Trie 前缀树面试题总结:字典树原理、前缀匹配与 Java 实现
Trie,也叫前缀树或字典树,适合处理大量字符串的前缀匹配问题。搜索提示、词典查询、敏感词过滤、路由前缀匹配,都能看到它的影子。
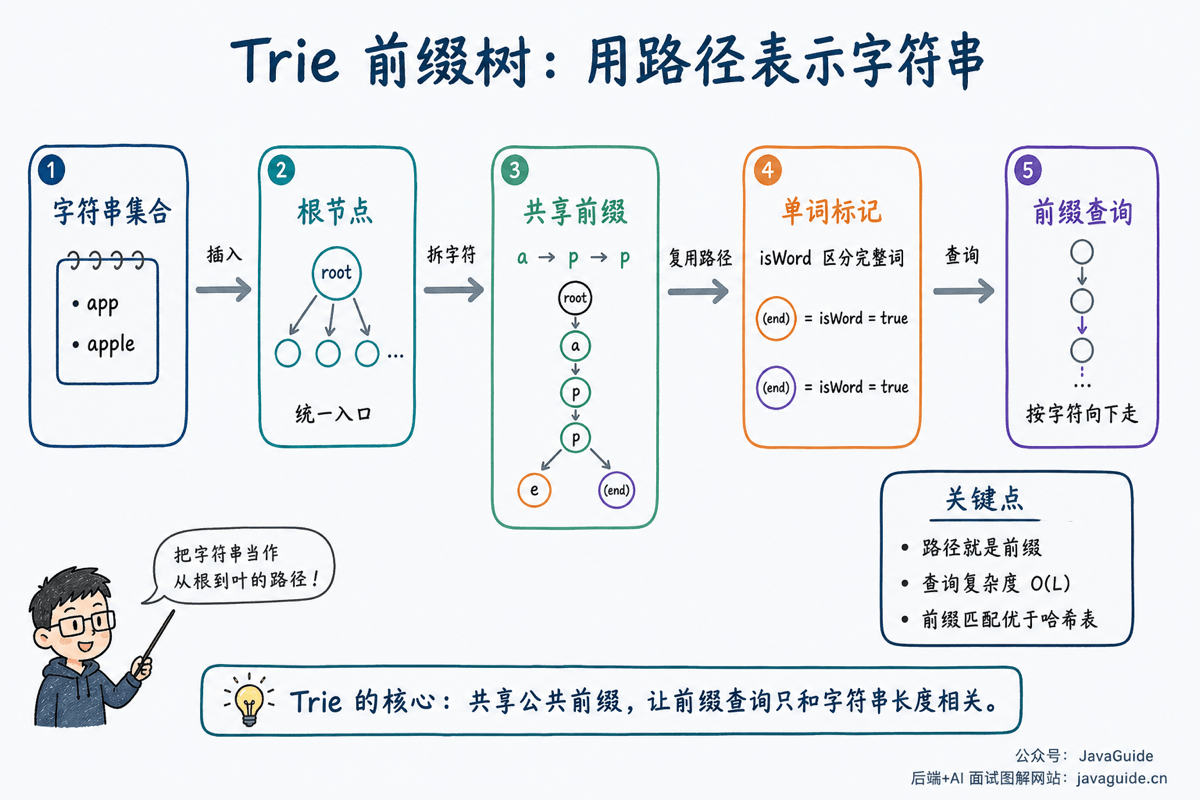
它的核心思路很直接:把字符串按字符拆开,共享相同前缀。比如 app、apple、apply 会共用 a -> p -> p 这条路径。
文章内容概览:
- 什么是 Trie?
- Trie 为什么适合前缀匹配?
- Trie 节点怎么设计?
- Trie 的插入、查询和前缀查询怎么写?
- Trie 和哈希表应该怎么选?
什么是 Trie?
Trie 是一种专门面向字符串集合的数据结构。和二叉搜索树不同,Trie 的节点通常不靠“大小关系”组织,而是靠“字符路径”组织。
可以这样理解:
- 根节点不代表任何字符,只是所有字符串的入口。
- 从根节点出发,每向下一层走一步,就匹配字符串中的一个字符。
- 从根节点到某个节点经过的字符连起来,就是一个前缀。
- 如果某个节点被标记为单词结尾,说明从根到这个节点形成的字符串是一个完整单词。
举个例子,插入 app、apple、apply 之后,它们会共享 a -> p -> p 这段路径。app 对应的最后一个 p 节点需要标记为单词结尾,否则 Trie 只能知道 app 是某些单词的前缀,不能知道它本身也是一个完整单词。
这就是 isWord 变量存在的意义。没有它,就无法区分“这个路径只是前缀”还是“这个路径已经构成一个词”。
Trie 为什么适合前缀匹配?
