图详解(DFS、BFS、最短路径)
图
图是一种较为复杂的非线性结构。为啥说其较为复杂呢?
根据前面的内容,我们知道:
- 线性数据结构的元素满足唯一的线性关系,每个元素(除第一个和最后一个外)只有一个直接前趋和一个直接后继。
- 树形数据结构的元素之间有着明显的层次关系。
但是,图形结构的元素之间的关系是任意的。
何为图呢? 简单来说,图就是由顶点的有穷非空集合和顶点之间的边组成的集合。通常表示为:G(V,E),其中,G 表示一个图,V 表示顶点的集合,E 表示边的集合。
下图所展示的就是图这种数据结构,并且还是一张有向图。
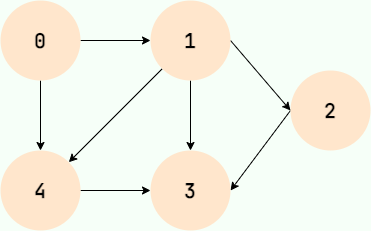
图在我们日常生活中的例子很多!比如我们在社交软件上好友关系就可以用图来表示。
图的基本概念
顶点
图中的数据元素,我们称之为顶点,图至少有一个顶点(非空有穷集合)。
对应到好友关系图,每一个用户就代表一个顶点。
边
顶点之间的关系用边表示。
对应到好友关系图,两个用户是好友的话,那两者之间就存在一条边。
度
度表示一个顶点包含多少条边,在有向图中,还分为出度和入度,出度表示从该顶点出去的边的条数,入度表示进入该顶点的边的条数。
对应到好友关系图,度就代表了某个人的好友数量。
无向图和有向图
边表示的是顶点之间的关系,有的关系是双向的,比如同学关系,A 是 B 的同学,那么 B 也肯定是 A 的同学,那么在表示 A 和 B 的关系时,就不用关注方向,用不带箭头的边表示,这样的图就是无向图。
