I/O 多路复用详解:select、poll、epoll 原理与区别
写一个 TCP 服务端,最直觉的写法是:主线程 accept 一个连接,就丢给一个新线程去 read、处理、write。连接少的时候这套跑得很好。
可一旦连接数冲到上万,问题就来了。在不少 Linux 发行版里,新线程默认会预留数 MB 的栈空间,常见配置是 8 MB(实际值取决于 ulimit -s、运行库和线程属性)。一万个连接哪怕栈页是按需提交的,预留的地址空间、真正用到的栈页加上线程元数据叠起来也很可观;更要命的是几千上万个线程挤在几个 CPU 核上,光是线程间的上下文切换就把 CPU 啃掉一大半,真正干活的时间所剩无几。更别提大部分连接其实是空闲的——它们各自占着一个线程,却只是在那儿干等数据。
这就是经典的 C10K 问题:怎么让一个(或少数几个)线程,同时盯着成千上万个连接,谁来数据了就处理谁。
答案就是 I/O 多路复用。
下面按 select、poll、epoll 的顺序往下讲,它们解决的是同一个问题,但一个比一个聪明。
什么是 I/O 多路复用?
要讲清楚,得先知道一次网络读操作在内核里其实分成两个阶段:
- 等数据就绪:数据还在网卡、还在路上,内核要等它到达并拷进内核缓冲区。这一步往往很慢。
- 拷数据:数据到了内核缓冲区,再从内核态拷到用户态的应用缓冲区。这一步很快。
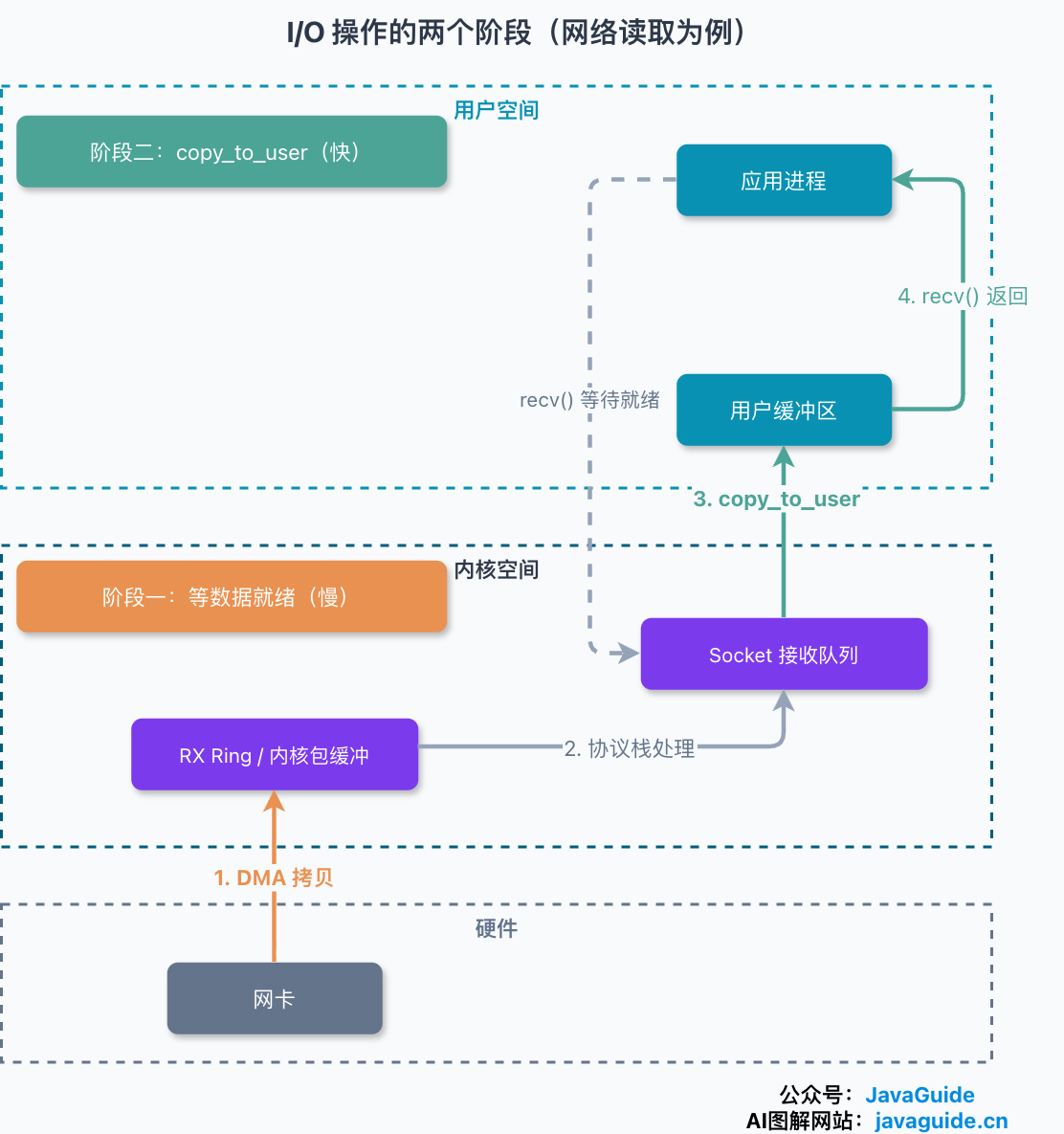
一个连接一个线程的阻塞模型,问题出在第一阶段:线程调用 recv 后就卡死在那儿,专门为这一个连接等数据,等的时候什么也干不了。
I/O 多路复用换了个思路:把所有要监听的文件描述符(fd)交给内核,让线程阻塞在一个专门的监听系统调用上。只要这批 fd 里有任意一个就绪,这个调用就返回,告诉你谁可以读、谁可以写了,然后你再去处理那几个就绪的 fd。
打个比方:一个服务员同时管十张桌子,不是站在第一桌死等客人想好菜,而是来回扫一眼,哪桌举手了就去哪桌。
