操作系统内存管理详解:分页、分段、页面置换、Swap 与 OOM
打开一个普通进程的内存信息,你会看到很多看起来反直觉的数字:进程有自己的虚拟地址空间,地址范围可能很大;真正占用的物理内存又是另一回事;同一个动态库还可能被多个进程共享。
程序写代码时只是在访问地址,操作系统看到的却是一堆更具体的问题:这块内存给谁?能不能让别的进程碰?物理内存不够时换谁出去?释放之后留下的空洞还能不能继续用?
这就是内存管理要处理的事。小 G 建议不要一上来就背分页、分段、TLB 这些名词,先抓住一条线:操作系统把程序看到的地址和真实物理内存隔开,再用分配、映射、保护和回收把内存管起来。
VSZ、RSS 和 PSS 分别代表什么?
Linux 里最容易看错的是进程内存数字。ps 里的 VSZ、/proc/<pid>/status 里的 VmSize,表示进程已经映射的虚拟地址空间大小。它可能包含尚未真正驻留的匿名映射、文件映射、共享库和预留地址,不能直接当成物理内存占用。
RSS 表示当前驻留在 RAM 中、并映射给该进程的页面总量。共享库、共享内存、Page Cache 中的共享页也会算进每个相关进程的 RSS,所以把多个进程 RSS 直接相加容易重复计算。
PSS 更适合估算进程的实际分摊占用。一个物理页如果被 4 个进程共享,每个进程的 PSS 只算四分之一。需要看汇总时可以用:
grep -E 'VmSize|VmRSS|RssAnon|RssFile|RssShmem|VmSwap' /proc/<pid>/status
cat /proc/<pid>/smaps_rollupsmaps_rollup 会给出进程级汇总;要分析每段映射,再看 /proc/<pid>/smaps。不过完整 smaps 会遍历进程的 VMA 和页表,线上高频采集要谨慎。
内存管理主要负责什么?
从操作系统视角看,内存管理至少要做 5 件事。
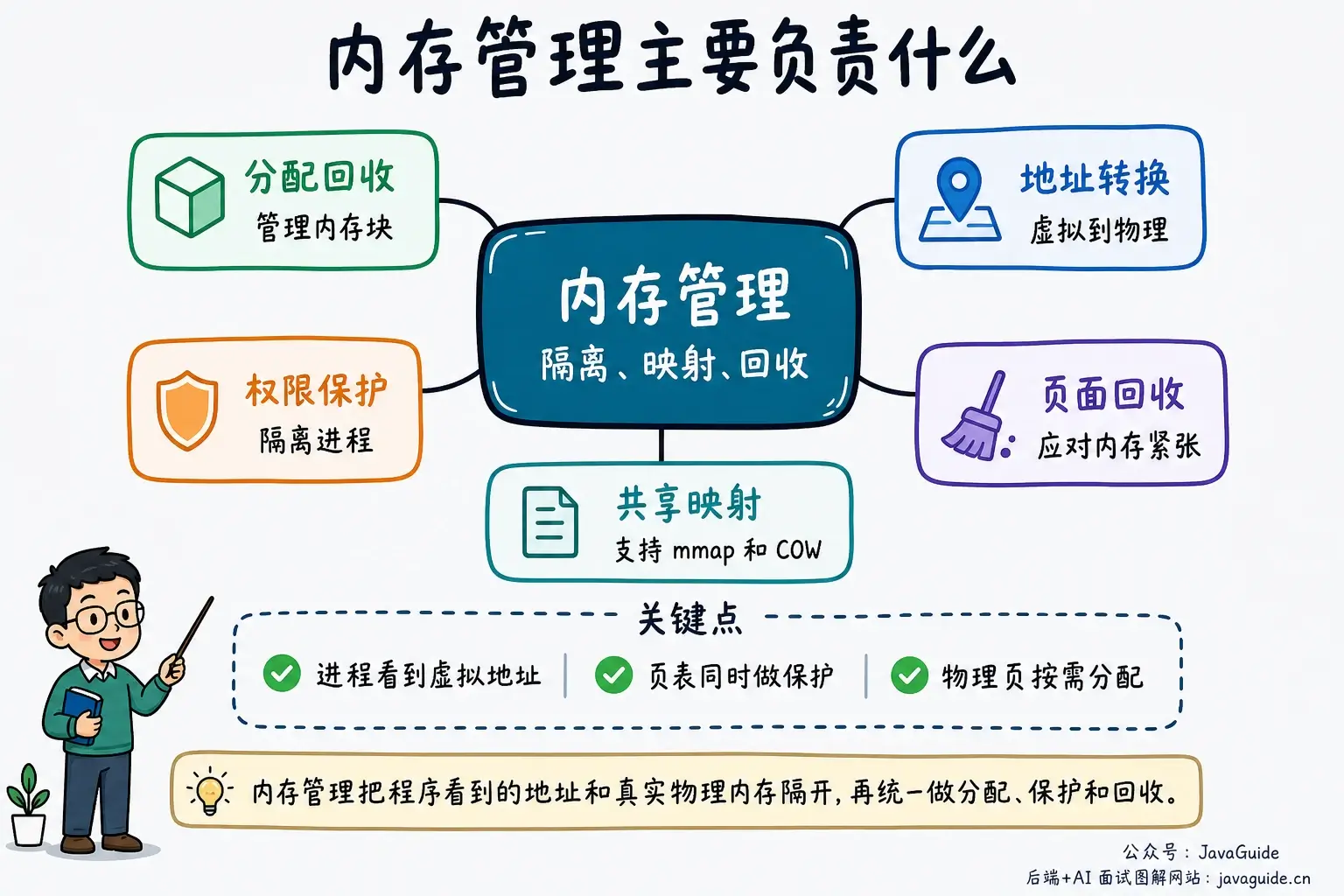
第一,分配和回收内存。 用户态的 malloc()/free() 负责管理进程堆里的内存块。以 glibc 为例,分配器必要时会通过 brk()、mmap() 等接口扩展可用虚拟地址区域;虚拟区域建好后,物理页通常还要等首次访问时通过缺页路径建立。内核内部则通过页分配器和 SLAB/SLUB 这类对象分配器管理物理页与内核对象。
第二,完成地址转换。 程序访问的是虚拟地址,真正落到内存条上的是物理地址。CPU 里的 MMU 会配合页表、TLB,把虚拟地址翻译成物理地址。
第三,做进程隔离和权限控制。 每个进程都有自己的地址空间。A 进程里的 0x1000 和 B 进程里的 0x1000 可以映射到完全不同的物理页;页表项还能标记可读、可写、可执行,越权访问会触发异常。
第四,在物理内存紧张时回收页面。 干净的文件页可以直接丢弃,需要时再从文件读取;脏文件页通常要先回写;匿名页如果要回收,通常需要写入 Swap。Linux 会结合页面冷热、refault、内存水位、cgroup 和 swappiness 等因素选择回收对象,不是固定先回收某一种页面。
第五,支持共享和映射。 动态库共享、共享内存 IPC、mmap() 文件映射、写时复制(COW),都依赖“多个虚拟地址映射到同一批物理页”这个能力。
没有内存抽象会怎样?
