进程与线程详解:区别、状态、通信、上下文切换与虚拟线程
进程和线程是操作系统里最基础、也最容易被混着背的两个概念。
面试里问它们的区别,很多回答会停在“进程是资源分配的基本单位,线程是 CPU 调度的基本单位”。这句话可以作为入口,但不够用。
继续往下追,就会遇到一串更具体的问题:为什么进程之间默认隔离?线程到底共享了什么?fork() 后父子进程有哪些东西相同、哪些东西已经分开?为什么多线程程序里随便 fork() 会出问题?Java 虚拟线程又算不算操作系统线程?
这篇文章就顺着这些问题展开。先把程序、进程、线程的边界讲清楚,再看 Linux 里的 fork、exec、wait、clone,最后回到上下文切换、线程模型和 Java 虚拟线程。读的时候可以抓住一条主线:进程更像资源和隔离边界,线程更像一条可以被调度的执行路径。
程序、进程和线程分别是什么?
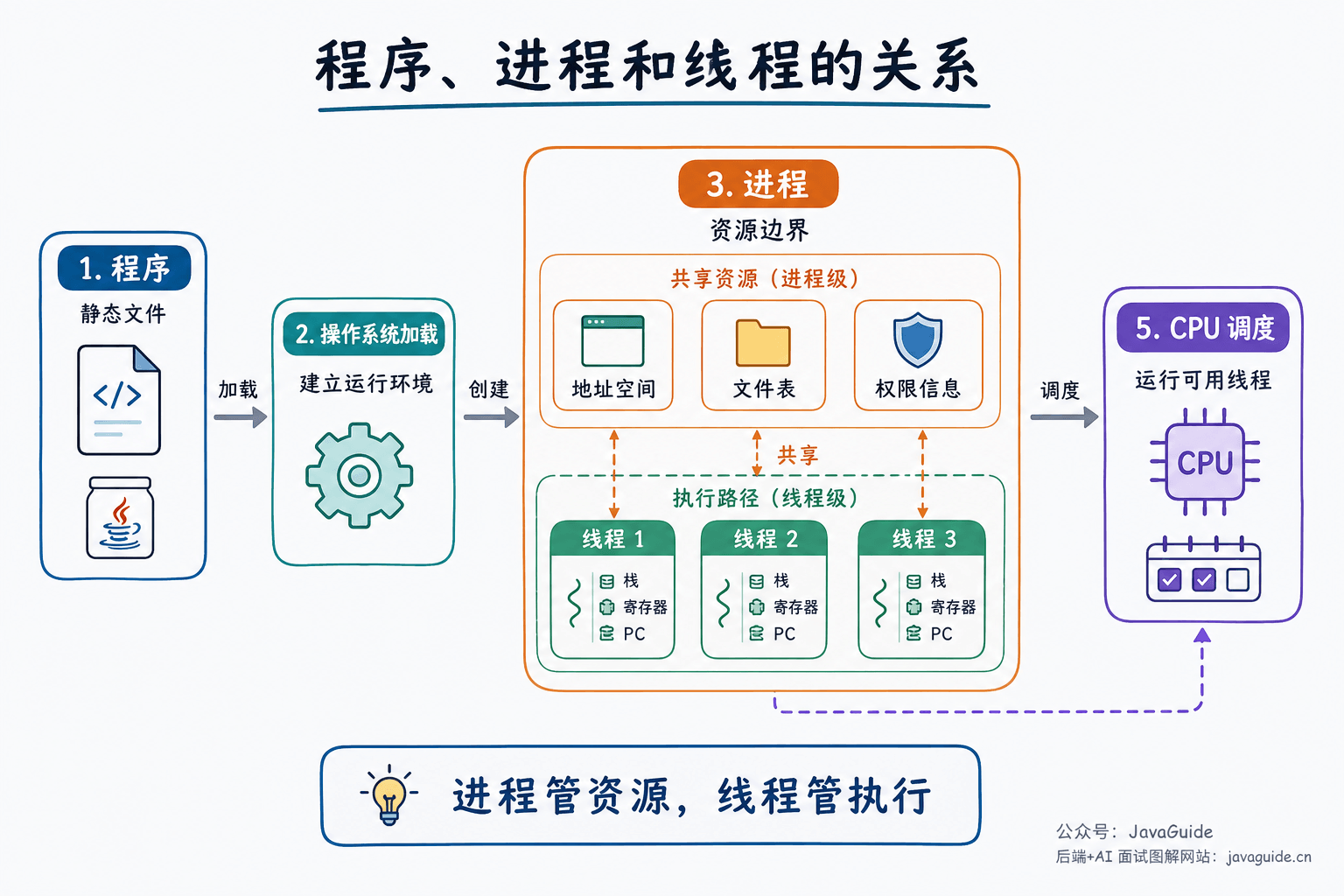
程序是存放在磁盘上的一组指令和数据,比如一个可执行文件、一个 JAR 包。它还没有真正运行,只是静态文件。
当操作系统把程序加载到内存,为它建立虚拟地址空间、文件描述符表等进程级资源,并为初始线程建立栈、寄存器上下文等执行现场后,程序的一次运行就变成了进程。同一个程序可以启动多次,对应多个进程;比如同时打开两个终端窗口,通常就是两个不同的进程实例。
线程是进程里的执行流。一个进程至少有一个线程,进程中的多个线程共享这份进程资源,但每个线程也有自己的执行现场。现代操作系统真正拿去调度的通常是线程:哪个线程处于可运行状态,调度器就可能把 CPU 时间片分给它。
可以用一句话先记住大方向:进程侧重资源边界,线程侧重执行和调度。
判断一个概念更偏进程还是更偏线程,也可以先问:它描述的是资源边界,还是一条执行路径?地址空间、打开文件表、权限信息更偏进程;栈、寄存器、程序计数器更偏线程。
不过这句话只是学习时的抓手,不能当成所有系统的实现细节。比如 Linux 内核内部用 task_struct 描述调度实体,进程和线程更像是共享资源程度不同的任务;Windows 文档则明确把线程说成操作系统分配处理器时间的基本单位。不同系统名字不完全一样,但抽象层面的关系大致相通。
进程拥有哪些资源?
