什么是 Model Context Protocol (MCP)?和 Function Calling、Agent 什么关系?
做 LLM 应用时,我一开始也以为最麻烦的是模型接入。
后来发现不是。OpenAI、Claude、DeepSeek、Qwen 这些模型虽然接口不完全一样,但各家 SDK 已经把很多细节包掉了,真要接起来并不算特别难。更烦的是工具。
比如同样是“让 AI 读本地文件、查 GitHub、连数据库”,在 Claude Desktop 里要配一套,在 Cursor 里可能又是一套,自己做 Agent 时还得再封一层。工具少的时候还能忍,工具一多,维护成本就开始上来了:参数变了要改,鉴权变了要改,宿主换了还要改。
MCP 解决的就是这类问题。
它不是让模型变聪明,也不是替代 Function Calling,更不是新一代 Agent 框架。它更像一套接线规范:外部系统把能力封装成 MCP Server,支持 MCP 的 AI 应用连接上来之后,就能发现这些能力并调用。
我不太喜欢一上来就把 MCP 吹成“AI 领域的 USB-C”。这个比喻确实好记,但也容易让人误会它什么都能统一。
我更喜欢这个说法:MCP 先解决工具接入这块的重复适配问题。
说明一下:MCP 还在快速演进,本文主要按 2025-06-18 及之后的新版规范口径来讲。比如,2025-03-26 版本把早期 HTTP+SSE 传输调整为 Streamable HTTP;2025-06-18 版本又加入了 Elicitation 等能力。不同客户端、SDK 和旧教程的支持情况不完全一致,实际落地前最好先确认自己使用的客户端和 SDK 版本。
MCP 到底是什么?
MCP 全称是 Model Context Protocol,中文一般叫“模型上下文协议”。
把 MCP 的全称拆开来看,其实就很清晰了:
- Model:面向大模型应用;
- Context:把外部上下文、工具和数据源带给模型;
- Protocol:用一套标准协议把交互方式定下来。
不过,也不要把 MCP 理解成给模型加插件这么简单。之前在星球群里看大家讨论 MCP 的时候,有不少同学都是这样认为的。