早期或很小的系统里,程序可以直接访问物理地址。单个程序运行时,这种方式还能凑合;一旦多个程序同时运行,问题马上出现。
假设程序 A 往物理地址 1000 写数据,程序 B 也把自己的变量放在物理地址 1000。两个程序互相不知道对方存在,最后谁后写,谁就覆盖前者。更糟的是,普通用户程序也可能写到操作系统自己的内存,系统稳定性没法保证。
解决办法是引入地址空间(Address Space)。每个进程看到一套自己的地址,里面通常有代码段、数据段、堆、栈、内存映射区等。进程只和虚拟地址打交道,真实物理页由操作系统和硬件共同决定。
这样一来,进程隔离、按需加载、共享内存、COW 才有落脚点。
连续内存分配和碎片问题
最容易理解的内存分配方式是连续分配:一个进程需要多少内存,操作系统就找一整块连续物理内存给它。早期系统常用固定分区或动态分区管理。
连续分配的问题是碎片。
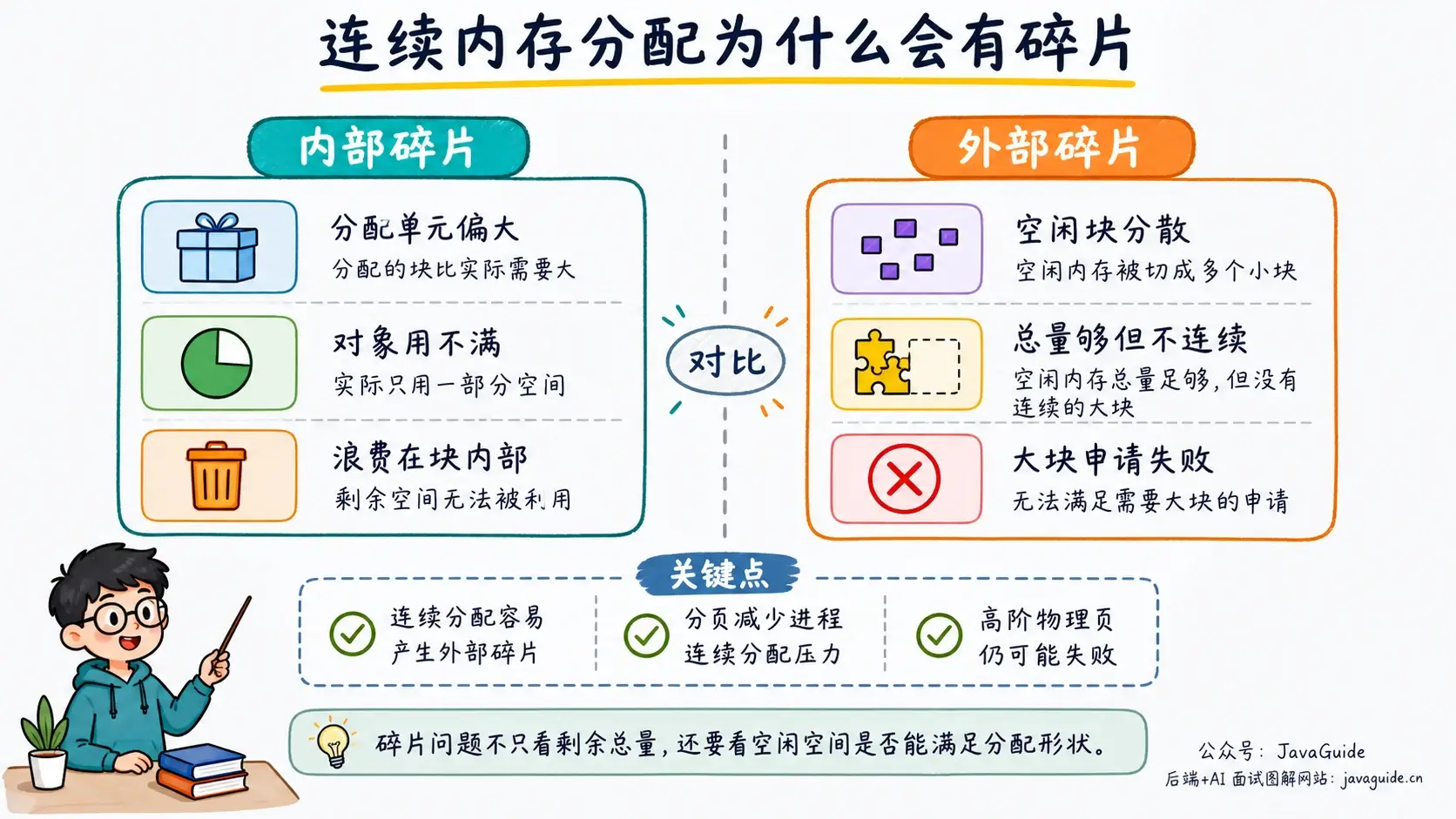
内部碎片指已经分配出去、但实际没用上的空间。比如系统按 128 字节为单位分配,一个对象只需要 65 字节,剩下 63 字节就浪费在这个分配单元内部。
外部碎片指空闲空间总量够,但不连续,没法满足新的大块连续分配。比如内存里有两块空闲区,每块 128 MB,总共 256 MB;现在要申请一块连续 200 MB 空间,仍然失败。
动态分区常见的分配策略有首次适应、最佳适应、最坏适应等。它们能改变碎片出现的位置和速度,但不能从根上消除外部碎片。内存紧凑会迁移可移动页面,把分散的空闲页聚合成更大的连续物理区域。它不等同于 Swap I/O,但同步紧凑可能占用 CPU、迁移大量页面并造成延迟尖峰。
Linux 的伙伴系统解决了什么?