进程不是只有正在执行的代码。一个进程通常包含这些内容:
- 虚拟地址空间:进程看到的是一段连续的虚拟内存,里面有代码段、数据段、堆、栈、内存映射区域等。
- 打开的文件和句柄:比如文件描述符、Socket、管道、设备句柄。
- 安全和身份信息:比如用户 ID、权限、凭据、安全上下文。
- 调度相关信息:优先级、CPU 时间统计、亲和性、状态等。
- 信号、环境变量、工作目录等运行上下文。
进程之间默认是隔离的。一个进程不能随便读写另一个进程的虚拟地址空间,这也是操作系统能把不同程序保护起来的基础。两个进程想交换数据,需要借助管道、消息队列、共享内存、Socket、文件、信号等 IPC 方式。
隔离带来安全,也带来成本。两个进程各自有地址空间和资源表,切换、通信、创建和销毁都比线程更重。
进程有哪些常见状态?
教材里常见的五状态模型够应付大多数面试题:
- 创建状态(New):进程正在创建,还没有进入就绪队列。
- 就绪状态(Ready):运行条件基本具备,只差 CPU。
- 运行状态(Running):正在 CPU 上执行。
- 阻塞状态(Blocked/Waiting):正在等某个事件,比如 I/O 完成、锁释放、定时器到期。
- 终止状态(Terminated/Exit):进程结束,操作系统回收相关资源。
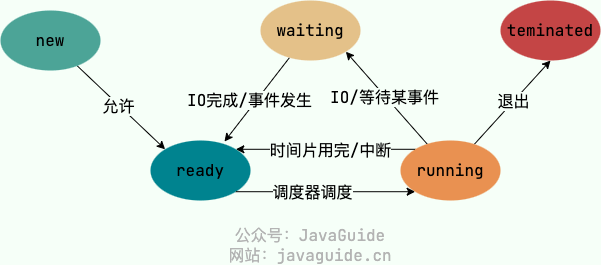
状态转换的关键不在名词,而在触发原因。就绪态拿到 CPU 会变成运行态;运行中的时间片用完,可能回到就绪态;运行中发起阻塞 I/O,会进入阻塞态;阻塞等待的事件完成后,先回到就绪态,等待下一次被调度。
有些教材还会加入挂起状态。挂起强调进程暂时不在内存中,或者被用户/系统暂停;阻塞强调它在等待事件。二者不是一回事:一个进程可以阻塞但仍在内存里,也可以被换出到外存后处于阻塞挂起。
PCB 是什么?
PCB(Process Control Block,进程控制块)是操作系统管理进程的数据结构。进程运行时的许多信息不会散落在空气里,而是由内核放在类似 PCB 的结构里维护。
PCB 通常记录:
- 进程标识信息:PID、父进程 ID、用户 ID 等。
- 进程状态和调度信息:就绪、运行、阻塞、优先级、时间统计。
- CPU 上下文:程序计数器、栈指针、通用寄存器等,方便切换回来继续执行。
- 内存管理信息:页表、虚拟地址空间、内存映射。
- 资源信息:打开文件、信号处理、工作目录、I/O 状态等。
发生上下文切换时,操作系统会把当前执行实体的寄存器等现场保存起来,再恢复下一个执行实体的现场。PCB/TCB 这类结构就是“下次从哪儿继续跑”的依据。
Linux 的实现有一点特别:它把进程和线程都看成 task,task_struct 里并不直接塞进所有资源,而是通过指针指向内存描述符、文件表、信号处理等资源结构。多个线程属于同一进程时,它们会指向同一批资源结构;不同进程则指向不同资源。这也是 Linux 上理解 clone() 很有用的原因。
Linux 里 fork、exec、wait 分别做什么?
