AI Agent 记忆系统:短期记忆、长期记忆与记忆演化机制

长任务一跑起来,很快就会撞到几件硬约束:上下文窗口有上限,Token 账单会一路涨,Session 结束后如果没有落库,上一轮轨迹默认就跟进程一起消失。很多时候不是模型不够聪明,而是它没有一套能挂载历史记录的记忆层。
记忆层要解决两件事:当前这轮对话里,关键事实别丢;隔几天再开一个新 Session 时,还能把与用户相关的偏好、背景和历史决策捞回来。下面会按记忆的表征和功能分类、读写生命周期、短期和长期实现、主流产品与检索优化、Markdown 记忆这几条线展开。滑动窗口怎么裁、overload 怎么卸,和同站的 《上下文工程实战指南》 有交集,两篇可以对着看。
这篇文章会把 Agent 记忆系统拆开讲清楚。文章比较长,接近 1.1w 字。看完之后你能搞懂这些问题:
- 记忆的存储形式和功能分类;
- 短期记忆与长期记忆分别怎么落地;
- LETTA、ZEP、MemOS 这些产品有什么差异;
- 反思、遗忘、混合检索这些机制该怎么做;
- 为什么 Markdown 也可以作为一种轻量级记忆载体。
Agent 的记忆系统是如何设计的?

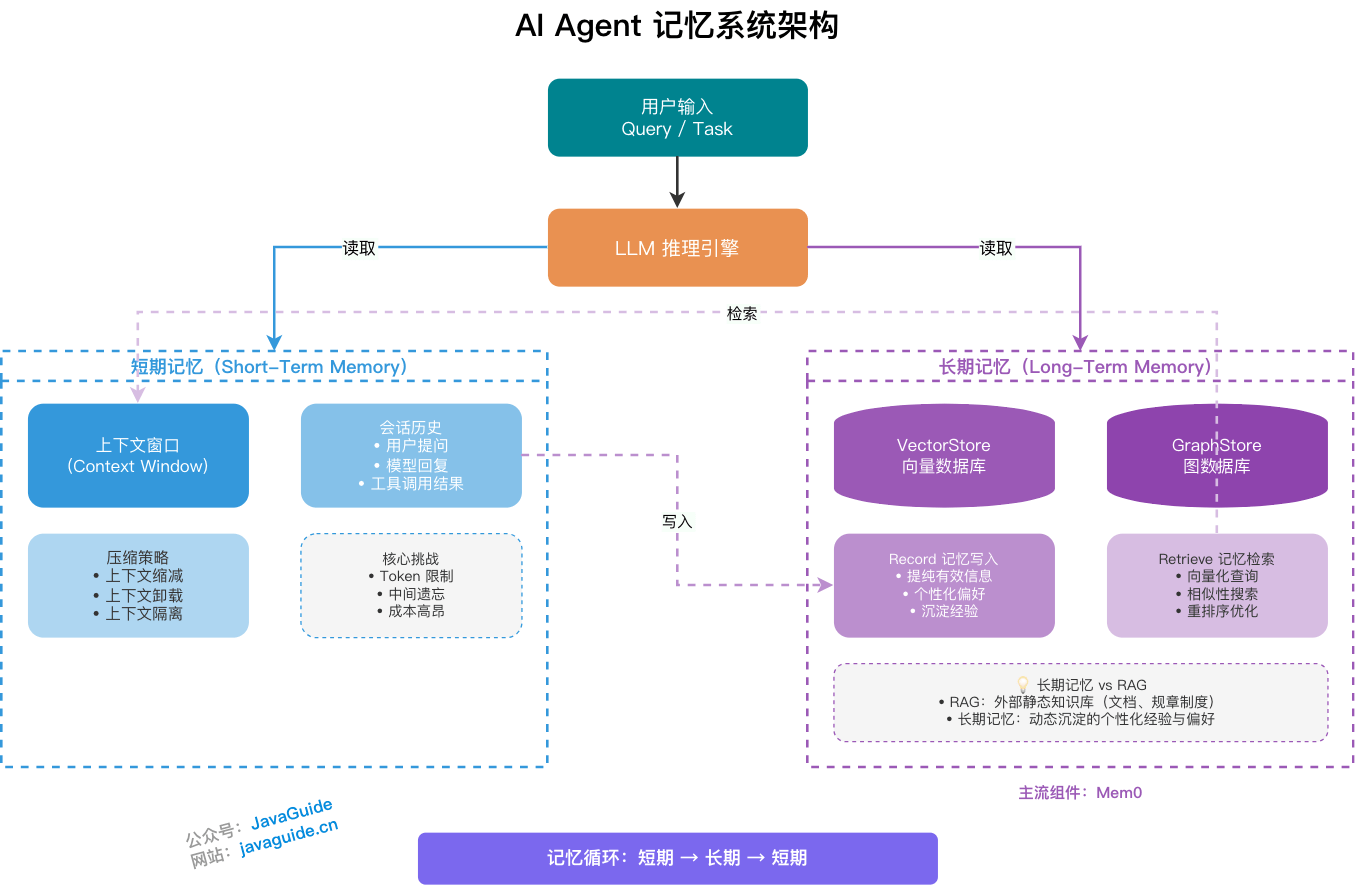
记忆系统通常分两层:短期记忆和长期记忆。短期记忆是 Session 级的,服务当前任务;长期记忆是跨 Session 的,负责把用户偏好、历史决策、过往经验沉淀下来。两者在物理和逻辑上都应该分开,不要混成一锅。
记忆有哪些存储形式?
除了按时间维度拆,记忆还可以按存储位置和表征形式分成三类。
| 存储形式 | 说明 | 典型实现 |
|---|---|---|
| Token 级记忆 | 以自然语言或离散符号形式存储在外部数据库 | 向量库中的文本块、结构化 JSON |
| 参数化记忆 | 将信息编码进模型参数中 | 预训练知识、LoRA 适配器、SFT 微调 |
| 潜在记忆 | 以隐式形式承载在模型内部表示中 | KV Cache、激活值、Hidden States |
这三种形式不是完全割裂的。MemOS 提出的“记忆立方体”框架就支持从纯文本记忆,到激活记忆(KV Cache),再到参数记忆的动态流转。简单说,就是把经常用的热记忆放到更近的位置,把稳定、长期的冷记忆用更重的方式固化下来。
记忆在功能上如何分类?