多路 指的是多个连接,复用 指的是复用同一个线程去处理它们。
注意一个容易混淆的点:多路复用本身仍然是同步 I/O。select 这类调用只报告 fd 已经就绪,应用仍要主动调用 recv 完成读取。同步不等于阻塞:这次 recv 是否会等待,还取决于 fd 是否设为非阻塞、就绪状态是否在读取前发生变化等因素。事件循环通常会配合非阻塞 fd 使用。
多路复用在五种 I/O 模型里的位置
UNP 把 Unix 下的 I/O 归成五种模型,搞清楚多路复用站在哪一格,比单看它本身更清楚:
- 阻塞 I/O:调
recv后线程一直睡,等数据就绪再加拷贝两个阶段全程卡死。最简单,也最浪费线程。 - 非阻塞 I/O:
recv没数据立刻返回EWOULDBLOCK,线程不睡,但你得反复轮询去问“好了没”,空转烧 CPU。 - I/O 多路复用:阻塞在
select/poll/epoll上,一个线程同时等多个 fd,谁就绪处理谁。这就是本文主角。 - 信号驱动 I/O:注册
SIGIO,数据就绪时内核发信号通知你,平时线程该干嘛干嘛。用得不多。 - 异步 I/O:提交请求后立即返回,I/O 完成后再通知应用。这里描述的是语义模型,具体实现取决于平台和 API;例如 Linux glibc 的 POSIX
aio_read主要由用户态工作线程实现,不能直接等同于内核原生异步 I/O。
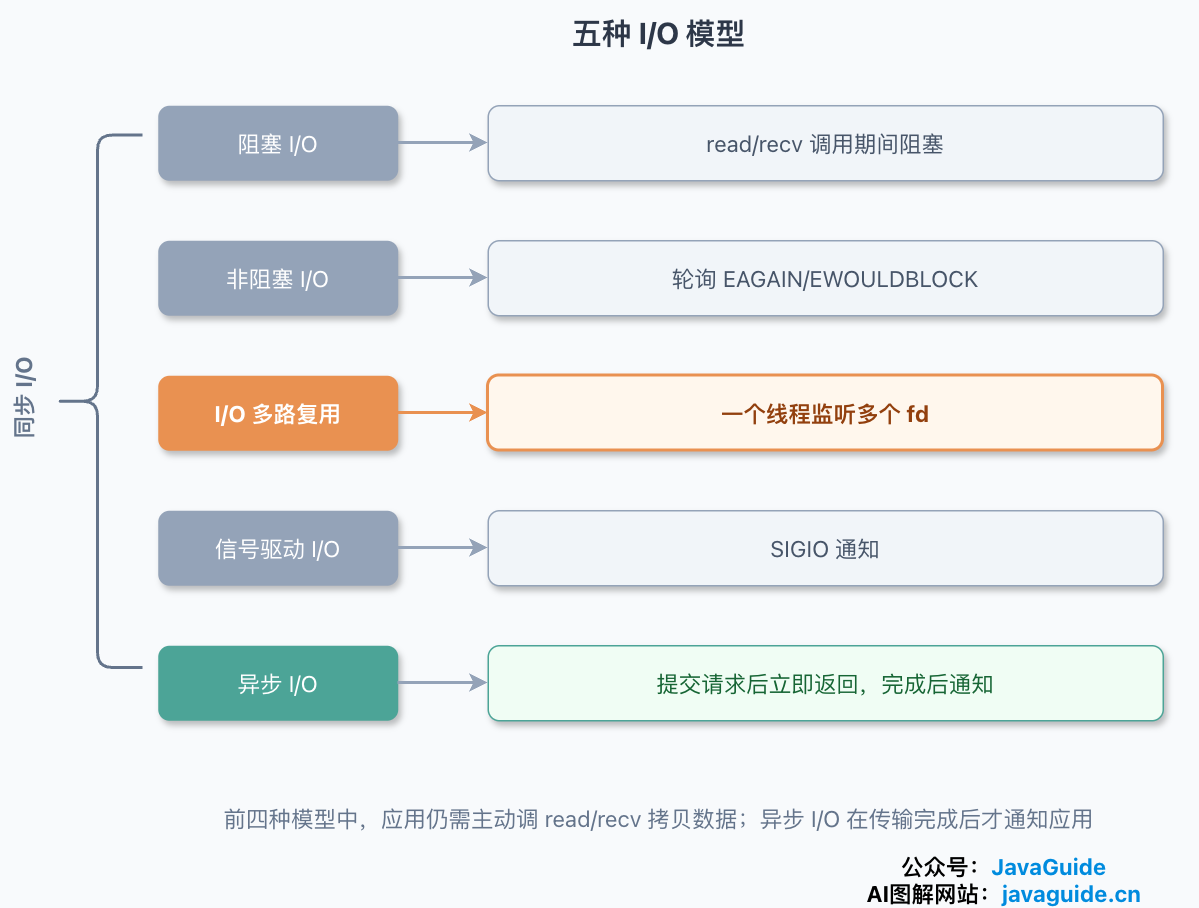
关键区别在于谁来完成“把数据从内核缓冲区搬到用户缓冲区”这个动作:前四种模型里,最终都得由应用自己调 read/recv 来完成这次复制,调用返回后才能用数据,所以都算同步(至于这次调用会不会真的睡,要看 fd 是否非阻塞以及当时数据在不在);只有异步 I/O 把等待和复制全交给内核,完成后再通知你。多路复用的价值不在于让单次读取变快,而在于让一个线程把“等”这件事一次性摊到多个连接上。
select 是怎么做的?