Linux 管理物理页时使用伙伴系统(Buddy System)。它把空闲内存按 2 的幂次组织,比如 4 KB、8 KB、16 KB、32 KB……申请内存时,先找能满足请求的最小块;如果找到的块太大,就不断一分为二;释放时,如果相邻伙伴块也空闲,就合并成更大的块。
这个设计的好处是分裂和合并规则很简单,能较快找到连续物理页,也能减少外部碎片。
不过它也会浪费一些空间:伙伴系统的分配单位是 2^order 个连续物理页。以 4 KB 基础页为例,如果内核调用方需要至少 65 KB 的连续物理内存,就可能申请 32 页,也就是 128 KB 的 order-5 块,从而产生内部浪费。这个例子描述的是内核连续物理页申请,不代表用户调用 malloc(65KB) 就一定直接占用一块 128 KB 的 buddy block。
另外,伙伴系统主要按页管理物理内存。内核里还有大量比页小的对象,例如文件对象、inode、网络缓冲结构。如果每次都按页申请,会浪费太多。Linux 会在伙伴系统之上使用 SLAB/SLUB 这类分配器,按对象大小缓存和复用内存块,减少频繁分配、初始化和释放的成本。
分段、分页和段页式有什么区别?
地址空间不一定只能按一种方式拆。操作系统教材里常见三种:分段、分页、段页式。
| 方式 | 划分依据 | 地址结构 | 优点 | 主要问题 |
|---|---|---|---|---|
| 分段 | 按程序逻辑划分,如代码段、数据段、栈段 | 段号 + 段内偏移 | 贴近程序结构,便于共享和保护 | 段长不固定,容易产生外部碎片 |
| 分页 | 固定大小切分虚拟地址和物理内存 | 页号 + 页内偏移 | 物理内存可离散分配,减少进程连续分配导致的外部碎片 | 页表占空间,最后一页可能有内部碎片 |
| 段页式 | 先按逻辑分段,再把段切成页 | 段号 + 段内页号 + 页内偏移 | 兼顾逻辑保护和离散分配 | 地址转换更复杂 |
现代通用操作系统主要依赖分页管理内存。以 x86 为例,硬件历史上支持分段和分页;在 x86-64 长模式下,Linux 的普通用户地址空间主要依赖分页,传统代码段和数据段基本采用平坦模型。不过 FS/GS 仍然有实际用途,例如 FS 常用于用户态线程本地存储(TLS)。
还要补一个容易被教材简化掉的点:分页减少的是进程地址空间连续分配带来的外部碎片,并没有让物理内存自身的碎片问题消失。DMA、大页和部分内核申请仍可能需要连续物理页,所以空闲内存总量够,高阶连续页申请也可能失败,内核还需要伙伴合并和内存紧凑。
分页是怎么完成地址转换的?
