一文搞懂 Harness Engineering:六层架构、上下文管理与一线团队实战
别只盯模型。
很多人第一次做 Agent,直觉都是先买更贵的模型。结果模型换了,Agent 还是会重复犯错,做到一半放弃,上下文一长就开始不稳定。这个时候继续调 Prompt,收益往往也很有限,因为问题可能根本不在模型本身。
有个实验挺能说明这件事:同一个模型,只换了文件编辑接口的调用方式,编码基准分数从 6.7% 跳到了 68.3%。模型没有变,变的是它外面那套系统。也就是说,Agent 能不能稳定干活,很多时候取决于模型之外的环境、工具、反馈和约束。
最近 AI Agent 开发圈里经常提到一个词:Harness Engineering。它讨论的就是这件事:决定 Agent 表现上限的,可能不是模型,而是你给模型搭的那套工作环境。
这篇文章会把 Harness Engineering 拆开讲清楚。全文接近 7800 字,主要看这几块:
- Harness 是什么,为什么可以把 Agent 理解成 Model + Harness
- 为什么同一个模型换一套接口,分数能从 6.7% 变成 68.3%
- Harness 的六层架构分别解决什么问题
- 从零搭 Harness 时,哪些事情应该先做,哪些可以后面再补
- OpenAI、Anthropic、Stripe 这些团队到底怎么用 Harness
Harness 基本概念
Harness 到底是什么?
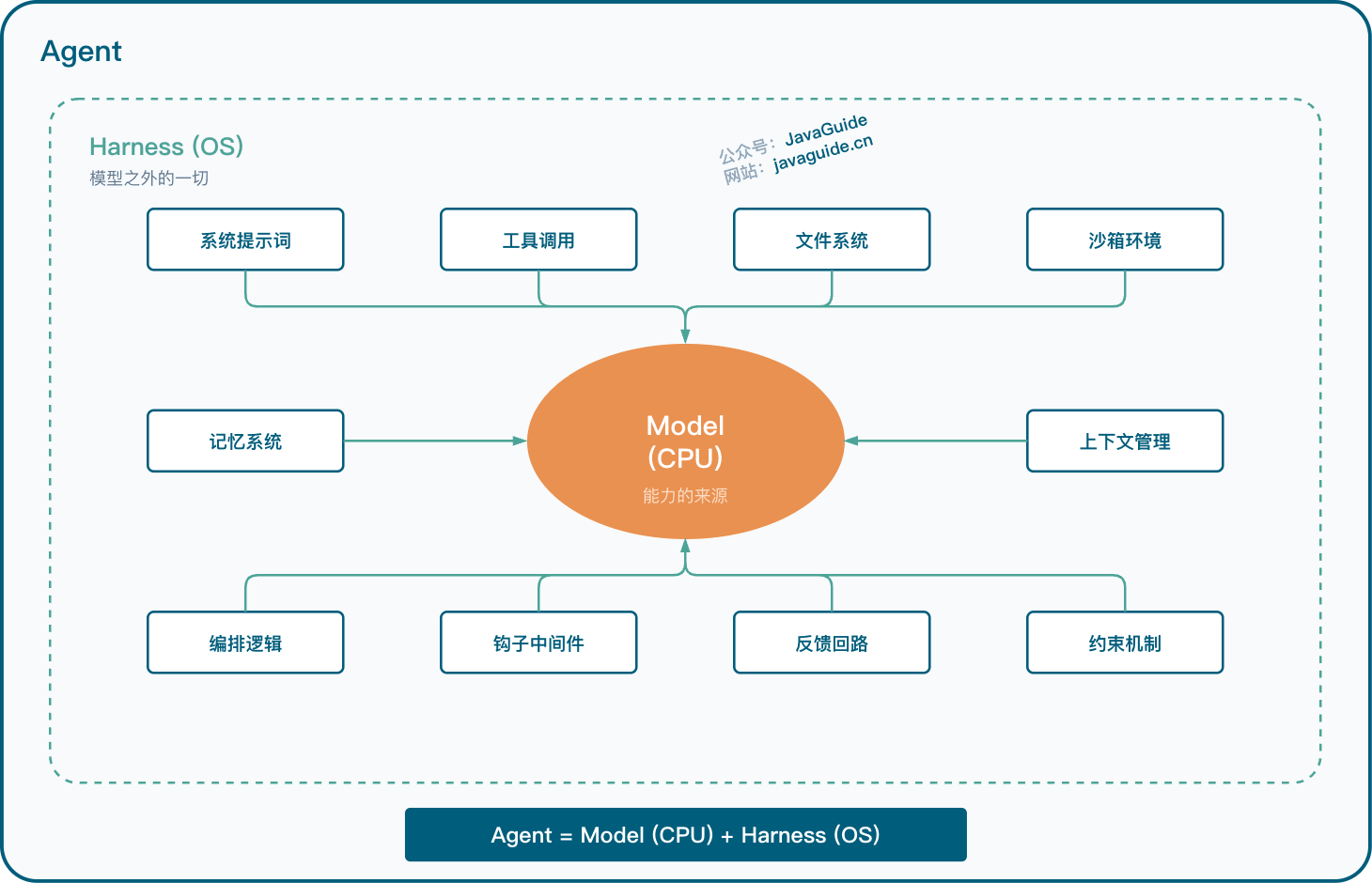
可以先用一个粗暴但好记的说法:Agent = Model + Harness。你不是模型,那你做的东西大概率就是 Harness。
这个说法有点绝对,但抓住了重点。Harness 指的是模型之外的整套系统:系统提示词、工具调用、文件系统、沙箱环境、编排逻辑、钩子中间件、反馈回路、约束机制。模型只提供推理和生成能力,Harness 把状态、工具、反馈、执行环境和安全边界串起来,Agent 才能真正开始干活。