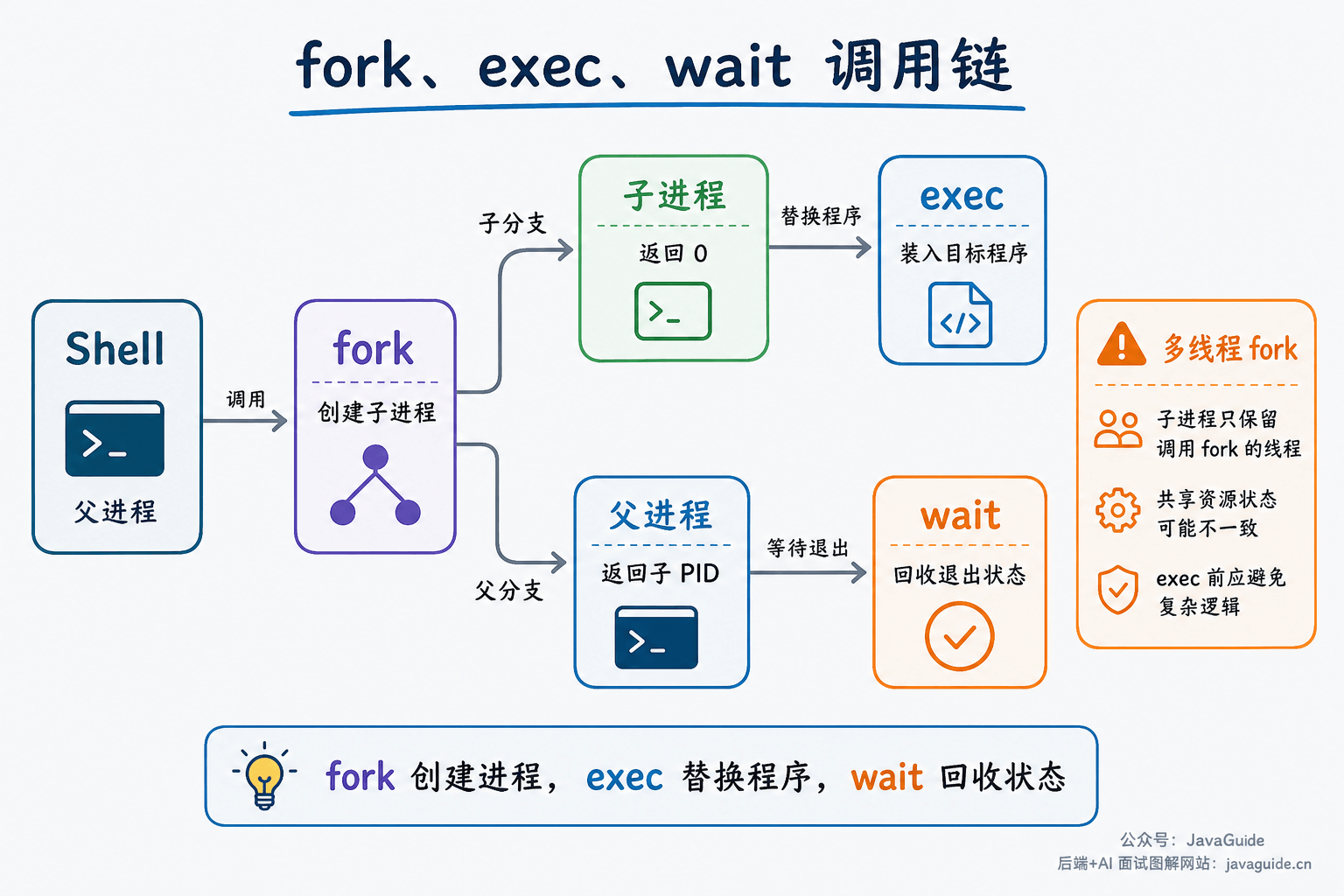
在 Unix/Linux 编程里,进程创建常绕不开 fork()、exec()、wait() 这三个动作。
fork() 用来创建子进程。调用成功后,父子进程从同一个位置继续往下执行,只是返回值不同:父进程拿到子进程 PID,子进程拿到 0。父子进程拥有独立的虚拟地址空间,刚创建时内容看起来一样;现代系统一般配合写时复制,只有当某一方写内存时,内核才复制对应页面。
还要注意文件描述符。fork() 后,父子进程的文件描述符表是各自的副本,但对应 fd 会指向同一个 open file description,所以文件偏移量、打开状态标志等会共享。工程里常配合 FD_CLOEXEC 或 O_CLOEXEC,避免 exec() 后把不该继承的 fd 泄漏给新程序。
exec() 系列函数用于在当前进程里装入另一个程序。它不会新建进程,而是把当前进程的代码、数据、堆、栈等用户态内容替换成新程序。命令行里常见的模型就是:Shell 先 fork() 出子进程,子进程再 exec() 成目标程序。
wait()/waitpid() 用来等待子进程状态变化,并回收子进程退出后残留在内核里的状态信息。子进程已经退出但父进程还没有 wait,就会留下僵尸进程。僵尸进程不再执行代码,但仍占着 PID 和退出状态记录。
Shell 启动外部命令时,常见链路就是:Shell 调 fork() 创建子进程,子进程调 exec() 变成目标程序,父进程用 wait() 或 waitpid() 等待并回收退出状态。
这里有个容易忽略的细节:多线程进程调用 fork() 后,子进程里只保留调用 fork() 的那个线程。父进程其他线程的锁状态、条件变量状态、malloc 状态、stdio 状态可能被复制过去,但对应线程已经不存在。更严格地说,多线程程序 fork() 之后、exec() 之前,子进程只应调用 async-signal-safe 的函数;在这段窗口里做复杂逻辑很容易踩坑。
线程共享什么,又私有什么?