按功能目的看,Agent 记忆可以分成三类。
| 功能类型 | 核心问题 | 存储内容 | 典型场景 |
|---|---|---|---|
| 事实记忆 | 智能体知道什么 | 用户偏好、环境状态、显式事实 | 记住用户的技术栈偏好 |
| 经验记忆 | 智能体如何改进 | 过往轨迹、成败教训、策略知识 | 从失败的代码审查中学习 |
| 工作记忆 | 智能体当前思考什么 | 当前推理上下文、任务进展 | 多步推理中的中间状态 |
按内容性质还可以继续细分:
- 情景记忆(Episodic Memory):记录特定时间、场景下的具体事件,回答 “What happened?”。例如:“上周三用户反馈订单超时问题”。
- 语义记忆(Semantic Memory):从多个情景中提炼出的通用知识、事实或规律,回答 “What does it mean?”。例如:“该用户对性能问题的敏感度高于功能需求”。
- 程序记忆(Procedural Memory):存储技能、规则和习得行为,让 Agent 能自动执行某类任务序列,而不是每次重新推理。例如:“处理该用户的代码审查时,优先检查 OOM 风险”。
记忆操作的生命周期是怎样的?
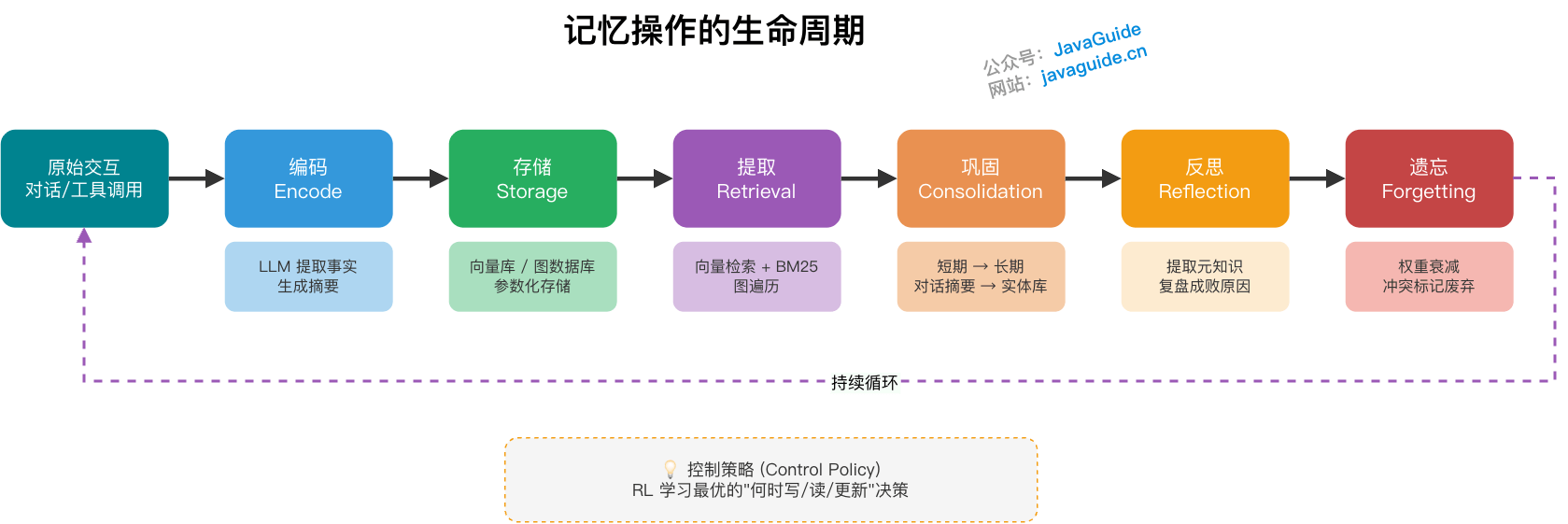
一条记忆从进入系统到最终被淘汰,一般会经历这些环节。不同论文里的名字会有差异,但语义基本能对上。
编码(Encode) → 存储(Storage) → 提取(Retrieval) → 巩固(Consolidation) → 反思(Reflection) → 遗忘(Forgetting)| 操作 | 说明 | 工程实现 |
|---|---|---|
| 编码 | 将原始交互转化为可存储的结构化信息 | LLM 提取事实三元组、生成摘要 |
| 存储 | 将编码后的信息持久化 | 写入向量库 / 图数据库 / 参数 |
| 提取 | 根据上下文检索相关记忆 | 向量检索 + BM25 + 图遍历 |
| 巩固 | 将短期记忆转化为长期记忆 | 异步任务:对话摘要 → 实体库 |
| 反思 | 主动回顾评估记忆内容,优化决策 | 任务完成后提取 Meta-Knowledge |
| 遗忘 | 淘汰低价值或过时记忆 | 权重衰减 + 冲突标记废弃 |
除了“存什么”“存哪儿”,更难的是何时写、何时读、何时更新。最简单的做法是每轮对话结束后都跑一次提取,把结果写进长期库。但这样很容易写入大量噪音,向量库很快塞满低价值碎片。另一端是让策略网络通过强化学习决定读写节奏,理论上能减少无效写入,但训练成本高,解释性也差,实际落地仍然更依赖可观测回放和离线评估。
多数团队会在两者之间找平衡:用简单规则先筛一遍,比如 importance 高于某个阈值才写入;再用离线 batch job 做冲突检测、合并和清理。这种做法不花哨,但更容易控制。
什么是短期记忆(Short-Term Memory / Working Memory)?