更准确一点说,MCP 是 MCP Client 和 MCP Server 之间的通信协议。Host 负责承载用户交互和模型调用,Client 负责和 Server 说话,Server 负责把具体能力暴露出来。
举个很常见的场景。
G 友问:“帮我看看这个项目最近一次提交改了什么。”
你用的模型或者 Agent 当然不知道你本地 Git 仓库的提交记录。它得借助外部能力读取 Git 日志。
没有 MCP 时,每个 AI 应用都得自己定义一套“怎么连 Git 工具、怎么传参数、怎么拿结果”的方式。
有了 MCP 之后,Git 相关能力可以被封装成一个 MCP Server。Host 里的 MCP Client 连上它,先发现有哪些工具,再按协议调用工具,最后把结果交给模型继续分析。
这就是 MCP 的核心价值:让工具开发和 Agent 开发解耦。
工具团队负责把能力做好,封成 MCP Server;Agent 或 AI 应用负责理解用户问题、选择工具、组织结果。两边不用每次都重新商量一套私有接口。
MCP、Function Calling、Agent 到底是什么关系?
不少读者朋友第一次了解 MCP,都会将它和 Function Calling、Agent、Skills 混在一起。
这几个确实经常一起出现,但不在同一层。
Function Calling 解决的是:模型怎么表达自己想调工具。
模型读完用户问题后,输出一个结构化调用,比如:
{
"name": "read_file",
"arguments": {
"path": "/repo/README.md"
}
}OpenAI 叫 Function Calling,Anthropic 叫 Tool Use,名字不同,核心都是让模型用结构化方式表达“我要调什么、参数是什么”。
MCP 解决的是:这个工具从哪里来,怎么被宿主发现,怎么真正连到后端服务。
Agent 再往上一层,关注的是:任务怎么一步步做完。
它可能会规划步骤、调用工具、读取结果、继续判断,也可能会维护记忆、做循环、等待人工确认。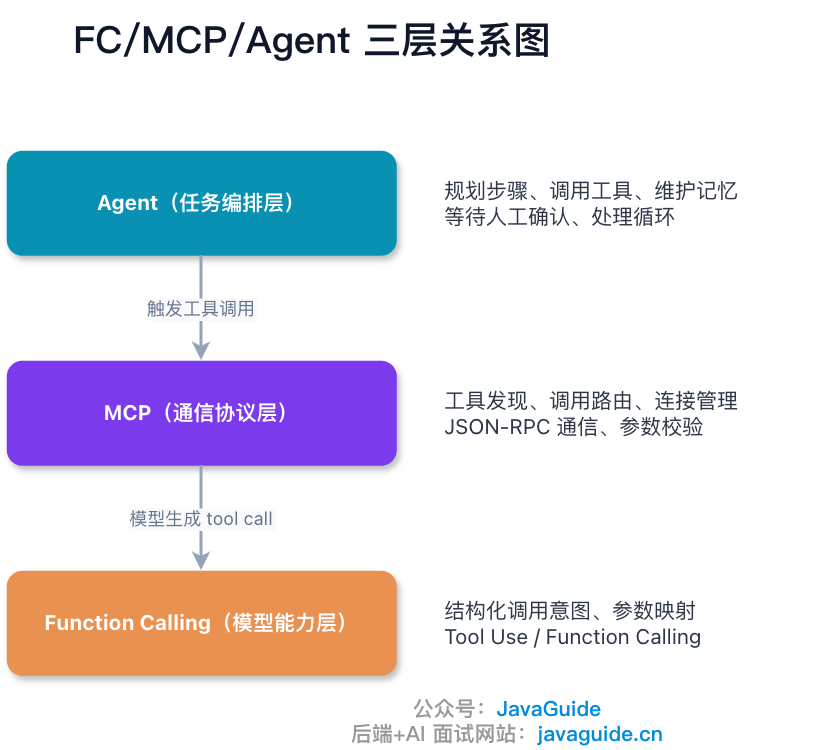
这里最容易踩的坑是把 MCP 当成“模型调用工具”的全部过程。其实模型只负责判断和生成调用意图,MCP 负责把这个调用接到外部系统上。
