哈希表面试题总结:哈希冲突、扩容与 Java HashMap
哈希表(Hash Table,也叫散列表)的面试价值很高,因为它一头连着算法题里的快速查找和计数,另一头连着 Java HashMap、缓存、去重和分布式系统里的分片路由。
这个问题问的是:如何把一个 key 快速映射到数组下标,并在冲突、扩容和极端数据下仍然保持可接受的查询效率。
文章内容概览:
- 什么是哈希表?
- 哈希表怎么从 key 定位到数组下标?
- 哈希冲突、负载因子和扩容分别解决什么问题?
- Java
HashMap和普通哈希表有什么关系? - 哈希表在算法题和工程场景中怎么用?
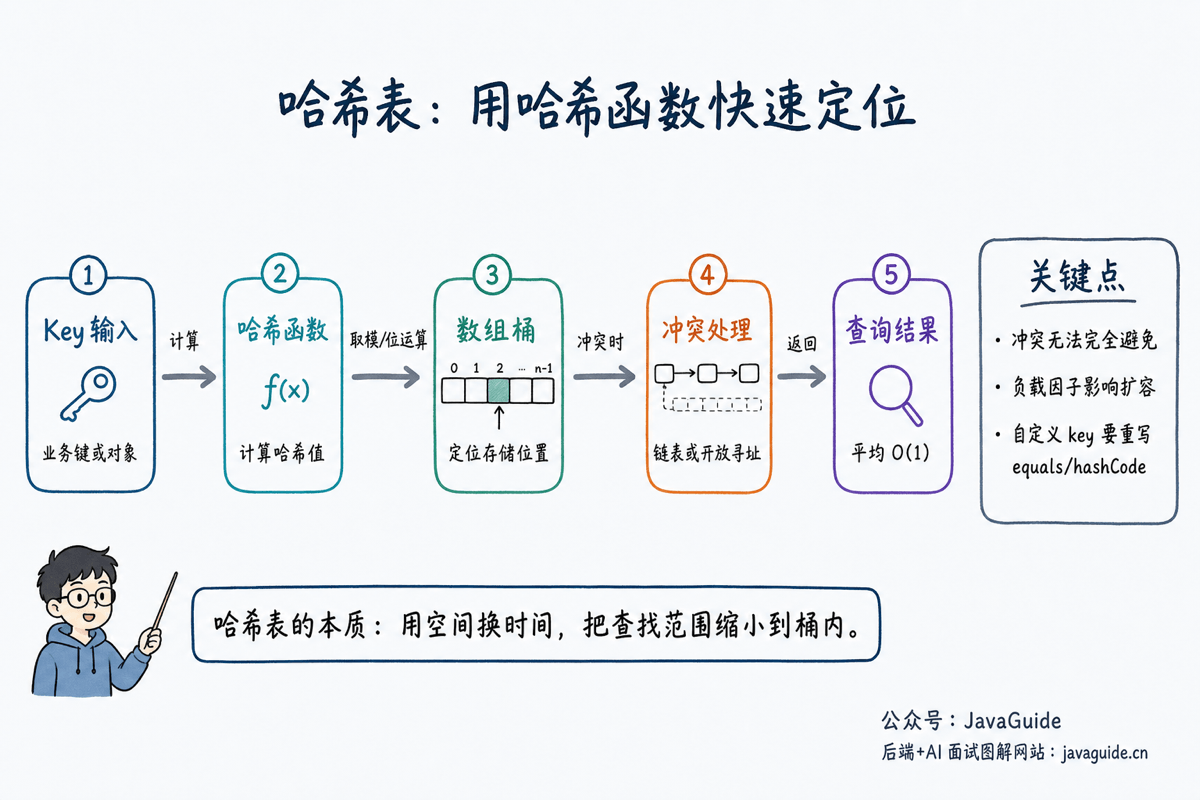
什么是哈希表?
哈希表是一种用来存储 key-value 映射关系的数据结构。我们平时说的 Map、Dictionary、Associative Array,本质上都可以用哈希表来实现。
如果 key 是连续整数,比如学生编号刚好是 0 到 999,直接用数组就能做到 students[id] 这种 O(1) 访问。但真实业务里的 key 通常不是这么规整:可能是字符串、用户 ID、订单号、URL,也可能是自定义对象。哈希表要做的事情,就是先把这些不同类型、不同长度的 key 通过哈希函数转换成一个整数,再把这个整数映射到数组下标。
可以把哈希表拆成三层来看:
- 数组:真正存放数据的位置,也常被称为桶(bucket)。
- 哈希函数:负责把 key 转换成哈希值。
- 冲突解决策略:当多个 key 落到同一个桶时,决定这些 key 怎么继续存。
所以,哈希表不是“完全没有查找过程”,而是通过哈希函数把查找范围大幅缩小:理想情况下,一次定位就能找到目标桶;发生冲突时,再在桶内部做少量比较。
为什么需要哈希表?