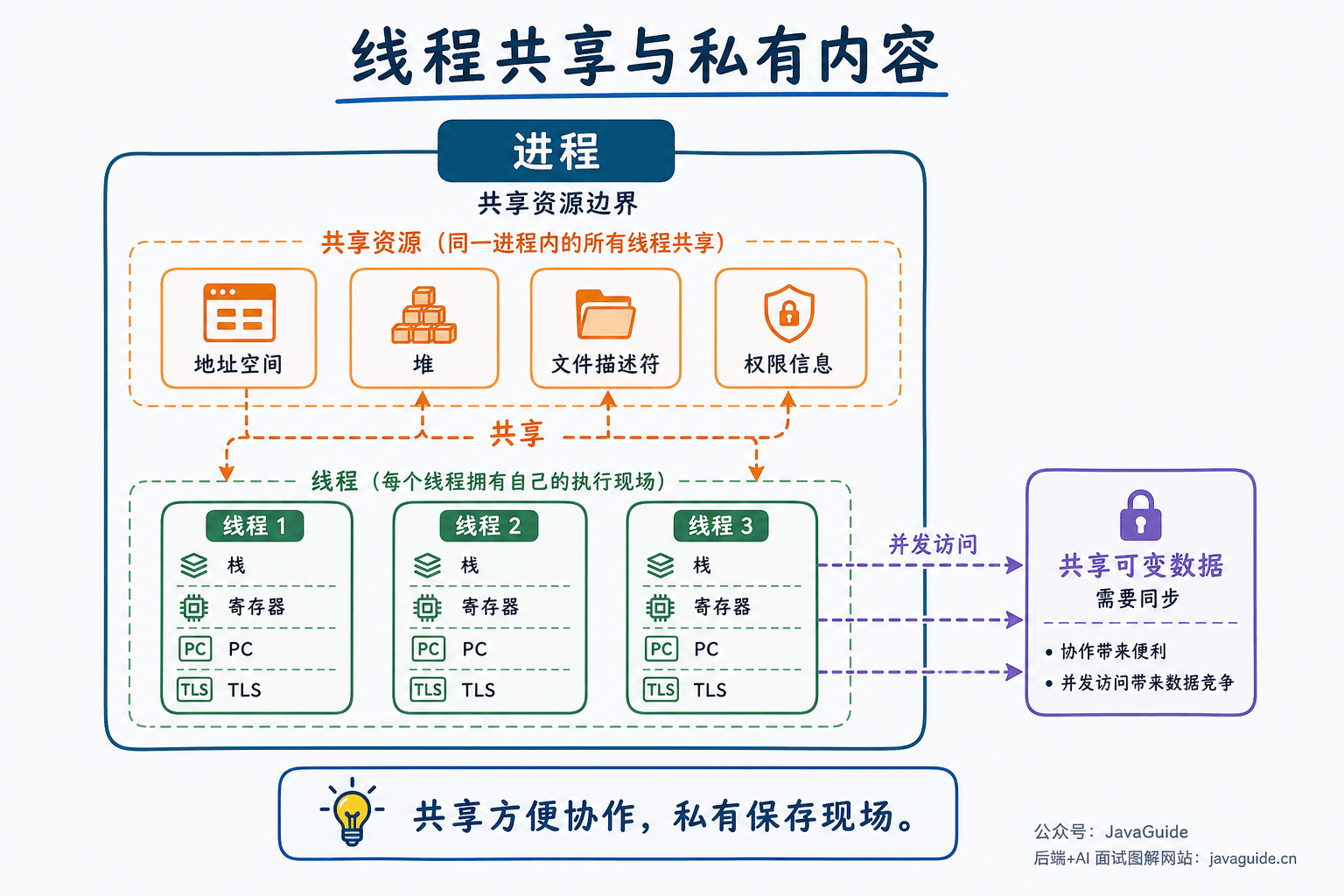
从操作系统角度看,同一进程内的线程共享进程的大部分资源,例如:
- 代码段、数据段、堆等进程地址空间里的内存区域;
- 打开的文件描述符、Socket、工作目录;
- 进程 ID、地址空间、信号处理配置中的一部分;
- 全局变量和堆对象。
如果换到 Java/JVM 语境,Java 线程还会共享同一个 JVM 进程里的堆、方法区/元空间等运行时数据区域。方法区/元空间不是通用操作系统概念,放在 JVM 这一层理解更合适。
在 Linux 用户态,同一进程内的多个线程调用 getpid() 通常看到的是同一个线程组 ID,也就是平时说的进程 ID;但每个线程在内核里仍有自己的 task/TID,可以用 gettid() 区分。
每个线程也有自己的私有内容:
- 栈:保存函数调用、局部变量、返回地址等。
- 寄存器和程序计数器:记录线程当前执行到哪里。
- 线程 ID、调度优先级、线程本地存储(TLS)。
- 线程状态和少量内核用于恢复执行的上下文信息。
共享让线程间通信很方便,一个线程往堆里的对象写入数据,另一个线程马上就可能看到。但共享也带来数据竞争:多个线程同时读写同一份可变数据,如果没有锁、原子变量、条件变量等同步手段,结果就可能不符合预期。
这也是线程和进程在工程上的重要差别:进程崩溃通常不会直接破坏另一个进程;同一进程内某个线程越界写内存、触发非法访问,往往会把整个进程带走。
TCB 是什么?
TCB(Thread Control Block,线程控制块)可以理解为线程级别的控制信息。它通常记录线程 ID、线程状态、寄存器现场、栈信息、优先级、线程本地存储等内容。