分页把虚拟地址空间切成固定大小的虚拟页,把物理内存切成同样大小的页帧。常见 Linux x86-64 系统一页通常是 4 KB,但具体页大小和架构有关。
一个虚拟地址可以拆成两部分:
- 虚拟页号:用来查页表,找到对应物理页帧。
- 页内偏移:页内的具体位置。
地址转换大致是:CPU 发出虚拟地址,MMU 取出虚拟页号查页表,得到物理页帧号,再拼上页内偏移,得到物理地址。
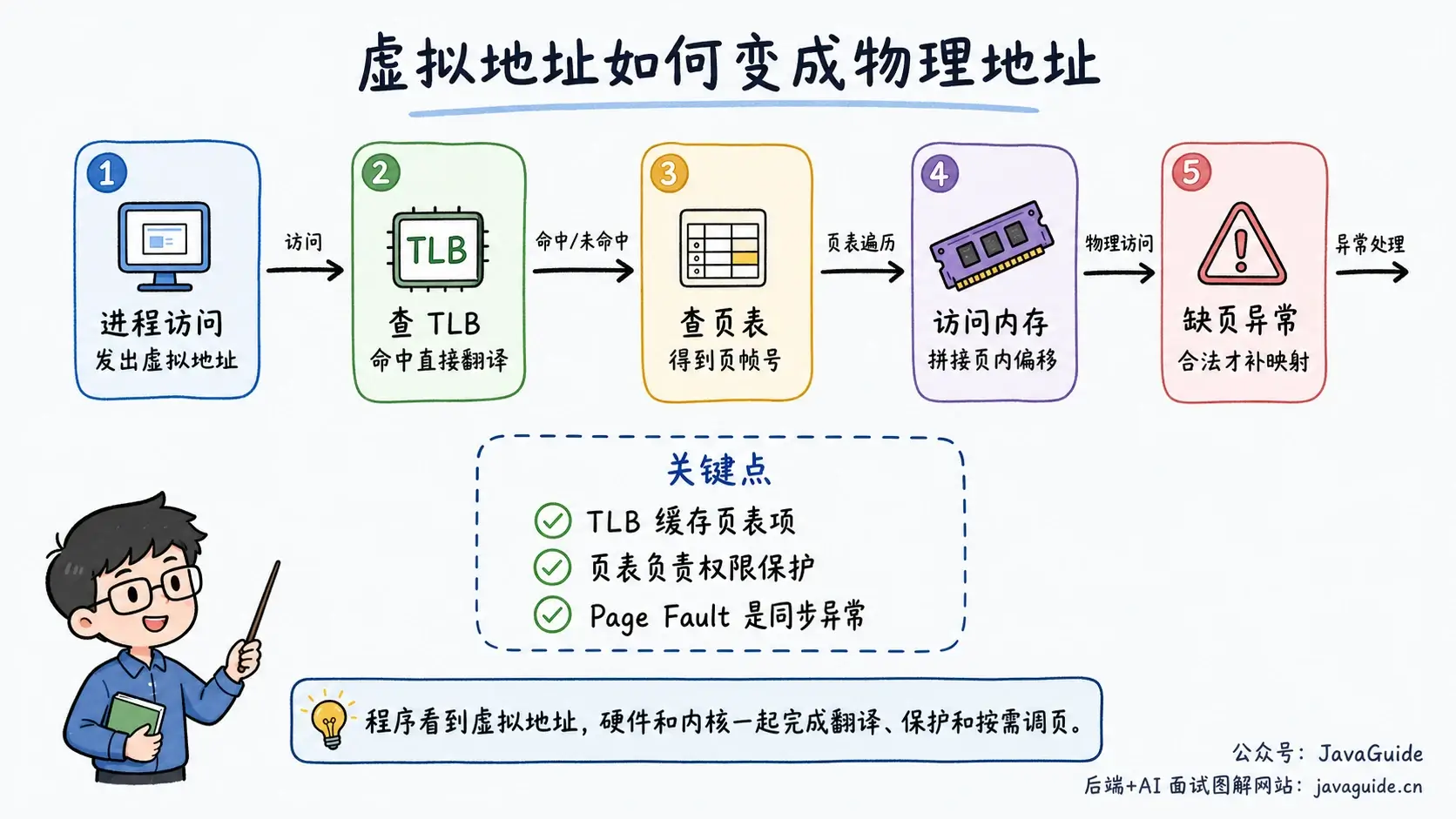
页表项不只保存物理页帧号,还会保存很多状态位,例如 present 位、读写权限、用户/内核权限、脏位、访问位等。present 位表示页面是否已经在物理内存里;权限位用于保护;访问位和脏位会参与页面回收判断。
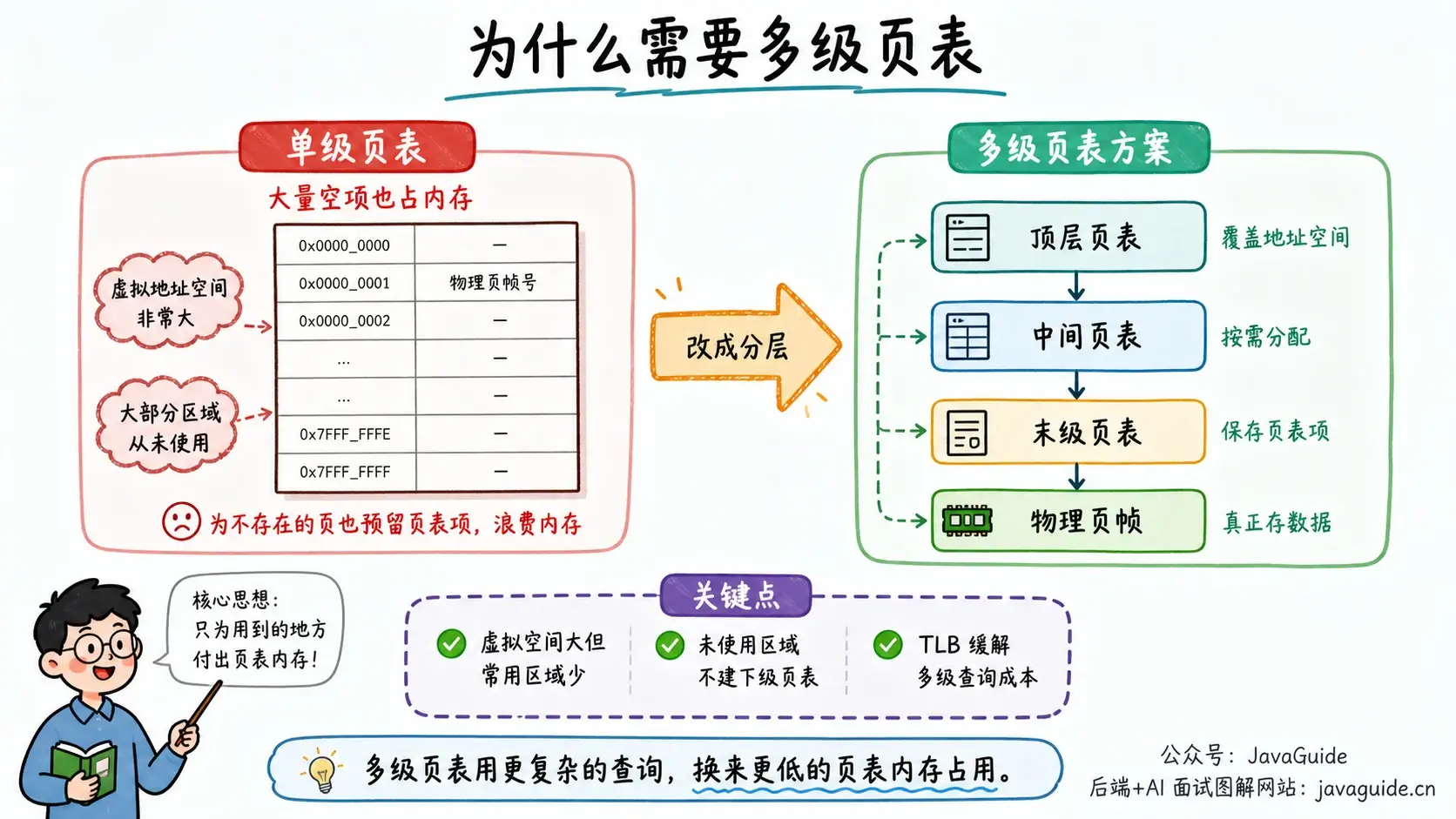
为什么需要多级页表?
单级页表很好理解,但空间开销太大。
以 32 位地址空间、4 KB 页大小为例,一个进程有 4 GB 虚拟地址空间,需要 4 GB / 4 KB = 2^20 个页表项。如果每个页表项 4 字节,单个进程的页表就要约 4 MB。进程多起来后,这部分内存不能忽略。
更麻烦的是,大多数进程不会用满整个虚拟地址空间。单级页表却要为整片空间准备页表项,大量条目都是空的。
多级页表的做法是分层:顶层页表覆盖整片虚拟地址空间,下级页表按需创建。某段虚拟地址根本没用到,就不创建对应下级页表。Linux 的架构无关页表代码按照 5 层层级编写;如果具体架构或机器没有使用全部层级,多余层会被折叠。
在 x86-64 上,传统配置通常使用 4 级分页;CPU、内核和配置支持 LA57 后才会使用 5 级分页。Linux 文档说明,5 级分页可启用 56 位用户态虚拟地址空间,但为了兼容部分会使用指针高位的程序,内核默认不会主动在 47 位以上分配虚拟地址,除非应用通过高位 hint 地址显式请求。
TLB 为什么重要?
多级页表省了空间,却让地址转换多走了几次内存访问。每次访问数据前都完整查多级页表,成本太高。