举几个场景就更清楚了:
| 场景 | 更关键的东西 | 原因 |
|---|---|---|
| 让模型判断要不要查天气 | Function Calling | 重点是模型把意图转成结构化参数 |
| 让 Claude Desktop 读取本地文件 | MCP | 重点是宿主和本地文件系统之间有标准接口 |
| 让 AI 自动排查线上故障 | Agent | 重点是多步决策、工具调用和结果反馈 |
这张表别理解得太死。实际项目里三者经常一起用,只是各自负责的地方不一样。
MCP 里到底有哪些东西?
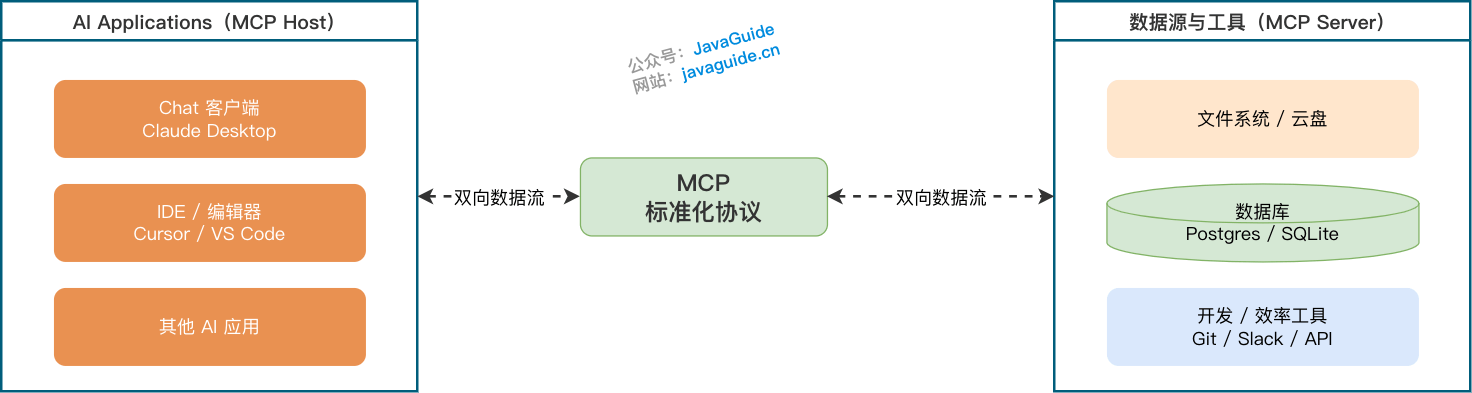
从协议角色看,MCP 最核心的是三个部分:Host、Client、Server。
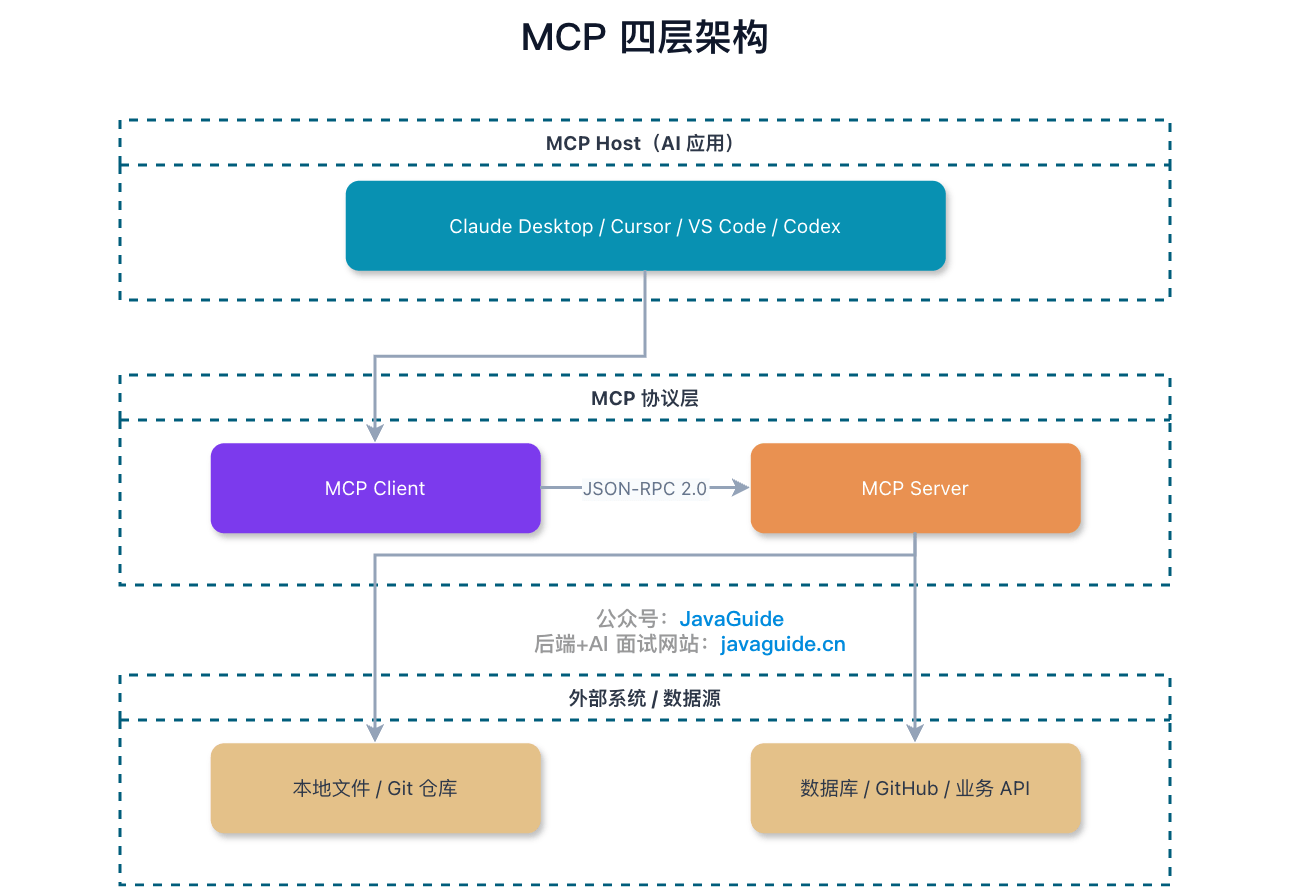
Host 是 AI 应用本身,比如 Claude Desktop、Cursor、VS Code 里的 AI 插件,或者你自己做的 Agent 平台。用户一般直接面对的是 Host。
Client 是 Host 内部负责和 MCP Server 通信的那一层。大多数情况下你看不到它,也不需要自己写。
一个 Host 可以连接多个 MCP Server,通常每个 Server 会对应一个 Client 会话。
Server 是开发者最常接触的部分。你可以写一个 MCP Server,把文件读取、SQL 查询、GitHub Issue 查询、内部工单查询这些能力暴露出去。
实际系统里,Server 后面通常还会连接各种 Data Source,比如本地文件、数据库、内部平台、GitHub 或第三方 API。Data Source 很重要,但它不属于 MCP 协议里的核心角色,更像 Server 背后真正访问的数据和能力来源。
所以,Host 并不是直接“裸连”所有工具。它先通过 Client 连到 Server,Server 再去碰真实数据源。这个分层看起来多了一步,但边界会清楚很多:AI 应用只认 MCP,底层具体怎么查数据库、怎么调 API,由 Server 自己处理。
一次 MCP 调用大概怎么走?
