分布式协调详解:Leader、Quorum、Lease、Fencing Token 与 Gossip
一个定时任务部署了 3 个实例,到了凌晨 2 点,到底谁来跑这批任务?
如果 3 个实例都跑,数据可能被重复处理;如果 3 个实例都等别人跑,任务就会漏掉。缓存集群、消息队列、配置中心、分布式锁也会遇到类似问题:节点多了以后,系统必须有人决定“谁负责什么”“谁现在还活着”“这次变更按什么顺序生效”。
这就是分布式系统里的协调问题。
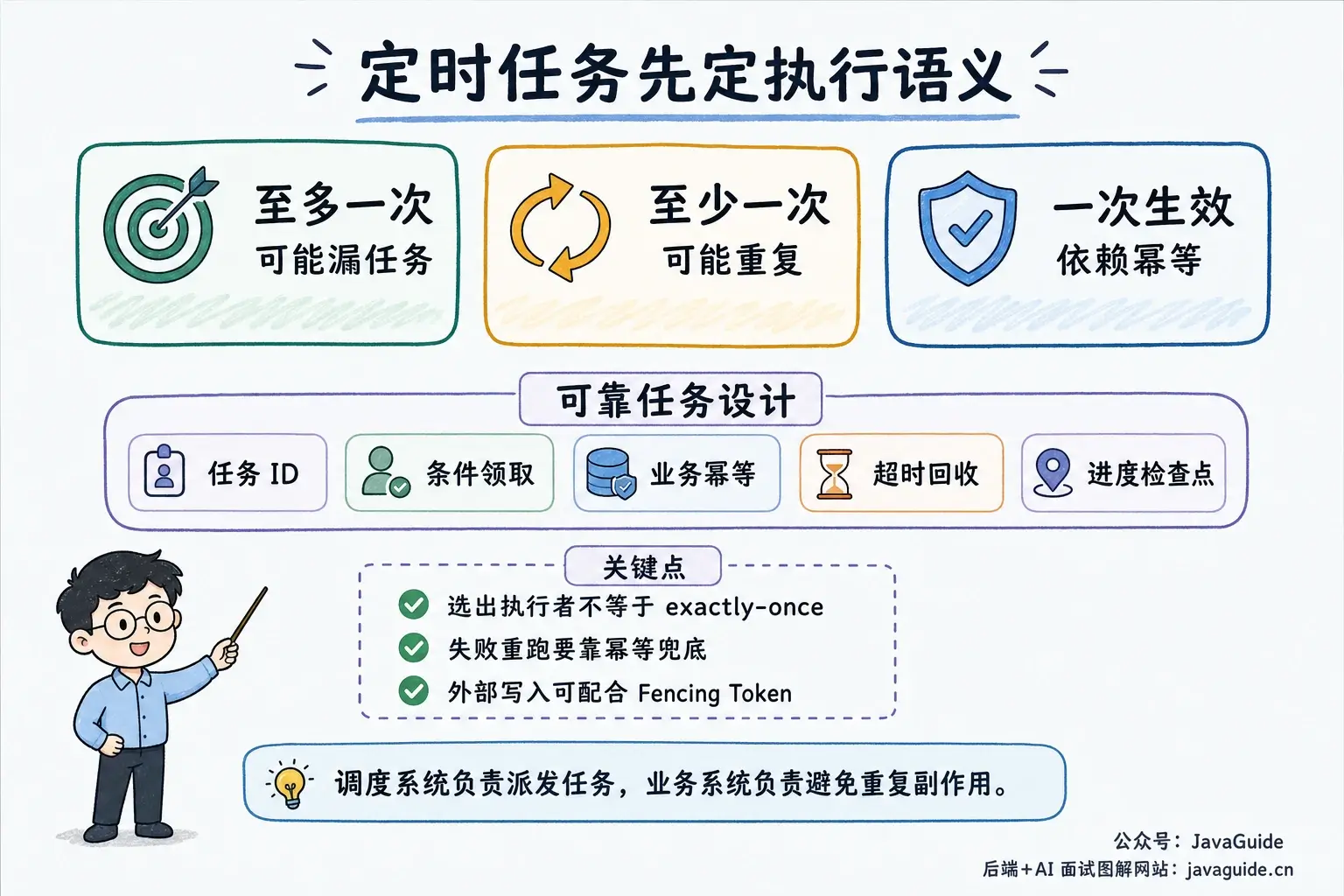
不过,这里要先区分两件事:只选出一个执行者,和业务只生效一次。
选主、分布式锁或数据库抢占可以减少多个实例同时执行,但无法单独保证端到端的 exactly-once。执行节点可能已经处理成功,却在更新任务状态前宕机;调度系统为了避免漏任务,只能再次派发。Kubernetes CronJob 官方文档也提醒过,CronJob 创建 Job 的时间是近似的,某些情况下可能创建两个 Job,也可能没有创建 Job,因此 Job 本身应该设计成幂等。
生产里的定时任务通常更接近“至少执行一次 + 业务幂等”:用任务 ID、业务唯一键、状态机、去重表或事务约束保证同一批数据重复执行时不会产生额外副作用。
这篇文章只讨论设计取舍,不展开 ZooKeeper、etcd、Redis Cluster、Eureka 等具体系统的完整实现。想看共识算法,可以继续读 Raft 算法详解 和 ZAB 协议详解;想看状态传播,可以继续读 Gossip 协议详解;想看业务互斥,可以继续读 分布式锁实现方案详解。
这篇和其他文章是什么关系?
