为什么 TCP 是面向字节流,UDP 是面向报文?(传输层)
前面说 TCP 是面向字节流,UDP 是面向报文。这个点看起来像一句定义,但很多粘包、拆包问题,其实都藏在这里。
先说结论:TCP 只保证字节可靠、有序地到达,不保证应用层消息边界;UDP 会保留应用层交给它的报文边界。
这篇文章主要回答几个问题:
- 为什么说 TCP 是面向字节流,UDP 是面向报文?
- TCP 粘包、拆包到底是怎么产生的?
- 应用层应该如何定义消息边界?
- Nagle 算法和 Delayed ACK 为什么可能让小包变慢?
举个例子,应用层连续发送两条消息:
消息 1:hello
消息 2:world如果用 UDP 发送,通常会对应两个 UDP 数据报。接收方调用 recvfrom() 时,也是按数据报来读:一次读取一个 UDP 报文,不会把两次发送的报文合成一个流。UDP 的接收队列里,一个元素就是一个数据报,消息边界天然保留了下来。
不过这里也有一个细节:UDP 保留的是传输层报文边界,不代表它适合发送任意大的消息。数据报太大时,底层 IP 层仍可能分片;接收端缓冲区太小时,也可能出现截断。所以 UDP 的“面向报文”不是“随便发多大都没事”,而是说它不会像 TCP 那样把应用数据抽象成一条连续字节流。RFC 768 对 UDP 的定义就是 datagram mode,并说明它提供的是最小协议机制,不保证可靠交付和去重。