还是拿“分析这个仓库的最新提交”举例。
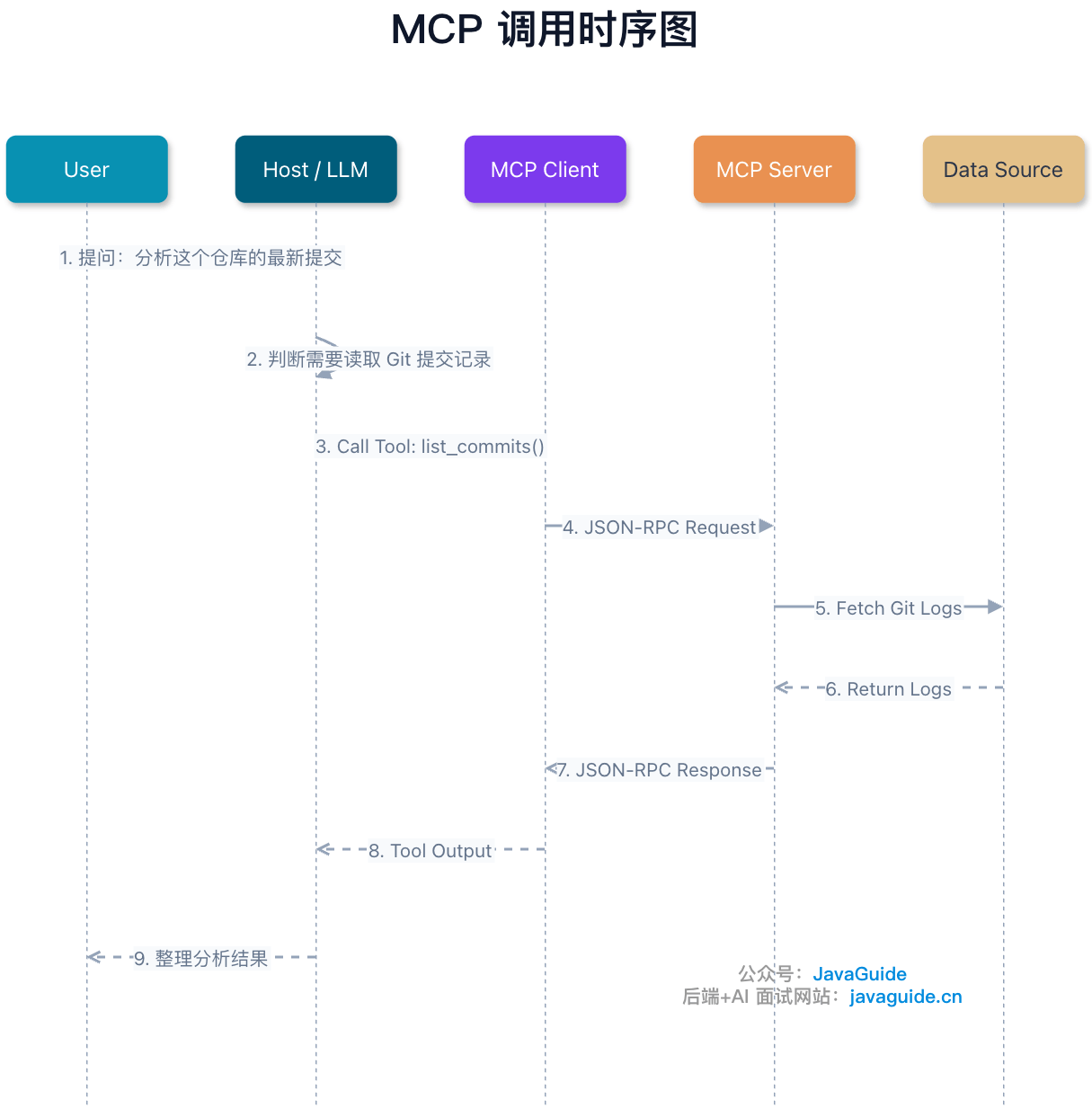
整个流程还是挺简单的。
用户提问后,模型判断自己缺少外部信息,于是生成一个工具调用。Host 把这个调用交给 MCP Client,Client 通过 JSON-RPC 请求 MCP Server。Server 去查 Git 日志,结果再一路返回给模型,由模型组织成最终回答。
这里有两个细节很重要。
第一,模型选不选得对工具,很大程度上看工具描述写得好不好。工具名、description、参数说明、禁用场景,都要写清楚。
第二,模型传来的参数不能默认可信。读文件要限制目录,查 SQL 要参数化,高危操作要审批,返回数据要脱敏。别因为前面多了一个大模型,就忘了后端最基本的安全习惯。
还有一步容易被忽略:Client 和 Server 在正式调用工具前,会先完成初始化握手。Client 发送 initialize 请求,带上自己支持的协议版本和能力列表;Server 返回自己支持的协议版本、能力和基础信息。确认之后,Client 再发 initialized 通知,双方才进入可用状态。
这一步的意义在于:Client 能通过它知道 Server 支持哪些能力(只有 Tools?还是有 Resources 和 Prompts?),Server 也能知道 Client 的限制。很多“Server 配好了但工具没出现”的问题,排查时都应该先看初始化阶段有没有失败。
MCP 暴露的能力只有 Tools 吗?