短期记忆是 Agent 在当前单次会话中持有的暂存信息,包括用户提问、模型每轮回复、工具调用的中间结果(Observations)。这些内容会直接进入当轮 Prompt,是当前任务状态的主要载体。宿主机侧的隐藏状态、state JSON 如果存在,也应该和这条叙事对齐。
短期记忆主要依托 LLM 自身的上下文窗口。主流模型窗口已经越做越大:GPT-5 支持 400K Token,Claude Sonnet 4.6 支持 1M Token,Gemini 3 Pro 支持 1M Token,Llama 4 Scout 支持 10M Token,Grok 4 支持 2M Token(截至 2026 年数据)。不过上下文窗口是高频变更指标,这些数字最好以各模型官方 model card 或 API 文档的最新发布为准。
窗口大,不等于可以无限塞上下文。推理成本会随 Token 数线性增长。《Lost in the Middle》研究也表明,在多文档检索型任务中,模型更容易利用上下文首尾的信息,中间段的信息利用率明显更低。窗口越长,这种位置偏差越明显,所以上下文工程里要主动控制输入信息的分布。

为了控制短期记忆膨胀,框架层常见三种做法,和上下文工程里的 Token 降级、JIT 卸载属于同一类思路。
第一种是上下文缩减(Context Reduction)。当对话历史达到预设 Token 阈值时,框架自动丢弃最早的 N 轮消息,也就是滑动窗口;或者调用轻量模型把历史对话压缩成摘要,用信息损耗换上下文空间。
第二种是上下文卸载(Context Offloading)。工具或 Skill 调用可能返回很大的数据,比如完整网页 HTML、CSV 文件内容。这时可以把重型结果放到外部临时存储里,Prompt 里只保留一个短引用,比如 UUID 或文件路径。模型需要深挖细节时,再通过强制关联的 Function Calling 调内部工具读取。这里一定要配防雪崩策略:读取超时或文件超限时,工具要主动返回截断或降级结果。
第三种是上下文隔离(Context Isolation)。多智能体架构里,主 Agent 给子 Agent 分配任务时,只传递精简任务指令和必要上下文片段,不要把完整对话历史广播给每个子 Agent。这是控制多 Agent 系统总 Token 消耗的关键做法。
什么是长期记忆(Long-Term Memory)?
长期记忆是活在 Session 之外的持久化知识库。它不会随着对话结束消失,而是通过“写入-检索”机制,让 Agent 在新的 Session 里还能拿到之前沉淀的偏好、事实和历史决策。
长期记忆可以理解成 Record & Retrieve 两条链路。
记忆写入(Record)通常发生在对话结束后。框架触发后台异步任务,调用 LLM 对本轮短期记忆做语义提纯:过滤冗余对话噪声,抽取高价值结构化事实,比如“用户的技术栈偏好为 Python + FastAPI”“用户的汇报对象是 CFO,需要非技术化表达风格”,再写入持久化存储。
这条写入链路最好按尽力而为(Best-Effort)来设计。LLM 抽取可能漏掉关键事实,也可能把假设性陈述误写成偏好。写入操作本身还要有幂等 Key,避免重试产生重复记忆。LLM 抽取场景下,幂等 Key 更适合基于源消息 ID + 抽取批次 ID,而不是抽取结果文本,因为温度采样或 Prompt 微调可能导致语义相同但字面不同,字符串哈希并不可靠。多端并发对话时,实体库合并和覆盖还要引入乐观锁或版本控制(MVCC)。
记忆检索(Retrieve)通常发生在新 Session 开始时。系统把用户 Query 向量化,再和长期记忆库里的条目做语义相似性检索,将命中率最高的一批条目 prepend 进 System Prompt 或放进平行 slot。首包路径上跑一次向量检索很常见,但 VectorStore 的 P99 会直接吃进 TTFT。常见缓解方式是用 Redis 做预热线,或者把浅层偏好、静态画像全量预载,深度记忆再走异步精排,或者和生成流水线重叠,把等人感压下去。
长期记忆和 RAG 有什么区别?

长期记忆和 RAG 技术上很像,都会用向量库和语义检索。但它们服务的对象不一样。
RAG 挂载的是共享知识源,比如公司规章、产品文档、实时数据库查询结果。这些内容和“谁在使用”没有强绑定,对不同用户通常返回同一套知识库内容。RAG 的核心特征是非个性化,而不是一定静态,实时数据库查询结果也可以接入 RAG。
长期记忆管理的是 Agent 与特定用户交互中动态沉淀的个性化经验,比如用户偏好、习惯、历史决策、专属背景。它高度个性化,因人而异。
两者不是二选一。RAG 提供世界知识,比如公司规章、产品文档;长期记忆提供用户画像,比如偏好、习惯、历史决策。检索阶段可以分别召回再融合排序;长期记忆里的实体也可以作为 RAG 检索的 query 扩展;用户偏好还可以作为 RAG 结果的个性化重排信号。
主流的记忆技术架构有哪些?
长期记忆会涉及向量化存储、语义检索和记忆管理。逻辑一复杂,很多团队就会把它拆成独立组件,不再和主 Agent 流程揉在一起。
底层存储架构通常包含哪些层级?
底层架构通常分三层。
VectorStore 负责向量存储。它把提取出来的记忆文本转成 Embeddings,再存进向量数据库。以单节点 Qdrant 1.x 版本、本地 SSD、HNSW 索引 ef=128、Recall@10 ≥ 0.95 为基准,在低并发场景(如 QPS 小于 50)下,P99 延迟可以控制在数十毫秒级。不同产品在同样 QPS 下 P99 差异可能达到 5-10 倍,比如 Pinecone Serverless、自建 Qdrant、Milvus 之间就会有明显差异。实际选型最好参考 ann-benchmarks.com 或各厂商 benchmark 报告。常见方案包括 Pinecone、Weaviate、Chroma、Qdrant 等。
GraphStore 负责图存储。进阶场景里,可以把记忆建模成“实体-关系”形式的知识图谱,比如用 Neo4j。它更适合需要多跳推理的复杂查询,比如“用户提到的同事 A 和项目 B 之间有什么关联”。
Reranker 负责重排序。向量检索只是初步召回,语义相关性并不总是精确有序。Reranker 通常基于交叉编码器(Cross-Encoder)对候选结果做二次精排,把更相关的记忆排到前面,减少无关内容进入上下文。
向量库选型时,下面几个维度很关键:
| 维度 | 关键考量 | 说明 |
|---|---|---|
| 索引类型 | HNSW / IVF / DiskANN | 影响召回率与延迟的 tradeoff |
| 元数据过滤 | pre-filter vs post-filter | 高过滤率场景下 pre-filter 易破坏图结构连通性 |
| 多租户隔离 | Namespace / Collection / 物理隔离 | 影响召回率与数据安全 |
| 持久化一致性 | 强一致 vs 最终一致 | 影响写入可靠性 |
| 成本模型 | Serverless 按量 vs 自建集群 | 影响运营成本 |
LLM 做事实抽取时,失败模式也要提前想清楚。它可能漏掉关键事实,也可能把假设性陈述固化成偏好。工程上可以做几层防护:用 JSON Schema 强约束输出,并配重试机制;用 LLM-as-Judge 做二次校验,低置信度结果不写入;在 Prompt 里加“假设性语句识别”,比如 “I might...” 这类陈述不要固化;高 importance 记忆进入人工 Review 队列;同时保留原始对话和抽取结果的审计日志,便于回溯。
主流 Memory 产品如何对比?