如果用 TCP 发送,就不能这么理解。应用层调用两次 send(),只是把两段字节写进内核发送缓冲区。至于这些字节什么时候发、合成几个 TCP 段发、对端一次 recv() 能读到多少,都不是由这两次 send() 直接决定的。
比如,接收端可能一次读到(粘包):
helloworld也可能分几次读到(拆包):
hel
lowor
ld这不是 TCP 出错,而是 TCP 的工作方式本来就是这样。TCP 处理的是连续字节流,它只关心这些字节是否可靠、有序地到达,不关心应用层定义的“第几条消息”从哪里开始、到哪里结束。RFC 9293 也明确提到,TCP segment 和应用层 send() / socket write 的边界通常不是一一对应的,TCP 不保证应用读写缓冲区边界和网络分段边界相关。
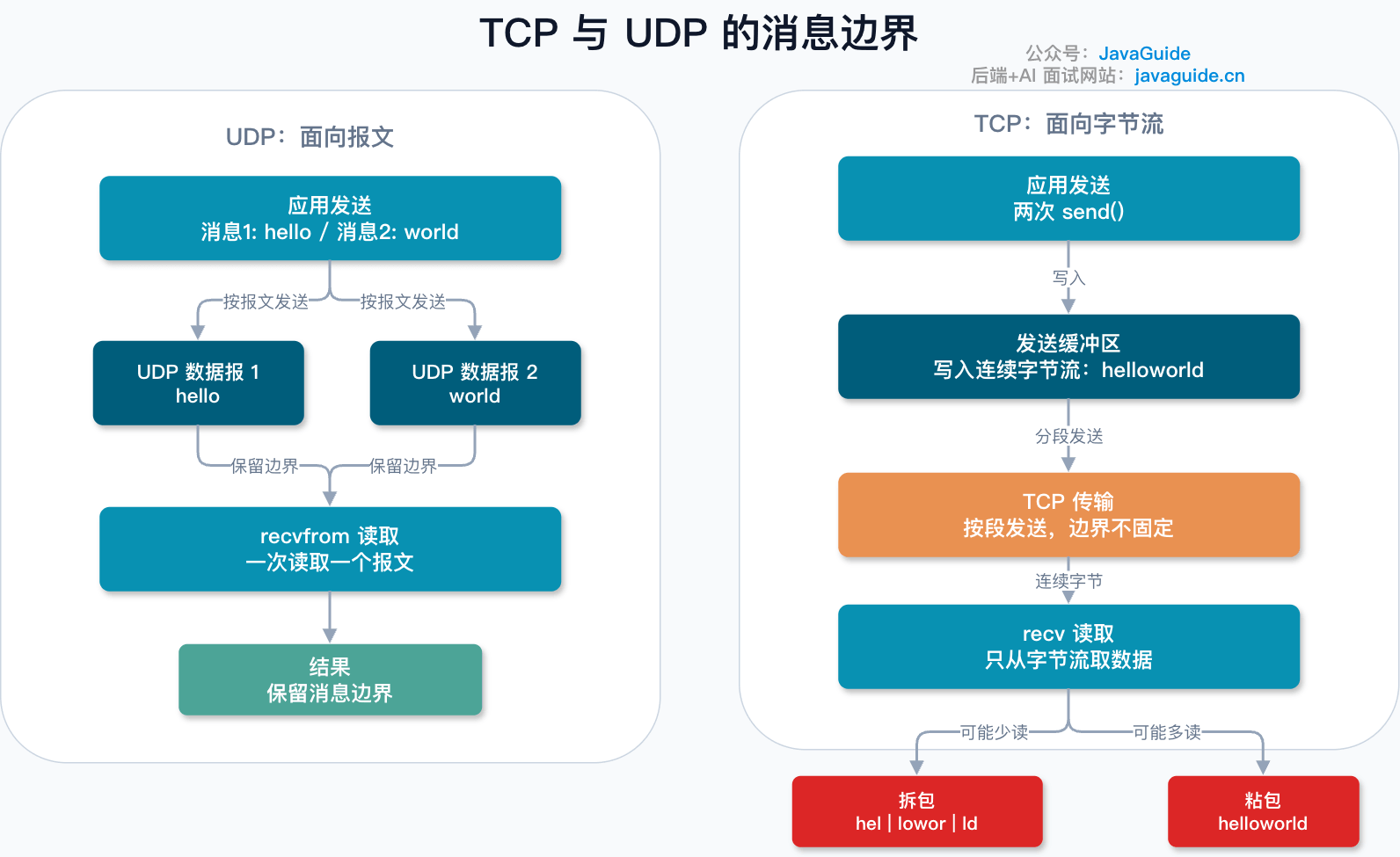
所以,“TCP 粘包/拆包”这个说法更像是应用层视角下的现象。严格来说,TCP 没有“包”的概念,它传的是连续字节流。真正需要解决的是:应用层协议如何定义消息边界。
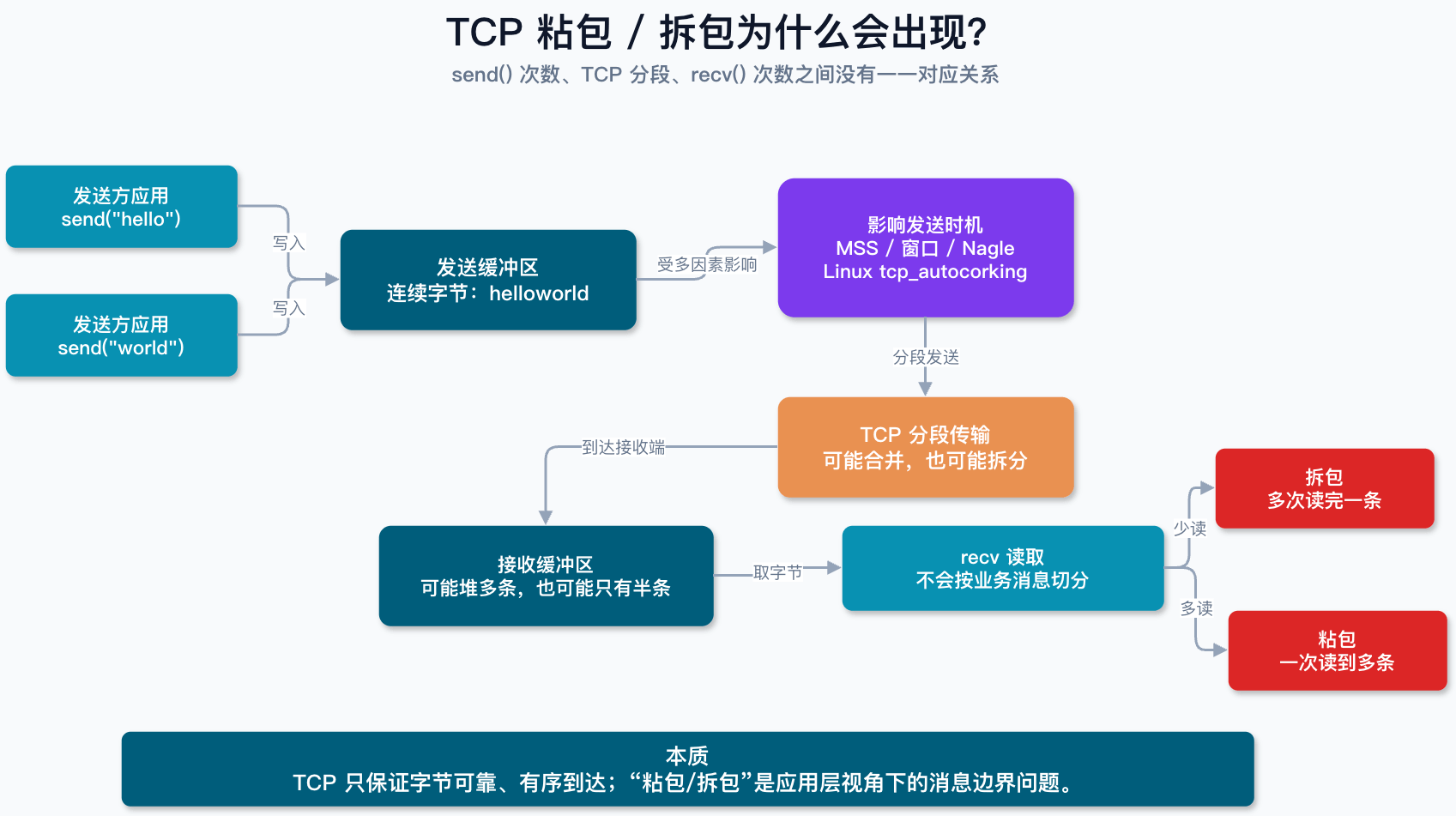
为什么会出现粘包和拆包?
