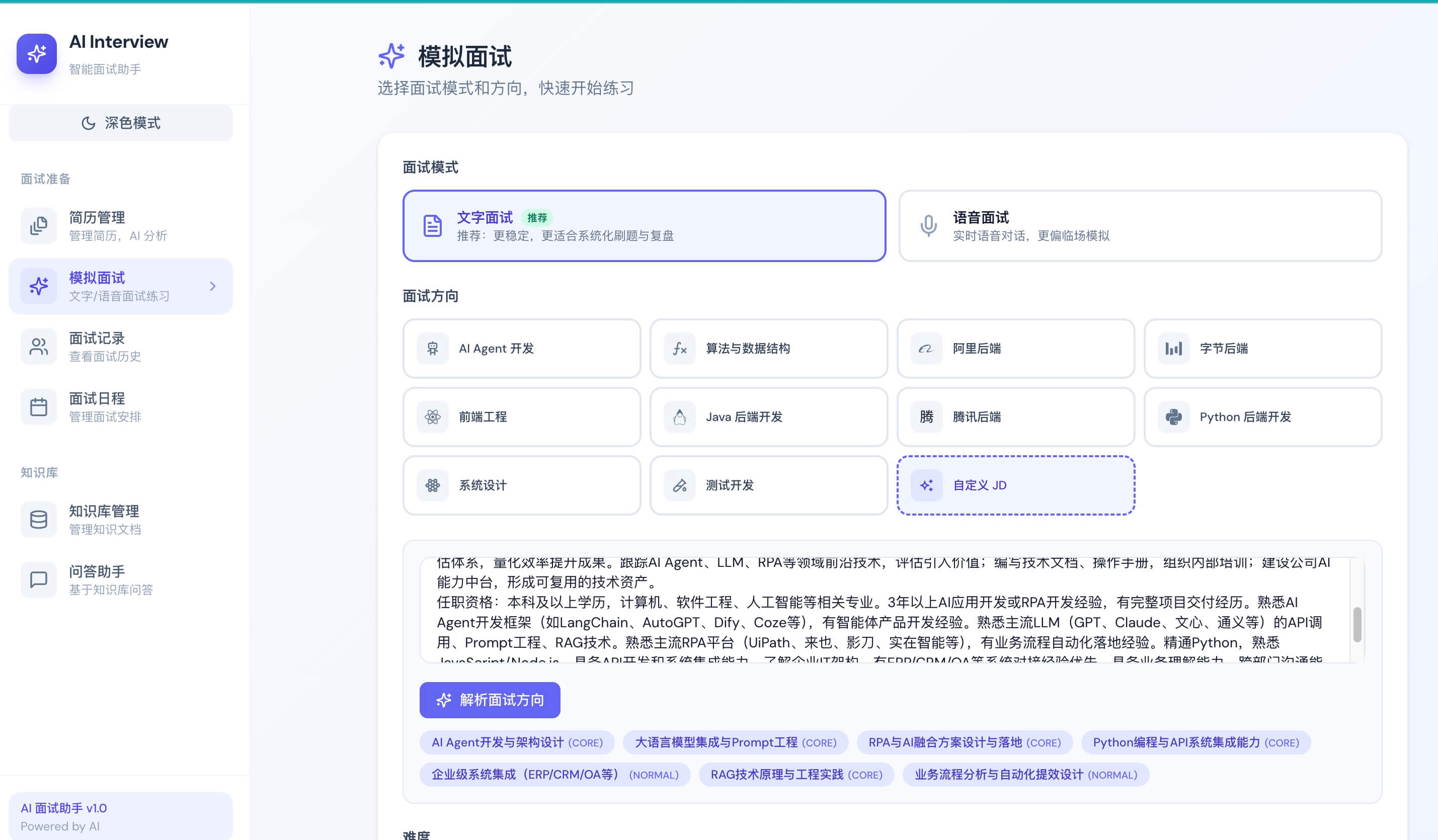
- 自定义 JD 解析:粘贴职位描述(JD),LLM 动态提取面试分类并匹配共享题库,无需预设方向即可开始面试。
- 简历推荐方向:上传简历后,LLM 通过 Semantic Matching 自动推荐最匹配的面试方向,降低用户选择成本。
- 历史题目去重:出题时自动排除已有会话中问过的题目,避免重复考察。
- 面试阶段时长联动:总时长滑块拖动后,各阶段(自我介绍、技术考察、项目深挖、反问环节)按时比自动分配。
- 智能追问流:支持配置多轮智能追问(默认 1 条),模拟多轮问答场景。
- 统一评估架构:文字面试和语音面试共用同一套评估引擎(分批评估 + 结构化输出 + 二次汇总 + 降级兜底),评估结果可对比。
- 报告一键导出:支持异步生成并导出详细的 PDF 模拟面试评估报告。
- 面试中心入口:面试中心页整合文字面试和语音面试入口,支持继续面试和重新面试。
面试安排模块
- 邀请解析:规则 + AI 双引擎,支持飞书/腾讯会议/Zoom 格式,自动提取公司、岗位、时间、会议链接
- 日历管理:日/周/月视图 + 拖拽调整 + 列表视图
- 状态流转:定时任务自动过期,手动标记待面试/已完成/已取消
- 面试提醒:可配置提醒,避免错过面试
语音面试模块