下面这张表主要看几个公开项目或产品各自强调什么,不等于直接选型结论。最后还得看你自己的延迟要求、合规要求和数据形态。
| 产品 | 核心思想 | 技术亮点 | 适用场景 |
|---|---|---|---|
| Mem0 | 单次 ADD-only 抽取 + 多信号融合检索 | 单次 LLM 调用完成实体抽取与跨记忆链接;语义 + BM25 + Entity Linking 并行打分;通过可选的 GraphStore 后端启用图记忆(Mem0g) | 通用对话记忆 |
| LETTA(原 MemGPT) | 操作系统虚拟内存分页 | Main Context ↔ External Context 动态交换;递归摘要压缩 | 长对话上下文管理 |
| ZEP | 时间感知知识图谱 | 自研 Graphiti 引擎;情景/语义/社区三层子图;边失效机制 | 企业级多租户场景 |
| A-MEM | Zettelkasten 知识管理 | 卡片笔记法;记忆间自动建立语义连接 | 知识密集型任务 |
| MemOS | 三种记忆类型动态转换 | 纯文本 ↔ 激活记忆(KV Cache)↔ 参数记忆(LoRA) | 全栈记忆管理 |
| MIRIX | 六模块分工协作 | 元记忆管理器路由;不同记忆组件采用不同存储结构 | 复杂决策支持 |
LETTA、ZEP、MemOS 有什么不同?
LETTA 把上下文想成操作系统里的页。Main Context 放系统指令和当前工作台,FIFO 顶住最新消息;顶不住时,就把旧段落递归摘要后换到 External Context。这个思路很好理解,但它是一条有损路径。递归摘要多轮以后,精确密钥字面量、报错栈、小数点后几位这种细节很容易先被洗掉。看起来像“失忆”,其实是压缩带来的副作用。
ZEP 在图上加了三层粒度:情景子图咬住原始 payload,语义子图抽实体关系,社区子图把强连接聚成大块摘要。这个思路和 GraphRAG 的社群层有相似之处。ZEP 更值得借鉴的是边失效机制:新事实和旧边时间重叠时,标记旧边失效并打时间戳。这样既能追新事实,也方便审计旧判断。
MemOS 则在论文和宣传里画了“文本 → KV Cache(激活)→ LoRA(参数)”这条梯度。热条目预灌 cache 可以降低冷启动延迟;如果想把记忆固化成权重,就要走离线 SFT,这会变成一笔单独的训练账单。
这里有个很现实的限制:LoRA 写进去之后不好删。向量库删一行就行,但参数里抠掉某条事实,本质上会碰到 Machine Unlearning 还没完全铺好的深水区。所以参数记忆只适合变化很慢的偏好。多租户场景下,还要依赖 vLLM / TGI 这类支持动态挂载、卸载 adapter 的运行时。
纯文本记忆 ──(高频使用)──→ 激活记忆(KV Cache) ──(长期固化)──→ 参数记忆(LoRA)
↑ │
└──────────────(知识过时/卸载)─────────────────────────────┘记忆的高级演化机制有哪些?
只会写入和检索还不够。生产级 Agent 系统还需要一套代谢机制,让记忆能被反思、合并、清理和遗忘,否则库越大,噪声也越大。
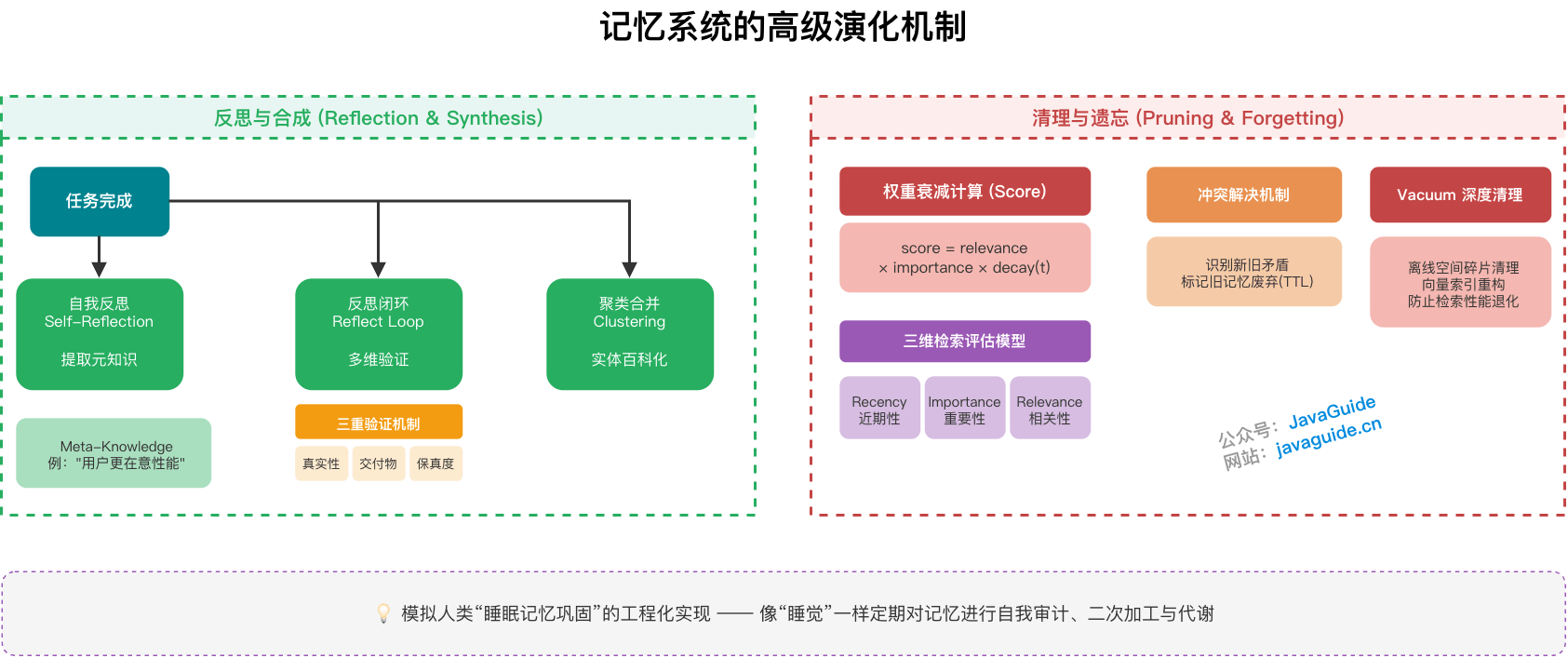
记忆反思与合成如何实现?