分布式系统入门 解决的是“为什么单机系统拆成多节点后会变复杂”。CAP 定理与 BASE 理论详解 解决的是“分区发生时一致性和可用性怎么取舍”。Raft、Paxos、ZAB 解决的是“一组节点如何对某个值或日志顺序达成一致”。Gossip 解决的是“状态如何在大量节点之间传播并最终收敛”。
这篇文章放在它们中间,重点回答一个更工程化的问题:一个分布式系统到底怎么协调多个节点?
为了避免概念混在一起,先拆成两类问题:
- 决策问题:谁能成为 Leader?某条日志是否提交?某个资源当前归谁?某个任务能不能执行?
- 传播问题:成员状态、故障报告、配置版本、缓存元数据怎么扩散到其他节点?
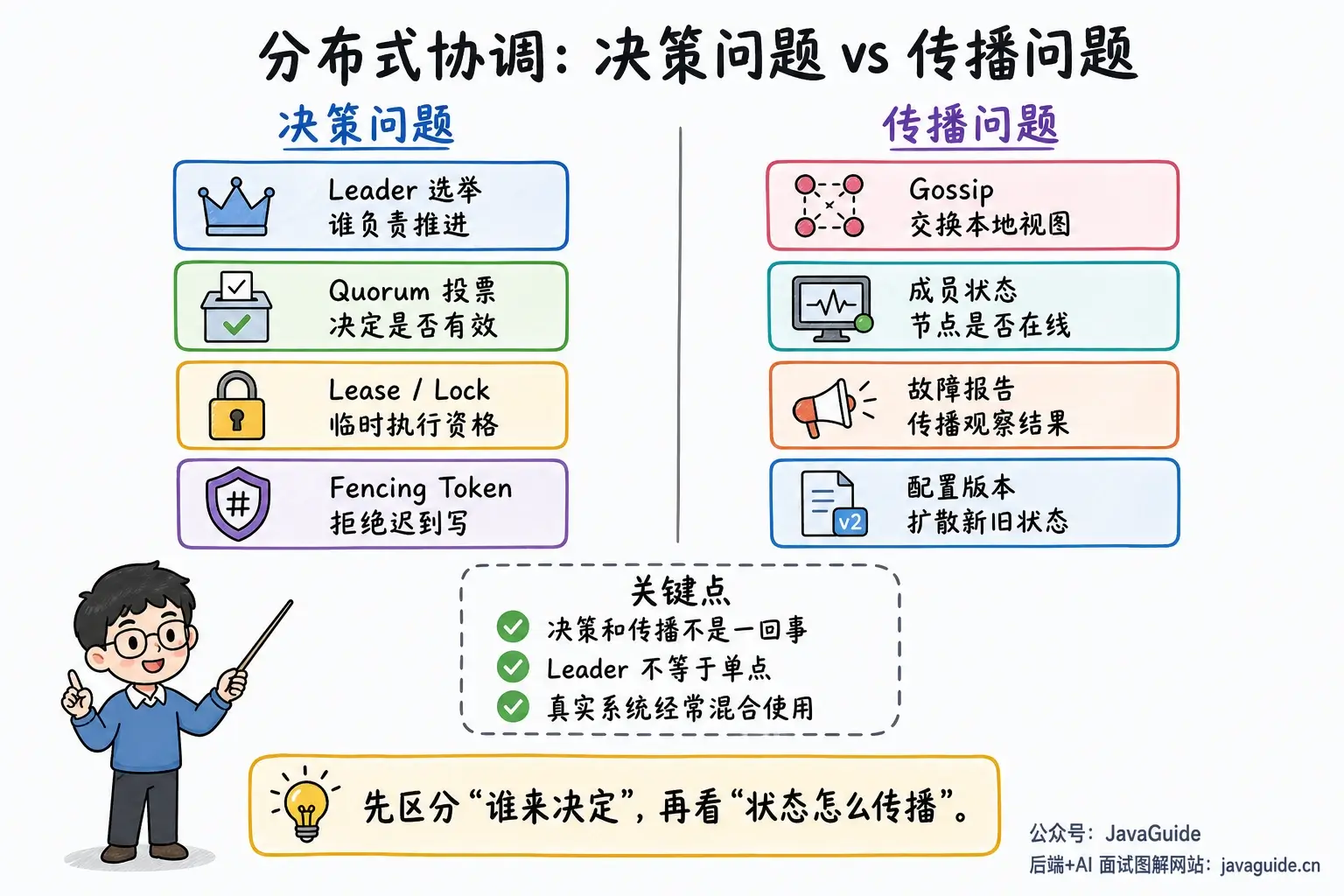
Leader、Quorum、Lease、Lock、Fencing Token 主要围绕决策和执行资格展开;Gossip 主要解决状态传播。真实系统经常把这些机制组合起来使用,很少只有简单的“中心化”或“去中心化”二选一。
分布式系统为什么要协调?