实时语音对话面试,WebSocket + 千问3 语音模型(ASR/TTS/LLM 统一 API Key):
- 实时流式对话:句子级并发 TTS,边生成边合成边播放,首包延迟 200ms
- 服务端 VAD:自动断句,实时字幕(含中间结果)
- 回声防护 + 手动提交:避免 AI 语音被误录入
- 多轮上下文记忆 + 暂停/恢复:超时自动暂停
- Micrometer 埋点:TTS/ASR 延迟、会话时长等指标
已知问题:端到端延迟偏高(服务端音频中转)、无耳机时回声泄漏、TTS 音色单一、弱网音频断续。后续计划探索 WebRTC、客户端 VAD 降噪、端到端语音模型等方案。
知识库管理模块
- 文档智能处理:支持 PDF、DOCX、Markdown 等多种格式文档的自动上传、分块与异步向量化。
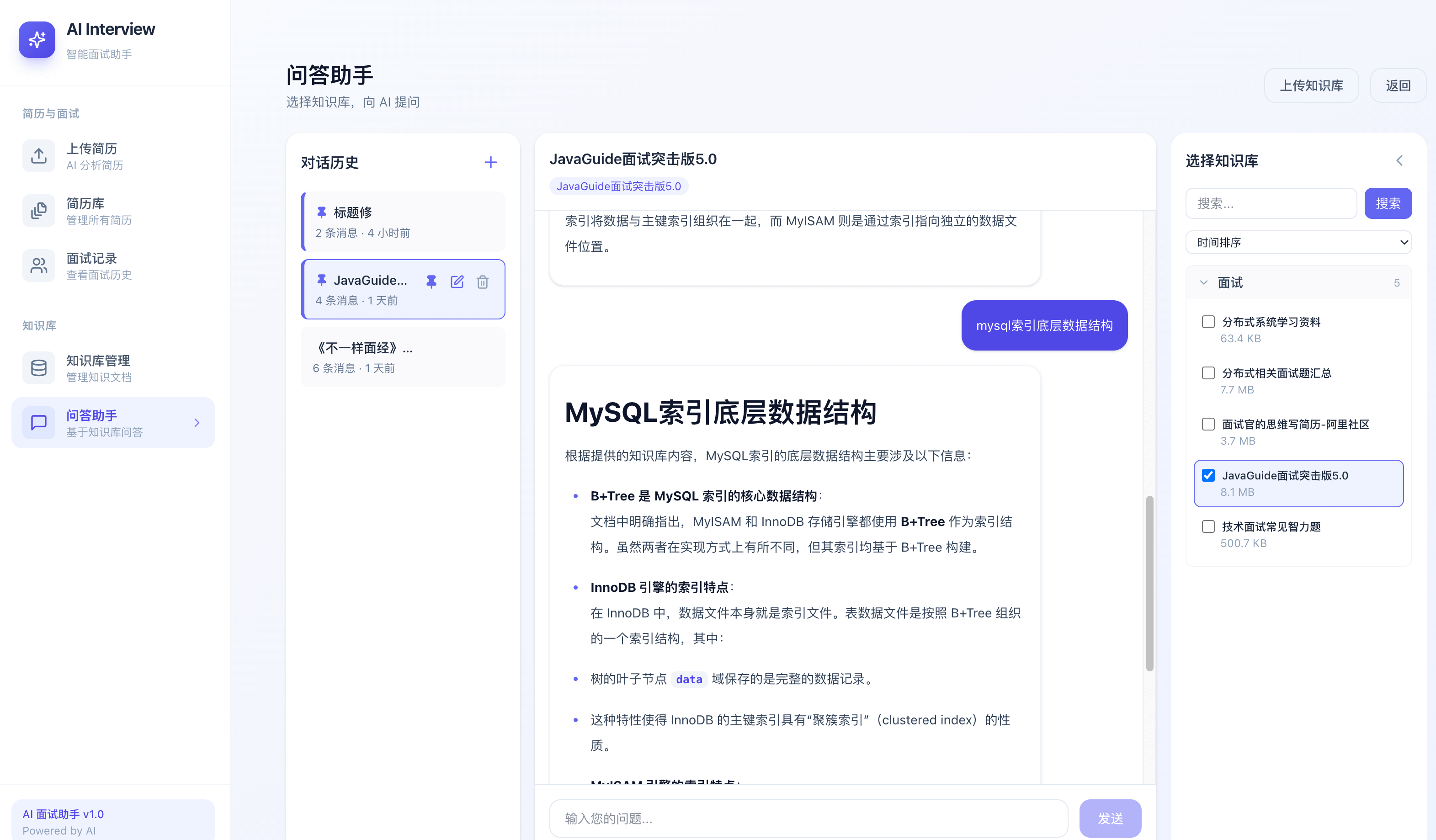
- RAG 检索增强:集成向量数据库,通过检索增强生成(RAG)提升 AI 问答的准确性与专业度。
- 流式响应交互:基于 SSE(Server-Sent Events)技术实现打字机式流式响应。
- 智能问答对话:支持基于知识库内容的智能问答,并提供直观的知识库统计信息。
效果展示
简历与面试
面试中心:
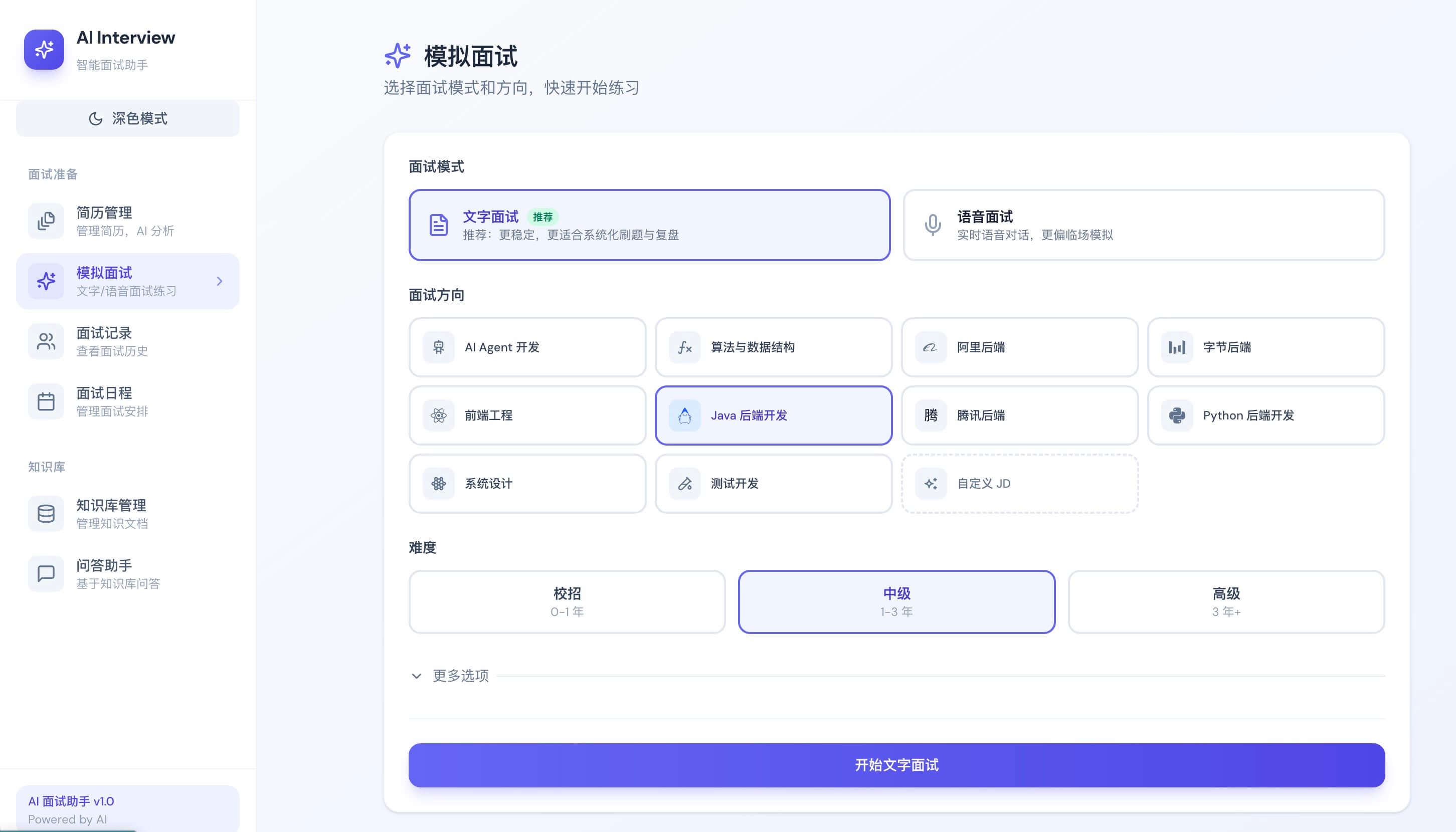
Skill 出题 + JD 解析:
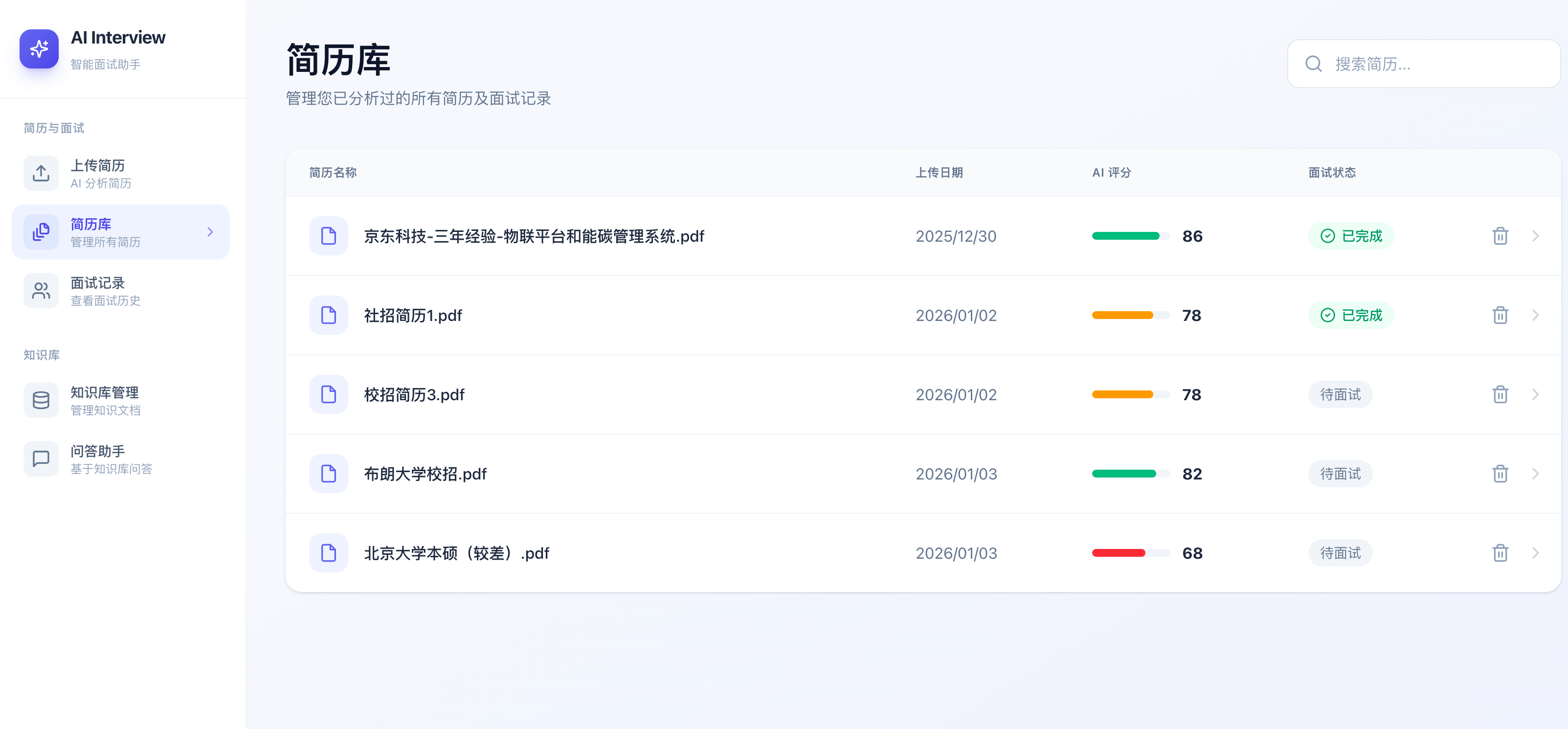
简历库:
简历上传分析:
简历分析详情:

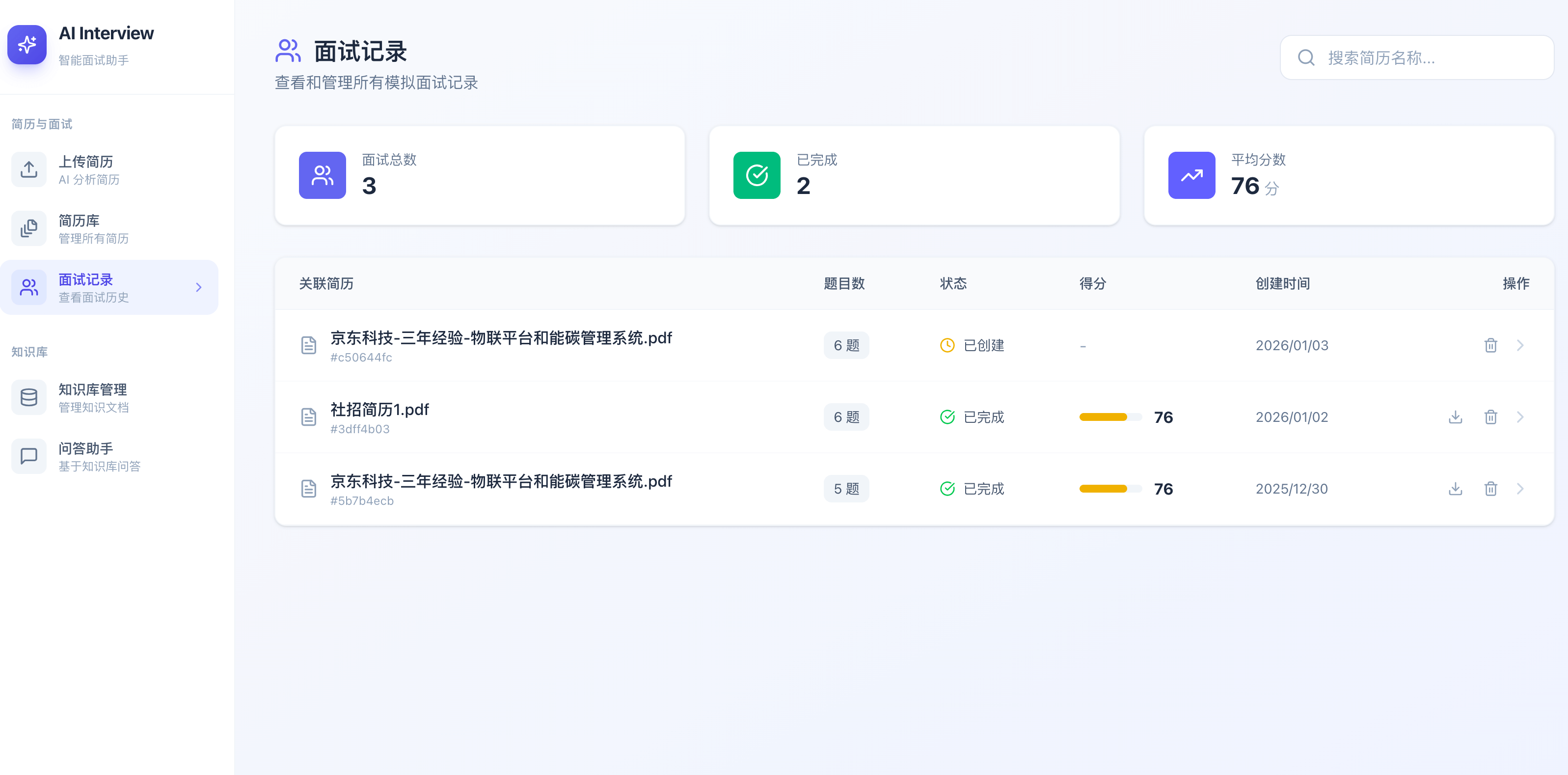
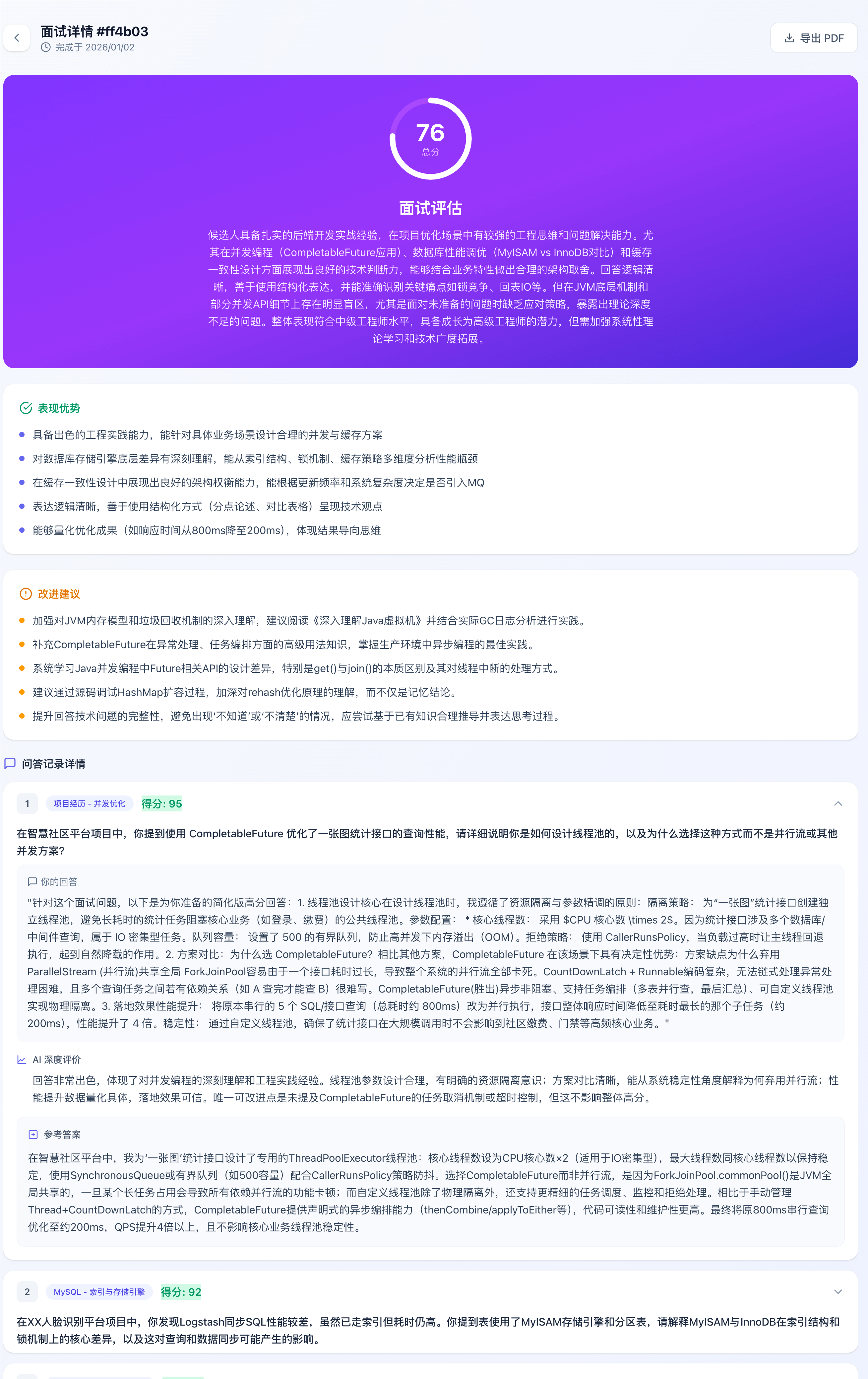
面试记录:
面试详情:
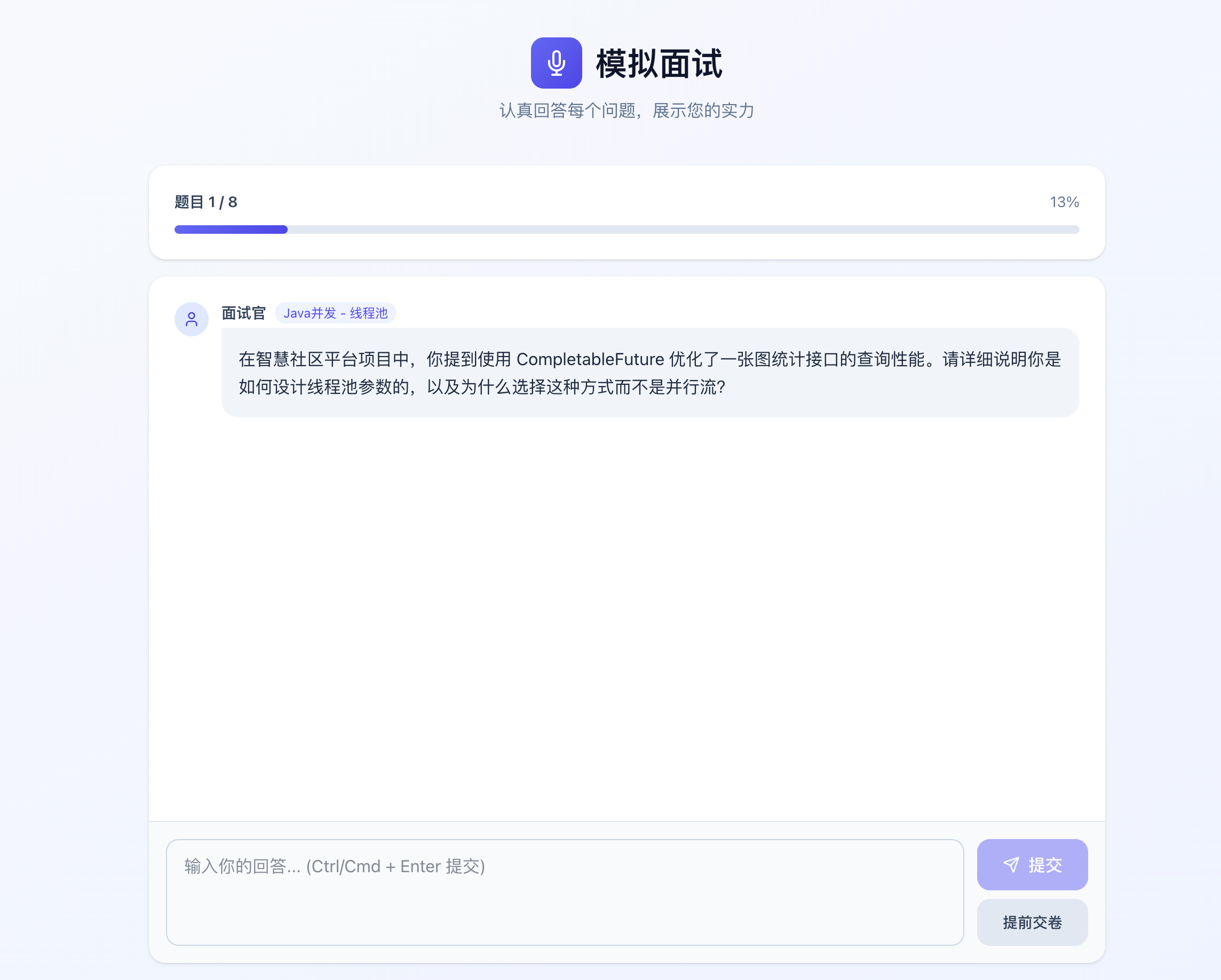
模拟面试:
面试安排

知识库
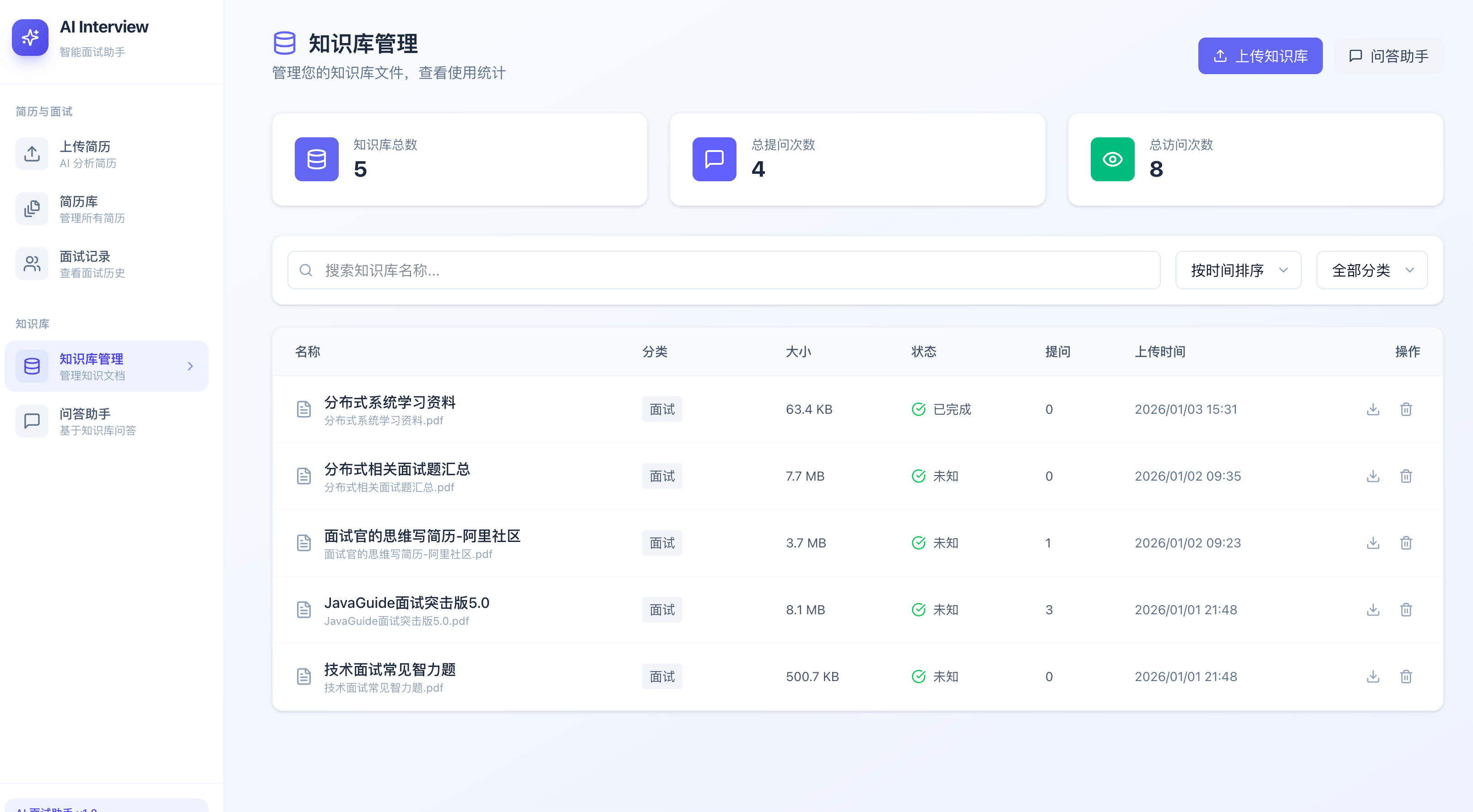
知识库管理:
问答助手:
学习本项目你将获得什么?
本项目采用行业最前沿的 Java 21 + Spring Boot 4.0 技术栈,是市面上首个深度集成 Spring AI 2.0 的全栈实战项目。我们不仅提供高质量的代码,更配套了详尽的架构解析教程。
项目整体设计遵循“由浅入深”原则。即使你的编程基础尚浅,只需跟随我们的保姆级教程,也能顺利从零搭建出一套生产级别的 AI 大模型应用。
深度掌握 AI 应用开发的核心范式
本项目是你从传统后端转型 AI 应用开发工程师的最佳敲门砖:
Spring AI 2.0 工业级实战:深入理解 Spring 官方的 AI 抽象层,掌握如何通过统一的声明式接口对接通义千问、OpenAI 等主流模型。