TLB(Translation Lookaside Buffer,快表)就是页表项缓存,通常在 MMU 里。CPU 访问内存时先查 TLB:
- 命中:直接得到物理页帧号。
- 未命中:再去走多级页表,查到后把结果放回 TLB。
程序访问内存有局部性:刚访问过的页,接下来大概率还会访问;访问某个地址,附近地址也可能很快被访问。TLB 正是吃这份局部性红利。
这也是大页有价值的原因之一。普通 4 KB 页下,一个 TLB 项只能覆盖 4 KB;如果使用 2 MB 大页,一个 TLB 项能覆盖更大的地址范围,TLB miss 可能减少。不过大页也会带来更大的分配和回收成本,数据库、JVM 这类程序是否启用 THP 或 HugeTLB,要按延迟和吞吐目标验证。
缺页异常(Page Fault)是怎么回事?
虚拟内存不是进程一启动就把所有页面装进物理内存。很多页面只有第一次访问时才真正加载,这叫按需调页。
Page Fault 是当前指令同步触发的处理器异常,不是外部设备异步产生的硬件中断。
当进程访问某个虚拟页,MMU 找不到有效翻译,就会触发缺页异常并进入内核处理。内核先判断访问是否落在合法 VMA 中,以及访问权限是否允许。非法地址或权限违规通常会转化为 SIGSEGV;合法缺页则根据映射类型处理:可能映射已有 Page Cache 页面、建立匿名零页、执行 COW、分配新页,或者从文件和 Swap 读取数据。处理完成后更新页表,再重新执行刚才那条指令。
Linux 的 getrusage(2) 把缺页统计分成两类:
- 次缺页(minor fault):处理时不需要实际 I/O。例如页面已经在内存里,只是当前进程还没建立映射;COW 触发复制也常见于这类路径。
- 主缺页(major fault):处理时需要 I/O,例如要从磁盘文件或 Swap 读入页面。
主缺页比次缺页慢得多。线上排查内存问题时,majflt 增长很快通常比 minflt 更值得警惕。
页面置换:内存不够时换谁出去?