有的关系是有方向的,比如父子关系,师生关系,微博的关注关系,A 是 B 的爸爸,但 B 肯定不是 A 的爸爸,A 关注 B,B 不一定关注 A。在这种情况下,我们就用带箭头的边表示二者的关系,这样的图就是有向图。
无权图和带权图
对于一个关系,如果我们只关心关系的有无,而不关心关系有多强,那么就可以用无权图表示二者的关系。
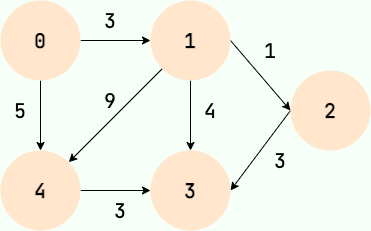
对于一个关系,如果我们既关心关系的有无,也关心关系的强度,比如描述地图上两个城市的关系,需要用到距离,那么就用带权图来表示,带权图中的每一条边用一个数值表示权值,代表关系的强度。
下图就是一个带权有向图。
图的存储
邻接矩阵存储
邻接矩阵将图用二维矩阵存储,是一种较为直观的表示方式。
如果第 i 个顶点和第 j 个顶点之间有关系,且关系权值为 n,则 A[i][j]=n。
在无向图中,我们只关心关系的有无,所以当顶点 i 和顶点 j 有关系时,A[i][j]=1,当顶点 i 和顶点 j 没有关系时,A[i][j]=0。如下图所示:
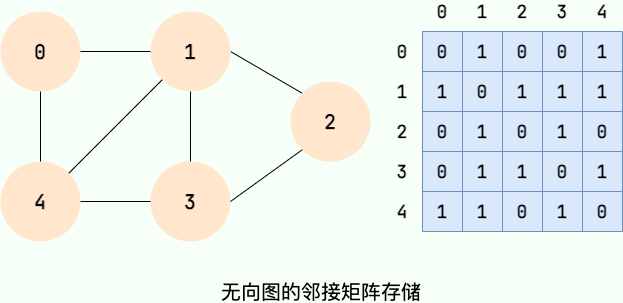
值得注意的是:无向图的邻接矩阵是一个对称矩阵,因为在无向图中,顶点 i 和顶点 j 有关系,则顶点 j 和顶点 i 必有关系。

邻接矩阵存储的方式优点是简单直接(直接使用一个二维数组即可),并且,在获取两个顶点之间的关系的时候也非常高效(直接获取指定位置的数组元素的值即可)。但是,这种存储方式的缺点也比较明显,那就是比较浪费空间。
邻接表存储