Prompt Engineering(提示词工程)深度应用:告别简单的字符串拼接。学习如何构建结构化的 System/User Prompt,并利用 BeanOutputConverter 实现 LLM 输出向 Java 对象的自动化映射,彻底终结繁琐的 JSON 手动解析。
Query Rewrite(查询重写)技术:学习如何利用 LLM 对用户原始查询进行智能改写,补充语义、优化检索词,显著提升 RAG 系统的召回率。掌握“原问题→改写问题→回退原问题”的级联检索策略。
动态检索参数调优:深入理解如何根据查询长度、语义密度等特征,动态调整 topK 与相似度阈值,实现短查询、中长查询、长查询的差异化检索策略。
RAG(检索增强生成)全链路闭环:深度拆解“文档解析 → 文本分块 → 向量化 (Embedding) → 向量数据库存储 → 相似度检索 → 上下文增强生成”的完整技术链条。学习“有效命中判定”机制,避免弱相关片段触发生效模型的长篇“信息不足”回复。
结构化输出可靠性与重试策略:掌握
StructuredOutputInvoker统一封装模式,学习如何通过自动重试、错误注入、严格 JSON 指令等方式,大幅提升 LLM 结构化输出的解析成功率。
现代化的 Java 后端架构思维
你可以学习到优秀的工程实践:
拥抱 Java 21 与 Spring Boot 4.0:抢先布局虚拟线程 (Virtual Threads)、Record 类等高性能特性。针对 Spring Boot 4.0 的模块化设计进行深度适配,让你的技术栈领先市场。
模块化单体架构:学习如何通过清晰的层级(Modules + Infrastructure + Common)组织代码。这种设计既具备微服务的解耦优势,又极大降低了单体应用的运维心智负担。
极致的对象转换性能:通过 MapStruct 在编译期生成映射代码。学习如何在追求极致响应速度的场景下,优雅、安全地处理 Entity 与 DTO 之间的复杂映射。
务实的数据存储与中间件选型
我们拒绝盲目堆砌中间件,而是教你如何基于业务场景做出“最理智”的选择:
PostgreSQL + pgvector 的“一站式”存储方案:掌握如何在同一套数据库中高效处理关系型业务数据与高维向量数据。深入学习 HNSW 索引在万级文档场景下的性能调优实践。
Redis + Lua 分布式限流体系:实战封装高性能分布式限流组件。基于 Lua 脚本保证限流逻辑的原子性,支持按用户、IP 或全局维度的精准流量控制,有效防御恶意刷接口行为,保障高价值 AI API 的配额安全。
Redis Stream 异步任务处理:深入探讨在简历分析等耗时场景(10-60s)下,为什么选择轻量级的 Redis Stream 而非 Kafka。实战演示如何通过消息队列实现系统解耦与流量削峰。