在一些教材或系统实现里,PCB 和 TCB 是分开的:PCB 负责进程级资源,TCB 负责线程级执行现场。Linux 的 task_struct 则把调度实体统一为 task,再按资源结构是否共享来区分进程和线程。概念学习时不必纠结名字,关键是看清哪些信息属于资源边界,哪些信息属于执行现场。
有了进程为什么还需要线程?
主要是为了在同一个应用内用更低成本做并发。
如果一个服务端要同时处理网络读写、业务计算、日志刷盘,用多个进程当然也能做,但进程之间共享状态麻烦,通信要走 IPC,资源占用也更高。改成多个线程后,它们能直接共享堆内存和打开的连接,只要同步写对,协作成本低很多。
线程也能提高资源利用率。单核 CPU 上,一个线程阻塞在磁盘或网络 I/O 时,其他线程可以继续运行;多核 CPU 上,多个线程有机会在不同核心上同时执行。CPU 密集型任务、I/O 密集型任务对线程数的需求不同,不能简单理解为线程越多越快。
线程不是免费资源。Linux NPTL 下,如果进程启动时的 RLIMIT_STACK 软限制不是 unlimited,它会决定新线程的默认栈大小;常见 ulimit -s 为 8192 KB,因此常见默认线程栈是 8 MB。如果 RLIMIT_STACK 是 unlimited,则使用架构相关默认值,例如多数架构为 2 MB。也可以通过 pthread_attr_setstacksize() 指定线程栈大小,但不能低于 PTHREAD_STACK_MIN,Linux man-pages 给出的值是 16384 字节。除此之外,线程还受 PID 数量、threads-max、内存等限制。线上系统里盲目创建大量平台线程,常见后果是内存压力、调度开销和上下文切换增多。
用户线程、内核线程和线程模型怎么区分?