单机系统里,很多事情可以直接靠本地内存、数据库事务或进程锁完成。到了分布式系统里,这些办法突然不够用了。
分布式系统多了一层网络,不确定性也跟着来了。
每个节点只能看到自己的本地状态,以及已经收到的消息。某个节点没有响应,可能是真的宕机了,也可能是网络抖动、GC 暂停、磁盘 I/O 卡住、线程池打满。调用方看到的超时,只能说明自己在指定时间内没有收到结果,不能证明对方一定没有执行。
协调要解决的就是这些问题:
- 成员管理:集群里有哪些节点?哪些节点现在可以参与工作?
- 任务分配:某个分片、任务、分区、主副本应该由谁负责?
- 顺序控制:多个节点同时提交变更时,谁先谁后?
- 故障切换:负责节点失联后,谁来接管?接管之前要确认哪些状态?
- 版本推进:配置、元数据、选主结果变化后,如何让节点识别新旧状态?
这些问题可以交给当前 Leader 统一推进,也可以让一组节点通过 Quorum 共同判断,还可以通过 Gossip 先传播观察到的状态,再由投票、版本号或业务规则作出决定。
Leader/Quorum 协调:谁来作出决定?
很多系统会引入 Leader、Primary 或调度中心。其他节点主要执行任务,或者根据 Leader 推进的日志、配置和分配结果更新状态。
这里容易有一个误解:有 Leader 不等于有一个脆弱的单点。Raft、ZAB 这类系统里的 Leader 是多副本选举出来的当前角色,状态仍然由日志复制和 Quorum 保护。真正要看的是,Leader 背后的状态有没有副本保护,Leader 挂掉后能不能选出新的 Leader,以及新 Leader 能不能接住旧状态继续工作。
Leader 常见职责有几类。
第一类是维护集群视图。比如哪些 Worker 在线、每个 Worker 的负载如何、某个分片现在归谁、某个副本是不是落后太多。这些信息可能来自心跳、上报、探测,也可能来自底层存储里的注册信息。
第二类是做分配决策。比如任务调度系统把任务派给某个执行器,分布式存储把分片迁移到某台机器,消息队列把分区 Leader 切到另一个副本。Worker 不需要各自猜测,只要执行已经确认的分配结果。
第三类是控制写入顺序。很多分布式系统并不怕读请求分散,真正麻烦的是写请求。多个节点同时改元数据,如果没有统一顺序,很容易出现两个节点都认为自己持有同一个分片、两个任务都认为自己是主执行者这类问题。Leader 可以把写入串成一条有序日志,再复制给其他节点。
Leader 让系统行为更容易理解,排查问题时也更容易找到决策入口。代价是协调链路可能变成瓶颈,也必须处理误判、脑裂和故障切换。
Leader/Quorum 协调会遇到哪些问题?
最容易想到的是 Leader 单点。
如果 Leader 的状态只存在自己内存里,Leader 一挂,集群就不知道当前任务分配、分片归属和最新元数据是什么。这种设计确实很危险。更常见的工程做法是让 Leader 只承担“当前决策者”的角色,元数据和日志复制到多个副本里。Leader 挂掉后,剩余节点基于已有日志再选出新 Leader。
另一个问题是瓶颈。所有协调请求都经过 Leader,Leader 的 CPU、网络、磁盘日志写入都会影响整个系统。尤其是元数据变更很频繁时,Leader 会变成系统扩展的上限。很多系统会把数据面和控制面拆开:普通读写尽量分散,只有选主、元数据变更、分片迁移这类操作才进入协调链路。
更麻烦的是误判。
心跳检测很常见,但心跳不是“生死证明”。Leader 没收到 Worker 的心跳,只能说明在当前网络和超时时间内没有收到响应。Worker 可能还在执行任务,只是卡在 Full GC、网络隔离或磁盘写入上。如果 Leader 直接把任务交给另一个 Worker,旧 Worker 恢复后继续写结果,就可能出现重复写入。
脑裂也是从这里来的。
脑裂发生时,多个分区会同时认为自己有权继续推进系统状态。比如原 Leader 和一部分节点被隔离,另一部分节点又选出了新 Leader。如果两个 Leader 都能对外接受写入,分区恢复后就会出现两条互相冲突的状态线。对配置中心、分布式锁、主从切换、分片归属这类场景来说,这通常是不能接受的。
所以,难点不止是“选一个 Leader”,还要让旧 Leader 在失去资格后不能继续造成破坏。
如何缓解 Leader 单点和脑裂?