技术群里很多读者聊 MCP 时只讲 Tools,这也正常,因为工具调用最直观。但 MCP 里不只有工具。
Resources、Tools 和 Prompts
从 Server 侧看,常见能力主要有三类:Resources、Tools、Prompts。
Resources 更像只读上下文。 比如本地文件、日志片段、数据库 Schema、某条配置记录。它们通常适合“给模型看”,让模型拿来理解和推理。
Tools 是可执行动作。 比如查询数据库、发送消息、创建工单、调用业务接口。只要会主动执行逻辑,或者可能改变外部世界,通常都应该放到 Tools。
Prompts 是可复用的提示词模板。 比如“按团队规范做代码审查”“生成故障复盘初稿”“把接口文档整理成测试用例”。这类固定任务可以沉淀成模板,不必每次让用户重新写一遍。
这里有个小区别:Tools 更偏模型主动选择并执行,Resources 和 Prompts 则不一定完全由模型自主选择,很多时候会由 Host、用户界面或应用逻辑决定怎么展示和使用。
用一个生活例子理解 Resources、Tools、Prompts。
G 友说:“我想吃凉拌黄瓜。”
LLM 扮演厨师,它知道凉拌黄瓜大概怎么做,但它还需要外部条件:
- Resources 像食材和菜谱,比如冰箱里有什么、家里有没有黄瓜、调料放在哪里;
- Tools 像具体动作,比如切菜、拌料、开火、下单买菜;
- Prompts 像家里的固定偏好,比如少放辣、必须放香菜、不能放蒜。
如果工具描述写错了,比如把“黄瓜”描述成“西红柿”,模型就可能选错东西。
这个例子看起来有点好笑,但放到生产里就是很真实的问题:工具名不清楚、参数描述模糊、返回结构不稳定,都会让 Agent 做出奇怪选择。
所以 MCP Server 不是能跑就行。你要把能力描述成模型看得懂、选得准、用得安全的形式。
Roots、Sampling 和 Elicitation
除了 Server 侧能力,Client 侧也可以提供一些能力给 Server 使用,比如 Roots、Sampling、Elicitation。
Roots 可以理解为 Host 通过 Client 告诉 Server:“你只能在这些文件或目录范围内工作。”比如只允许访问当前项目目录,而不是整个用户主目录。
Sampling 比较特殊,它允许 Server 请求 Host 侧的 LLM 做一次生成。比如 Server 读取到一段日志后,希望借助模型做摘要或分类。
Elicitation 则是 Server 在执行过程中向用户补充询问信息的能力。比如参数不完整、选项有歧义、执行前需要用户确认,就可以由 Host 侧展示交互。
不过这些能力不要硬凑。大多数 MCP Server 一开始只提供 Tools 就够了。后面真的有需要,再考虑 Resources、Prompts;至于 Roots、Sampling、Elicitation,要看对应 Client 是否支持,也要看业务场景是否真的用得上。
为什么 MCP 用 JSON-RPC?
MCP 底层通信使用 JSON-RPC 2.0。
REST 更偏资源,比如 /users/1、/orders/100。JSON-RPC 更偏方法调用,比如 tools/call、resources/read。AI 工具调用天然就是“我要执行某个动作”,所以 JSON-RPC 和 MCP 的使用场景比较贴。
一个工具调用请求大概长这样:
{
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "read_file",
"arguments": {
"path": "/path/to/file.txt"
}
},
"id": 1
}响应可能是这样:
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"content": [
{
"type": "text",
"text": "文件内容..."