假设要判断一个 URL 是否已经爬取过,最直接的方式是把爬过的 URL 放到列表里,每来一个新 URL 就从头扫一遍。数据量很小时问题不大,但如果已经爬了几百万个 URL,每次都线性扫描,性能很快就扛不住。
哈希表的思路是用空间换时间:多开一块数组空间,把 URL 通过哈希函数分散到不同桶里。查询时不再从头遍历所有 URL,而是先计算哈希值,直接跳到对应桶附近查找。
这也是哈希表适合做查找、计数、去重、缓存索引的原因。它不关心元素之间的大小关系,也不保证有序;它关心的是“给定 key,能不能尽快找到对应的 value”。
哈希函数要解决什么问题?
哈希函数的目标不是把 key 变得神秘,而是尽量把 key 均匀地分散到数组里。一个好的哈希函数通常要满足三个要求:
| 要求 | 含义 |
|---|---|
| 稳定 | 同一个 key 多次计算得到的哈希值应该一致 |
| 计算快 | 哈希函数本身不能太慢,否则会抵消哈希表的性能优势 |
| 分布尽量散 | 不同 key 尽量落到不同位置,减少哈希冲突 |
需要注意的是,普通哈希表里的哈希函数和密码学哈希不是一回事。哈希表更关注速度和分布质量;密码学哈希更关注抗碰撞、抗篡改等安全性质。
在 Java 里,自定义对象作为 HashMap 的 key 时,hashCode() 和 equals() 必须配合好:如果两个对象通过 equals() 判断相等,它们的 hashCode() 也必须相同;但两个对象的 hashCode() 相同,不代表它们一定相等。这一点正是哈希冲突会存在的根源之一。
面试考察重点
- 哈希函数负责把 key 映射成数组下标。
- 哈希冲突无法完全避免,只能设计策略处理。
- 哈希表平均查询、插入、删除是
O(1),最坏情况可能退化。 - Java
HashMap使用数组 + 链表 + 红黑树,JDK 8 后链表过长会树化。 - 哈希表常用于快速查找、计数、去重、缓存索引。
哈希表怎么工作?
以插入一个 key-value 为例,哈希表通常会做这几步:
- 对 key 计算哈希值。
- 根据数组长度把哈希值映射成下标。
- 如果该位置为空,直接放入。
- 如果发生冲突,按冲突解决策略继续处理。
int index = hash(key) & (table.length - 1);HashMap 的容量是 2 的幂时,可以用位运算替代取模。位运算更快,也方便扩容后重新分布。
这里的 hash(key) 通常不是直接使用对象原始的 hashCode(),还会做一次扰动,让高位信息也参与到低位下标计算中。原因也很好理解:当数组长度是 2 的幂时,length - 1 的二进制低位全是 1,直接 & 会更依赖哈希值低位。如果低位分布不好,冲突就会更集中。
哈希冲突怎么解决?
| 方法 | 思路 | 典型应用 | 注意点 |
|---|---|---|---|
| 拉链法 | 数组位置上挂链表或树 | Java HashMap | 链表过长会影响查询 |
| 开放寻址法 | 冲突后继续探测下一个位置 | 一些高性能哈希表 | 删除和负载因子处理更复杂 |
| 再哈希 | 冲突后换一个哈希函数 | 理论方案较常见 | 实现成本更高 |
Java HashMap 主要使用拉链法。JDK 8 开始,当链表长度达到阈值并且数组容量足够大时,会把链表转换成红黑树,降低极端冲突下的查询成本。
拉链法的优点是实现直观,删除也比较容易。数组中的每个桶不只放一个元素,而是挂一条链表,冲突的元素追加到这条链上。查询时先通过哈希定位桶,再在桶里的链表或树中比较 key。
开放寻址法则不额外挂链表,所有元素都放在数组内部。发生冲突后,它会按照某种探测规则继续找下一个可用位置,比如线性探测、二次探测、双重哈希。它的好处是内存局部性通常更好,但删除元素、控制负载因子和处理连续聚集会更麻烦。
负载因子和扩容
负载因子表示哈希表使用程度:
负载因子 = 元素数量 / 数组容量HashMap 默认负载因子是 0.75。当元素数量超过 capacity * loadFactor 时触发扩容,容量通常变为原来的 2 倍。
扩容会带来一次 rehash 成本。面试里可以这样回答:哈希表单次插入平均是 O(1),但触发扩容的那次会搬迁元素;从摊还角度看,多次插入仍然可以看作平均 O(1)。
负载因子不能只看“空间利用率”。负载因子越高,数组越满,空间越省,但冲突概率也会上升;负载因子越低,冲突少一些,但会浪费更多桶位。0.75 是 Java HashMap 在时间和空间之间做的一个经验折中。
哈希表为什么平均是 O(1)?