只给 Leader 配一个备用节点还不够。备用节点要接管,就必须知道 Leader 已经做过哪些决定、哪些决定已经提交、哪些决定还只是 Leader 自己以为成功。
这就需要副本、Quorum 和协议约束。
多数派不是完整答案
多数派规则很好理解:超过半数节点同意后,才认为某个决定有效。假设集群有 N 个投票节点,多数派就是 floor(N/2) + 1。3 个节点需要 2 个同意,5 个节点需要 3 个同意。
这个公式默认几个前提:
- 成员集相对固定;
- 每个投票节点权重相同;
- 处理的是崩溃故障和网络分区,不考虑恶意节点;
- 使用的是普通多数派 Quorum,而不是加权 Quorum、Flexible Quorum 或 BFT Quorum。
多数派有一个重要性质:任意两个多数派集合一定有交集。
但“存在交集”本身还不够。协议还必须约束谁有资格当选,以及新 Leader 如何恢复状态。以 Raft 为例,每个节点在同一个 Term 内最多投一票,候选人的日志还必须至少和投票者一样新。多数派交集加上日志新旧判断,才能保证已经提交的日志不会在后续选主时丢失。Raft 把这类性质称为 Leader Completeness。
因此,多数派提供的是交集基础;真正的安全性还来自选举规则、日志匹配规则和提交规则。
多数派也有成本。对依赖多数派保证安全的协调状态或复制日志,拿不到 Quorum 时通常应停止提交新的写入。系统是否还能提供旧数据读取,取决于具体协议和一致性要求。3 个节点容忍 1 个投票节点故障,5 个节点容忍 2 个投票节点故障;4 个节点仍然只能容忍 1 个投票节点故障,6 个节点仍然只能容忍 2 个投票节点故障,所以很多协调系统更推荐奇数个投票节点。
Term/Epoch 只能保护协议内部
Leader 选举通常需要任期概念。Raft 里叫 Term,ZAB 里有 Epoch。每次选主进入一个新的任期,节点看到更高任期后,会拒绝旧任期请求,旧 Leader 也应退回普通节点。
这主要保护的是协调协议内部状态。
任期不会自动传播到所有外部业务资源。旧 Leader 如果绕过复制协议直接写数据库、对象存储或第三方接口,资源端并不知道 Raft Term 或 ZAB Epoch 已经变化。要真正拒绝迟到写,还需要资源端验证版本号或 Fencing Token。