物理内存满了,还要装入新页,就必须先回收一批页。页面置换要解决的问题很直接:内存不够时,先把哪一页换出去,才能尽量少影响后面的访问。
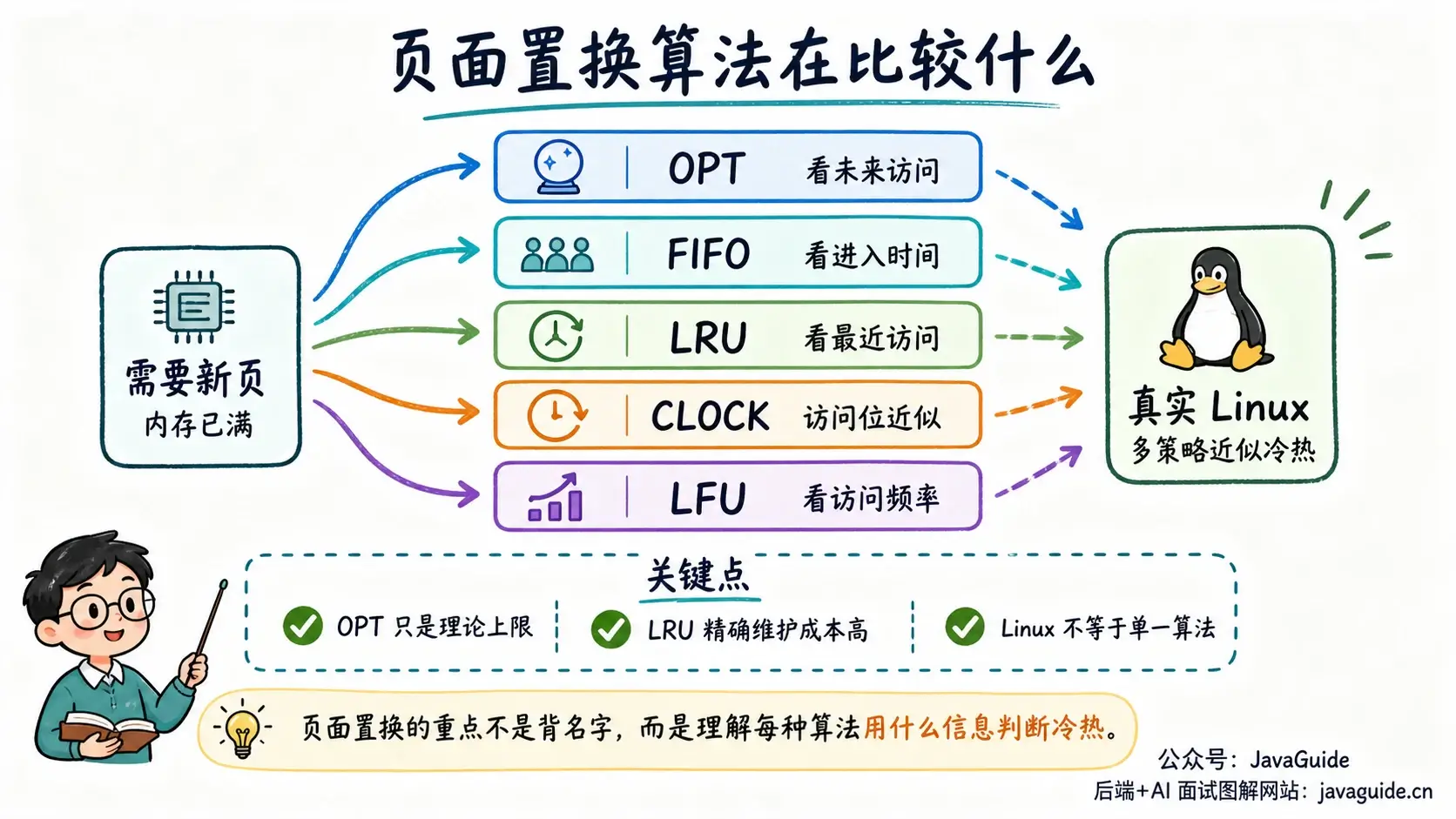
最理想的是 OPT:直接换出未来最长时间不会再访问的页。它只能当理论上限,因为操作系统没法预知未来。FIFO 更容易实现,谁先进内存谁先出去,但它不关心页面是否还热,甚至会出现 Belady 异常:分配更多页框,缺页次数反而可能增加。
LRU 的直觉更接近真实程序:最近一直没访问的页,以后大概率也没那么快用到。问题在实现成本,精确维护每个页的访问顺序太贵。CLOCK 就是在这个背景下出现的折中方案,它用访问位和环形队列给页面一次“第二次机会”,用较低成本近似 LRU。LFU 走的是另一条路,按访问频率淘汰,但如果没有衰减机制,早期热点页可能长期占着位置,后面已经不用了也不容易被踢出去。
真实 Linux 不会照搬某个教科书算法。经典回收路径会使用文件页/匿名页、活跃/非活跃 LRU、workingset 和 refault 等机制近似识别冷热页面;较新的内核还可能启用 Multi-Gen LRU,用多个访问代际表示页面新旧程度。文件页、匿名页、cgroup、NUMA、内存水位都会影响回收路径,具体算法还取决于内核版本和配置。
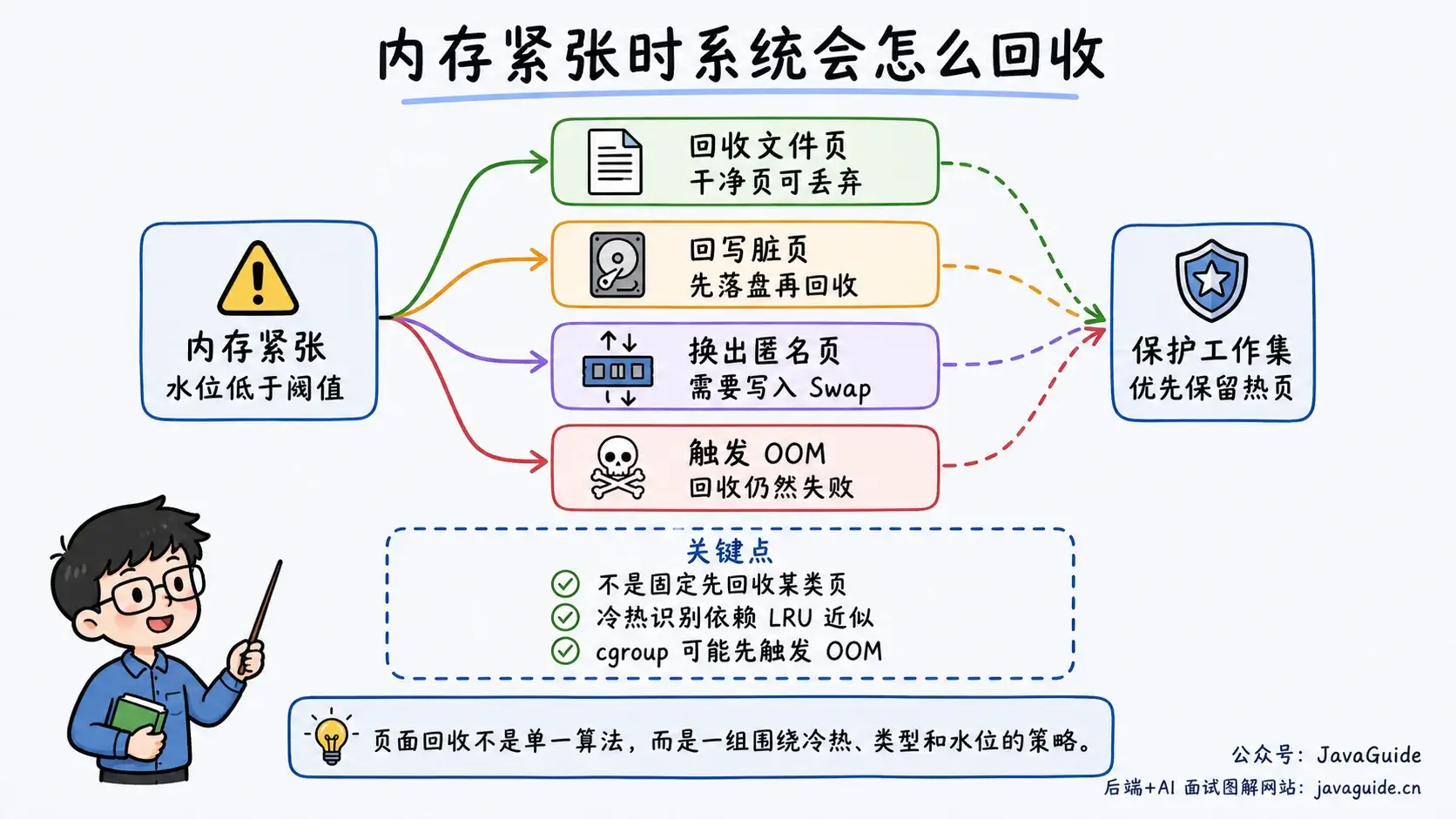
因此,把 Linux 页面回收简单说成某一个算法并不准确。它更像一组围绕工作集保护、冷热识别和内存水位控制组合起来的策略。
Swap、工作集和抖动
Swap 不是“多出来的内存”,更像一块低速后备区域。匿名页没有文件来源,内存紧张时如果要回收它,就可能写入 Swap;以后再访问,再从 Swap 读回。
一个进程真正活跃使用的页面集合叫工作集。只要物理内存能容纳系统里主要进程的工作集,缺页就比较可控;如果容纳不下,页面会被频繁换出又换入,系统进入抖动状态。
抖动时,CPU 看起来不一定忙在业务计算上,磁盘 I/O、主缺页、内存回收会变得很明显。排查时可以看这些指标:
# 系统整体
free -h
vmstat 1
cat /proc/meminfo
cat /proc/pressure/memory
grep -E 'pgfault|pgmajfault|pswpin|pswpout|pgscan|pgsteal' /proc/vmstat
# 单个进程
grep -E 'VmSize|VmRSS|RssAnon|RssFile|RssShmem|VmSwap' /proc/<pid>/status
cat /proc/<pid>/smaps_rollup
pmap -x <pid>
perf stat -e page-faults,major-faults <command>
# 容器 / cgroup v2
cat /sys/fs/cgroup/memory.current
cat /sys/fs/cgroup/memory.max
cat /sys/fs/cgroup/memory.events