LangChain 的 Vivek Trivedi 写过一篇《The Anatomy of an Agent Harness》,里面有个思路很值得记:先分清模型负责什么,再看剩下的系统该补什么。用这条线一切,很多 Agent 问题就不再是“模型行不行”,而是“系统有没有把模型需要的东西准备好”。
可以把模型想成 CPU,把 Harness 想成操作系统。CPU 再强,OS 如果天天崩,体验也不会好。你买了最新的 M5 芯片,但系统卡死、驱动乱飞,实际体验可能还不如旧芯片配一个稳定系统。
Harness 和 Prompt / Context Engineering 的关系
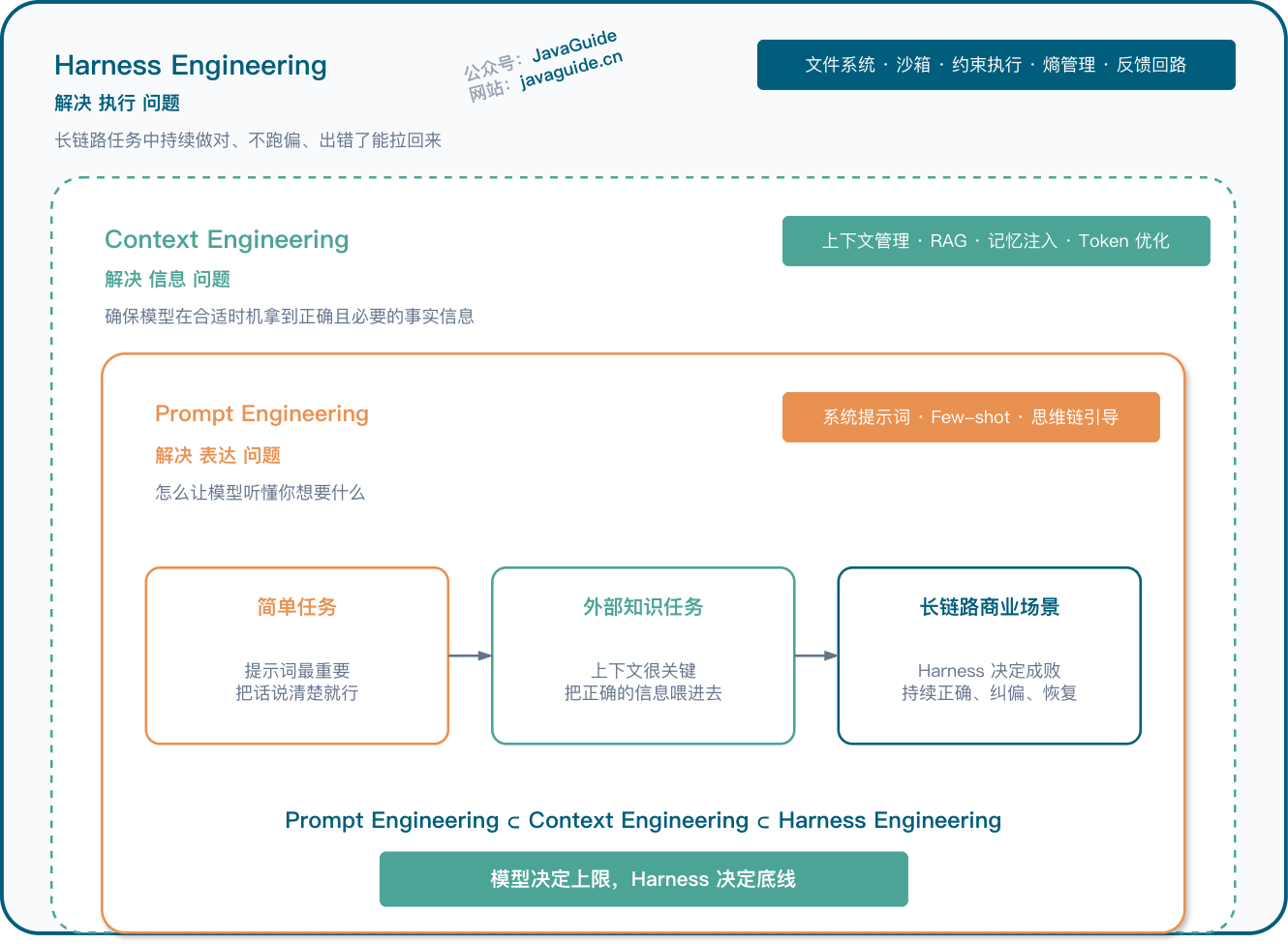
Prompt Engineering、Context Engineering、Harness Engineering 不太适合放在同一层比较。它们更像一层套一层,处理的问题范围越来越大。
| 层级 | 解决的问题 | 关注点 | 典型工作 |
|---|---|---|---|
| Prompt Engineering | 怎么把指令说清楚 | 让模型理解意图,减少局部歧义 | 系统提示词设计、Few-shot 示例、思维链引导 |
| Context Engineering | 该给 Agent 看什么 | 在合适时机给模型提供正确且必要的信息 | 上下文管理、RAG、记忆注入、Token 优化 |
| Harness Engineering | 系统怎么持续执行、纠偏、观测和恢复 | 长链路任务中的持续正确、偏差修正、故障恢复 | 文件系统、沙箱、约束执行、反馈回路、观测 |