}
]
}
}失败时才返回 error:
{
"jsonrpc": "2.0",
"id": 1,
"error": {
"code": -32602,
"message": "Invalid params"
}
}这里有个小坑:成功响应里不要同时写 result 和 error: null。JSON-RPC 2.0 里,成功响应走 result,失败响应走 error,不要两个都塞进去。
JSON-RPC 的优点很实在:轻量、纯文本、容易打日志,也不强绑定某种传输方式。
但它也不是银弹。它不像 gRPC 那样有强 IDL 和编译期类型约束。
MCP 可以用 JSON Schema 描述工具参数,但这更多是运行时校验和模型提示层面的约束。要想在生产里用得稳,Server 侧仍然要做严格参数校验,不能指望模型“自觉传对”。
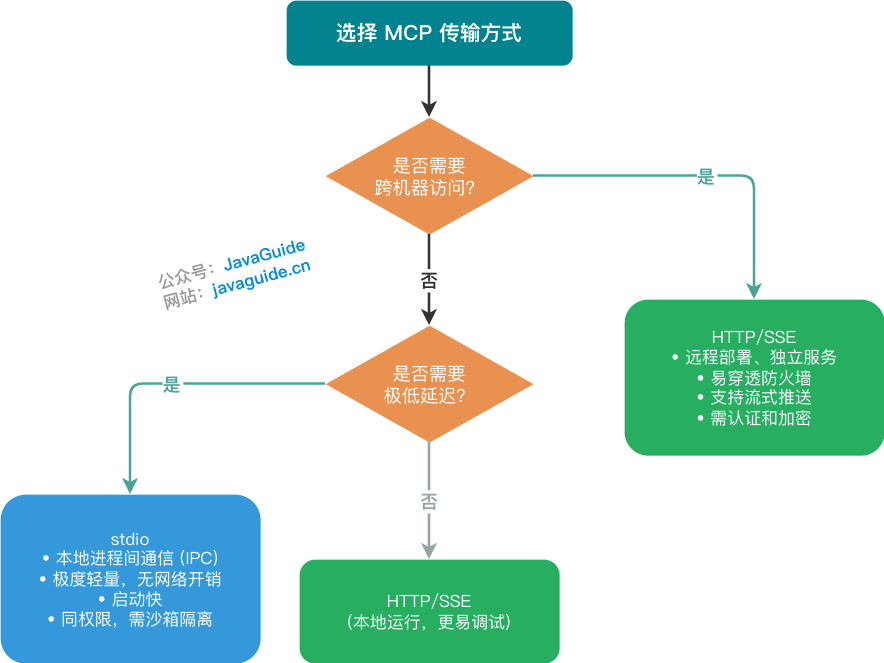
stdio 和 Streamable HTTP 怎么选?
本地开发最常见的是 stdio。
Host 把 MCP Server 当成本地子进程启动,然后通过 stdin/stdout 通信。Claude Desktop 里很多本地 MCP Server 都是这种方式。它的好处是简单,几乎没有网络部署成本;坏处也明显,Server 跑在本机,权限边界要自己管好。
如果是第三方 Server,最好别直接裸跑。至少先看源码,或者用 Docker、cgroups、namespace 这类方式隔离一下。尤其是文件系统、Shell、数据库相关的 Server,权限一旦给大,后面很难补。
stdio 还有个很容易踩的坑:不要往 stdout 打调试日志。stdio 模式下,stdout 是 JSON-RPC 消息通道,你随手 print() 一句日志,就可能把消息流污染掉,导致 Host 解析失败,Server 直接断连。日志建议写到 stderr 或文件里。很多“Server 启动失败”的问题,最后查下来不是协议写错了,而是 stdout 里混进了调试输出。
远程部署更适合 Streamable HTTP。
MCP 早期远程传输常见的是 HTTP + SSE,后来逐步转向 Streamable HTTP。它把通信收敛到统一端点上,认证、负载均衡、网关接入都更接近普通 HTTP 服务的运维方式。
POST /mcp
Authorization: Bearer xxx响应可能是普通 JSON,也可能是 SSE 流,取决于请求类型。
简单选型可以这样记:
- 本地工具、本地文件、个人使用,优先 stdio。
- 团队服务、远程 API、多用户访问,优先 Streamable HTTP。
- 涉及写操作和敏感数据时,不管哪种传输方式,都要额外做鉴权、限流和审计。
MCP 的意义只是让模型会调接口吗?
如果只说“让模型调接口”,其实 Function Calling 早就能做。
MCP 真正有意思的地方,不是让模型多会一个“调接口”的动作,而是把工具接入做成一种更标准的交付形态。
以前你要给某个 Agent 接一个内部工单系统,可能要在这个 Agent 里写一套适配。换一个 Host,再写一套。换一个模型供应商,调用格式又变了。
MCP 的思路是:工具提供方把能力封成 MCP Server,AI 应用只要支持 MCP Client,就可以按统一方式发现和调用这些能力。
这有点像前后端分离带来的变化。
前端不用知道后端内部怎么查库,后端也不用关心前端页面怎么渲染,双方通过接口契约协作。MCP 也是类似思路:Agent 开发关注任务和交互,工具开发关注能力和边界,中间用协议连接。
这会带来一个很现实的变化:业务团队也能参与 Agent 能力建设。
比如一个团队积累了很多操作手册、值班文档、故障复盘、内部排查脚本。过去这些东西散在文档库、飞书、Wiki、脚本仓库里,新人要问人,兄弟团队也经常找不到入口。
如果把其中一部分能力整理成 MCP Server,Agent 就不只是“会聊天”,而是能在授权范围内查文档、看配置、跑排查工具、生成初步分析。
这比“让大家多看文档”现实一点。
MCP 接进来之后,就能直接上生产吗?