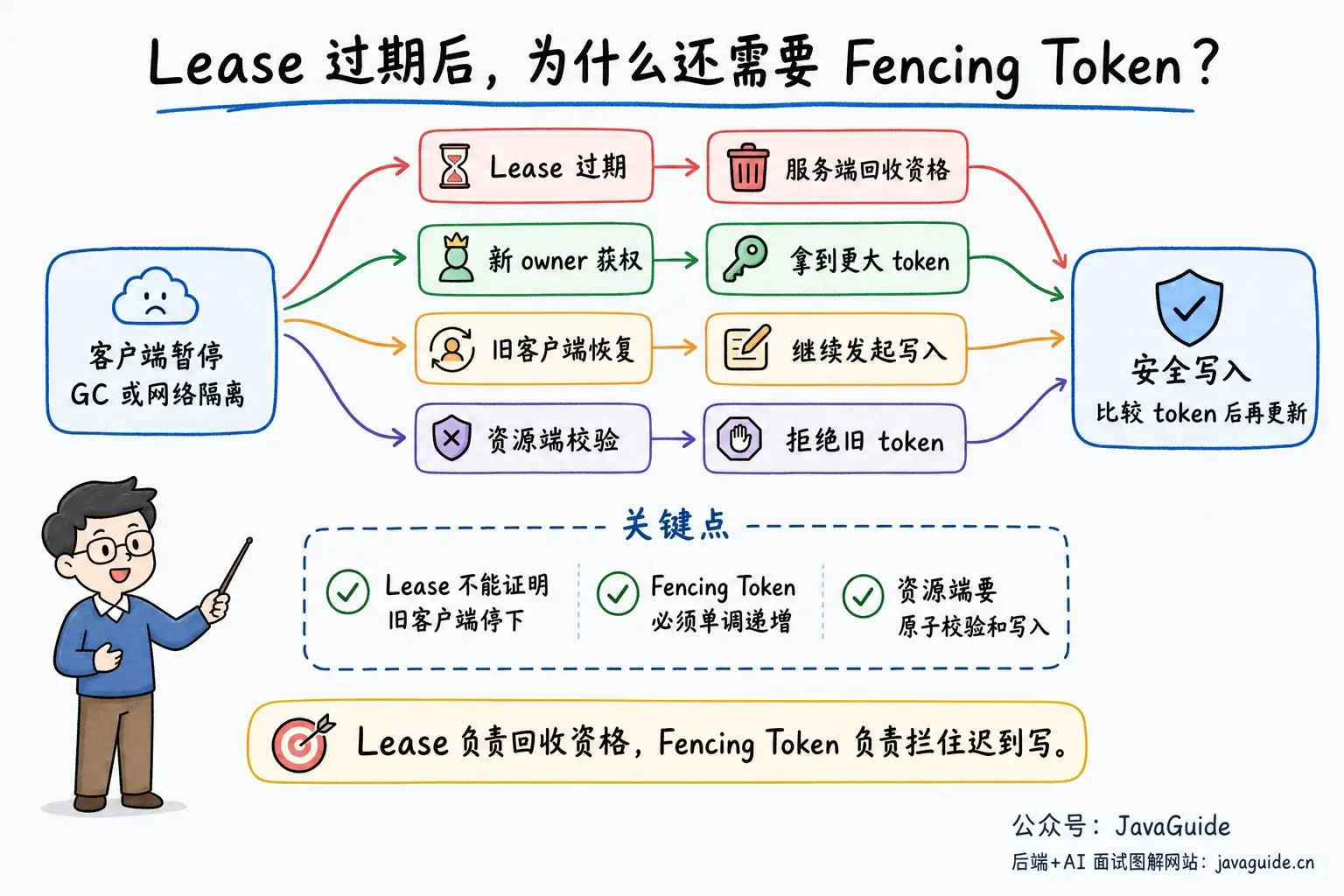
Lease 解决资源回收,不能证明旧客户端已经停下
比如一个客户端拿到了锁,然后发生长时间 GC。锁服务认为它已经失联,把锁交给了另一个客户端。旧客户端恢复后,它可能还拿着旧的执行上下文去写数据库、对象存储或外部接口。锁服务已经换主或换 owner,并不代表旧客户端手里的业务线程立刻消失。
Lease 可以理解为带有效期的授权。客户端拿到 Lease 后,需要在 TTL 内续约;续约失败或 Lease 过期后,协调系统就可以回收相关资源。etcd 的 Lease API 就是这种模型:集群授予带 TTL 的 Lease,如果集群在 TTL 内没有收到 keepAlive,Lease 就会过期,挂在 Lease 上的 Key 也会被删除。etcd 返回的 TTL 以服务端选择和响应为准,并不是客户端自己用本地时钟决定 Lease 是否过期。
真正危险的是客户端对 Lease 状态的认知可能过时。它可能因为长时间 GC、网络隔离或线程阻塞,没有及时发现 Lease 已经过期。
所以 Lease 适合做存活检测和资源自动回收,却不能单独证明旧客户端已经停止执行。只要旧客户端还能访问共享资源,就仍然可能产生迟到写。
Fencing Token 拒绝过期执行者
Fencing Token 的处理方式更直接:每次成功获得权限时,协调系统发一个单调递增的 token。客户端写共享资源时必须带上这个 token,资源端记录见过的最大 token,并拒绝更小 token 的写入。
举个例子:
- 客户端 A 获得锁,拿到 token=10。
- A 发生长时间暂停,锁过期。
- 客户端 B 获得锁,拿到 token=11,并成功写入资源。
- A 恢复后继续带着 token=10 写资源。
- 资源端发现
10 < 11,拒绝 A 的写入。
token 数字本身解决不了问题,资源端校验才是关键。资源端最好原子地完成“比较 token + 更新数据 + 记录最新 token”。如果先查 token、再单独写数据,中间仍可能被并发请求插入。
可以把 Lease、Fencing Token 和幂等键放在一起看:
| 机制 | 解决的问题 | 不能保证什么 |
|---|---|---|
| Lease | 自动回收失联客户端持有的资格 | 旧客户端已经停止运行 |
| Fencing Token | 拒绝旧持有者的迟到写 | 业务操作本身可重试 |
| 幂等键 | 防止同一业务请求重复产生副作用 | 当前执行者一定是最新 owner |
Gossip 状态传播:让节点交换本地视图
Gossip 不依赖一个固定节点维护完整集群视图。每个节点保存自己的本地视图,并通过对等通信交换状态。
节点周期性选择其他节点交换信息,状态像消息扩散一样在集群里传播。一个节点知道了新成员、新故障、新版本,后面会继续告诉其他节点。经过多轮交换后,大部分节点会看到相近的状态。
Gossip 本身更适合传播“我观察到了什么”,不适合单独决定“全体必须接受什么”。
它通常提供最终传播和收敛,不直接提供严格互斥或全局写入顺序。Gossip 传播需要时间,同一时刻不同节点看到的状态可能不同。同一条消息也可能被重复传播,需要版本号、消息 ID、时间戳或其他方式去重。发生网络分区时,不同分区可能各自形成不同判断,恢复后还要靠版本、任期、冲突解决策略收敛。
但这不表示所有无固定 Leader 的协议都只能最终一致。EPaxos 这类无固定 Leader 的共识协议仍然可以提供强一致性,只是实现复杂度和适用场景与常见 Leader-based 协议不同。
真实系统经常混合使用多种机制。Redis Cluster 就是一个典型例子:节点通过 Cluster Bus 和 Gossip 传播成员状态、槽位信息和故障观察;节点可以先把另一个节点标记为 PFAIL;当多数 Master 对故障达成足够观察后,再升级为 FAIL;Replica 晋升还要结合多数投票、currentEpoch 和 configEpoch 区分新旧配置。
所以,Gossip 更适合“状态传播”,不适合单独承担“强互斥”和“严格写入顺序”。如果一个场景要求任意时刻只能有一个 owner,或者写入必须线性一致,还是要引入共识、多数派投票、资源端版本校验或 Fencing Token。
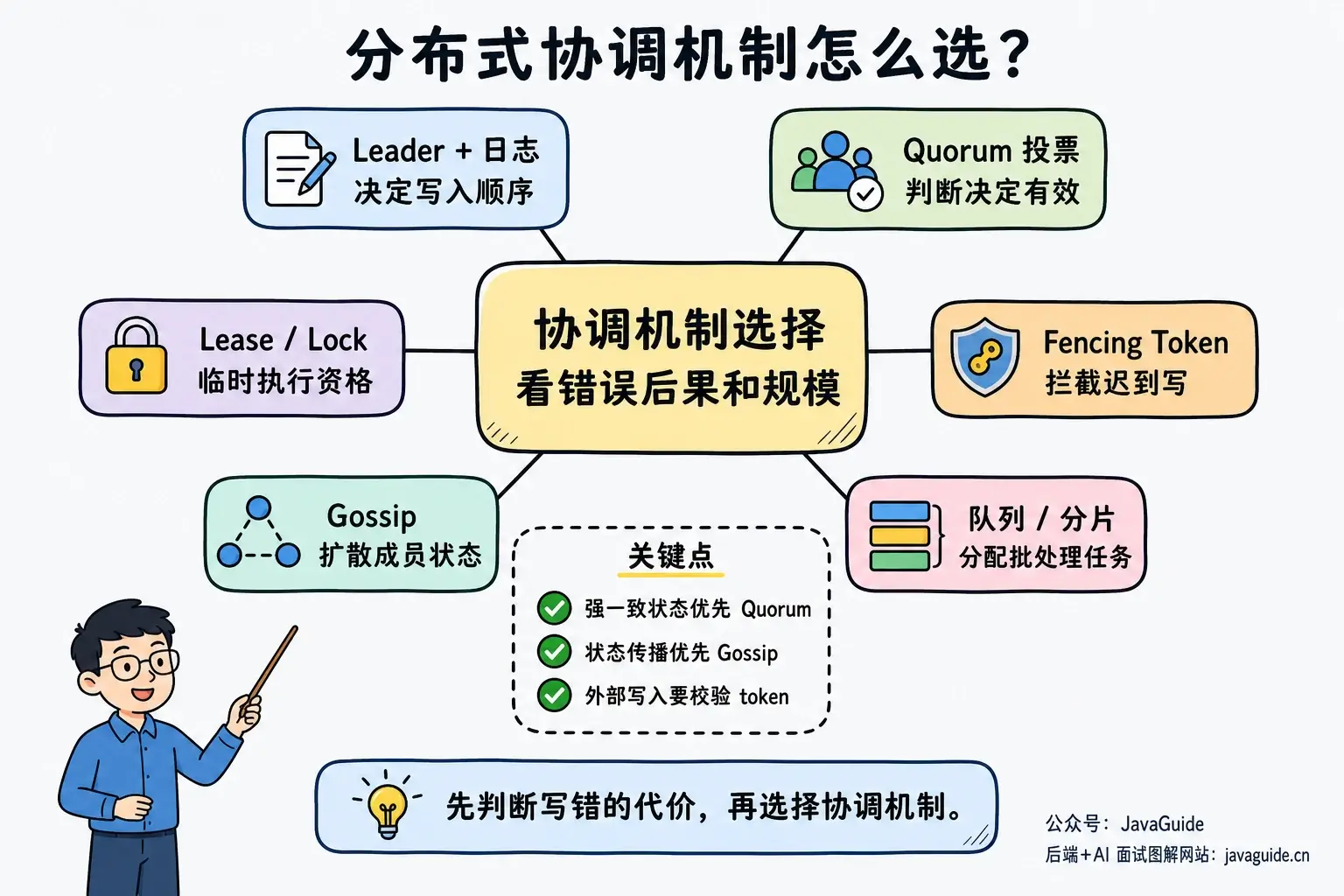
这些机制怎么选?