简单任务里,Prompt 可能就够了。比如让模型改一句文案,提示词说清楚,效果通常不会差。需要外部知识时,Context 更重要,你得把资料、检索结果、历史状态放到合适位置。到了长链路、可执行、低容错的商业场景,Harness 才会变成主要矛盾,因为 Agent 需要的不只是“会回答”,还要能执行、验证、回滚、继续推进。
这也是一线团队会把大量精力放在 Harness 上的原因。不是他们不会写 Prompt,而是 Prompt 解决不了所有执行问题。
Harness 包含哪些组件?
想知道 Harness 里应该放什么,可以反过来问:模型做不到什么?
大模型看起来很能干,但从系统角度看,它仍然主要是一个输入输出函数。输入一段上下文,输出一段文本或结构化调用。它不会天然记住历史,不会自己跑命令,不会知道代码是否真的通过测试,也不会自动区分哪些信息该保留、哪些该丢掉。
| 模型做不到的事 | Harness 怎么补 | 对应组件 |
|---|---|---|
| 记住多轮对话历史 | 维护对话历史,每次请求时拼进上下文 | 记忆系统 |
| 执行代码、跑命令 | 提供 Bash 和代码执行环境 | 通用执行环境 |
| 获取实时信息,比如新库版本、API 变化 | 接入 Web Search、MCP 工具 | 外部知识获取 |
| 操作文件和环境 | 抽象文件系统,引入 Git 版本控制 | 文件系统 |
| 判断自己有没有做对 | 提供沙箱、测试工具、浏览器自动化 | 验证闭环 |
| 长任务中保持连贯 | 做上下文压缩、记忆文件、进度追踪 | 上下文管理 |
把这些“模型做不了,但你又希望 Agent 能做到”的部分补齐,就是 Harness 的组件清单。LangChain 也把它拆成了几块:文件系统负责持久化,Bash 执行负责通用工具,沙箱负责隔离风险,记忆机制负责跨会话积累,上下文压缩负责对抗长上下文带来的质量下降。
Harness 进阶
一个成熟的 Harness 长什么样?