哈希表的 O(1) 说的是平均情况或者期望情况,不是所有输入下的绝对保证。
在哈希函数分布比较均匀、负载因子控制得当时,元素会比较分散,每个桶里的元素数量很少。因此查询时的主要成本就是:计算哈希值、定位数组下标、在桶里做少量比较,这些操作可以看作常数级。
但如果大量 key 落到同一个桶,哈希表就会退化。使用拉链法时,桶内链表太长,查询会接近 O(n);JDK 8 之后的 HashMap 会在满足条件时树化,把极端冲突下的桶内查询成本降到 O(logn) 级别,但这不代表哈希表永远不会受冲突影响。
和 Java HashMap 的关系
HashMap 常见追问:
- 初始容量为什么建议设置成 2 的幂?
- 默认负载因子为什么是
0.75? - JDK 8 为什么引入红黑树?
HashMap为什么线程不安全?HashMap和ConcurrentHashMap有什么区别?
这些问题已经超出纯数据结构,但底层仍然是哈希表:数组负责定位,链表或红黑树负责处理冲突,扩容负责控制负载。
常见算法题模板
两数之和:
int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int need = target - nums[i];
if (map.containsKey(need)) {
return new int[] {map.get(need), i};
}
map.put(nums[i], i);
}
return new int[] {-1, -1};
}这段代码体现了哈希表最常见的用法:用空间换时间,把一次查找从 O(n) 降到平均 O(1)。
代表题精讲:和为 K 的子数组
560. 和为 K 的子数组 很适合用来理解“前缀和 + 哈希表”。题目要求统计连续子数组和等于 k 的个数。
如果只枚举左右端点,复杂度是 O(n^2)。换个角度看,假设当前前缀和是 sum,想找到一个之前的前缀和 prev,使得:
sum - prev = k也就是 prev = sum - k。所以只要用哈希表记录每个前缀和出现过几次,就能在遍历到当前位置时立刻知道有多少个子数组以当前位置结尾、和为 k。
int subarraySum(int[] nums, int k) {
Map<Integer, Integer> count = new HashMap<>();
count.put(0, 1);
int sum = 0;
int ans = 0;
for (int num : nums) {
sum += num;
ans += count.getOrDefault(sum - k, 0);
count.put(sum, count.getOrDefault(sum, 0) + 1);
}
return ans;
}这里 count.put(0, 1) 很重要,它表示空前缀出现过一次。这样当从数组开头到当前位置的和刚好等于 k 时,也能被统计到。
另一个易错点是“先查再加”。如果先把当前 sum 加进哈希表,再查 sum - k,在 k = 0 时可能把当前前缀自己算进去,导致答案偏大。
比如 nums = [1]、k = 0。正确的“先查再加”不会找到和为 0 的非空子数组;如果先把当前前缀和 1 加进去,再查 sum - k = 1,就会把当前前缀和自己配对,错误地多算 1 次。
Java HashMap 面试追问
哈希表文章只讲概念还不够,Java 后端面试里经常会继续追问 HashMap。可以按下面的层次准备:
| 追问 | 回答重点 |
|---|---|
| 为什么容量通常是 2 的幂? | 方便用 hash & (length - 1) 定位,同时扩容后元素迁移更容易 |
为什么默认负载因子是 0.75? | 在空间利用率和冲突概率之间取折中,太小浪费空间,太大冲突增多 |
| 为什么 JDK 8 引入红黑树? | 极端冲突时链表查询会退化,树化后能把查询成本从链表长度级别降下来 |
为什么 HashMap 线程不安全? | 多线程并发修改会破坏结构一致性,读写也没有可见性和互斥保证 |
| 自定义 key 要注意什么? | equals() 和 hashCode() 要一致,参与计算的字段不要在放入后再被修改 |
面试里不用把源码细节全部背下来,但要讲清楚一条主线:数组定位、冲突处理、扩容迁移、极端冲突优化,这四件事共同决定了 HashMap 的性能表现。
易错点
- 哈希表平均
O(1)不等于任何情况下都是O(1)。 - 自定义对象作为 key 时,要正确重写
equals()和hashCode()。 - 可变对象不适合直接作为哈希表 key。
- 统计频率时,数组计数比
HashMap更适合字符集很小的场景。 - 哈希表能加速查找,但会带来额外空间。
高频问题自测
- 哈希表为什么平均查询是
O(1)?什么情况下会退化? - 拉链法和开放寻址法有什么区别?
HashMap为什么需要扩容?扩容成本怎么理解?- 为什么自定义对象作为 key 时要同时重写
equals()和hashCode()? - 前缀和 + 哈希表为什么要“先查再加”?
推荐练习题
参考资料
- Algorithms, 4th Edition:Hash Tables
- Java SE 21 API:HashMap
- OpenJDK:HashMap 源码
- Java SE 21 API:Object#hashCode
写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。