Loop Engineering 是什么?为什么说它是新瓶装旧酒?
这几天 Loop Engineering 突然火起来,我第一反应是:这又是哪个新名词?怎么天天造新词?
看了一圈之后,感觉它确实有点新瓶装旧酒。Agent Loop、Workflow Graph、Context Engineering、Skills、MCP、CI、测试验证,这些东西 JavaGuide 之前其实都聊过。换个名字重新包装一下,味道很熟悉了。
代码 Agent 真能连续读文件、改代码、跑命令、处理 PR 之后,我们确实不能只盯着“下一句 Prompt 怎么写”。以前是人守在对话框前,一轮一轮补充提示;现在越来越多任务会由 /loop、/goal、CI、PR 评论或者定时任务触发。Agent 被叫醒后自己读材料、跑命令、写状态,卡住再把问题抛回来。
说白了就是多让你花一些 Token,少一些人工成本。这下好懂了吧?
这篇文章不站队,也不跟着造词。我会把 Loop Engineering 放回已有的几个概念里看:它借了哪些老东西,哪些地方只是换了个说法,哪些部分确实值得在项目里补上。
从公开讨论看,这个词大概在 2026 年 6 月上旬 开始热起来。Addy Osmani 在 2026 年 6 月 7 日写了篇 Loop Engineering,随后 AI 圈开始反复讨论“让系统去提示 Agent”。
我个人的感觉是:新鲜的是名字,能力早就在往这个方向走了。Claude Code、Codex 里的 /loop、/goal、Automations、Skills、Sub-agent、工作区隔离、MCP/Connector,解决的都是一类问题:别让 Agent 只停在一轮回答里,给它边界,让它继续干活。