select 是最早的实现,几乎所有平台都支持。它的函数签名长这样:
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);核心是 fd_set 这个数据结构,本质是一个位图:每一位对应一个 fd,置 1 表示关心它。配套有四个宏来操作:
void FD_ZERO(fd_set *set); // 清空所有位
void FD_SET(int fd, fd_set *set); // 把 fd 对应的位置 1
void FD_CLR(int fd, fd_set *set); // 把 fd 对应的位清 0
int FD_ISSET(int fd, fd_set *set); // 检查 fd 对应的位是否为 1一个用 select 写的 echo 服务端,主循环大致是这样:
fd_set rset;
int maxfd = listenfd;
while (1) {
FD_ZERO(&rset); // 每轮都得重新清空
FD_SET(listenfd, &rset); // 再把关心的 fd 一个个塞回去
for (int i = 0; i < n; i++)
if (conns[i] >= 0) FD_SET(conns[i], &rset);
// 写集合、异常集合不关心,传 NULL;最后一个 NULL 表示一直阻塞
int ready = select(maxfd + 1, &rset, NULL, NULL, NULL);
if (FD_ISSET(listenfd, &rset)) { // 监听 fd 就绪,有新连接
int connfd = accept(listenfd, NULL, NULL);
// 存进 conns[],更新 maxfd
}
for (int i = 0; i < n; i++) // O(N) 挨个问:你就绪了吗?
if (conns[i] >= 0 && FD_ISSET(conns[i], &rset)) {
// 处理这个连接上的读事件
}
}这段代码里藏着 select 的几个硬伤,看清楚它们,才明白后面 poll 和 epoll 在改什么。
第一,fd 数量有上限。在 Linux/glibc 环境里,fd_set 位图的大小由 glibc 的常量 FD_SETSIZE 决定,默认是 1024,只能安全表示 0~1023 的 fd——这个限制来自用户态 glibc 的固定大小数据结构和 FD_* 宏,而不是 Linux 内核本身。对超出范围的 fd 使用这些宏属于未定义行为,也别指望靠重定义 FD_SETSIZE 或重新编译内核绕过去。真要盯更多连接,正确做法是换用 poll、epoll。
第二,每次调用都要把位图在用户态和内核态之间来回拷一遍。调用前你在用户态填好位图,select 把它拷进内核;返回时内核改写位图(把没就绪的位清掉),再拷回用户态。内核实际检查和回写的范围由 nfds 决定,所以 fd 编号越大、监听越多,这一来一回越费。
第三,位图是“传入即传出”参数(value-result)。内核返回时会把没就绪的位清零,所以你下一轮必须 FD_ZERO + 重新 FD_SET 一遍,老的关心列表不能复用。代码里那句“每轮都得重新清空”就是被这个逼出来的。
第四,返回后还得自己 O(N) 遍历。select 的返回值只给出就绪 fd 的数量,具体哪些 fd 就绪体现在被原地改写的 fd_set 中。应用仍要遍历候选范围并调用 FD_ISSET;一万个连接哪怕只有一个来数据,也可能要检查一万次。
timeout 这个参数倒是有点用:传 NULL 一直阻塞,传一个 0 值的 timeval 表示不等立即返回(轮询),传具体值表示最多等多久。
poll 改进了什么?
poll 和 select 是同代产物,思路一致,但换掉了数据结构。它不用位图,改用一个 pollfd 结构体数组:
#include <poll.h>
struct pollfd {
int fd; // 要监听的文件描述符
short events; // 你关心的事件,调用前填,比如 POLLIN(可读)
short revents; // 实际发生的事件,由内核回填
};
int poll(struct pollfd *fds, nfds_t nfds, int timeout);主循环长这样:
struct pollfd fds[MAX];
fds[0].fd = listenfd;
fds[0].events = POLLIN;
// 其余 fds[i].fd = connfd; fds[i].events = POLLIN;
while (1) {
int ready = poll(fds, nfds, -1); // timeout 传 -1 表示一直阻塞
for (int i = 0; i < nfds; i++) {
if (fds[i].revents & POLLIN) { // 内核把结果写在 revents 里
// 处理读事件
}
}
}相比 select,poll 改对了两件事:
没有 1024 的硬上限。监听多少个 fd 取决于你传入的数组多大,不再受 FD_SETSIZE 卡死,上限主要看进程能打开的 fd 数。
关心的事件和发生的事件分开了。events 是你填的(输入),revents 是内核回填的(输出),两个字段各管各的。这样下一轮不用像 select 那样把整个关心列表重置,events 保持不动就行。
但 poll 没解决 select 最要命的两个性能问题:每次调用还是要把整个数组从用户态拷到内核态,返回后还是要 O(N) 遍历整个数组才能找出哪些 fd 就绪。连接规模一上去,开销照样是线性增长。
说白了,poll 是把 select 的接口擦干净了,性能模型没变。真正的质变在 epoll。
epoll 为什么是质变?