企业级文件处理与清洗优化:不仅利用 Apache Tika 构建通用的文档解析引擎,还配套实现了 TextCleaningService。通过正则清洗、空行标准化及文本去噪(如剔除图片链接、非法控制字符),显著提升 RAG 的召回质量;同时集成内容哈希检测,从源头拦截重复上传,节省存储与 Token 成本。
高级 AI 功能设计模式
Skill 架构与 Agent Skills:学习如何将面试方向配置从代码中解耦,基于
SKILL.md+skill.meta.yml的双层配置设计。掌握spring-ai-agent-utils的 Discovery → Semantic Matching → Execution 三层 Progressive Disclosure 机制,以及文字面试(单次调用预加载)与语音面试(多轮 ReAct 按需加载)的差异化资源加载策略。并行双路出题架构:深入理解”单次调用无法兼顾简历和方向”的 Prompt 冲突问题,学习如何通过物理隔离(两套独立 Prompt 模板 + 两路并行 AI 调用)实现 60% 简历题 + 40% 方向题的混合出题,以及索引合并和降级策略的设计。
多轮追问生成机制:学习如何在面试问题生成场景中,通过多层 Prompt 设计实现”主问题 + 追问”的树形结构。掌握可配置追问数量、问题类型权重分配、历史去重等实战技巧。