常见原因有这几个。
1. TCP 是字节流协议,没有应用层消息边界。
TCP 负责把字节可靠、有序地送到对端,但不会记录“这 20 个字节是第一条消息,那 30 个字节是第二条消息”。
2. 一次 send() 不等于一次网络发送。
send() 成功通常只表示数据从应用进程拷贝到了内核发送缓冲区。至于什么时候真正发出去、拆成几个 TCP 段发,要看 MSS、发送窗口、拥塞窗口、Nagle 算法、网卡队列等因素。
3. 一次 recv() 也不等于读到一条完整消息。
接收端只是从 TCP 接收缓冲区取字节。缓冲区里可能已经堆了多条消息,也可能只有半条消息。recv() 只会把当前可读的数据拷贝给应用,不会帮你按业务消息切分。
4. 小包优化可能改变发送时机。
Nagle 算法、Delayed ACK、Linux 自动合并小写入等机制,都可能影响小数据的发送时机。比如 Linux 从 3.14 开始有 tcp_autocorking,内核会尽量合并连续的小写入,减少发送包数量;应用也可以用 TCP_CORK 明确控制何时“拔塞”发送。
这也是为什么在 Netty、Dubbo、自定义 RPC、IM 网关、游戏服务里,协议编解码都很重要。只要底层用的是 TCP,就必须在应用层定义清楚消息边界。
怎么解决 TCP 粘包/拆包?