如果系统只是 append,长期记忆很快会变成流水账。真正有价值的,是从流水账里提炼出可复用的规则、偏好和教训。
生产系统里通常会加一层离线或准实时的自省任务。
第一类是自我反思(Self-Reflection)。任务完成后,Agent 启动异步任务,复盘本次任务的成败原因,把“教训”提取成一条 Meta-Knowledge。这一机制最早由 Park et al.(2023)的《Generative Agents》系统化提出,可以看作模拟人类“睡眠记忆巩固”的工程化实现。
例如:“在处理该用户的 Java 代码审查时,他更在意性能而非规范,未来应优先关注 OOM 风险。”
第二类是精细化反思闭环(Reflect Loop)。2025-2026 年的一些前沿框架,比如 MUSE,已经把反思机制演化成更细的“规划-执行-反思-记忆”闭环。反思不再只发生在任务完成后,而是在每个子任务结束时触发。独立的 Reflect Agent 会对子任务输出做三重验证:真实性验证,检查输出是否符合客观事实;交付物验证,检查是否完成用户指定目标;数据保真性验证,检查关键数据在传递中有没有丢失或变形。
这种细粒度反思能减少错误在多轮推理里持续放大。不过它也会带来额外成本,不适合所有任务都开满。对低风险、低价值任务来说,过度反思反而可能得不偿失。
第三类是记忆聚类与合并(Clustering & Consolidation)。当长期记忆里出现大量碎片化、重复记录时,比如用户 10 次提到同一个项目背景,系统可以自动触发合并任务,把这些碎片整理成更完整的“实体百科”。这样既能减少向量库冗余,也能提升检索一致性。
记忆的清理与遗忘机制是怎样的?
记忆不是越多越好。无用噪声和过时信息会严重干扰 LLM 判断。
一种常见做法是权重衰减。系统为每条记忆维护综合得分:
score = relevance × importance × decay(t)其中 decay(t) 通常取指数形式,比如 e^{-λt}。这套机制来自《Generative Agents》提出的三维检索模型。实际工程里,不建议每次在向量库里对全量记忆计算时间衰减,更稳的做法是向量库先做静态语义召回,再在 Reranker 阶段实时应用动态调整。
另一种做法是冲突解决。新事实和旧事实矛盾时,比如用户去年用 Java 8,今年升级到 Java 21,旧记忆应该标记为废弃。注意,主流向量库的软删除可能破坏 HNSW 图结构连通性,所以还需要定期执行 Vacuum 任务清理和重建。
这点很多团队一开始会低估。大家舍不得“遗忘”,觉得信息存着总比丢了好。结果向量库里堆了几十万条记忆,每次 Top-K 里混着一堆过时噪音,Agent 给出的建议还停留在三年前。这个体验非常糟糕,而且很难靠调 Prompt 补回来。
如何优化长期记忆的检索效果?
在 VectorStore 和 GraphStore 之外,生产环境通常还需要一层混合检索策略。
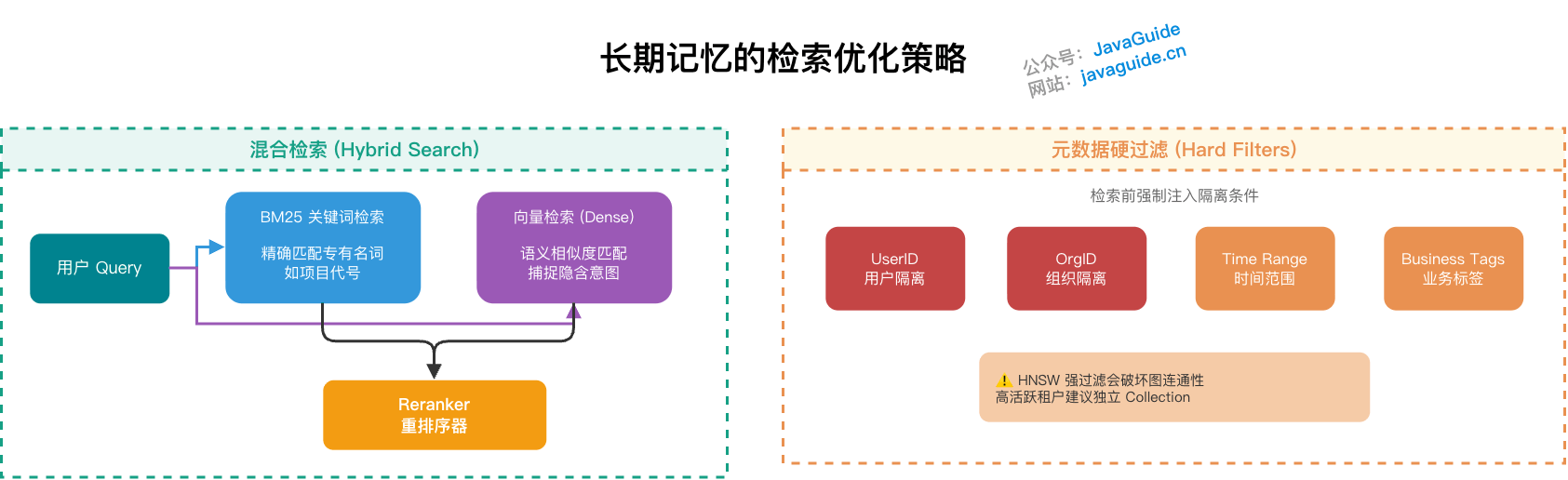
混合检索与元数据过滤怎么做?