Loop Engineering 到底是什么?
如果用一句话概括,可以这么理解:
Loop Engineering 是围绕 Agent 设计可持续运行的反馈循环,让它在明确目标、工具、上下文、验证信号和停止条件下反复行动,直到任务完成、失败或需要人工接管。
落到工程上,主要看这些点:
- 触发:谁来启动这轮任务?手动命令、定时任务、CI 失败、PR 创建、Issue 更新,还是某个消息事件。
- 目标:什么状态算完成?全部测试通过、CI green、覆盖率达到某个数值、页面截图对齐设计稿,还是只生成待人工确认的草稿。
- 上下文:Agent 每轮要看哪些文件、规则、历史状态、工具结果和项目约定。
- 行动:Agent 能改代码、跑测试、查 GitHub、读日志、发 PR,还是只能输出建议。
- 观察:它怎么知道刚才那一步做对了?测试输出、lint、类型检查、截图、审查评论、日志摘要都可以是观察结果。
- 状态:这轮试过什么、失败在哪里、下一步做什么,要写到外部文件、Issue、Linear 卡片或数据库里,不能只靠当前对话记住。
- 停止:什么时候退出,什么时候转人工,什么时候因为预算或轮次耗尽直接停。
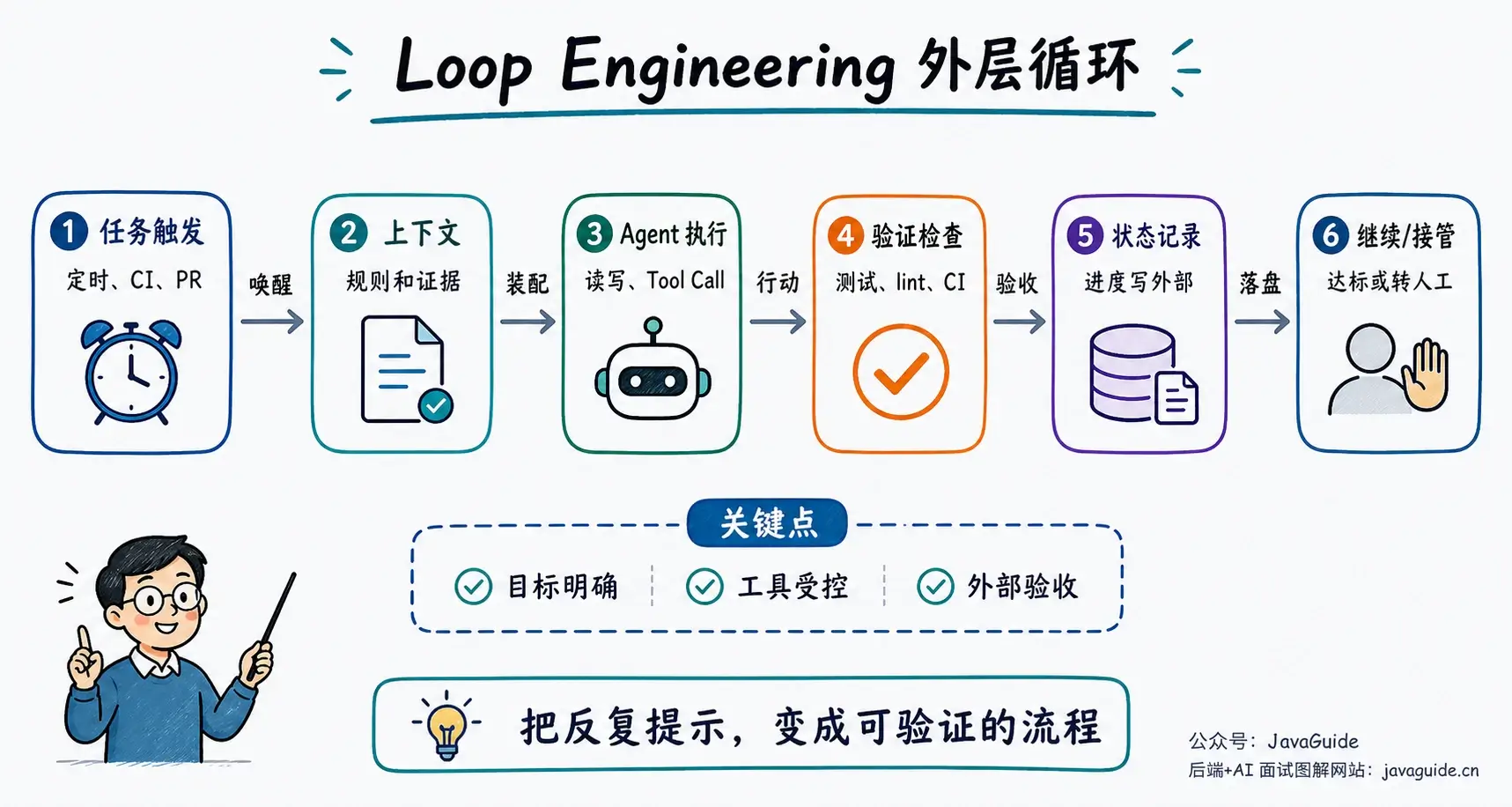
网上很多文章会把它说成“停止提示 Agent,开始写提示 Agent 的系统”。
这句话挺好传播,但容易把 Prompt 说没了。Loop 里的每一次模型调用,还是要靠 Prompt、上下文和工具描述工作。区别在于,工程师开始把注意力放到 Prompt 外面:谁来触发、带哪些材料、跑完以后用什么证据判断。