前面是从“模型缺什么,系统补什么”的角度看 Harness。如果换成系统设计视角,一个成熟的 Harness 通常会有清晰的分层。
我之前在 YouTube 上看到过一个六层体系,比较适合拿来理解 Harness 的全貌:

| 层级 | 名称 | 解决什么问题 | 关键设计 |
|---|---|---|---|
| L1 | 信息边界层 | Agent 该知道什么、不该知道什么 | 定义角色与目标,裁剪无关信息,结构化组织任务状态 |
| L2 | 工具系统层 | Agent 怎么和外部世界交互 | 选择工具、控制调用时机、提炼工具结果并反馈 |
| L3 | 执行编排层 | 多步骤任务怎么串起来 | 让模型按“理解目标、判断信息、分析、生成、检查”的轨道推进 |
| L4 | 记忆与状态层 | 长任务中间结果怎么管理 | 独立管理当前任务状态、中间产物和长期记忆,避免状态混在一起 |
| L5 | 评估与观测层 | Agent 怎么知道自己做对了没有 | 建立独立于生成过程的验证机制 |
| L6 | 约束、校验与恢复层 | 出错了怎么办 | 预设规则拦截错误,失败时提供重试、回滚或降级 |
可以把它想成给一个新员工搭工作环境。L1 是岗位说明,告诉他该关注什么;L2 是办公工具;L3 是标准操作流程;L4 是项目管理系统和笔记本;L5 是质检流程;L6 是红线规则和应急预案。
这六层从边界、工具、流程、状态、验证到恢复,组成一整套体系。后面看 OpenAI、Anthropic、Stripe 的做法,会发现它们虽然形式不同,但很多设计都能映射到这六层。
不过不要一上来就想把六层全部搭齐。更现实的做法是先做 L1 和 L6:先让 Agent 知道自己该干什么,再给它设置出错后的拦截和恢复机制。这两层投入不算最高,但通常最容易见效。中间几层可以随着项目复杂度慢慢补。
为什么瓶颈经常不在模型?
第一次听到这个结论,很多人会觉得反直觉。模型不够聪明,那等更强的模型出来不就好了?但不少实验和实践都在指向另一个结论:模型当然重要,但在很多 Agent 场景里,真正卡住效果的是基础设施。
前面提到的 Can.ac 实验就是一个典型例子。同一个模型,只换了工具调用格式,效果能差十倍。LangChain 的实践也类似,他们优化了 Agent 运行环境,包括文档组织方式、验证回路、追踪系统,在 Terminal Bench 2.0 上从全球第 30 名升到第 5 名,得分从 52.8% 提升到 66.5%。模型没有换,换的是 Harness。
很多团队遇到 Agent 表现不好,第一反应是换模型或继续调提示词。这个反应很正常,但不一定命中问题。如果工具接口设计得很难用,反馈回路缺失,错误信息也不给修复方向,模型再强也会被外部环境拖住。
LangChain 还提到过一个 model-harness 耦合现象。现在很多 Agent 产品,比如 Claude Code、Codex,模型和 Harness 是一起被调优出来的,这会带来一种过拟合:模型习惯了某套工具逻辑,换一个 Harness 后表现可能变差。他们在 Terminal Bench 2.0 排行榜里观察到,Opus 在 Claude Code 的 Harness 下得分,远低于它在其他 Harness 中的得分。
他们的结论是:the best harness for your task is not necessarily the one a model was post-trained with。为任务选择 Harness 时,不要默认模型自带的 Harness 就一定最合适。
为什么上下文喂越多,Agent 反而越蠢?
Dex Horthy 观察到一个很有意思的现象:168K token 的上下文窗口,用到大约 40% 的时候,Agent 输出质量就开始明显下降。

| 区间 | 占比 | 表现 |
|---|---|---|
| Smart Zone | 0 - ~40% | 推理聚焦、工具调用准确、代码质量高 |
| Dumb Zone | 超过 ~40% | 幻觉增多、兜圈子、格式混乱、代码变差 |
Anthropic 也遇到过类似问题,他们称之为“上下文焦虑”。Sonnet 4.5 在上下文快填满时会变得犹豫,甚至倾向于提前收工,即使任务还没完成。只做压缩不够,他们后来直接采用 context resets:清空上下文窗口,但通过结构化交接文档保留关键状态。
这里的目标不是给 Agent 塞更多信息,而是让它尽量停留在干净、相关的上下文里。一线团队做“渐进式披露”和“分层管理”,底层原因就在这里。上下文越多不等于越聪明,很多时候只是噪声越来越多。
生产环境里最好监控上下文利用率。一个可操作的做法是把 40% 当成告警线,超过后触发压缩、分段执行或任务交接。等 Agent 已经开始兜圈子,再处理就比较被动了。
从哪里开始搭 Harness?