单纯依赖向量检索,容易产生“虚假关联”。Dense Retrieval 看的是语义相似度,有时会把听起来相近、但业务上没关系的内容召回来。
混合检索(Hybrid Search)会结合关键词检索(BM25 / Sparse)和语义向量检索(Dense)。不同 query 类型可以动态调整权重,比如专有名词查询加大 BM25 权重,模糊意图查询加大向量权重。常见融合方式有几种:
- RRF(Reciprocal Rank Fusion):几乎不用调参,适合冷启动,按排名倒数加权融合。
- Linear weighted(
α·dense + (1-α)·sparse):可调,但需要标注数据校准权重。 - Cross-encoder Reranker:召回阶段取并集,精排阶段统一打分,对长尾 query 更有帮助。
元数据硬过滤(Hard Filters)也很重要。向量检索前,先基于 UserID、组织 ID、时间范围、业务标签做硬过滤,这是多租户场景下最关键的数据隔离手段。如果缺少这层隔离,“张三的偏好被推给李四”就不是效果问题,而是隐私合规事故。更稳的做法是在数据访问层强制注入隔离条件,不依赖调用方手动传参。
这里也有工程取舍。基于 HNSW 的向量库里,如果在海量图谱中对少数租户标签做强过滤,可能破坏图结构连通路径,导致召回率明显下降。对于高活跃核心租户,分配独立 Collection 做物理隔离往往更稳。
为什么检索链路优化往往先于写入策略?
检索链路优化的 ROI 通常高于写入链路。
Mem0 在 LoCoMo 上达到 91.6,较旧算法 +20 分;LongMemEval 上达到 93.4,+26 分;BEAM (1M) 上达到 64.1;每次检索约消耗 7K Token,对比全上下文方案的 25K+ 更省。详见 Mem0 官方 benchmark。
很多时候你感觉“记忆没用”,并不是写入阶段完全失败,而是 Recall 跑偏,或者精排没有把真正相关的内容顶上来。优先看 trace 里的 query、过滤条件、融合权重,再决定要不要给提取链路加预算。别一上来就狂加写入逻辑,那很可能只是把噪声写得更快。
生产级记忆系统架构要关注哪些要点?
真正上生产时,要盯住的不只是“能不能记住”,还包括召回精度、合规、性能和成本。
| 维度 | 核心问题 | 解决方案 |
|---|---|---|
| 多维索引 | 召回精度 | Vector + Graph + Keyword 三种索引结合 |
| 隐私合规 | GDPR 等法规 | 写入前做 PII 脱敏 |
| 冷热分离 | 性能与成本 | 高频偏好缓存 + 低频背景 RAG |
表上每一项背后都是成本。多套索引意味着更高的维护负担,PII 策略需要法务过一遍,冷热边界也很容易在团队里来回争。没到多租户体量之前,单向量链路先把写入幂等、检索 trace、rerank 跑顺,通常更划算。
如何用 Markdown 存储 Agent 记忆?
向量链路太重时,还有一个很土但好用的办法:把 Agent 需要记住的东西写进仓库里的 Markdown。没有 embedding 也没关系,只要信息量可控,并且可读性比语义检索更重要,这条路就能成立。
为什么 Markdown 可以作为 Agent 记忆?
Markdown 可以看成人机共写的明文长期记忆。不强制上向量检索,只靠目录组织,以及 Claude Code 里的 @ / rules 机制,也能跑起来。
它省掉的是可见性和运维成本:
- 透明可审计:随时打开文件,就能看到 Agent 记住了什么、写入了什么,没有黑盒。
- 持久化:文件存在磁盘上,不依赖进程生命周期。进程崩溃、重启、换机器,记忆都在。
- 版本控制:记忆可以提交到 Git,回滚、分支、Code Review 都很自然。
- 零迁移成本:标准格式,没有供应商锁定。换模型、换框架时,复制文件即可。
- 成本低:托管向量数据库和完整 RAG pipeline 的成本、运维复杂度都不低,Markdown 本地文件几乎没有额外成本。
Manus 把文件系统视为结构化外部记忆;Claude Code 把 CLAUDE.md 和 Auto Memory 产品化;OpenClaw 等 Agent 项目和社区实践中,也能看到类似的文件化记忆思路。它们都说明,在不少 Agent 场景里,文件系统 + Markdown 已经是足够务实的长期记忆方案。
Claude Code 的 CLAUDE.md 机制是怎样的?
Claude Code 的记忆系统采用双轨制:人工编写的 CLAUDE.md,以及自动积累的 Auto Memory。
CLAUDE.md 里该写什么、不该写什么?
官方建议每个 CLAUDE.md 控制在 200 行以内。超过这个限制会降低 Claude 的指令遵守率。通过 @ 引用拆分文件可以改善可维护性,但不会减少上下文消耗,因为被引用文件在启动时会全量加载。如果指令很长,优先使用 .claude/rules/ 目录的 path-scoped rules,只在编辑匹配路径时加载对应规则。
可以把 CLAUDE.md 理解成给 AI 新人的 onboarding 文档。写得不好还不如不写,因为臃肿的 CLAUDE.md 会把真正重要的规则淹掉。
适合写进去的内容有几类。技术栈和版本信息很重要,框架版本差异往往是 AI 犯错的源头。你不标 Spring Boot 版本,它就容易生成训练数据中更常见的版本用法。常用命令也应该写进去,比如构建、测试、lint、启动,并尽量放在代码块里。代码块里的命令 Claude 更倾向于照着跑,自然语言里的命令它可能会按自己的理解改写。
架构决策和背后的理由也值得写。光写规则不够,解释“为什么”能帮助 Claude 举一反三。比如只写“不要直接写 SQL,使用 QueryWrapper”,不如补上“因为 SQL 审计系统依赖 Wrapper 解析来记录操作日志”。这样它在其他查询场景里也更容易自觉使用 Wrapper。团队约定和项目特有的坑也适合写,比如提交信息格式、分支命名规范、环境变量依赖,这些 Claude 很难单靠读代码推出来,但新入职工程师一定会问。
不适合写进去的内容也很明确:代码风格规则应该交给格式化工具;语言或框架的默认行为,比如现代 Python 用 f-string,这类内容写下来就是噪音;大段参考文档给链接即可,Claude 需要时可以自己去读。
一个判断标准很好用:逐行看 CLAUDE.md,每条都问自己,如果没有这行,Claude 最近是否真的犯过这个错。如果答案是“好像没有”,那它大概率可以删。
怎么写才能让 Claude 真正遵守?