这个变化不小,但也没新到哪里去。
它其实借了哪些老概念?
Loop Engineering 其实很好理解,就是一些老概念的融合。
Agent Loop / ReAct:内层循环早就存在
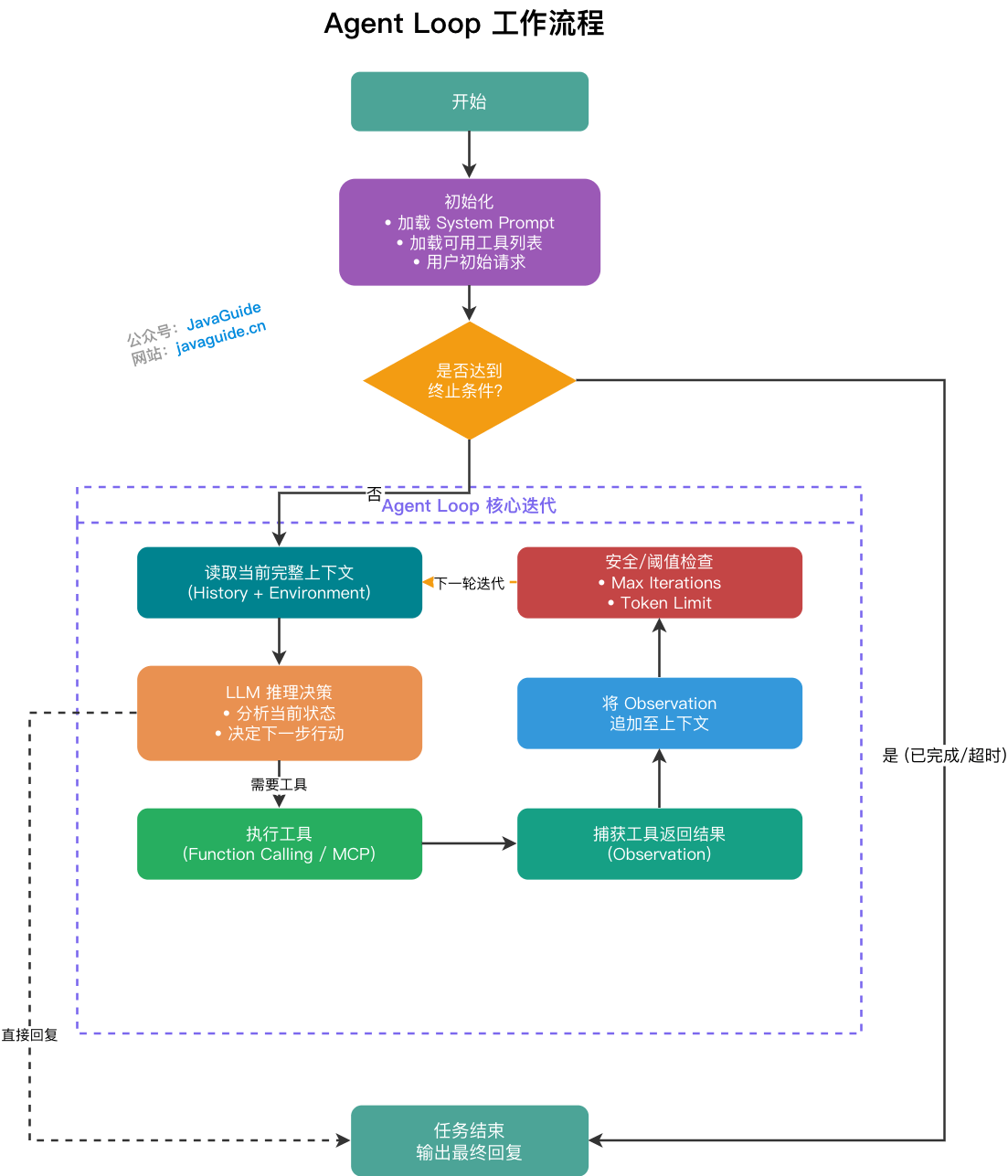
Agent Loop 很早就有了。一个最简单的 Agent 本来就是:
- 读取当前上下文。
- 让 LLM 判断下一步。
- 调用工具或输出答案。
- 把工具结果写回上下文。
- 继续下一轮,直到触发停止条件。
ReAct 也是这个思路:Reasoning 和 Acting 交替进行,模型走一步看一步,拿到外部反馈后再决定下一步。
我之前在 AI Agent 核心概念 里讲过,它适合处理路径不确定、需要根据证据调整方向的任务。查线上故障、读代码库、排查测试失败,都属于这一类。
这篇主要看外层。内层是 Agent 自己每一轮“推理、行动、观察”的循环;外层则负责隔一段时间启动 Agent、把工作分出去、检查结果、保存状态,决定下一轮还要不要继续。
| 层级 | 谁在循环 | 每轮做什么 | 典型停止条件 |
|---|---|---|---|
| 内层 Agent Loop | Agent 自己 | 思考、调用工具、观察结果、继续下一步 | 不再需要工具,返回最终结果 |
| 外层 Engineering Loop | 调度系统或人写的流程 | 唤醒 Agent、分配任务、验证结果、记录状态 | 达成目标、超预算、失败转人工 |