核心思路只有一个:让接收方知道一条消息到哪里结束。
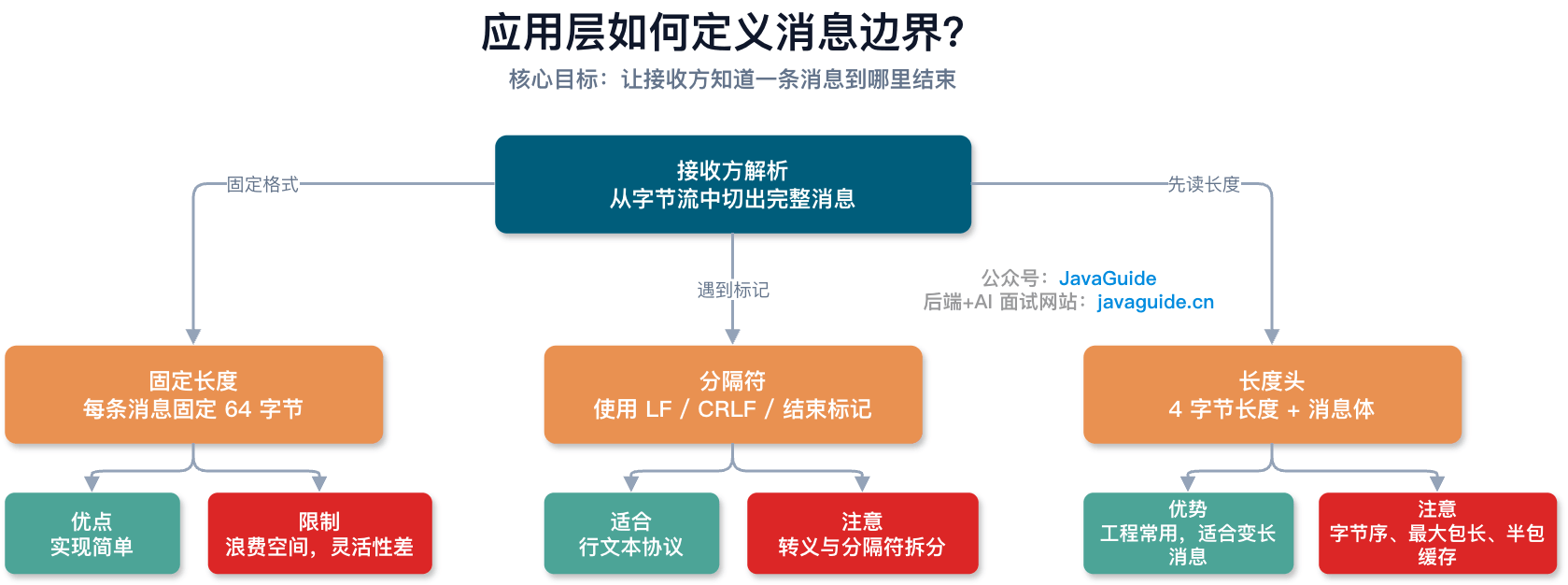
常见做法有三种。
1. 固定长度
规定每条消息都是固定长度,比如 64 字节。接收方每读满 64 字节,就认为读到了一条完整消息。
这种方式实现简单,但灵活性差。消息短了要补齐,浪费空间;消息长了又要额外拆分。它适合消息格式非常固定的场景,不太适合通用业务协议。
2. 分隔符
在消息之间加特殊分隔符,比如换行符 \n、\r\n,或者自定义结束标记。
hello\n
world\n接收方不断从缓冲区读数据,只要遇到分隔符,就切出一条完整消息。很多文本协议都会用类似思路。
这种方式直观,但要注意两个问题:第一,分隔符可能刚好出现在消息体里,这时需要转义;第二,分隔符本身也可能被拆在两次读取里,所以接收端解析时不能假设一次 recv() 就能读到完整分隔符。
3. 长度头
这是工程里更常见的一种方式。协议头里固定放一个长度字段,表示后面的消息体有多少字节。
| 4 字节长度 | 消息体 |接收方先读固定长度的协议头,解析出消息体长度,再继续读取指定字节数。只要没有读满,就继续等待;如果读多了,就把多出来的字节留在缓冲区,作为下一条消息的开头。
很多二进制协议、RPC 协议都会用这种方式。实际设计时,协议头里通常不只放长度,还会放魔数、版本号、消息类型、序列号、序列化方式等字段。
长度头方案也有坑。长度字段要约定字节序,通常使用网络字节序;还要限制最大包体长度,避免对端传一个特别大的长度值,把内存撑爆。线上做协议解析时,不能只考虑正常路径,还要处理半包、异常长度、连接中途关闭、恶意构造请求等情况。
Nagle 算法和 Delayed ACK 为什么会让小包变慢?