规则要具体可验证。“注意代码可读性”没法验证,“函数名使用动词开头、单个函数不超过 40 行”就可以验证。规则越具体,Claude 遵守的概率越高。
禁令最好搭配替代方案。只说“不要做 X”,Claude 遇到相关场景时可能会卡住。更好的写法是“不要做 X,遇到这种情况做 Y”。例如:
# 依赖注入
- 不要使用 @Autowired 字段注入
- 使用构造器注入,配合 Lombok 的 @RequiredArgsConstructor
- 参考示例:UserController.java 中的写法标记词可以用,但别滥用。如果某条规则 Claude 反复违反,加 IMPORTANT: 或 YOU MUST: 能稍微提高注意力。但整篇文件到处都是“重要”,最后就等于没有重点。
如果 Claude 反复忽略某条规则,不要第一反应就是加感叹号。更大的可能是文件太长,规则被其他内容稀释了。解决方式是精简文件,不是继续加强调。
标题也尽量用常规名字,比如 Commands、Structure、Conventions、Testing。Claude 的训练数据里有大量标准 README 结构,它对这类标题下面通常写什么有稳定预期。
CLAUDE.md 文件的层级结构是怎样的?
| 层级 | 位置 | 作用范围 | 适用场景 |
|---|---|---|---|
| 组织级 | 系统目录,如 /etc/claude-code/CLAUDE.md | 所有用户 | 公司编码规范、安全策略,任何设置都无法排除 |
| 用户级 | ~/.claude/CLAUDE.md | 个人所有项目 | 代码风格偏好、个人工具习惯 |
| 项目级 | ./CLAUDE.md 或 ./.claude/CLAUDE.md | 团队共享 | 项目架构、编码标准、工作流,提交至 Git |
| 本地级 | ./CLAUDE.local.md | 个人当前项目 | 沙箱 URL、测试数据偏好,需手动加入 .gitignore,运行 /init 可自动添加 |
文件加载遵循目录树向上查找规则:从当前工作目录逐级向上。同一目录内,CLAUDE.local.md 会追加在 CLAUDE.md 之后,越靠近工作目录的规则优先级越高。
CLAUDE.md 不适合存大段日志和完整对话记录,也不应该存敏感密钥、Token、账号信息。高频变化的运行时数据、可以实时查询的动态信息,也不适合写进去。
项目变大后,需要做分层管理。一个人的项目,一份 CLAUDE.md 通常够用;团队项目就要拆开。
# `CLAUDE.md`(项目根目录)
## Project
Spring Boot 3.2 + MyBatis-Plus + MySQL 8.0 的订单管理服务。
## Commands
- 构建:`mvn clean package`
- 测试:`mvn test`
## Rules
- API 约定:@docs/api-conventions.md
- 数据库规范:@docs/database-rules.md可以用 @path/to/file 引用外部文件。但要注意,@ 引用最多支持 5 层递归深度。首次在项目中使用外部引用时,Claude Code 会弹出审批对话框。如果误拒,引用会被永久禁用,需要手动重置。@ 引用会把整个文件内容嵌入上下文,被引用文件在启动时全量加载,所以不会减少上下文消耗。
如果需要更细粒度控制,可以用 .claude/rules/ 目录组织 path-scoped rules。它和 @ 引用的区别很关键:rules 只在匹配指定路径时加载,属于按需加载;@ 引用在启动时全量加载。规则只针对特定文件或目录时,比如后端 API 规范、测试配置,优先用 rules,而不是继续往 CLAUDE.md 里堆内容。
---
paths:
- "src/main/java/**/controller/**/*.java"
---
# Controller 规范
- 统一使用 Result<T> 包装返回值
- 所有接口必须添加 Swagger 注解这样编辑 Controller 时只加载 Controller 规则,编辑 Service 时只加载 Service 规则。
AGENTS.md 和 CLAUDE.md 是什么关系?
Claude Code 读取 CLAUDE.md,不是 AGENTS.md。AGENTS.md 更像跨工具开放标准,被 OpenAI Codex、Cursor 等采用。如果仓库已经用 AGENTS.md 给其他编码 Agent 提供指令,可以创建一个导入 AGENTS.md 的 CLAUDE.md,让两个工具复用同一份基础指令,不用重复维护。
@AGENTS.md
## Claude Code 特定指令
- 使用 plan mode 处理 `src/billing/` 下的改动Auto Memory 是什么?
Auto Memory 是 Claude 根据对话自动写入的笔记,包括调试模式、代码习惯、工作流偏好。它存在 ~/.claude/projects/<project>/memory/ 目录下,MEMORY.md 是入口文件,细节笔记放在子文件中。
这里有几个使用限制要记住。MEMORY.md 只加载前 200 行或 25KB,超出部分不会被读取,Claude 会把详细内容拆分到 Topic 文件里。经过 20-30 个会话后,Auto Memory 笔记质量可能下降,出现矛盾条目或过时信息累积。社区里有 dream-skill 这类工具能做记忆整合,比如 Orient、Gather Signal、Consolidate、Prune 四阶段,但这不是官方正式功能。
如果要禁用 Auto Memory,除了 /memory 切换和 autoMemoryEnabled 配置,也可以通过环境变量 CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 禁用。CI/CD 场景更适合用这种方式,因为自动化管线没必要让 Claude 积累构建环境笔记。
Auto Memory 需要 Claude Code v2.1.59+,默认开启。
Markdown 记忆如何分层设计?