epoll 是 Linux 专有的,由 Davide Libenzi 实现,在 2.5.44 内核引入,glibc 2.3.2 开始提供封装。它把“一个系统调用搞定一切”拆成了三个,各司其职:
#include <sys/epoll.h>
int epoll_create1(int flags); // 创建 epoll 实例,返回一个 fd(旧接口是 epoll_create(int size))
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 增删改要监听的 fd
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); // 等就绪事件其中 epoll_ctl 的 op 有三种:EPOLL_CTL_ADD(注册)、EPOLL_CTL_MOD(修改)、EPOLL_CTL_DEL(删除)。事件用 epoll_event 描述:
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; // 事件类型,如 EPOLLIN、EPOLLOUT、EPOLLET
epoll_data_t data; // 用户数据,epoll_wait 返回时原样带回,通常存 fd
};完整用起来是这样:
int epfd = epoll_create1(0); // 第一步:建实例
struct epoll_event ev;
ev.events = EPOLLIN; // 关心可读,默认水平触发
ev.data.fd = listenfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, listenfd, &ev); // 第二步:注册一次就够
struct epoll_event events[MAX_EVENTS];
while (1) {
// 第三步:只返回真正就绪的 fd,n 就是就绪个数
int n = epoll_wait(epfd, events, MAX_EVENTS, -1);
for (int i = 0; i < n; i++) { // 只遍历就绪的,不扫描全集
int fd = events[i].data.fd;
if (fd == listenfd) {
int connfd = accept(listenfd, NULL, NULL);
ev.events = EPOLLIN;
ev.data.fd = connfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, connfd, &ev); // 新连接注册进去
} else {
// 处理 fd 上的读事件
}
}
}对比 select 那段代码,差别一眼就看出来:注册 fd 和等事件被拆开了,epoll_wait 返回的 events 数组里全是就绪的 fd,遍历它就行,不用再拿所有 fd 挨个问。
这个差别不是接口设计上的小聪明,而是底层数据结构换了。一个 epoll 实例在内核里对应一个 eventpoll 结构,里面有两样关键东西:
- 一棵红黑树(rbr):存所有通过