讲粘包时,经常会顺带问到 Nagle 算法。
Nagle 算法的目标是减少小包数量。早期网络带宽有限,如果应用每次只写 1 个字节,TCP/IP 头部却有几十个字节,网络里就会充满“小包”,效率很低。RFC 896 讨论的就是这类 small-packet problem,并提出当连接上还有未确认数据时,新的小数据可以先暂缓发送,等 ACK 到来后再继续发送。
Delayed ACK 是接收端的优化。接收端收到数据后,不一定立刻发 ACK,而是等一小段时间,看能不能把 ACK 和要返回的数据一起发出去,减少纯 ACK 包数量。RFC 9293 也把这种“少于每个数据段一个 ACK”的策略称为 delayed ACK。
这两个机制单独看都有道理,放在一起就可能放大延迟。典型场景是:
客户端 write 小数据 A
客户端马上 write 小数据 B
客户端等待服务端响应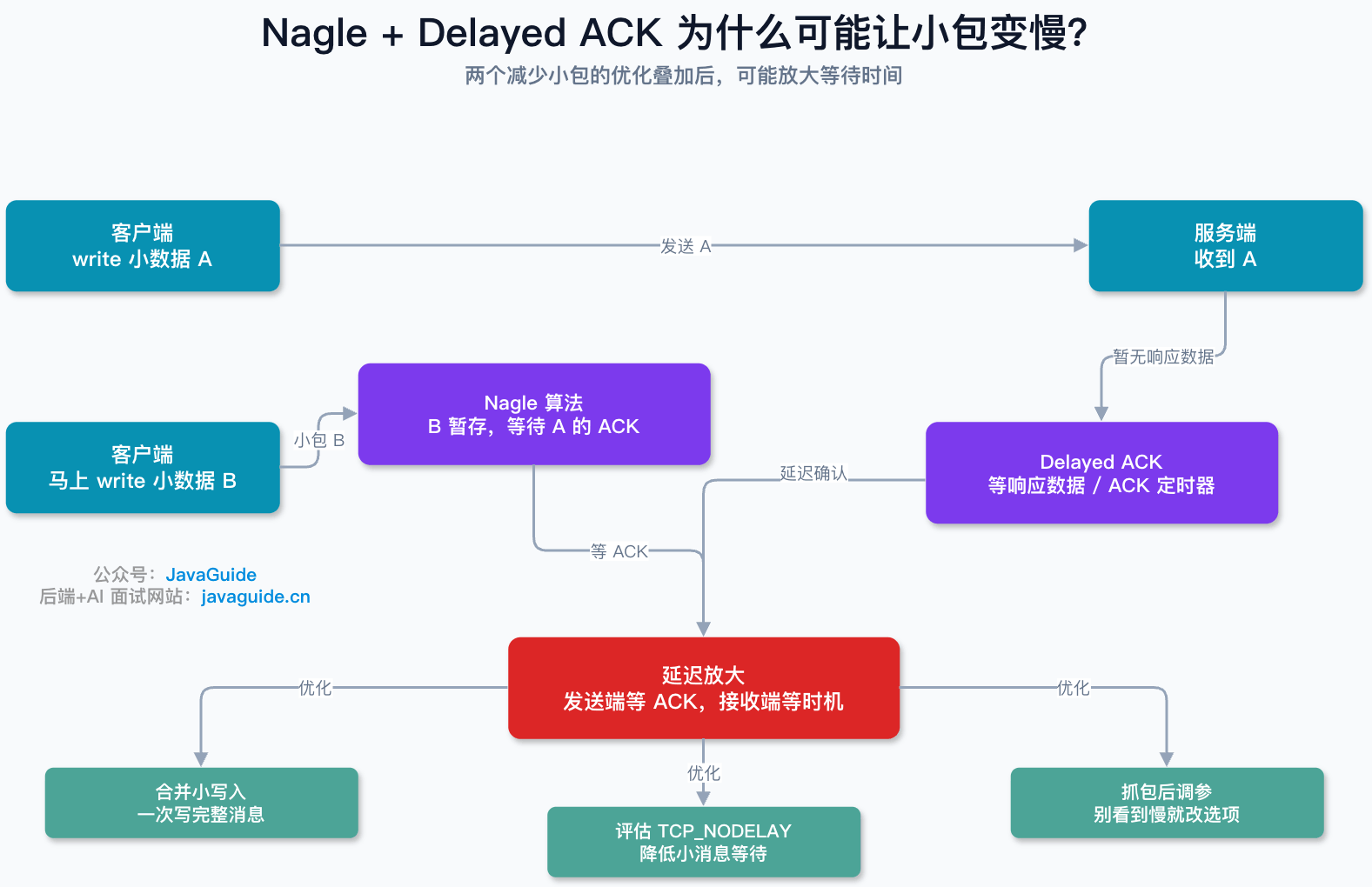
小数据 A 发出去了,小数据 B 可能因为 Nagle 算法暂存在发送缓冲区里,等待 A 的 ACK。服务端收到 A 后,如果暂时没有业务响应要返回,Delayed ACK 又可能延迟发送 ACK。于是发送端等 ACK,接收端等更多数据或等延迟确认定时器,延迟就被放大了。
这类问题在短小 RPC、交互式协议、游戏同步、远程终端里更容易被感知。
解决思路不是“无脑关 Nagle”。更稳的做法是:
- 能合并的小写入,在应用层先合并成一次完整消息,再调用一次
write()。 - 请求/响应模型里,尽量避免连续多次小
write()后马上等待响应。 - 对延迟敏感、消息很小的连接,可以评估开启