不能。
现在很多 MCP Demo 看起来很顺:装一个 Server,问一句话,模型自己查工具,结果就回来了。
Demo 阶段这样挺好。问题是一到生产,麻烦就会出来。
第一,类型和 Schema 要管住。
MCP 的工具参数可以用 JSON Schema 描述,但这不等于你有了完整的强类型体系。时间字段到底是 ISO-8601 还是时间戳?金额单位是元还是分?分页参数默认值是多少?这些不写清楚,模型就会猜。
更稳的做法是:每个工具都要有明确 Schema、版本号、字段说明、示例和边界条件。Server 侧要做强校验,错误信息也要能让模型看懂。
第二,可观测性要补上。
Agent 一次回答可能调用多个 Server、多个工具。如果最后答案错了,你要知道它调了哪些工具、每一步参数是什么、哪个工具耗时最长、哪个结果影响了最终判断。
没有 Trace ID、结构化日志、调用链记录,排查问题会非常痛苦。别等线上出错了,再去日志里人肉拼调用链。
第三,权限不能只靠用户同意。
本地 stdio 可能拿到用户机器上的文件权限,远程 Server 可能连接内部系统。文件能读哪些目录,SQL 能查哪些表,API 能不能写生产数据,工具能不能发邮件,这些都要有边界。
尤其是写操作,最好默认保守。删除、修改、发送、调用生产接口这类动作,要做二次确认、审计和回滚预案。
第四,工具描述本身也要审核。
恶意或粗糙的 MCP Server 可能在 description、Prompt 模板、返回内容里夹带提示词注入,诱导模型继续读取更多文件,或者把信息带到不该去的地方。
所以不要觉得“装个 Server 就完事”。企业里要审核 Server 来源、工具描述、权限范围、依赖包和更新记录。
第五,成本要能归因。
Agent 调工具不只是工具成本,还可能带来模型 Token 成本、向量检索成本、第三方 API 成本、云资源成本。一次调用背后到底是哪条业务线、哪个用户、哪个工具产生的费用,要能追踪。
否则账单来了,只知道总数变高,却不知道钱花在哪里。
第六,版本管理不能靠口头约定。
工具接口一改,Agent 可能就出问题。字段改名、枚举值变化、返回结构调整,都可能影响模型判断。
Server 要有工具级版本管理,不兼容变更要灰度,要保留旧版本一段时间,最好能有自动化兼容性测试。
企业落地 MCP 前,应该先检查哪些问题?
如果只是本地玩一玩,跑通就行。真要进生产,建议至少过一遍下面这些问题。
Schema 和版本
- 每个工具是否有明确输入输出 Schema?
- 字段单位、时间格式、枚举值、默认值是否写清楚?
- 工具接口是否有版本号?
- 不兼容变更有没有灰度和回滚方案?
- 是否能基于 Schema 做自动化校验?
权限和安全
- Server 能访问哪些文件、目录、数据库和 API?
- 是否区分只读工具和写操作工具?
- 高危操作是否需要人工确认?
- 返回结果是否做了脱敏?
- 是否防路径遍历、SQL 注入、命令注入?
- 第三方 MCP Server 是否经过源码、依赖和权限审核?
可观测性
- 每次用户请求是否有 Trace ID?
- 工具调用参数、耗时、结果摘要、错误码是否有结构化日志?
- 是否能还原一次 Agent 回答背后的完整工具调用链?
- 是否有超时、限流、熔断和重试策略?
成本归因
- 每次调用是否能关联到用户、业务线、工具和会话?
- Token 成本、API 成本、云资源成本是否能拆分统计?
- 是否有配额和预算告警?
- 模型循环调用工具时,是否有调用次数上限?
依赖治理
- MCP SDK、第三方库、第三方 Server 是否有维护者和更新记录?
- 安全漏洞谁负责跟进?
- Server 升级是否有测试环境和回滚策略?
- 是否避免把核心能力押在无人维护的三方扩展上?
这份清单看着有点“后端老毛病”,但生产环境就吃这一套。
AI 应用再新,鉴权、审计、日志、版本、限流这些基本功也绕不过去。
写 MCP Server 时,有什么需要注意的?