epoll_ctl注册进来的 fd(每个 fd 对应一个epitem节点)。增删改是 O(log N) 的树操作。fd 只在这里登记一次,之后一直待着,不像 select/poll 每次调用都要把全量列表搬进内核。 - 一条就绪链表(rdllist):一个双向链表,专门存“已经就绪”的 fd。
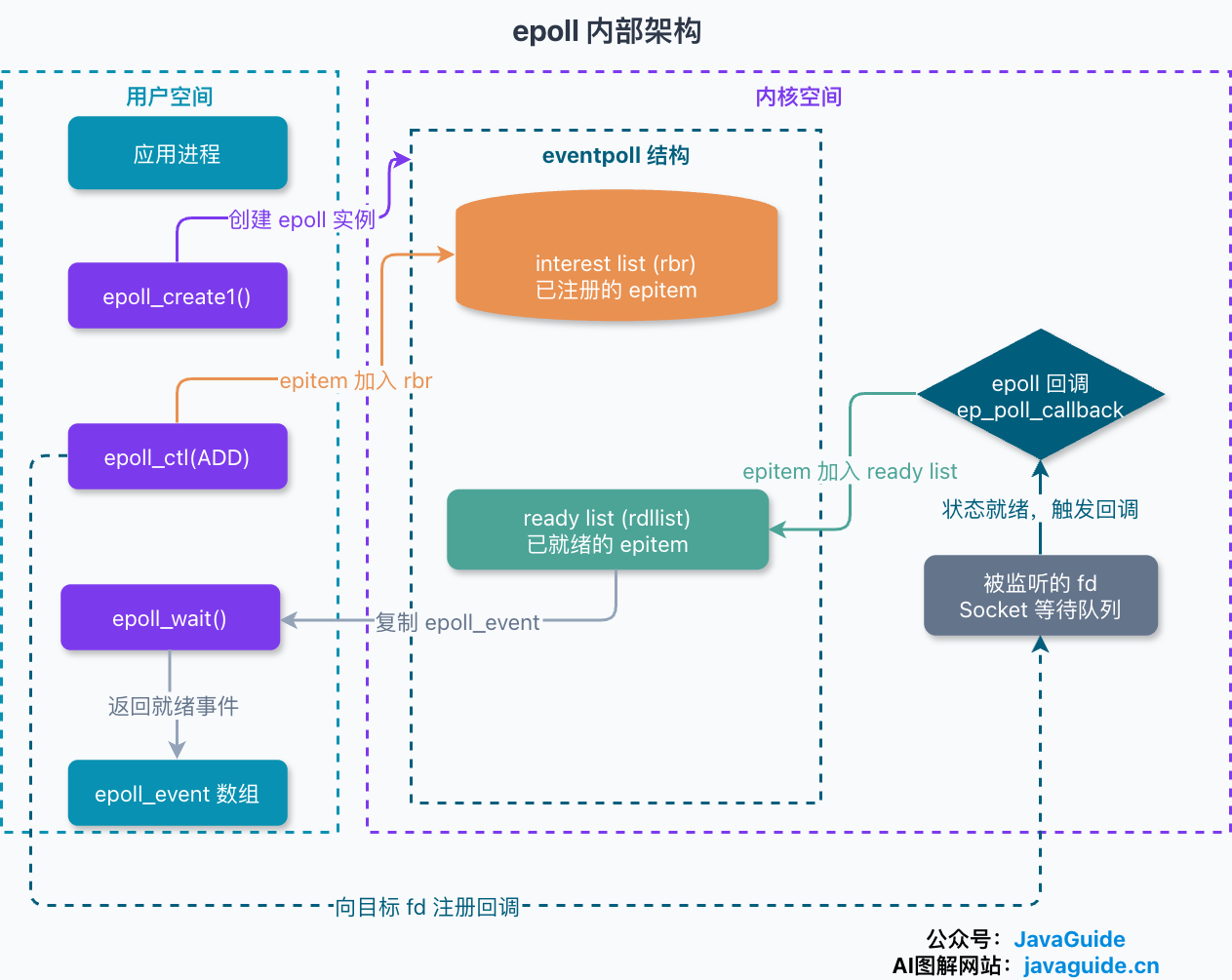
关键在于回调机制。epoll_ctl 注册 fd 时,内核会给这个 fd 挂一个回调函数。当网卡来数据、某个 fd 变得可读时,这个回调被触发,把对应的就绪对象挂进就绪链表,并唤醒阻塞在 epoll_wait 上的线程。于是 epoll_wait 要做的只是看一眼就绪链表空不空——有就把里面的事件拷给用户态,没有就睡觉等回调来唤醒。(补一句:红黑树、就绪链表都是当前内核的实现方式,epoll 对用户态承诺的只是“注册集合 + 就绪列表”这层抽象语义,别把树结构当成稳定的 ABI。)
这就是 epoll 高效的根子:在海量连接、少量活跃的场景下,epoll_wait 返回后要遍历的就只是本批次就绪的事件,和“注册的 fd 总量”无关。注册十万个 fd、其中只有三个来数据,epoll_wait 就只处理这三个,不用像 select/poll 那样每次扫描全集。但要强调:epoll 的整体成本不只是 epoll_wait 返回这一下——注册变更(epoll_ctl)、事件回调、并发锁竞争、把就绪事件拷回用户态都有开销;当连接活跃比例接近 100% 时,它相对 select/poll 的优势也会缩小。一句话总结:select 和 poll 每次等待都要把完整监听集合交给内核并线性扫描;epoll 把监听集合长期保存在内核里,等待时只取已经就绪的事件,因此更适合大量 fd、少量活跃连接的场景。
数据拷贝也省了。fd 通过 epoll_ctl 一次性登记在红黑树上,之后 epoll_wait 反复调用都不用再重传整个 fd 列表。
这里得纠正一个流传很广的说法:“epoll 之所以快,是因为它用 mmap 在内核和用户态之间共享内存,省掉了拷贝。”这个说法是错的。翻 epoll 的内核实现就能看到,epoll_wait 返回时是实打实地用 __put_user 把就绪事件拷到用户态的 events 数组里,并没有什么 mmap 共享区。epoll 省掉的拷贝是另一回事:是省掉了 select/poll 那种“每次调用都把全量 fd 列表搬进内核”的重复拷贝,而不是省掉返回就绪事件这一次拷贝。这两件事别混为一谈。
水平触发和边缘触发,区别在哪?
epoll 支持两种触发模式,这是它比 select/poll 多出来的一个能力,也是面试和实战里最容易踩坑的地方。
水平触发(LT,Level Triggered) 是默认模式。只要 fd 上还有数据没读完(或者还有空间可写),每次 epoll_wait 都会一直通知你。select 和 poll 只有这一种模式。
边缘触发(ET,Edge Triggered) 要显式加 EPOLLET 标志。它只在状态发生变化的那一刻通知一次。
用一个具体场景说清楚区别(这也是 Linux man page 里的经典例子):假设对端往一个 socket 写了 2 KB 数据。
- LT 模式:
epoll_wait通知你可读。你只读了 1 KB,缓冲区里还剩 1 KB。下次epoll_wait还会继续通知你“这儿有数据没读完”,直到你把 2 KB 读干净。 - ET 模式:
epoll_wait通知你一次。你只读了 1 KB 就走了,那剩下的 1 KB——除非对端又写了新数据、状态再次发生变化,epoll_wait不会主动再为它通知你。这 1 KB 可能就长期躺在缓冲区里,连接迟迟得不到处理。
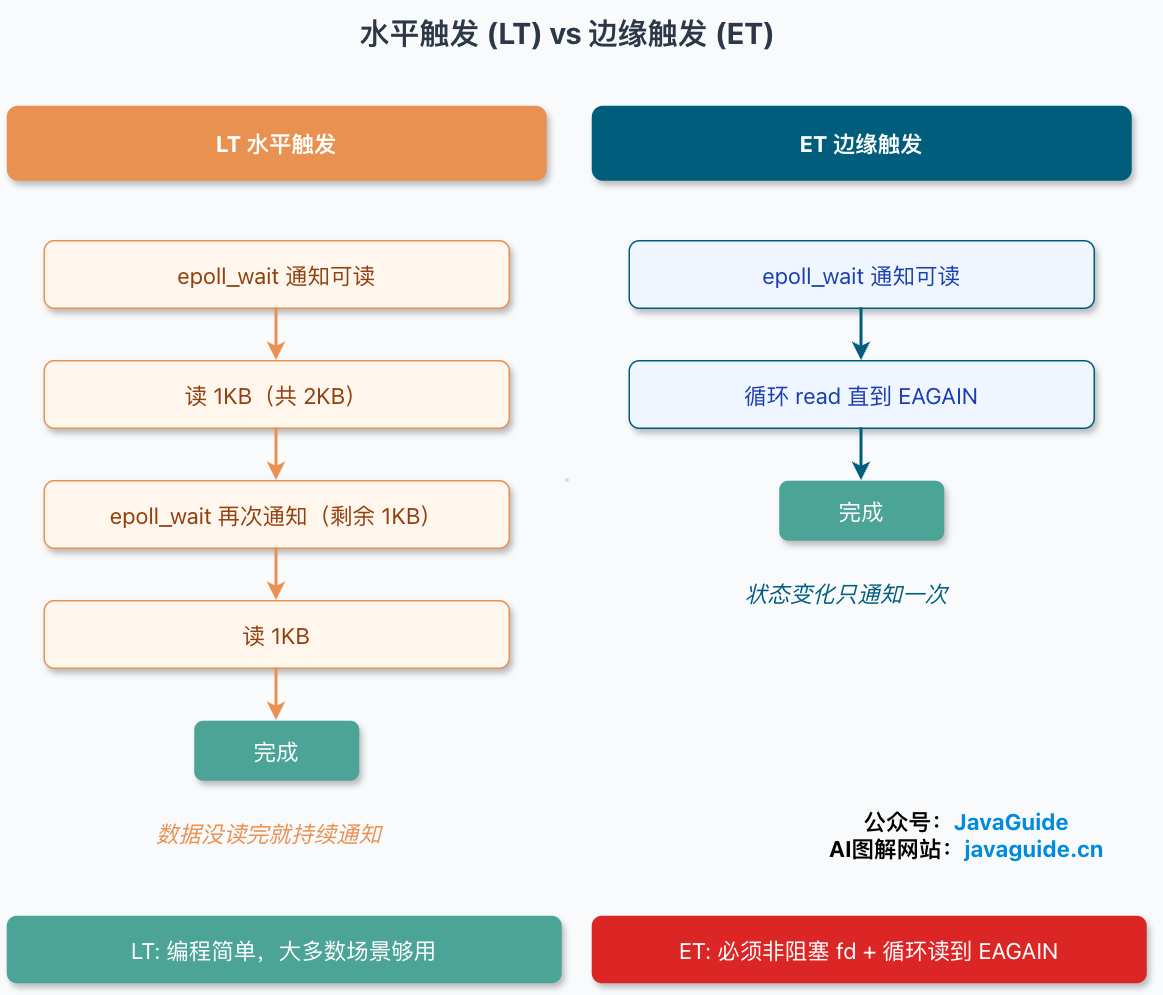
所以用 ET 必须遵守两条铁律:fd 设为非阻塞,并且循环 read 直到返回 EAGAIN(或 EWOULDBLOCK),确保一次把数据彻底读空。典型的 ET 读法是这样:
// 前提:connfd 已设为非阻塞,且注册时带了 EPOLLET
while (1) {
ssize_t n = read(connfd, buf, sizeof(buf));
if (n > 0) {
// 处理这批数据,然后继续循环把缓冲区抽干
} else if (n == 0) {
close(connfd); // 对端关闭连接
break;
} else { // n < 0
if (errno == EAGAIN || errno == EWOULDBLOCK)
break; // 数据读完了,这才是正常退出点
if (errno == EINTR)
continue; // 被信号打断,重试
close(connfd); // 真出错了
break;
}
}如果 fd 是阻塞的,最后一次没数据的 read 会把整个线程卡死在这里——这也是为什么 ET 和非阻塞 fd 必须成对出现。
ET 的好处是减少 epoll_wait 的唤醒次数,适合追求极致吞吐、又能把读写逻辑写严谨的场景;代价是编程门槛明显更高,漏读 EAGAIN 导致连接长期停滞是这类代码最常见的 bug。反过来,如果为了“读干净”在单个活跃 fd 上一直读,又可能饿死其他连接,所以工程上常给每个 fd 设单轮处理预算、配合应用层就绪队列轮转。LT 编程简单、不容易出错,绝大多数业务用 LT 就够了。Nginx 这类对性能敏感的服务才会用 ET。
写生产级事件循环时,光会读还不够,还有一圈边角要处理:epoll_wait 被信号打断返回 EINTR 要重试;ET 下 accept 同样得循环到 EAGAIN;EPOLLERR/EPOLLHUP/EPOLLRDHUP 要和读写事件一起判断;read 返回 0 表示对端关闭了写方向;write 可能短写,得自己缓存没发完的数据并按需注册 EPOLLOUT;多线程处理同一个 fd 时,考虑用 EPOLLONESHOT 配合重新武装(rearm)。
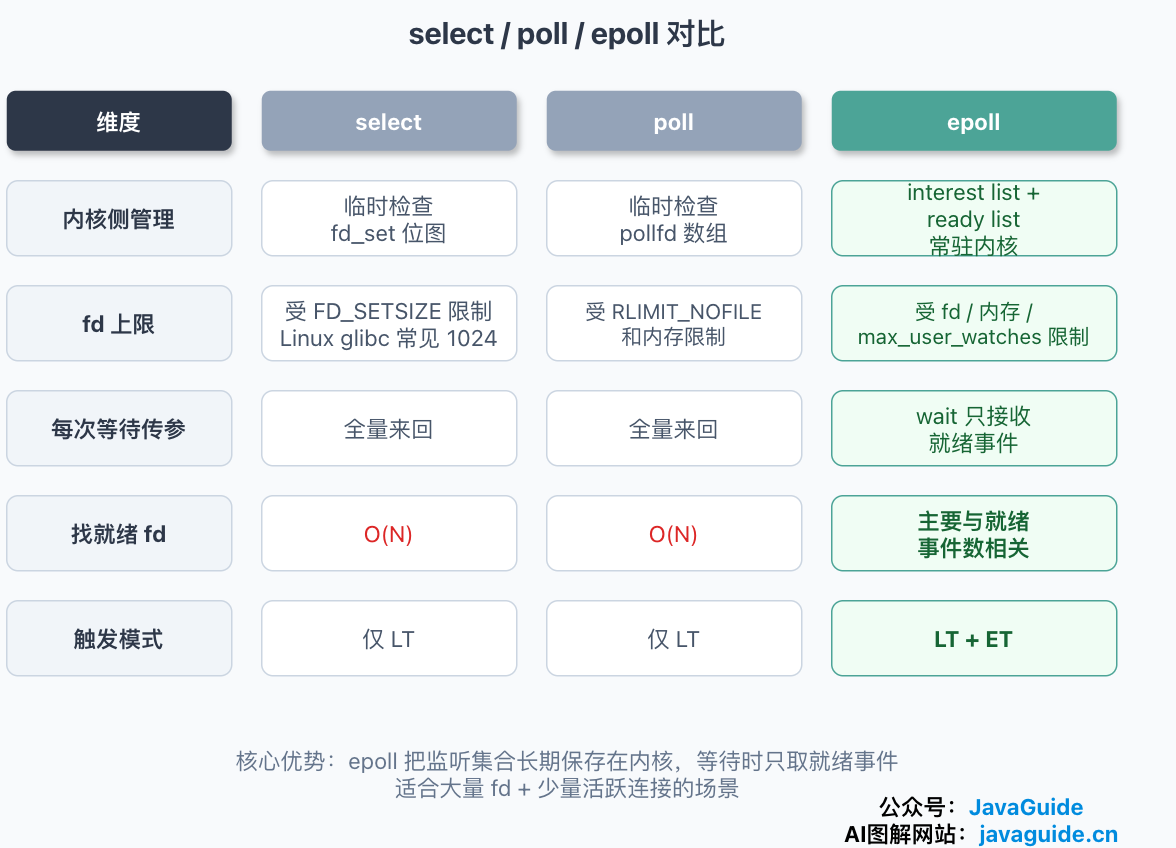
三者横向对比
把前面拆开讲的东西汇总成一张表,方便横向看:
| 维度 | select | poll | epoll |
|---|---|---|---|
| 平台 | 跨平台较好;Unix、Windows 均有(Windows 主要用于 socket) | 主要用于 Unix-like 系统 | Linux 专有(Linux 2.6+) |