先看错误决定的后果。
如果重复执行一次任务只是多消耗一些资源,或者某个节点短时间看到旧状态可以接受,那状态传播和最终收敛通常就够了。比如节点发现、健康状态传播、缓存元数据扩散、非关键状态同步,都可以考虑 Gossip 或类似的对等传播方式。
如果错误决定会导致资金错误、库存错误、元数据损坏、两个主节点同时写同一份数据,那就要优先考虑 Leader/Quorum、共识算法、多数派提交,必要时再加 Fencing Token。这里牺牲一点可用性和吞吐,通常比事后修数据便宜。
再看系统规模和写入路径。
小规模控制面用 Leader 管理通常更容易维护。节点数量很大、状态变化频繁、每个节点只需要近似视图时,对等传播更合适。Gossip 的消息会有冗余,但它避免了所有状态更新都汇聚到一个固定节点;同时也会增加冲突处理、消息去重和状态排查成本。
可以用下面这个表快速判断:
| 机制 | 主要解决什么 | 一致性特点 | 典型场景 |
|---|---|---|---|
| Leader + 日志复制 | 决定写入顺序和元数据状态 | 可提供强一致 | 配置发布、主从切换、元数据变更 |
| Quorum 投票 | 判断某个决定是否有效 | 依赖集合交集与协议规则 | 日志提交、Leader 选举、故障确认 |
| Lease / Lock | 临时授予执行资格 | 资格可能过期 | 定时任务、资源 owner、短临界区 |
| Fencing Token | 拒绝旧 owner 的迟到写 | 依赖资源端校验 | 数据库、对象存储、外部资源写入 |
| Gossip | 扩散成员和状态信息 | 通常最终收敛 | 服务发现、健康状态、缓存元数据 |
| 队列 / 分片领取 | 把工作分配给多个 Worker | 通常至少一次 | 批处理、消费任务、分片扫描 |
真实系统经常会混合使用这些机制。
比如控制面用 Leader 和多数派保护元数据,数据面尽量让请求分散;集群成员状态用 Gossip 传播,但真正的主从切换还要经过投票和 Epoch;任务调度可以有中心调度器,也可以让执行器自己触发,但底层仍可能依赖数据库条件更新、ZooKeeper、etcd 或消息队列。
3 个实例的定时任务到底怎么设计?
开头那个凌晨 2 点定时任务,常见方案不止一种。
- 选出一个调度 Leader,由它创建任务。
- 所有实例同时触发,但通过数据库唯一键、条件更新或分布式锁竞争执行权。
- 调度器只产生任务消息,由消费者组领取和分片处理。
- 把任务拆成多个分片,每个实例只处理自己领取的部分。
无论哪种方案,都不应该只依赖“这次一定只有一个实例执行”。更稳的设计通常包含这些东西:
- 调度记录有唯一任务 ID;
- 领取任务使用条件更新、版本号或租约;
- 业务处理具备幂等性;
- 任务支持超时回收和重新领取;
- 涉及外部共享资源时使用 Fencing Token 或资源版本校验;
- 保存执行进度,支持失败后从检查点恢复。
如果任务很短、失败后重跑代价低,数据库唯一键或消息队列通常就够了。如果任务会长时间占用外部资源,或者旧执行者恢复后继续写会造成损坏,就需要引入 Lease、Fencing Token、幂等键和状态机。
面试怎么回答?