结合一线团队的实践,可以把行动项按优先级拆开。没必要一开始做成大系统,先把 P0 做好,通常就能明显改善 Agent 表现。
P0:可以马上做
| 行动 | 为什么 | 参考实践 |
|---|---|---|
创建 AGENTS.md 并持续维护 | Agent 每次启动自动加载,犯错后更新,形成反馈循环 | Hashimoto 每一行对应一个历史失败案例 |
| 写自定义 Linter + 修复指令 | 错误消息直接告诉 Agent 怎么改 | OpenAI 的 Linter 报错自带修复方法 |
| 把团队知识放进仓库 | Slack、Wiki、Docs 里的知识对 Agent 很难稳定可见 | OpenAI 把仓库作为事实来源 |
这里有个坑:不要把 AGENTS.md 写成超级 System Prompt。很多团队一上来恨不得把所有规则都塞进去,结果上下文被撑爆,Agent 反而更容易跑偏。OpenAI 的做法更克制,AGENTS.md 只当目录用,大约 100 行,详细规则放到子文档里按需加载。
P1:P0 稳了之后再补
| 行动 | 为什么 | 参考实践 |
|---|---|---|
| 分层管理上下文 | 避免把所有信息塞进一个文件,按需披露 | OpenAI 把 AGENTS.md 当目录用,约 100 行 |
| 建立进度文件和功能列表 | 用 JSON 追踪功能状态,Agent 不太容易乱改结构化数据 | Anthropic 初始化 Agent + 编码 Agent 两阶段 |
| 给 Agent 端到端验证能力 | 让 Agent 像用户一样验证功能 | Anthropic 使用 Playwright / Puppeteer MCP |
| 控制上下文利用率 | 尽量不超过 40%,用增量执行降低污染 | Dex Horthy 的 Smart Zone / Dumb Zone |
P2:有余力再考虑
| 行动 | 为什么 | 参考实践 |
|---|---|---|
| Agent 专业化分工 | 每个 Agent 携带更少无关信息,留在 Smart Zone | Carlini 的去重、优化、文档 Agent |
| 定期垃圾回收 | 清理速度要跟得上生成速度 | OpenAI 的后台清理 Agent |
| 可观测性集成 | 把性能优化从感觉问题变成可测量的问题 | OpenAI 接入 Chrome DevTools |
你的 Harness 到哪个阶段了?
可以用下面这个表粗略判断一下。这里不需要追求一步到 Level 4,很多团队能从 Level 0 到 Level 1,收益就已经很明显。
| 阶段 | 特征 | 工程师角色 |
|---|---|---|
| Level 0:无 Harness | 直接给 Agent Prompt,没有结构化约束 | 手动写代码,偶尔使用 AI |
| Level 1:基础约束 | AGENTS.md、基础 Linter、手动测试 | 主要写代码,AI 辅助 |
| Level 2:反馈回路 | CI/CD 集成、自动化测试、进度追踪 | 规划和审查为主 |
| Level 3:专业化 Agent | 多 Agent 分工、分层上下文、持久化记忆 | 设计环境和管理执行过程 |
| Level 4:自治循环 | 无人值守并行化、自动清理、自修复 | 架构设计和质量把关 |
Harness 还没解决的问题
讲完这些实践,也要把没解决的问题摆出来。现在公开案例不少,但真正让人信服的方法论还不多,尤其是落到已有项目时,很多问题仍然悬着。
| 问题 | 现状 | 谁在关注 |
|---|---|---|
| 棕地项目怎么改造 | 公开成功案例几乎都是绿地项目,缺少成熟方法论 | Böckeler 把它比作“在从没用过静态分析的代码库上跑静态分析”。她还提出 Ambient Affordances:环境本身的结构特性,比如类型系统、模块边界、框架抽象,会影响 Harness 能做到什么程度 |
| 怎么验证 Agent 做对了事 | 大家更擅长限制它别做错,但验证功能正确性还很弱 | Böckeler 批评:用 AI 生成的测试来验证 AI 生成的代码,仍然像“用同一双眼睛检查自己的作业” |
| AI 生成代码的长期可维护性 | LLM 代码经常重新实现已有功能,长期效果还不好判断 | Greg Brockman 提出过这个问题,但目前没有清晰答案 |
| Harness 该做厚还是做薄 | Manus 五次重写越做越简单,OpenAI 五个月越做越复杂 | 场景决定。通用产品更追求最小化,特定产品可以高度定制。模型变强后,已有 Harness 也应该定期简化,Anthropic 已经做过类似验证 |
| 单 Agent 还是多 Agent | Hashimoto 坚持单 Agent,Carlini 使用 16 个并行 Agent | 规模决定。小项目单 Agent 往往够用,大项目更容易走向专业化分工 |
绿地项目和棕地项目是软件工程里的经典说法。绿地项目指从零开始的新项目,没有历史包袱,就像在空地上盖房子,想怎么设计都比较自由。棕地项目指在已有代码库上改造,里面有历史架构、技术债和遗留逻辑,就像在老旧城区翻新,很多管线不能随便动。
OpenAI、Anthropic、Stripe、Hashimoto 这些案例基本都是在新项目里从零搭 Harness。但现实里,大多数团队面对的是跑了多年的老代码库。一个有十年历史、没有明确架构约束、到处是技术债的项目,怎么引入 Harness?目前还没有公开的成熟方法论。
Harness 案例:这些团队是怎么做的