按“谁负责调度”来看,线程可以分为用户级线程和内核级线程。
用户级线程由用户态运行时或线程库管理,内核通常看不到这些线程。它的好处是创建、切换不一定需要系统调用;问题是如果所有用户线程只对应一个内核调度实体,那么其中一个线程发起阻塞系统调用,可能拖住整个进程,也很难利用多核。
内核级线程由操作系统内核创建和调度。某个线程阻塞,内核还能调度同进程的其他线程;多个线程也能在多核上并行执行。代价是创建、销毁、阻塞、唤醒、切换都要内核参与。
常见线程模型有三类:
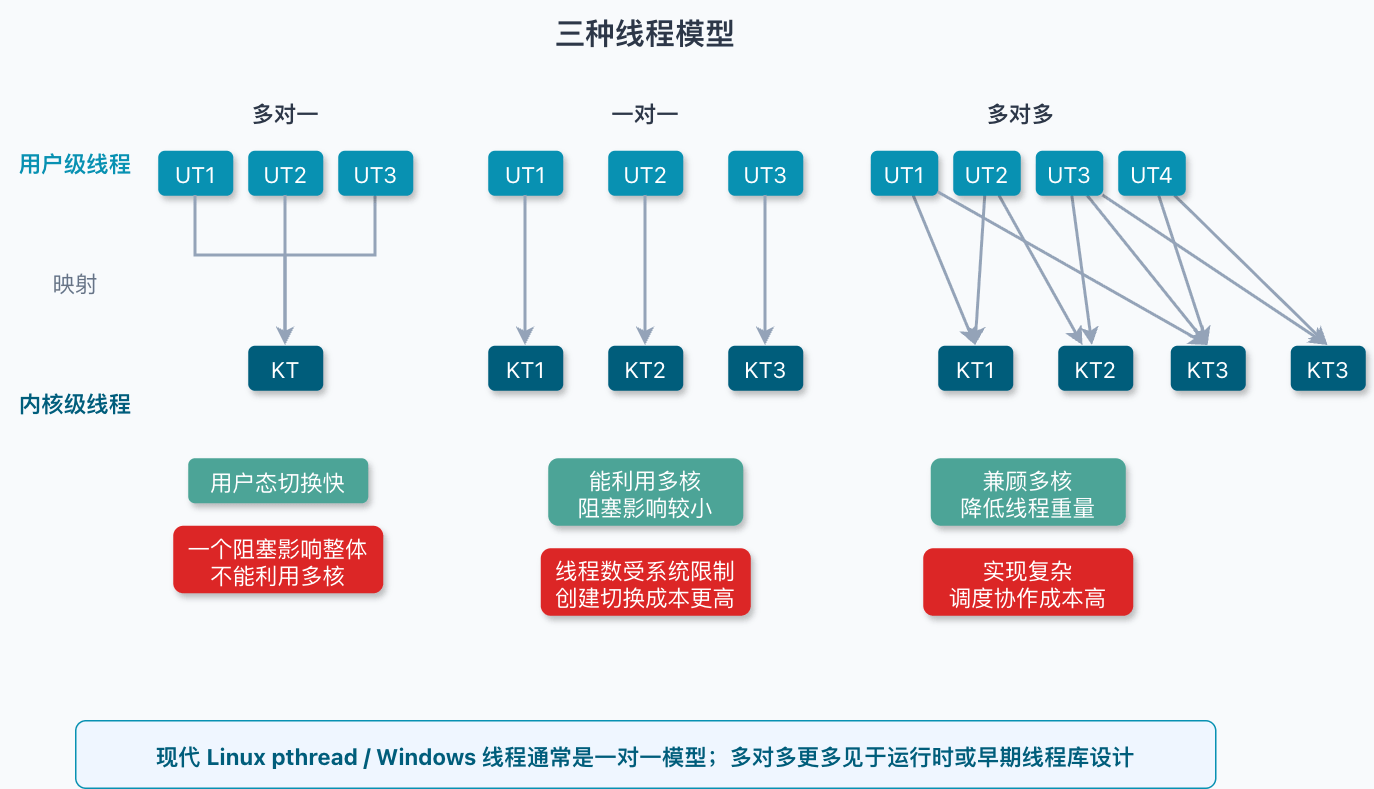
| 模型 | 含义 | 优点 | 主要问题 |
|---|---|---|---|
| 多对一 | 多个用户线程映射到一个内核线程 | 用户态切换快,实现成本低 | 一个阻塞可能影响整体,不能充分利用多核 |
| 一对一 | 一个用户线程映射到一个内核线程 | 能利用多核,阻塞影响较小 | 线程数量受系统资源限制,创建和切换成本更高 |
| 多对多 | 多个用户线程映射到多个内核线程 | 在灵活性和并行能力之间折中 | 运行时和调度实现更复杂 |
Linux 的 POSIX 线程和 Windows 系统线程基本属于一对一模型。Linux 的 pthread_create() 底层会使用 clone(),并由 CLONE_VM、CLONE_FILES、CLONE_FS、CLONE_THREAD 等标志决定共享哪些资源。Linux 上进程和线程并不是两套完全割裂的创建机制,而是 clone() 参数不同带来的资源共享差异。
线程上下文切换和进程上下文切换有什么不同?