面试里如果被问到“分布式系统中的中心化和去中心化有什么区别”,不要一上来就把 Leader 和 Gossip 对立起来。更好的回答顺序是:先说为什么需要协调,再把问题拆成“决策”和“传播”,最后补上脑裂、Lease、Fencing Token 和选型取舍。
可以这样回答:
分布式系统里,多个节点要共同完成一件事,就必须解决成员管理、任务分配、故障切换和写入顺序这些协调问题。
我会先把问题拆成两类:一类是决策问题,比如谁是 Leader、某条日志是否提交、某个资源当前归谁;另一类是传播问题,比如成员状态、故障观察、配置版本怎么扩散到其他节点。
Leader、Quorum 和共识协议主要解决决策问题。Leader 不一定是单点,关键要看它背后有没有日志复制、多副本和多数派选举。为了避免脑裂,通常要用多数派、Term/Epoch、选举限制和日志匹配规则。
Gossip 主要解决状态传播问题。它适合传播成员和健康状态,但不适合单独承担严格互斥或全局写入顺序。真实系统经常混合使用,比如 Gossip 传播故障观察,多数派投票和 Epoch 决定主节点晋升。
如果涉及锁或任务 owner,还要考虑 Lease 和 Fencing Token。Lease 能回收失联客户端的资格,但不能证明旧客户端已经停止运行;Fencing Token 需要资源端校验,才能拒绝旧 owner 的迟到写。业务侧还要用幂等键、唯一约束或状态机处理重复执行。
这个回答已经能覆盖大部分面试场景。如果面试官继续追问,可以按下面几类问题展开。
有 Leader 就一定是单点吗?
不一定。
如果 Leader 的状态只存在自己内存里,挂掉后没有副本接管,那就是单点。很多分布式系统里的 Leader 更像“当前决策者”:它负责接收写请求、推进日志或分配任务,但状态会复制到多个节点。Leader 挂掉后,剩余节点可以基于已有日志和多数派选举出新 Leader。
所以,判断是不是单点,不能只看有没有 Leader,要看 3 件事:
- Leader 状态有没有持久化和多副本;
- Leader 挂掉后能不能自动选出新 Leader;
- 新 Leader 能不能拿到已经提交过的状态。
如何避免脑裂?
脑裂的风险在于多个分区都认为自己有权写入。
常见做法是用多数派和任期控制。只有拿到多数派的节点集合才能选出 Leader 或提交写入。3 个节点至少要 2 个同意,5 个节点至少要 3 个同意。网络分区后,少数派拿不到多数派,就不能继续提交新的协调写入。
任期负责区分新旧 Leader。Raft 里的 Term、ZAB 里的 Epoch 都是类似思路。节点看到更高任期后,要拒绝旧任期的协议请求。这样旧 Leader 即使从网络隔离或长时间暂停中恢复,也不能继续用旧身份推进内部日志。
不过,这主要保护的是协调系统内部状态。业务资源还可能遇到旧客户端恢复后继续写的问题,这时就需要 Fencing Token:每次获得锁或权限时拿到一个递增 token,写资源时带上 token,资源端拒绝更小的旧 token。
Gossip 是不是只能最终一致?
纯 Gossip 状态传播通常只负责信息扩散和最终收敛,不直接提供强互斥和全局写入顺序。
但“无固定 Leader”和“最终一致”不能画等号。也有无固定 Leader 的共识协议可以提供强一致性,只是工程实现更复杂。实际项目里更常见的组合是:Gossip 负责传播成员状态和故障报告,Quorum、Epoch、日志复制或资源端校验负责作出最终决定。
项目里怎么落到选型?
回答项目经验时,不要只说“我们用了 ZooKeeper/Redis/etcd”。更应该把选择理由说出来。
如果是分布式锁、配置变更、主节点切换、分片归属这类场景,可以这样说:
这类状态写错后代价比较高,所以我会优先考虑带多数派和会话/租约语义的协调组件。锁或 owner 过期后,还要考虑旧客户端恢复后的迟到写。如果资源端支持版本校验,会加 Fencing Token 做兜底。
如果是服务发现、节点状态传播、缓存集群状态这类场景,可以这样说:
这类信息允许短时间不一致,更看重扩展性和传播成本。可以接受通过 Gossip 或类似机制逐步收敛,但要处理消息重复、旧状态、网络分区恢复后的版本冲突。
面试回答到这个程度,就已经跳出了“中心化 vs 去中心化”的定义背诵,开始讲分布式系统里最重要的取舍:决策、传播、租约、幂等和故障恢复。
参考
- Kubernetes CronJob
- The Raft Consensus Algorithm
- In Search of an Understandable Consensus Algorithm
- ZooKeeper Internals:Atomic Broadcast、Leader Activation、Quorums
- ZooKeeper Administrator's Guide:Clustered Setup 与多数派部署建议
- Redis Cluster Specification
- etcd API:Lease API
- EPaxos
- How to do distributed locking - Martin Kleppmann
- Epidemic Algorithms for Replicated Database Maintenance
写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。