下面几个案例放在一起看,会发现不同背景的团队踩坑很像。区别主要在于,有的团队先撞墙再补 Harness,有的团队从第一天就把约束和反馈回路放进架构里。
OpenAI:三个人,五个月,一百万行,零手写代码
先看数据:
| 指标 | 数值 |
|---|---|
| 团队规模 | 3 名工程师,后扩至 7 人 |
| 持续时间 | 5 个月,2025 年 8 月起 |
| 代码规模 | 约 100 万行 |
| 手写代码 | 0 行,设计约束 |
| 合并 PR 数 | 约 1,500 个 |
| 日均 PR/人 | 3.5 个 |
| 效率提升 | 约 10 倍 |
数字很夸张,但更值得看的是他们怎么做。
给 Agent 一张地图,不要塞一本千页手册
OpenAI 的 AGENTS.md 大约只有 100 行,作用更像目录,指向 docs/ 目录下更深层的设计文档、架构图、执行计划和质量评级。这就是渐进式披露:先给最关键的信息,需要更多细节时再加载。
这和到一个新城市很像。你不需要一上来背完整本旅游指南,先给一张地图,再告诉你想了解某个景点时去翻哪一页,就够用了。
Agent Skills 也可以看成渐进式披露的一种实现。它保留少量元数据,比如名称和描述,详细规则和执行流程只在触发时再加载进上下文。这个思路和 OpenAI 把 AGENTS.md 当目录很接近,只是 Skills 把这个模式标准化了。相关阅读可以看这篇:Agent Skills 详解:是什么?怎么用?和 Prompt、MCP 有什么区别?。
架构约束要靠工具执行
OpenAI 给每个业务领域定义了固定分层:
Types → Config → Repo → Service → Runtime → UI依赖方向不能反过来。怎么保证?靠自定义 Linter 和结构测试。违反规则时,工具不只是报错,还会告诉 Agent 应该怎么改。Agent 在修错的过程中,也被反复训练成更符合团队规范的写法。
OpenAI 有句原话很直接:If it cannot be enforced mechanically, agents will deviate. 只写在文档里的约束不够,不能机械化执行,Agent 迟早会偏离。
可观测性也要给 Agent 看
他们把 Chrome DevTools Protocol 接进 Agent 运行时,Agent 可以自己抓 DOM 快照和截图。日志、指标、链路追踪也通过本地可观测性栈暴露给 Agent。
这样一来,“把启动时间降到 800ms 以下”就变成了一个 Agent 可以自己测量、自己验证的目标。
熵不会自己消失
AI 生成代码越多,低质量实现、重复逻辑、文档不一致也会跟着变多。一开始 OpenAI 团队每周五花 20% 时间手动清理这些生成物。后来这件事被自动化了:后台 Agent 定期扫描文档不一致、架构违规和冗余代码,并自动提交清理 PR。
这个点很现实。生成速度上来了,如果清理速度跟不上,项目迟早会被自己的产物拖垮。
Slack 里的知识,Agent 很难稳定用上
写在 Slack 讨论或 Google Docs 里的知识,对 Agent 来说并不稳定。OpenAI 的做法是把团队知识作为版本控制制品放进仓库里,让仓库成为可追踪、可引用的事实来源。
这里也别误解成“照抄 OpenAI 就行”。OpenAI 自己也说了,这个结果不应该被假设为在缺少类似投入的情况下可以复现。它的每一项方法都要前期投入。真正适合普通团队先学的,是地图式文档、机械化约束和主动清理这些思路。
Anthropic:从上下文焦虑到三智能体架构
Anthropic 在这个方向上有两个值得细看的实践。一个是 Carlini 用多 Agent 写 C 编译器,另一个是 Anthropic Labs 借鉴 GAN 思路做三智能体协作。

用 16 个 Agent 写 C 编译器
Nicholas Carlini 用大约两周时间,跑了 16 个并行 Claude Opus 实例,大约 2000 个 Claude Code 会话,做出了一个 GCC torture test 通过率 99% 的 C 编译器。
| 指标 | 数值 |
|---|---|
| 持续时间 | 约 2 周 |
| 并行 Agent 数 | 16 个 Claude Opus 实例 |
| 会话数 | 约 2,000 个 |
| 产出 | 10 万行 Rust 代码 |
| GCC torture test | 99% 通过率 |
| 可编译项目 | PostgreSQL、Redis、FFmpeg、CPython、Linux 6.9 Kernel 等 150+ |
| API 成本 | 约 2 万美元 |
这个项目里的 Harness 细节比结果本身更值得看:
- 日志不打到控制台,全部写进文件,并使用 grep 友好的单行格式,比如
ERROR: [reason],主动减少上下文污染。 - 测试不全部跑。每个 Agent 只跑随机 1-10% 的测试子集;对单个 Agent 来说,子采样是确定性的,同一次运行总是跑同样的子集;跨 VM 又是随机的,不同 Agent 覆盖不同部分。这样整体覆盖全部测试,单个 Agent 不会在测试上耗掉几个小时。
- Agent 角色逐渐专业化,包括核心编译器工作、去重、性能优化、代码质量和文档。LLM 经常重新实现已有功能,所以专门做去重也很有必要。
Carlini 后来说过一句话:”我必须不断提醒自己,我是在为 Claude 写这个测试框架,不是为自己写。”这句话点出了 Harness 的服务对象:首先是 Agent,不一定是人类工程师。
Anthropic 为什么借鉴 GAN?