一个完整的 Markdown 记忆体系通常会分成几个层级:
- 用户级记忆:存个人偏好和长期习惯,放在
~/.claude/CLAUDE.md,比如 2-space 缩进、先写测试再写代码、不喜欢用 emoji。 - 项目级记忆:存项目规范、技术栈、目录结构,放在仓库根目录的
CLAUDE.md,团队成员共享,通过 Git 同步。 - 子目录级记忆:存局部模块的专属规则,放在子目录的
CLAUDE.md,比如backend/下的 API 设计规范、docs/下的写作风格要求。 - 团队共享记忆:需要提交到仓库的共同约定,通常是项目级
CLAUDE.md和.claude/rules/目录下可版本化的规则文件。 - 私有记忆:不应该提交的个人工作流,比如
CLAUDE.local.md,加入.gitignore后只留在本地。
Markdown 记忆和传统长期记忆的边界在哪里?

Markdown 和向量库各有适用边界,不建议一刀切。
| 维度 | Markdown 记忆 | 向量库记忆 | RAG 知识库 | 数据库型框架(Mem0 等) |
|---|---|---|---|---|
| 检索精度 | 全量注入,无检索机制,启动时全部加载 | 高,语义相似度 | 高,语义检索 | 高,混合策略 |
| 上下文成本 | 与文件大小线性相关,大文件会挤占空间 | 按需检索,上下文高效 | 按需检索,上下文高效 | 按需检索,上下文高效 |
| 调试体验 | 极佳,直接读写文件 | 中等,需向量查询工具 | 中等,需检索日志 | 复杂,需理解框架逻辑 |
| 部署成本 | 极低,只需文件读写 | 高,需维护向量服务 | 高,需 RAG pipeline | 高,需框架运行时 |
| 版本控制 | 原生集成 Git | 需额外同步机制 | 需额外同步机制 | 需额外同步机制 |
| 迁移成本 | 零,复制文件即可 | 高,锁定专有格式 | 高,锁定 pipeline | 极高,绑定框架 |
| 适用场景 | 偏好、约定、踩坑记录 | 多样化记忆检索 | 共享知识查询 | 复杂多源记忆管理 |
Markdown 的局限也很明显。当你需要从海量非结构化文本里检索特定片段时,人工组织的 Markdown 会成为瓶颈,这时向量库的语义检索能力不可替代。
反过来,如果记忆需求是“记住这个项目的编码规范”“记住用户的报告偏好”这类明确、可结构化的信息,Markdown 的简洁和可维护性通常比复杂系统更合适。
Markdown 记忆应如何维护?
这里以 CLAUDE.md 为例。CLAUDE.md 不是写完就完事,项目会演进,规则也会过时。
添加规则要慢。一条新规则只有在 Claude 确实犯了一个错误,并且这条规则能防止同类错误再次发生时,才值得写进去。为还没发生过的事情预设规则,往往是在浪费上下文空间。
删规则要果断。如果某条规则存在很久了,但删掉后 Claude 行为没有变化,说明它可能从一开始就没起作用。把空间留给真正需要的规则,比维持一份“看起来很完整”的文件更重要。
规则最好错误驱动地持续进化。每次纠正 Claude 的错误后,可以追加一句“更新 CLAUDE.md,确保下次不再犯”。累积几次同类错误后,再归纳成一条精炼规则,避免文件快速膨胀。
有两个预警信号很值得注意。第一,Claude 为已经写在文件里的规则道歉,比如“抱歉,我刚才忽略了 XX 规则”。这说明规则表述可能不够直接。第二,同一条规则在不同会话中反复被违反。这通常不是措辞问题,而是整份文件太长,规则被稀释了。解决方式不是继续改措辞,而是压缩整份文件。
维护时可以用对话式审查:每隔几周,挑几条 CLAUDE.md 里的规则问 Claude,“如果我删掉这条规则,你会改变行为吗?”如果它说不会,这条规则可能就可以删。
不过这个方法只能当启发式参考,不能完全相信 Claude 的自我评估。Claude 无法准确预测缺少某条规则时自己是否会改变行为。更可靠的做法是先备份规则,实际删除后,在几个真实任务上观察行为有没有变化。
/init 也可以用,但不要直接用。自动生成的 CLAUDE.md 是一个不错的起点,但里面可能有不准确的项目描述。按上面的原则逐条审查,删掉冗余,补上遗漏。
最后,团队共享的记忆更新最好走 Git。每次重要记忆更新都 commit,出问题可以回滚,Code Review 也能追溯修改原因。团队共享内容的修改,建议走 PR 流程。
如何把本文关于记忆的要点串起来?
记忆层要回答的问题很简单:怎么让 Agent 不要每次开新会话都从零开始。
短期记忆靠上下文窗口撑着,滑动窗口、摘要压缩、重型结果卸载是工程侧最常用的三把刀。长期记忆靠“写入-检索”两条链路,让新 Session 启动时也能拿回用户偏好和历史决策。
这篇文章里有几个判断比较值得带走。
短期记忆和长期记忆不是一个功能的两面,而是在物理和逻辑上都应该隔开。短期记忆活在当前任务和进程里,长期记忆应该落在库里。
记忆生命周期里,最容易被忽略的是遗忘。很多团队舍不得删,结果检索召回里全是几年前的过期噪音,Agent 反而变得更不靠谱。
向量库和 Markdown 也不是二选一。偏好、约定、踩坑记录这类信息量有限、对可读性要求高的场景,Markdown 的调试体验很好;但如果要从几十万条非结构化文本里捞相关段落,向量检索仍然不可替代。
CLAUDE.md 不是写得越多越好。每一条规则都应该对应 Claude 真实犯过的错误。如果删掉某条之后 Claude 行为没变,那它可能从来就没起作用。
检索链路优化通常比写入链路更值得优先做。体感“记忆没用”时,十有八九是 Recall 跑偏,或者精排没把真正相关的内容顶上来。先查 trace,再考虑往提取链路加预算。
记忆系统最后要撑住三个问题:Agent 知道什么事实,Agent 从过往任务里学到了什么,Agent 此刻正在处理什么。只有这三层对齐了,“有记忆”才不是一句空话。