| 内核侧管理 | 每次调用临时检查 fd 集合 | 每次调用临时检查 fd 数组 | 长期维护 interest list 和 ready list;Linux 当前实现通常使用红黑树和就绪链表 |
| fd 数量限制 | 受 FD_SETSIZE 限制;Linux glibc 通常为 1024,只能安全处理编号 0~1023 的 fd | 不受 FD_SETSIZE 限制,但仍受 RLIMIT_NOFILE 和内存约束 | 不受 FD_SETSIZE 限制,但受文件描述符、内存和 max_user_watches 等限制 |
| 每次等待的传参 | 每轮传入完整位图,返回后集合被修改,下轮必须重建 | 每轮传入完整 pollfd 数组,内核填写 revents(events 不用重建) | 监听集合通过 epoll_ctl 维护,epoll_wait 只接收就绪事件 |
| 查找就绪 fd 的开销 | 扫描到 nfds - 1,通常记作 O(N) | 遍历整个数组,O(N) | 等待阶段不扫描完整监听集合,返回成本主要与就绪事件数有关 |
| 触发模式 | 仅 LT | 仅 LT | 默认 LT,也支持 ET(EPOLLET) |
epoll 不是银弹
讲到这儿很容易得出“epoll 全面碾压”的结论,但实战里没这么绝对,有几个边界值得记住。
连接少且都很活跃时,epoll 不一定更快。epoll 维护红黑树、挂回调、走就绪链表这套机制本身有固定开销。如果你只盯着几十个 fd,而且它们几乎每次都有数据,那么 select/poll 那种“一把梭遍历”反而更直接、更省。epoll 的主场是海量连接 + 大部分空闲:几万条长连接挂着,同一时刻只有少数活跃,这时候只盯就绪的那几个才真正划算。
它是 Linux 专有的。macOS 和 BSD 上对应的是 kqueue,Windows 上是 IOCP。要写跨平台的网络程序,一般不会直接调 epoll,而是用 libevent、libuv 这类封装库,让它们在 Linux 上走 epoll、在别的系统上走对应实现。
惊群问题。多个进程/线程在同一个 listen fd 上等事件时,一个连接到来可能把它们全唤醒,但只有一个能 accept 成功,其余白忙一场。Linux 4.5 之后可以用 EPOLLEXCLUSIVE 标志缓解,让内核在多个 exclusive waiter 里只唤醒一个、或较少的几个;它并不是在所有部署形态(比如多个 epoll 实例、混用非 exclusive 注册)下都“严格只唤醒一个”的保证。
ET 模式的坑前面说过:一旦漏读没到 EAGAIN,剩余数据可能长期不再触发通知,连接迟迟得不到处理。这不是性能问题,是正确性问题,调试起来还很隐蔽。没把握就老老实实用 LT。
它们都用在哪儿
这套机制不是停在课本上的概念,常见的高性能组件底层都靠它。
Redis 是单线程事件循环 + I/O 多路复用的典型。它没有为每个客户端开线程,而是用一个线程通过多路复用同时监听大量 socket,谁就绪了就调对应的事件处理器。Redis 自己封装了一层(ae.c),在不同平台上分别选 epoll、kqueue 或 select。这也是它单线程还能扛住高并发的关键之一,省掉了多线程的上下文切换和锁竞争。