针对上面邻接矩阵比较浪费内存空间的问题,诞生了图的另外一种存储方法——邻接表。
邻接链表使用一个链表来存储某个顶点的所有后继相邻顶点。对于图中每个顶点 Vi,把所有邻接于 Vi 的顶点 Vj 链成一个单链表,这个单链表称为顶点 Vi 的 邻接表。如下图所示:
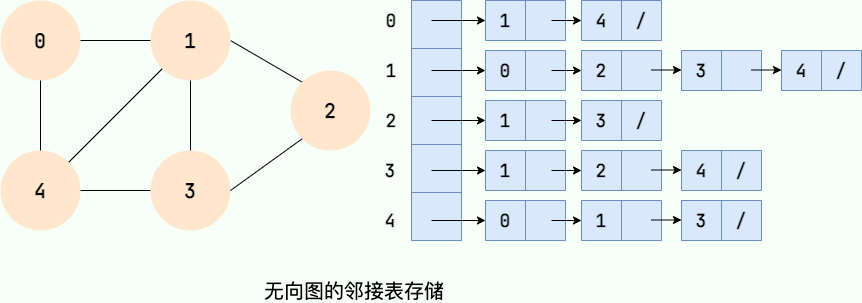

大家可以数一数邻接表中所存储的元素的个数以及图中边的条数,你会发现:
- 在无向图中,邻接表元素个数等于边的条数的两倍,如左图所示的无向图中,边的条数为 7,邻接表存储的元素个数为 14。
- 在有向图中,邻接表元素个数等于边的条数,如右图所示的有向图中,边的条数为 8,邻接表存储的元素个数为 8。
图的搜索
广度优先搜索
广度优先搜索就像水面上的波纹一样一层一层向外扩展,如下图所示:
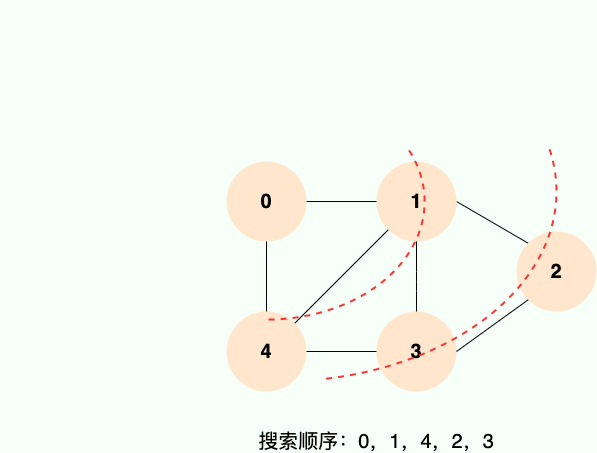
广度优先搜索的具体实现方式用到了之前所学过的线性数据结构——队列。具体过程如下图所示:
第 1 步:
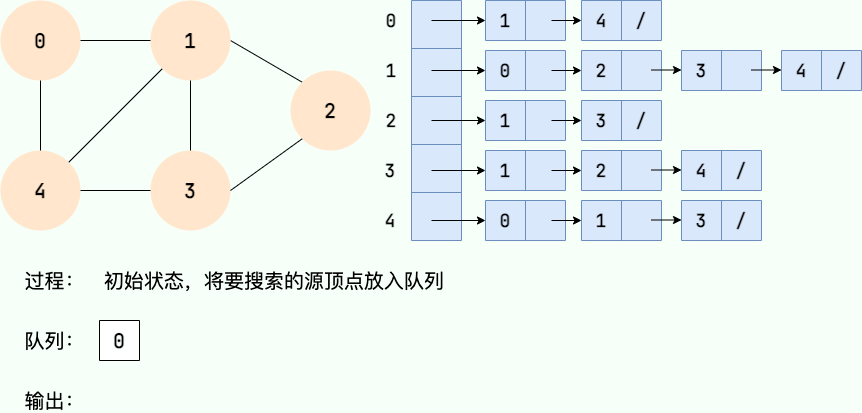
第 2 步:
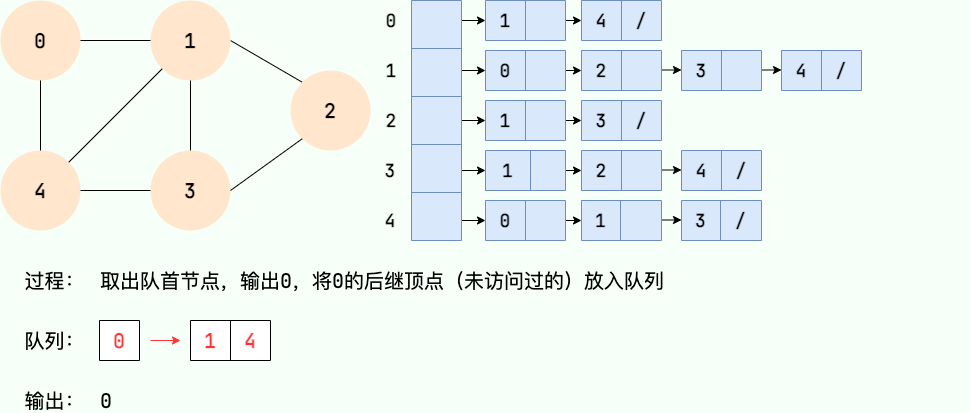
第 3 步:
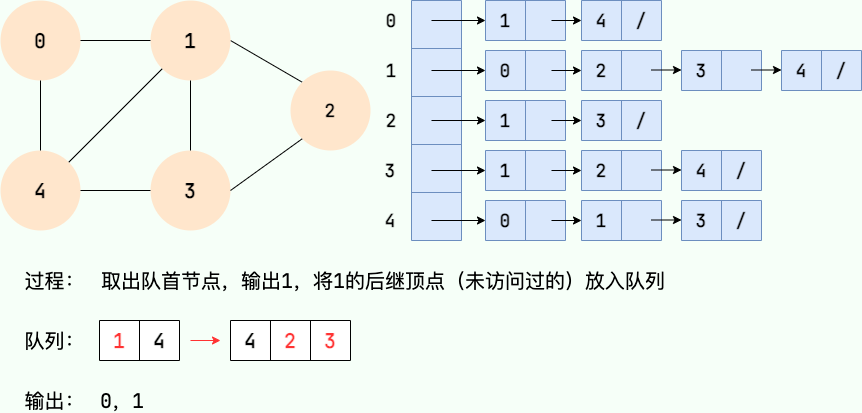
第 4 步:
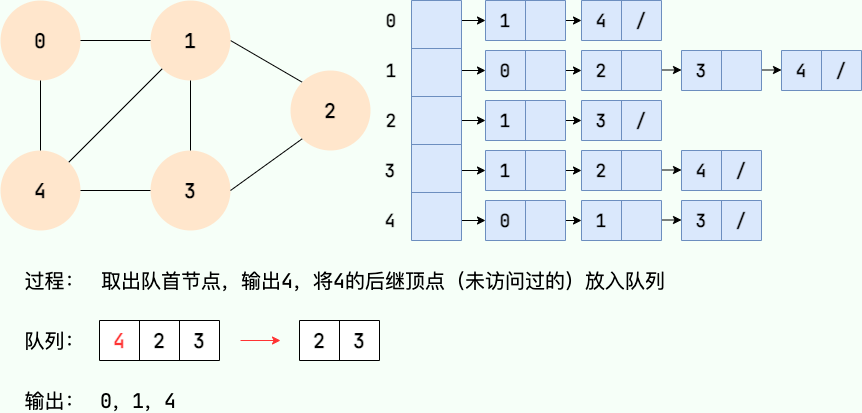
第 5 步:
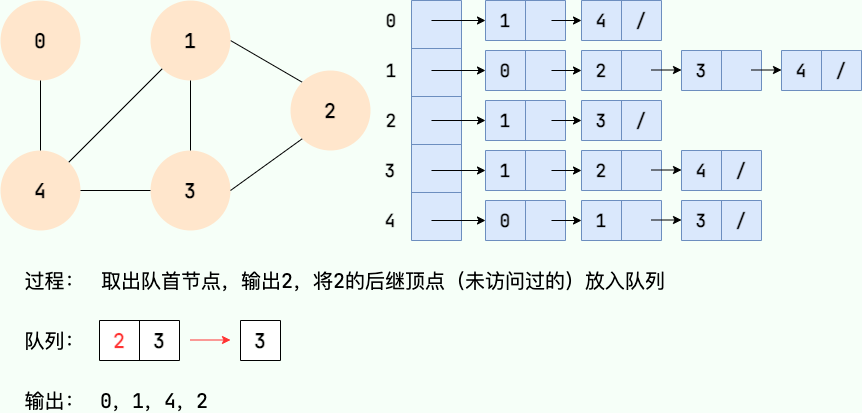