Anthropic Labs 团队在 2026 年 3 月发布了一个受 GAN 思路启发的三智能体架构。原文说的是 Taking inspiration from GANs,意思是借鉴思路,并不是真正做对抗训练。
Planner(规划者)→ Generator(执行者)⇄ Evaluator(评估者)Planner 拿到 1-4 句话的产品描述,把它扩展成完整产品规格,并被要求“在范围上要大胆”。Generator 按功能一个个做 Sprint,每个 Sprint 有明确完成标准。Evaluator 用 Playwright MCP 实际点击运行中的应用,再按产品设计深度、功能性、视觉设计、代码质量等维度打分。
这个架构主要处理两个问题:
| 问题 | 表现 | 解法 |
|---|---|---|
| 上下文焦虑 | Sonnet 4.5 快到上下文上限时草草收尾 | context resets + 结构化交接,单靠压缩不够 |
| 自我评价偏差 | Agent 自信地夸自己做得好,实际质量一般 | 生成和评估交给两个独立 Agent |
打分标准也有意思。前端设计里,设计质量和原创性的权重被故意调得比功能性和代码质量更高,因为模型很容易做出“功能齐全但长相平庸”的东西。权重调整是在逼它往更难的方向走。
遇到上下文焦虑,Anthropic 选择重启
Anthropic 发现 Sonnet 4.5 在上下文快满时会变得犹豫,甚至提前收工。他们最后采用的方案叫 context resets。
流程很简单:当 Agent 上下文接近饱和时,先把当前任务状态、已完成工作、待办事项结构化提取出来;然后启动一个新的干净 Agent,把交接文档给它;新 Agent 从干净状态继续做。
这有点像程序遇到内存泄漏。你不一定非要手动释放每个内存块,也可以重启进程,再从检查点恢复状态。听起来粗暴,但长任务里,一个干净的新 Agent 往往比一个塞满历史信息的 Agent 表现更好。
这个思路和 Carlini 的编译器项目也很接近。他跑了 2000 个 Claude Code 会话,每个会话都相对独立,从干净状态开始。Anthropic 只是把“重启和恢复”做得更正式。
两种配置的成本对比如下:
| 配置 | 耗时 | 花费 | 效果 |
|---|---|---|---|
| Solo Harness,单 Agent + 最少工具 | 20 分钟 | $9 | 跑不起来的半成品 |
| Full Harness,三 Agent + 完整工具链 | 6 小时 | $200 | 完整可用的应用 |
更复杂的任务差距还会拉大。比如用 Full Harness 做一个浏览器里的音乐制作工作站 DAW,跑了将近 4 小时,花了 $124.70,最后得到一个带编曲视图、混音台和播放控制的可用程序。
但他们还有一个重要发现:把模型从 Sonnet 4.5 换成 Opus 4.6 后,Sprint 机制可以完全移除,Evaluator 从每个 Sprint 检查变成最后只检查一次。Anthropic 的总结很准确:Every component in a harness encodes an assumption about what the model can't do on its own, and those assumptions are worth stress testing.