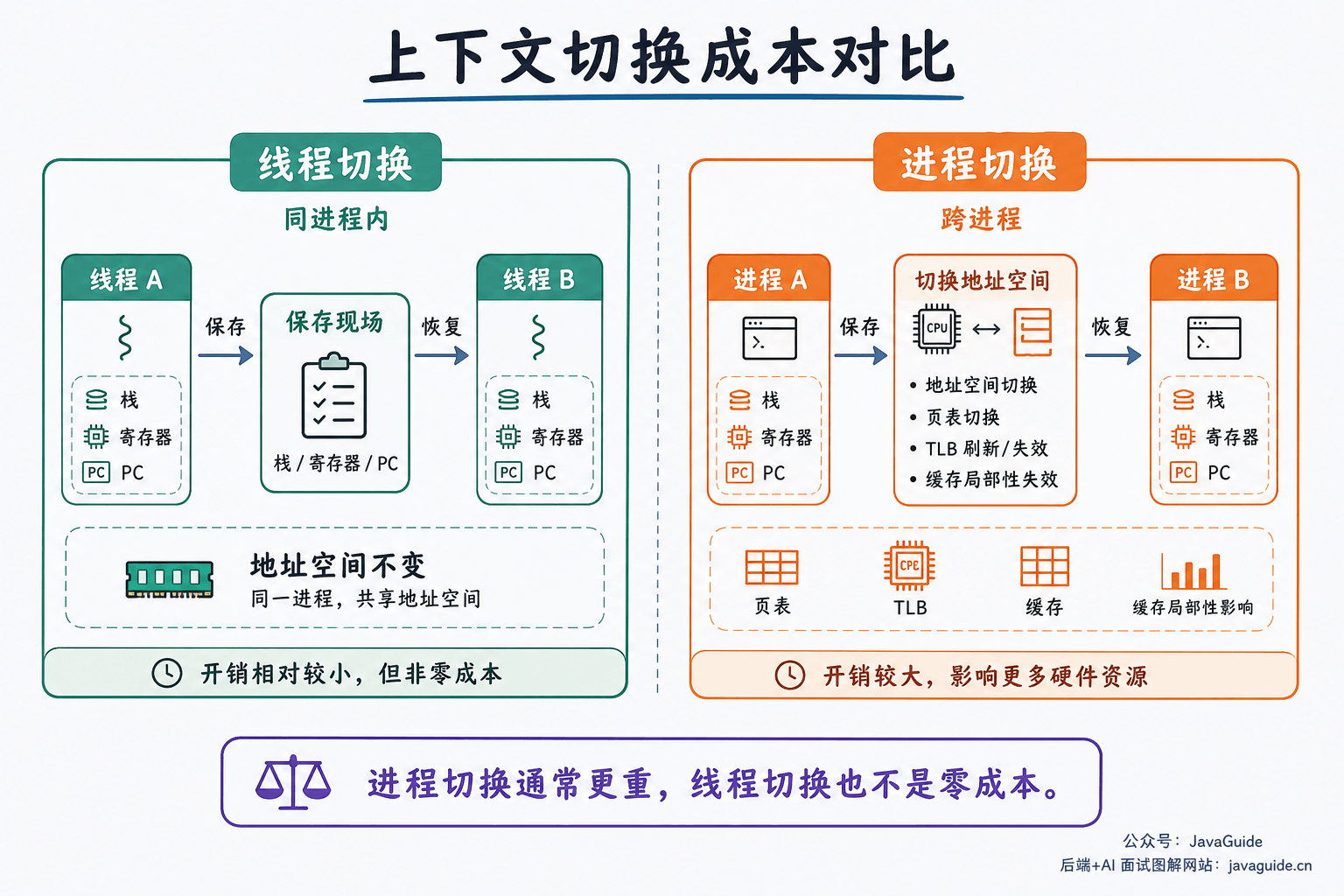
上下文切换指 CPU 从一个执行实体切到另一个执行实体。操作系统需要保存当前实体的寄存器、程序计数器、栈指针等现场,再恢复下一个实体的现场。
线程切换和进程切换都会有开销,但进程切换通常更重。原因是进程有独立地址空间,切换时可能涉及页表切换、TLB 失效、缓存局部性下降等成本;同一进程内的线程共享地址空间,切换时通常不需要换整套内存映射。
可以把它简化成两句话:同一进程内的线程切换,主要换线程自己的栈、寄存器、程序计数器等执行现场;跨进程切换除了换执行现场,还可能切换地址空间,并带来 TLB 和缓存局部性的影响。
不过,线程切换也不能只看成“保存几个寄存器”。跨核迁移、锁竞争、缓存行来回失效、线程数量远大于 CPU 核数时,线程调度照样会消耗很多 CPU。性能分析里如果看到大量时间花在调度、锁等待、系统调用和上下文切换上,继续加线程往往只会让情况更差。
纤程、协程和虚拟线程算线程吗?