别先追求大而全
很多人第一次写 Server,会下意识封一个万能工具:
execute_sql(sql)
file_operation(op, path, data)
call_api(url, method, body)这种工具对人来说很灵活,对模型来说反而危险。它不知道边界在哪里,也不知道什么场景该用哪个参数。更麻烦的是,权限也被放得太大。
更推荐把工具拆小一点:
get_user_by_id(id)
list_active_orders(user_id)
read_file(path)
write_report(path, content)名字尽量用动词加名词,description 里写清楚三件事:什么时候用、需要哪些参数、什么时候不要用。
比如查慢 SQL 的工具,不要只写“查询慢 SQL 日志”。最好补一句:服务响应慢、数据库超时、CPU 飙升且怀疑和数据库有关时使用;如果用户问的是网络或内存问题,不要调用这个工具。
这种“禁用场景”对模型很有帮助。
大文件和长文本要小心
MCP Server 很容易碰到大文件。比如日志、Markdown 文档、网页 HTML、CSV 文件。最偷懒的做法是一次性把全文返回给模型,但这通常不是好主意。
我更建议按三层处理。
- 先返回元数据。文件名、大小、更新时间、摘要、可读取范围先给出去,让模型知道这个文件大概是什么。
- 再做分块读取。文件太大就按 chunk 加载,单块控制在一个相对安全的大小,比如 100KB 以内。不要让一个资源直接把上下文撑爆。
- 最后设置硬限制。比如单个资源超过 10MB 时,不返回全文,只返回说明和可选读取方式。Server 被大文件打爆,排查起来很烦,而且这类问题经常不是测试阶段能马上暴露的。
这里还有一个细节:MCP Server 不应该强绑定某个模型的 tokenizer。不同模型的 token 计算不一样,Server 端用字符数或字节数做粗粒度限制就够了,真正的上下文裁剪交给 Host 或上层应用处理。
安全问题不能靠相信模型解决
MCP Server 本质上是在给模型接外部能力。能力越强,风险越大。
文件读取要防路径遍历,不能让 ../ 一路逃到系统目录。
SQL 查询要参数化,别让模型拼字符串执行任意 SQL。
返回数据要脱敏,尤其是手机号、邮箱、Token、密钥、内部链接这类信息。
写操作要限权。删除文件、修改数据库、发送邮件、调用生产接口,都不应该默认放开。该人工确认就人工确认,该审计就审计。
还有资源滥用问题。模型一旦进入循环,可能会连续调用同一个工具。Server 侧最好有限速、超时、熔断和配额,不要指望 Host 一定帮你兜住。
MCP Server 最小示例:先跑通一个工具
用官方 Python SDK 写一个天气 Server,大概是这样:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("weather-server")
@mcp.tool()
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
return f"{city} 今天晴天,温度 25°C"
@mcp.resource("weather://forecast")
def weather_forecast() -> str:
"""返回未来一周天气预报"""
return "未来七天天气预报..."
if __name__ == "__main__":
mcp.run()Claude Desktop 里可以这样配:
{
"mcpServers": {
"weather-server": {
"command": "uv",
"args": ["run", "--with", "mcp", "/path/to/weather_server.py"]
}
}
}本地调试建议直接用 MCP Inspector:
# Python Server
npx @modelcontextprotocol/inspector uv run --with mcp /path/to/weather_server.py
# Node Server
npx @modelcontextprotocol/inspector node build/index.js它可以模拟 Host 发请求。Server 初始化有没有问题、工具能不能被发现、参数校验有没有报错,基本都能先在这里看出来。
生产环境别依赖全局 python 里刚好装了 mcp。用虚拟环境解释器,或者像上面这样用 uv run --with mcp ... 显式声明依赖,会稳一点。如果 Claude Desktop 启动失败,先看 mcp.log,别一上来怀疑协议有问题,很多时候只是路径或依赖没配对。
总结
MCP 体系还在快速演进。协议本身也在迭代,比如 2025-03-26 版本把远程传输从 HTTP+SSE 升级到 Streamable HTTP,2025-06-18 版本又加入了 Elicitation 等新能力。不同客户端、SDK 和旧教程的支持情况不完全一致,接远程 MCP Server 前最好先确认自己使用的版本。
MCP 做的事就是把“各自适配”变成“统一接口”,解决 AI 应用开发里的基础设施碎片化问题。RESTful API 统一了 Web 服务的接口风格,MCP 想统一的是 AI 应用与外部工具/数据源的接入方式。
上手最快的路径就是写一个最简单的 MCP Server,边做边理解协议细节。协议还在演进,但核心概念已经稳定了,先跑起来比先研究透更重要。