cat /sys/fs/cgroup/memory.pressure读这些指标时,可以按来源拆开看:进程侧看 RSS/PSS 和 smaps_rollup,确认常驻内存落在匿名页、文件页还是共享内存;缺页侧看 pgmajfault 和 major-faults,确认慢在 I/O 还是只是在建映射;系统侧看 Swap、回收扫描和 PSI,确认内存压力有没有传到业务延迟上。
排查时不要只看 free。Linux 会尽量把空闲内存用于 Page Cache,低 MemFree 不一定表示压力很大;更应结合 MemAvailable、Swap 活跃度、主缺页、回收扫描和 PSI 判断。PSI 里的 some 表示至少有任务因内存压力停顿,full 表示所有非 idle 任务都同时因该资源停顿,通常更能反映内存压力对业务延迟的影响。
Overcommit 和 OOM:申请成功不等于物理内存已经准备好
Linux 可以允许进程承诺的虚拟内存超过当前 RAM 和 Swap,这叫内存 overcommit。它适合那些会申请很大地址空间、但只实际使用其中一部分的程序。
vm.overcommit_memory 常见有 3 种模式:
0:启发式判断,拒绝明显不合理的申请。1:尽量允许申请,直到真正耗尽资源。2:使用更严格的 commit 限制。
因此,malloc() 或 mmap() 成功,通常只表示地址空间和 commit 检查通过,不代表对应物理页已经全部驻留。当页面实际被访问,内核又无法通过回收、写回或 Swap 获得足够内存时,可能触发 OOM Killer,选择进程终止以释放资源。
在容器里,还可能先触发 cgroup 范围内的 OOM。宿主机整体仍有可用内存,某个容器也可能因为 memory.max 达到上限而被限制;cgroup v2 的 memory.events 会记录 high、max、oom、oom_kill 等事件。
mmap、COW 和共享内存
mmap() 会在进程虚拟地址空间里创建一段映射。它可以映射文件,也可以创建匿名映射。映射建立时不一定马上读入数据,真正访问到某个还没驻留的页时,才可能触发缺页。
文件映射适合随机访问、共享文件页,以及希望直接按内存地址访问文件内容的场景。它可以减少显式的用户态缓冲区拷贝和系统调用,但不保证一定比 read()/write() 更快;实际效果还取决于访问模式、缺页成本、预读、写回、异常处理和文件大小。
多个进程映射同一个文件时,内核可以让它们共享 Page Cache 中的物理页。MAP_SHARED 的修改可以对其他映射可见,并可写回底层文件;MAP_PRIVATE 创建的是私有 COW 映射,写入不会传播给其他进程,也不会写回原文件。共享内存 IPC 也是类似思路:不同进程的虚拟地址映射到同一批物理页,读写数据不需要每次经过内核拷贝。
COW(Copy-On-Write,写时复制)也很常见。fork() 后父子进程最开始可以共享同一批物理页,页表标成只读;谁先写,谁触发缺页,内核再复制一份页面给写入方。这样避免了 fork() 时立刻复制整个地址空间。
不过,COW 不是免费午餐。Redis 做 RDB 快照时会 fork() 子进程,父进程继续处理写请求;写请求越多,被复制的页越多,内存压力也越大。理解这点,才能看懂很多数据库、缓存系统里的 fork、mmap、Page Cache 和内存峰值问题。
内存管理和 Java 后端有什么关系?
操作系统内存管理并不只停在教材里。Java 后端平时会遇到很多相关现象。