纤程(Fiber)和协程通常运行在用户态,由应用或运行时调度。操作系统真正调度的是承载它们的内核线程,而不是每一个纤程或协程。因此,这类轻量执行单元切换时通常不需要陷入内核,成本可以更低。
但它们不是“免费线程”。如果运行时没有把阻塞 I/O 改造成可挂起、可恢复的形式,一个用户态任务阻塞住承载线程,同一承载线程上的其他任务也会受影响。另外,不同语言、运行时、CPU 架构和调用栈深度都会影响切换成本,不能把某个基准测试里的纳秒数字当成通用结论。
Java 21 引入的虚拟线程就是一个典型例子。它仍然是 java.lang.Thread,但不会长期独占一个操作系统线程。虚拟线程运行时会挂载到平台线程(platform thread)上,平台线程再对应底层的系统内核线程;当虚拟线程执行 JDK 支持的可挂起阻塞 I/O 时,JDK 可以先把它卸载下来,让这个平台线程去运行别的虚拟线程。
所以,虚拟线程适合大量“等 I/O”的任务,比如高并发请求、数据库访问、远程调用等。它提升的是并发承载能力和吞吐扩展性,不是让一段 CPU 计算代码跑得更快。CPU 密集型长任务仍然要看 CPU 核数、计算量和调度开销,不能无限量丢给虚拟线程。
虚拟线程、平台线程和系统内核线程的关系:
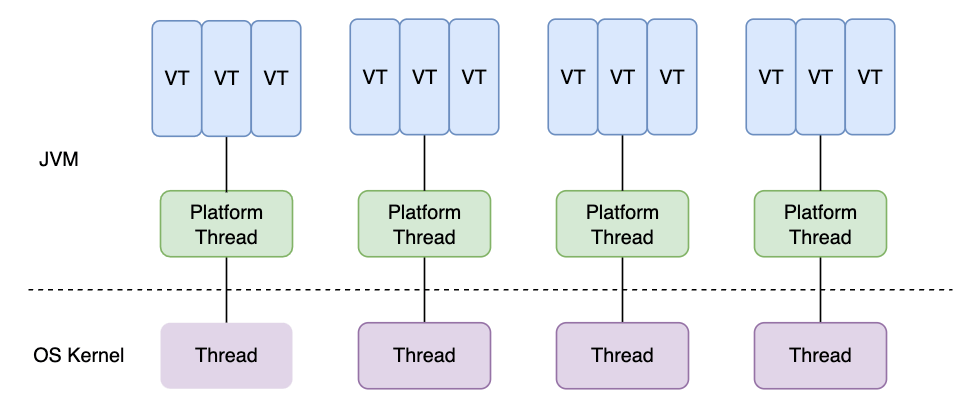
还要注意 pinning。以 Java 21 为例,虚拟线程在 synchronized 块/方法、native 方法或 foreign function 中执行阻塞操作时,可能无法从承载它的平台线程上卸载,结果就是平台线程也被一起占住,不能去运行其他虚拟线程。少量、短时间的 pinning 不会让程序出错,但频繁、长时间的 pinning 会影响扩展性。后续 JDK 对 synchronized 相关的 pinning 做过改进,实际判断时要以当前使用的 JDK 版本为准;native/foreign 调用这类边界仍然需要额外留意。
进程和线程的区别怎么总结?
面试里可以从资源、调度、通信、开销、可靠性 5 个角度答。
| 维度 | 进程 | 线程 |
|---|---|---|
| 基本定位 | 资源分配和隔离的基本单位 | CPU 调度和执行的基本单位 |
| 地址空间 | 默认独立 | 同一进程内共享 |
| 私有内容 | PID、地址空间、资源表等 | 栈、寄存器、程序计数器、TLS 等 |
| 通信方式 | 需要 IPC,如管道、Socket、共享内存 | 可直接读写共享内存,但要同步 |
| 创建/切换成本 | 通常更高 | 通常更低 |
| 故障影响 | 隔离性更好,一个进程崩溃通常不影响其他进程 | 一个线程崩溃可能导致整个进程退出 |
比较完整的回答可以这样组织:
进程是程序运行时的资源容器,拥有独立虚拟地址空间和文件、权限等资源;线程是进程内的执行流,多个线程共享进程资源,但各自保存栈、寄存器、程序计数器等执行现场。进程间隔离更强,通信和切换成本更高;线程间协作更方便,创建和切换通常更轻,但共享内存带来线程安全问题,一个线程出错也可能影响整个进程。
常见误区
误区一:进程并行,线程并发。
并发和并行描述的是执行关系,不是进程/线程的固定属性。单核上多个进程或线程都只能并发;多核上多个进程或线程都可能并行。
误区二:线程越多,性能越好。
线程适合掩盖 I/O 等待,也能利用多核;但线程过多会带来栈内存、调度、锁竞争和缓存失效。CPU 密集型任务通常更接近“核心数附近”的线程配置,I/O 密集型任务才可能需要更多并发执行单元。
误区三:进程之间完全不能共享内存。
默认隔离不等于不能共享。共享内存就是专门让多个进程映射同一块物理内存的 IPC 方式,只是程序员需要自己处理同步和生命周期。
误区四:Java 虚拟线程就是操作系统线程。
平台线程通常是 OS 线程的薄封装;虚拟线程由 Java 运行时调度,会挂载到平台线程上执行。它们都表现为 Thread,但资源模型和调度方式不同。