哈希表很适合判断一个完整字符串是否存在,比如查询 apple 在不在集合里。但如果问题变成“找出所有以 app 开头的词”,哈希表就不那么顺手了:除非额外维护前缀索引,否则需要扫描大量 key。
Trie 的优势在于,前缀天然对应树上的一条路径。查询 app 前缀时,只需要从根节点依次走 a、p、p:
- 如果中途某个字符路径不存在,说明没有任何单词以
app为前缀。 - 如果能走到最后一个
p,说明这个节点下面的所有单词都以app开头。
所以,Trie 的前缀查询复杂度主要和前缀长度有关,而不是和词典中有多少个单词直接相关。这个特点在搜索提示、路由最长前缀匹配、词典过滤这类场景里很有用。
面试考察重点
- 能说清 Trie 为什么适合前缀查询。
- 能写插入、完整单词查询、前缀查询。
- 能分析时间复杂度和字符串长度有关。
- 能说明 Trie 的空间开销可能比较大。
- 能和哈希表做对比。
节点结构
Trie 节点通常包含两类信息:
- 指向子节点的引用,用来继续匹配下一个字符。
- 是否为完整单词结尾的标记。
如果只处理小写英文字母,可以用长度为 26 的数组:
class TrieNode {
TrieNode[] children = new TrieNode[26];
boolean isWord;
}如果字符集不固定,可以用 Map<Character, TrieNode>,空间更灵活,但每次访问有哈希表成本。
这两种写法没有绝对好坏:
| 节点实现方式 | 优点 | 缺点 |
|---|---|---|
TrieNode[] children = new TrieNode[26] | 访问快,适合固定小字符集 | 空节点多时比较浪费空间 |
Map<Character, TrieNode> | 只存实际出现的字符,更灵活 | 有额外对象和哈希访问成本 |
面试手写代码时,如果题目明确只有小写英文字母,用数组最清楚;如果字符集包含大小写、中文、路径片段或任意字符,用 Map 更稳妥。
基础实现
下面这个模板假设字符串只包含小写英文字母:
class Trie {
private final TrieNode root = new TrieNode();
public void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int index = c - 'a';
if (node.children[index] == null) {
node.children[index] = new TrieNode();
}
node = node.children[index];
}
node.isWord = true;
}
public boolean search(String word) {
TrieNode node = find(word);
return node != null && node.isWord;
}
public boolean startsWith(String prefix) {
return find(prefix) != null;
}
private TrieNode find(String text) {
TrieNode node = root;
for (char c : text.toCharArray()) {
int index = c - 'a';
if (node.children[index] == null) {
return null;
}
node = node.children[index];
}
return node;
}
}插入和查询的逻辑其实是同一条主线:从根节点开始,按字符一层一层往下走。插入时如果路径不存在就创建节点;查询时如果路径不存在就返回 false。区别只在最后一步:search() 要检查 isWord,startsWith() 只要能走完整个前缀即可。
删除操作怎么理解?
Trie 的删除比插入和查询更容易写错,因为删除一个单词时不能简单地把整条路径都删掉。
比如 Trie 里同时有 app 和 apple,删除 app 时,只能取消 app 最后一个 p 节点上的 isWord 标记,不能把 a -> p -> p 这条路径删掉,否则 apple 也会被破坏。
真正删除节点时,需要从单词末尾往回看:如果某个节点没有子节点,并且也不是其他单词的结尾,才可以被删除。面试中如果没有明确要求删除,一般先把插入、完整查询、前缀查询写稳。
复杂度
设字符串长度为 L:
- 插入:
O(L) - 查询完整单词:
O(L) - 查询前缀:
O(L)
空间复杂度取决于节点数量。最坏情况下,如果字符串几乎没有公共前缀,空间开销会接近所有字符数量之和。
如果还要枚举某个前缀下的所有单词,复杂度就不只是 O(L) 了。定位前缀节点需要 O(L),后面还要遍历这个节点下面的子树,额外成本和返回结果数量、子树规模有关。
Trie 和哈希表怎么选?
| 场景 | Trie | 哈希表 |
|---|---|---|
| 完整字符串查询 | 可以做,但空间更大 | 更直接 |
| 前缀查询 | 很适合 | 需要额外处理 |
| 按前缀枚举所有词 | 很适合 | 不方便 |
| 字符集很大 | 需要优化节点结构 | 更省心 |
如果只是判断一个词是否存在,哈希表通常更简单。如果要频繁查前缀,Trie 更合适。
还有一个容易忽略的差异:哈希表的完整匹配通常更省空间、更通用;Trie 则把公共前缀显式存成路径,因此能自然支持前缀查询、按前缀枚举、最长前缀匹配。二者解决的问题重心不同,不是谁完全替代谁。
工程场景
- 搜索框自动补全:根据用户输入前缀找到候选词。
- 敏感词匹配:Trie 可以配合 AC 自动机做多模式匹配。
- IP 路由匹配:最长前缀匹配可以借鉴 Trie 思路。
- 词典校验:快速判断单词或前缀是否存在。
实际工程中还会看到一些 Trie 的变体:
- 压缩 Trie / Radix Tree:把只有一个子节点的连续路径压缩成一段字符串,减少节点数量。
- Ternary Search Trie(三向单词查找树):每个节点通过小于、等于、大于三个方向组织字符,在空间和查询灵活性之间做折中。
- AC 自动机:在 Trie 的基础上增加失败指针,用来做多模式字符串匹配。
这些变体不需要一开始就全背下来,但要知道 Trie 的基础思想是它们的共同起点:用路径表示字符串,用共享路径复用公共前缀。
易错点
isWord不能省,否则无法区分app和apple。- 字符集不一定只有小写字母,面试时要根据题目调整。
- 删除单词比插入查询复杂,需要判断节点是否还能被其他单词复用。
- Trie 查询复杂度和字符串长度有关,不直接和词典大小成正比。
推荐练习题
参考资料
- Algorithms, 4th Edition:Tries
- Algorithms, 4th Edition:TrieST API
- Stanford CS166:Tries and Suffix Trees
写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。