流式输出智能处理:掌握 SSE 流式场景下的”探测窗口”技术——在保持首字响应速度的同时,快速识别”无信息”输出并统一为固定模板,避免用户看到长篇拒答文字。
统一无结果策略:学习如何在 RAG 系统中设计一致的用户无结果体验,包括命中判定、输出归一化、流式截断等全链路优化。
标准化的工程化交付与部署
Gradle 现代构建体系:摆脱 Maven 的繁琐配置,掌握 Gradle 8.14 及其版本目录 (Version Catalog) 的灵活性,学习如何优雅地管理大型项目依赖。
生产级容器化部署:通过 Docker Compose 一键搭建包含数据库扩展、缓存、对象存储在内的全套运行环境,理解云原生时代下的基础设施配置规范。
丝滑的前端工程化与交互体验
对于后端开发者,这更是一次补齐“全栈视野”的绝佳机会:
SSE (Server-Sent Events) 流式渲染:掌握像 ChatGPT 一样逐字输出回答的底层技术,理解其在单向推送场景下相比 WebSocket 的架构优势。
响应式 UI 与动效设计:利用 Tailwind CSS 极简构建美观界面,结合 Framer Motion 实现高级交互动效。
AI 数据可视化:通过 Recharts 将 AI 分析后的简历评分、多维对比以直观的雷达图形式呈现,让数据“会说话”。