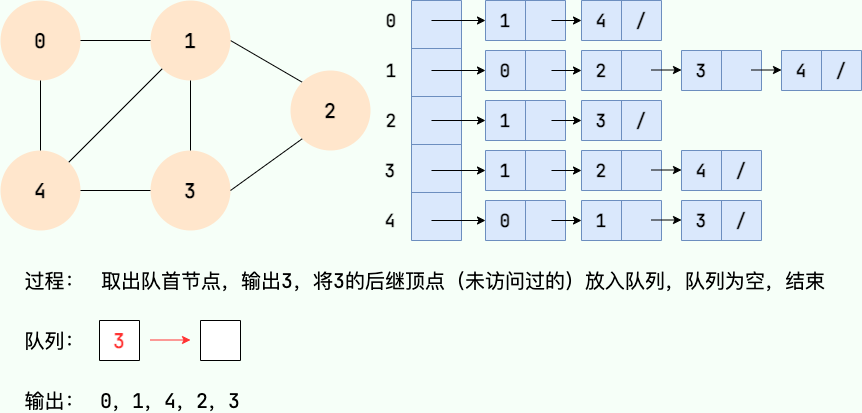
第 6 步:
深度优先搜索
深度优先搜索就是“一条路走到黑”,从源顶点开始,一直走到没有后继节点,才回溯到上一顶点,然后继续“一条路走到黑”,如下图所示:
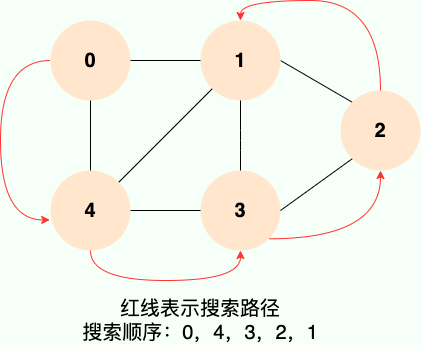
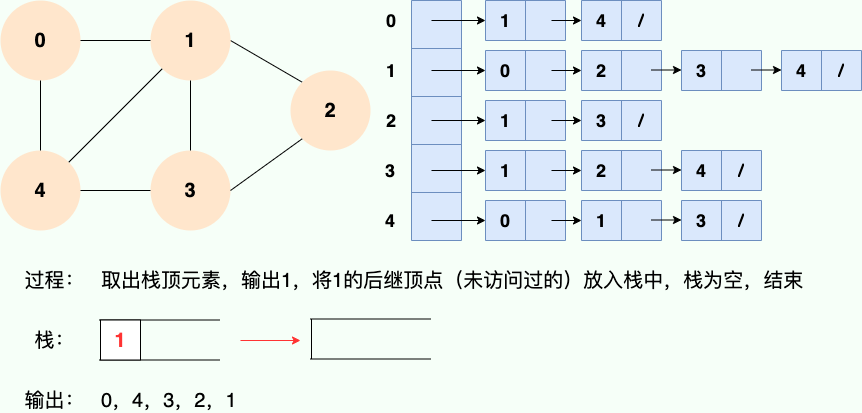
和广度优先搜索类似,深度优先搜索的具体实现用到了另一种线性数据结构——栈。具体过程如下图所示:
第 1 步:
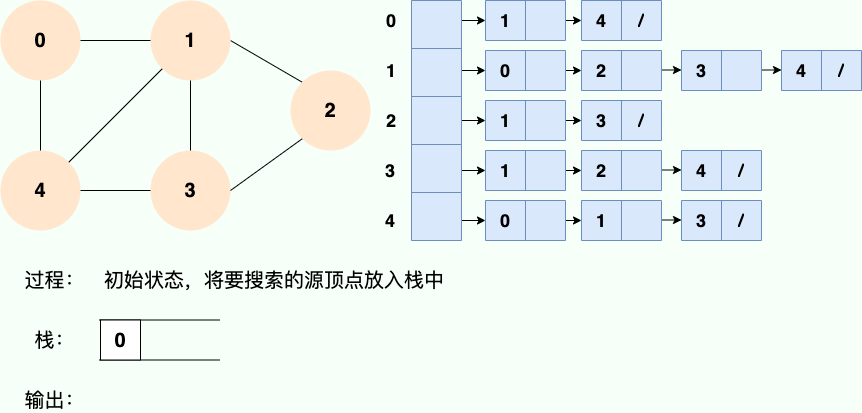
第 2 步:
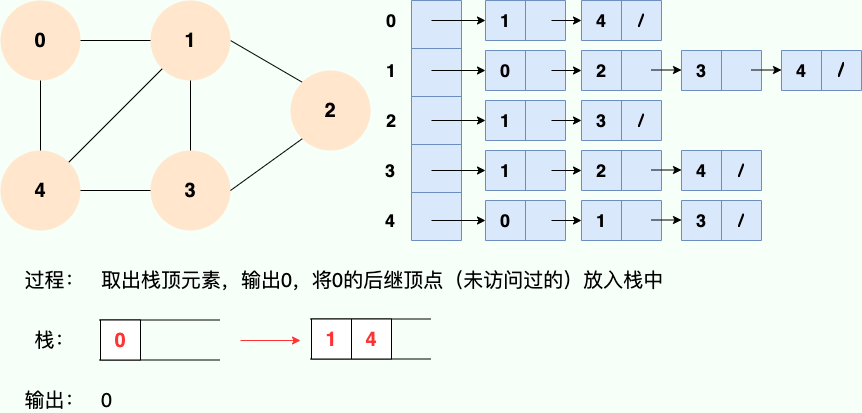
第 3 步:
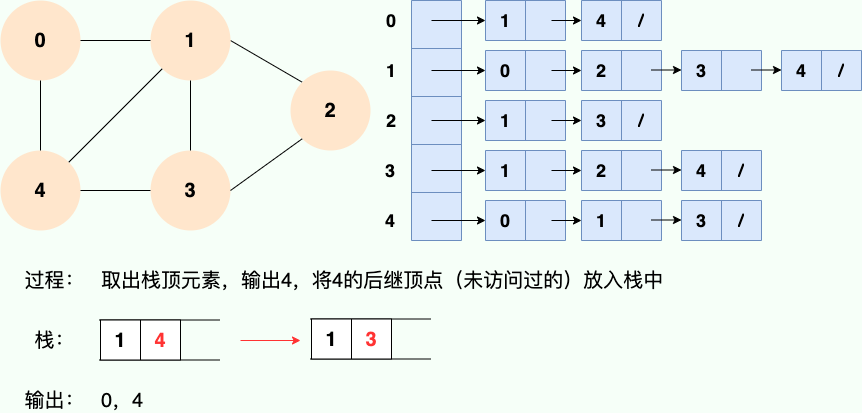
第 4 步:
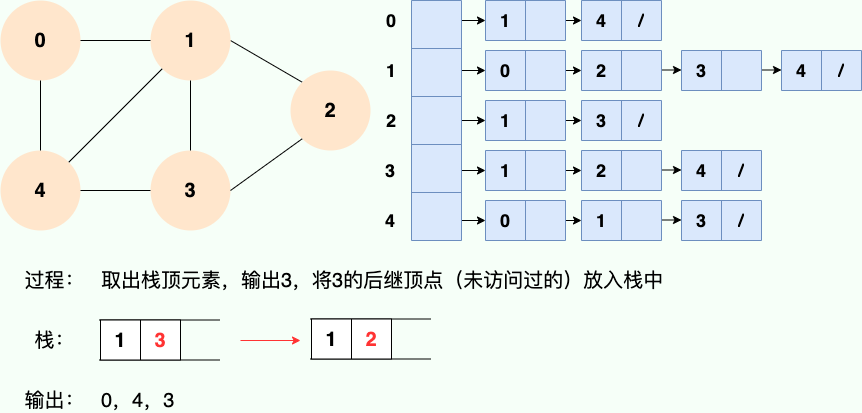
第 5 步:

第 6 步:
面试复盘重点
图题先选存储方式,再选遍历方式。面试里最常见的 4 类图题是:连通块、最短步数、依赖关系和判环。
| 存储方式 | 空间复杂度 | 判断两点是否相邻 | 遍历某点邻居 | 适合场景 |
|---|---|---|---|---|
| 邻接矩阵 | O(V^2) | O(1) | O(V) | 稠密图、节点数较少 |
| 邻接表 | O(V + E) | 取决于邻接表结构 | 和度数有关 | 稀疏图、算法题常用 |