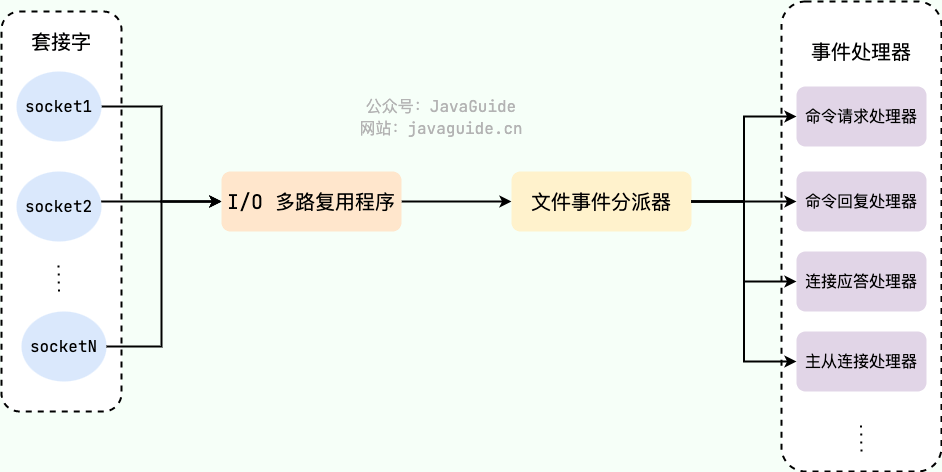
补充一个常被误解的点:Redis 6.0 引入了多线程,但加的只是网络 I/O 读写和协议解析这部分,命令的实际执行仍然是单线程。多路复用这套事件循环的内核没变,多线程只是把“读 socket、解析请求”这种耗时的活儿分摊到几个线程上,避免它成为单线程的瓶颈。
详细介绍推荐你看看这篇文章:Redis常见面试题总结(上)。
Nginx 是多进程 + epoll,而且用的是 ET 模式,配合非阻塞 socket 把每次唤醒的处理压到最少,这是它能用很少的进程扛住海量连接的底子。
Java NIO 里的 Selector 就是多路复用的 Java 封装。在 Linux 上,Selector 底层走的就是 epoll(对应 EPollSelectorImpl);换到别的系统会换成对应实现,这层切换对上层代码透明。
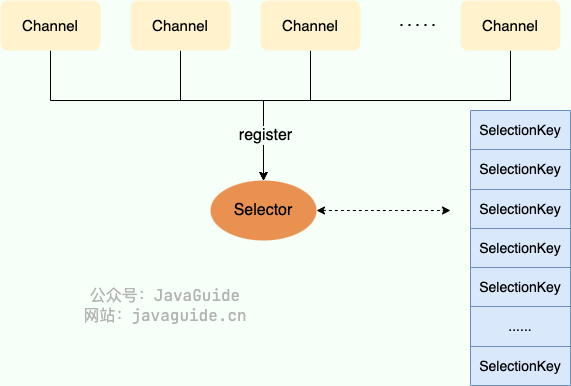
Netty 在标准 NIO 之外还额外提供了一套原生 epoll 传输(EpollEventLoop),直接对接 epoll、绕开 JDK 那层封装,在 Linux 上能榨出更高的性能。这里要留意版本差异:Netty 4.0 的原生 epoll transport 曾主打边缘触发;到了 Netty 4.2,EpollMode 已被标记废弃,并注明 transport 始终使用水平触发。中间 4.1 各小版本的行为以所用版本的源码和 API 为准。
另外,关于 Java I/O 模型的针对性详细介绍,可以阅读这篇文章:Java I/O 模型详解。
面试里怎么答?
问“I/O 多路复用解决什么问题”,别答成“让一次 read 更快”。它解决的是“等”的问题:一个线程不用阻塞在单个连接上,而是把一批 fd 交给 select、poll 或 epoll,哪个 fd 就绪了再处理哪个。真正把数据从内核缓冲区拷到用户缓冲区的 read/recv 仍然是应用自己调用,所以它属于同步 I/O 模型。
select、poll、epoll 的区别可以从三点展开。第一,数据结构不同:select 用固定大小的 fd_set 位图,Linux glibc 下通常受 1024 限制;poll 换成 pollfd 数组,绕开了 FD_SETSIZE,但数组仍然每次传进内核;epoll 把监听集合长期放在内核里,通过 epoll_ctl 增删改,epoll_wait 只拿就绪事件。
第二,性能模型不同。select 和 poll 每次等待都要传完整集合,返回后还得线性扫描,连接多但活跃少时很亏;epoll 适合大量 fd、少量活跃连接,因为等待阶段不用扫描完整监听集合,返回成本主要和本轮就绪事件数相关。不过它不是所有场景都更快,连接很少且都很活跃时,维护回调、红黑树和就绪链表的固定成本也要算进去。
第三,epoll 的 LT/ET 经常被追问。LT 是默认模式,只要缓冲区还有数据没读完,下次还会通知;ET 只在状态变化时通知一次,所以必须配合非阻塞 fd,并循环读到 EAGAIN。面试里能把这句话说清楚,再补上 EINTR、短写、EPOLLHUP/EPOLLERR 这些生产代码要处理的边角,基本就不是只会背概念了。