如何加入学习?
很多 AI 项目只停留在调用一个 API。而本项目带你解决的是真实工程问题:
- 如何处理大模型响应慢的问题?(异步处理 + Redis Stream)
- 如何让大模型输出格式固定的数据?(结构化 Prompt + MapStruct)
- 如何让大模型基于私有文档回答?(RAG + pgvector)
本项目为 JavaGuide 知识星球 内部专属实战项目,通过语雀文档在线阅读学习,不单独对外开放。
之所以选择在星球内部发布,是为了确保每一位学习者都能获得深度的技术答疑和完整的求职配套服务。
这只是开始。后续星球还会持续推出更多贴合企业真实业务场景的 Java 实战项目,带你始终站在技术前沿(预告一下,下一个项目是企业级智能客服系统,会带大家实践更多AI能力)。
并且,我的星球还有很多其他服务,比如一对一提问、简历修改、后端系统面试资料(包含高频系统设计&场景题)、学习打卡等,其中任何一项服务单独拎出来的价值都已远超星球门票。欢迎详细了解我的知识星球!
已经坚持维护六年,内容持续更新,虽白菜价(0.4 元/天)但质量很高,主打一个良心!
目前星球正在做活动,两本书的价格,就能让你拥有上万培训班的服务!这里再提供一张 30 元 的优惠券(价格马上上调,老用户扫码续费半价):
用心做内容,坚持本心,不割韭菜,其他交给时间!共勉!