换句话说,Harness 里的每个组件都在假设"模型自己做不到这个"。模型变强后,这些假设要重新测试。Anthropic 也提到,模型越强,Harness 的设计空间会移动,旧的保护机制可能会变成冗余,所以 Harness 也要定期简化。
Stripe:每周 1300+ 个 PR 的无人值守模式
Stripe 的 Minions 系统是另一个极端:高度自动化、无人值守。开发者发一条 Slack 消息,Agent 就从写代码、跑 CI 到提 PR 全部完成,人只在最后审查。每周有超过 1300 个完全由 Minions 生产、没有人类手写代码的 PR 被合并。

这个数字第一次看到确实有点吓人。拆开看,它靠的是一套很成熟的工程环境,不是某个”超强 Agent”。
| 组件 | 作用 | 关键设计 |
|---|---|---|
| Devbox | 开发环境 | AWS EC2 预装源码和服务,预热池分配,启动约 10 秒,“牲口不是宠物” |
| 编排状态机 | 流程控制 | 混合确定性节点,比如 lint、push,和 Agent 节点,比如实现功能、修 CI;该确定的地方确定,该灵活的地方灵活 |
| Toolshed MCP | 工具服务 | 集中式 MCP 服务,近 500 个工具,每个 Minion 拿到筛选后的子集 |
| 反馈回路 | 质量保障 | Pre-push hook 秒级修 lint;推送后最多 2 轮 CI,覆盖 300 万+ 测试 |
Stripe 的编排思路很像混合流水线。跑 lint、推送代码这类步骤走确定性流程;实现功能、修 CI 错误这类需要判断的部分交给 Agent。该死板的地方死板,该灵活的地方灵活。
他们还有一个理念:What's good for humans is good for agents。过去为人类工程师投入的 Devbox、工具链和开发者体验,在 Agent 上也会直接产生回报。Agent 不一定需要一套完全独立的基础设施,它更应该被当作开发环境中的一等公民。
Minions 底层是 Block 开源项目 goose 的一个 fork,Stripe 针对无人值守场景做了定制。
Mitchell Hashimoto:一个人的 Harness 工程学
Mitchell Hashimoto 是 Vagrant、Terraform、Ghostty 终端模拟器的作者。他的路线和 Stripe 很不一样。他坚持一次只跑一个 Agent,并且保持深度参与。他明确说过:“我不打算跑多个 Agent,也不想跑。”
他的实践可以拆成六步:
| 步骤 | 名称 | 做法 |
|---|---|---|
| 1 | 放弃聊天模式 | 让 Agent 在能读文件、跑程序、发 HTTP 请求的环境里直接干活 |
| 2 | 复现自己的工作 | 每件事做两次,一次自己做,一次让 Agent 做,他形容这个过程“痛苦至极” |
| 3 | 下班前启动 Agent | 每天最后 30 分钟给 Agent 布置任务,比如深度调研、模糊探索、Issue 分拣 |
| 4 | 外包确定性任务 | 挑出 Agent 几乎一定能做好的任务后台跑,建议关掉桌面通知,避免上下文切换 |
| 5 | 工程化 Harness | Agent 每犯一次错,就工程化一个方案,尽量让它以后不再犯同类错误 |
| 6 | 始终有 Agent 在跑 | 目标是 10-20% 的工作时间有后台 Agent 运行 |
Ghostty 项目里的 AGENTS.md 很有代表性。每一行都对应一个过去的 Agent 失败案例。它是一个持续积累的防错系统。Agent 犯了一个新类型错误,就加一条规则,后面同类问题就能少一些。

Birgitta Böckeler 对 Harness 的梳理
Birgitta Böckeler 是 Thoughtworks 的 Distinguished Engineer,她在 Martin Fowler 网站上对 OpenAI 实践做过结构化分析。她更关心这些做法可以归到哪几类,以及还有哪些空白。
她把 Harness 组件归为三类:
| 归类 | 关注点 | 典型实践 |
|---|---|---|
| Context Engineering | 管理 Agent 看到什么、什么时候看到 | 从巨大 AGENTS.md 演化为入口文件 + 分层文档 |
| Architectural Constraints | 确保 Agent 不跑偏 | 自定义 Linter、结构测试、LLM Agent 充当约束 |
| Garbage Collection | 对抗熵积累 | 定期运行清理 Agent,扫描不一致和违规 |
Böckeler 还提了几个判断,我觉得比案例本身更值得关注。
她认为 Harness 可能会变成新的服务模板。很多组织其实只有两三个主要技术栈,未来团队可能会从一组预制 Harness 中选择,就像今天从服务模板里创建新服务一样。
棕地项目改造会是最大挑战。公开成功案例大多是绿地项目,而把一个十年历史、没有清晰架构约束的代码库接入 Harness,要难得多。她把它比作在从没用过静态分析工具的代码库上运行静态分析,结果很可能是被警报淹没。她还提出 Ambient Affordances 这个概念:环境本身的结构特性会影响 Harness 能做多好。比如强类型语言天然有类型检查作为 sensor,清晰模块边界方便定义架构约束,Spring 这类框架也会抽象掉很多细节。
还有一个容易被忽略的问题:功能验证体系还很薄。现在很多讨论都集中在架构约束和熵管理上,但功能正确性验证仍然不够。Böckeler 的观察比较尖锐:很多团队让 AI 生成测试,再用这些测试验证 AI 生成的代码。这样做仍然缺少独立验证视角,她的原话是 puts a lot of faith into AI-generated tests, that's not good enough yet。
把这些案例放在一起看,共性比差异更明显:上下文污染、代码熵积累、工具调用可靠性,这三道坎几乎都会遇到。团队规模是 3 人还是 300 人,问题不太一样,但底层风险差不多。区别在于,有的团队等 Agent 出问题后再补救,有的团队一开始就把约束、验证和清理机制放进 Harness 里。后者的补救成本通常低很多。