JVM 堆是虚拟地址空间的一部分。 -Xmx 限的是 Java 堆最大值,但进程 RSS 还会包含元空间、线程栈、JIT 代码缓存、DirectBuffer、本地库、mmap 文件映射等。看到 RSS 大于 -Xmx,不能直接判断是堆泄漏。
线程栈也要占地址空间和物理页。 平台线程很多时,线程栈、调度开销、TLB 和缓存失效都会变重。虚拟线程能降低大量阻塞任务对平台线程的依赖,但 CPU 密集型任务仍然受核心数限制。
DirectBuffer 和 mmap 不在 Java 堆里。 它们由 JVM 或本地代码管理,最终还是落到进程地址空间和物理页上。排查时不能只看 GC 日志,也要结合 NMT、pmap、smaps_rollup、cgroup 指标一起看。
HotSpot NMT 默认关闭,需要在 JVM 启动时加参数:
-XX:NativeMemoryTracking=summary
# 或
-XX:NativeMemoryTracking=detail
jcmd <pid> VM.native_memory summaryNMT 能按 JVM 子系统统计原生内存,例如 Java Heap、Class、Code、Thread 等;但它不是操作系统级的完整进程内存账本,也不能覆盖所有第三方 native library 分配。RSS/PSS、smaps_rollup 和容器内存限制仍然要一起看。
大页不一定总是收益。 大页能降低 TLB 压力,但 THP 的直接回收、内存紧凑、大页清零和 COW 都可能带来延迟波动。Redis 官方就明确提醒:RDB/AOF 后台任务依赖 fork() 和 COW,写密集时额外内存可能接近平时用量的一倍;THP 还可能放大 fork() 后的 COW 成本。JVM、数据库和缓存系统不能共用一套固定结论,应按产品文档和实际负载压测。
面试里怎么回答?
如果被问“操作系统内存管理做什么”,别从分页、分段这些名词开始背。先讲主线:
操作系统先给每个进程一套独立的虚拟地址空间,再通过页表、TLB 和 MMU 把虚拟地址翻译成物理地址。页表不只做地址翻译,还会记录权限、是否在内存、是否被修改、是否被访问过。等物理内存紧张时,内核再根据页面冷热、页面类型和系统水位回收文件页或匿名页,必要时才动用 Swap。
追问分页和分段时,把差别落到“怎么切地址空间”上。分页按固定大小切,物理内存可以离散分配,基本消除了外部碎片;分段按代码、数据、栈这类逻辑区域切,表达程序结构更直观,但段长不固定,容易留下外部碎片。现代通用系统主要靠分页,分段更多用于理解历史设计和逻辑保护。
缺页异常可以按处理过程讲:CPU 访问某个虚拟地址,页表项不存在、页面不在内存,或者权限不匹配,就会触发 page fault。内核先判断这次访问是否合法;非法访问通常变成 SIGSEGV,合法访问才会按映射类型建立页面,例如映射已有 Page Cache 页面、分配匿名页、处理 COW,或者从文件和 Swap 调页。minor fault 通常不需要 I/O,major fault 需要 I/O。
真要聊到线上排查,再补这个限制:教科书算法适合理解思路,但 Linux 的内存回收、THP、NUMA、cgroup 内存限制、内存压缩和数据库自己的缓存管理都会叠在一起。定位问题时,用一个“LRU”解释所有现象,通常不够。