DFS/BFS 模板可以参考 DFS 与 BFS 面试题总结。这里再补几个面试回答点:
- 邻接表下,DFS 和 BFS 的时间复杂度通常是
O(V + E)。 - 无权图求最短步数,优先考虑 BFS。
- 有向图依赖关系常用拓扑排序,典型题是课程表。
- 无向图连通性和判环可以用 DFS/BFS,也可以用并查集。
- 带权最短路径不是普通 BFS,常见算法有 Dijkstra、Bellman-Ford、Floyd,面试中按题目范围选择。
Java 代码模板
算法题中最常用的是邻接表。节点编号通常是 0 到 n - 1,可以用 List<Integer>[] 表示。
List<Integer>[] buildGraph(int n, int[][] edges) {
List<Integer>[] graph = new ArrayList[n];
for (int i = 0; i < n; i++) {
graph[i] = new ArrayList<>();
}
for (int[] edge : edges) {
int from = edge[0];
int to = edge[1];
graph[from].add(to);
// 无向图需要再加一条反向边:
// graph[to].add(from);
}
return graph;
}BFS 适合求无权图最短步数:
int bfs(List<Integer>[] graph, int start, int target) {
boolean[] visited = new boolean[graph.length];
Queue<Integer> queue = new ArrayDeque<>();
queue.offer(start);
visited[start] = true;
int step = 0;
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
int cur = queue.poll();
if (cur == target) {
return step;
}
for (int next : graph[cur]) {
if (!visited[next]) {
visited[next] = true;
queue.offer(next);
}
}
}
step++;
}
return -1;
}过程示意和边界样例
以无权图最短路径为例,BFS 的层序扩散过程可以这样理解:
第 0 层:start
第 1 层:start 的所有未访问邻居
第 2 层:第 1 层节点的所有未访问邻居
...
第一次遇到 target 时,当前层数就是最短步数几个边界样例建议先过一遍:
start == target,答案应该是0。- 图不连通,目标点不可达,答案应该是
-1。 - 无向图建图时忘记加反向边,会把连通图误判成不连通。
- 有环图如果不标记
visited,BFS/DFS 会重复访问甚至死循环。
推荐练习题
写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。