TCP_NODELAY,让小数据尽快发送。 - 对吞吐优先、希望攒够数据再发的场景,可以在 Linux 上评估
TCP_CORK,但它不适合写跨平台代码。 - 调参前先抓包确认,不要看到“慢”就直接改 socket 选项。
在 Java 里,很多网络框架都会暴露 TCP_NODELAY 配置,例如 Netty 的 ChannelOption.TCP_NODELAY。它确实能降低小消息的等待时间,但也可能增加小包数量。对高 QPS 服务来说,这个 trade-off 要结合消息大小、RTT、吞吐、CPU 和网卡包量一起看。Linux tcp(7) 也说明,TCP_NODELAY 会关闭 Nagle 算法,而 TCP_CORK 则用于避免发送不完整帧、等应用确认“可以发了”再发送。
面试时怎么回答?
可以这么回答:
TCP 是面向字节流的。应用层写入的数据会进入内核缓冲区,TCP 只保证这些字节可靠、有序地到达对端,不保证一次 send() 对应一次 recv(),也不保留应用层消息边界。因此接收方可能一次读到多条消息,也可能只读到半条消息,这就是常说的粘包、拆包现象。
UDP 是面向报文的。应用层交给 UDP 的一次数据会作为一个 UDP 数据报发送,接收端也是按数据报读取,所以天然保留消息边界。不过 UDP 不保证可靠到达,也不保证顺序。
解决 TCP 粘包/拆包,本质是应用层协议自己定义消息边界。常见方案有固定长度、分隔符、长度头。工程里更常用长度头,因为它对二进制协议和变长消息更友好,但要处理字节序、最大长度限制、半包缓存和异常连接关闭等问题。
写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。