Workflow / Graph / Loop:可控回边早就有
在工作流图里,Loop 其实就是回边。

比如“生成初稿 → 审核 → 不通过就修改 → 再审核”,这本来就是 Graph 里的条件边和回边。我之前在 AI 工作流中的 Workflow、Graph 与 Loop 里讲过,可靠的 Loop 至少要写清三件事:
- 继续条件:为什么还要再跑一轮。
- 退出条件:什么结果算可以停。
- 安全边界:最大轮次、超时、Token 预算、失败后怎么降级。
Loop Engineering 把这个思路挪到了代码 Agent 的日常工作里。以前你可能在 LangGraph 或 Spring AI Alibaba Graph 里写循环;现在这个循环会跨过 Claude Code、Codex、CI、GitHub、Issue 系统和本地仓库。
Context Engineering:每一轮该给 Agent 看什么
Loop 一旦跑久,上下文问题很快就会冒出来。
一次对话里上下文塞多了,模型会变慢、变飘、漏掉中间信息。一个无人值守的 Loop 跑半天,情况只会更严重:工具输出越来越多,失败记录越来越多,旧结论和新结论混在一起,Agent 可能越跑越不像在解决问题。
所以,做 Loop 基本绕不开 Context Engineering。
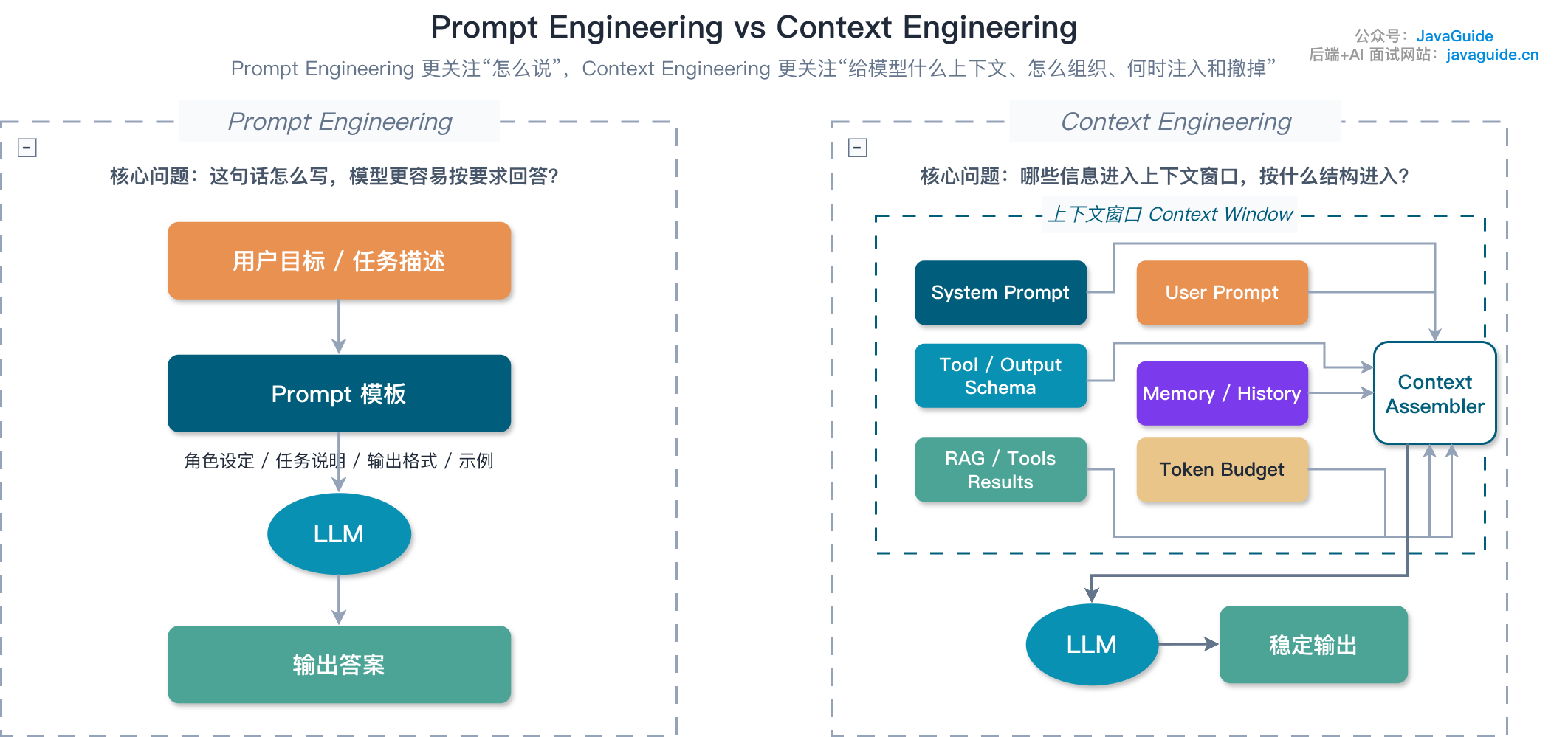
每一轮 LLM 调用前,都要重新决定该塞哪些材料:
- 哪些项目规则常驻,比如
AGENTS.md、CLAUDE.md、编码规范。 - 哪些内容按需加载,比如相关文件、测试输出、Issue 描述、设计文档。
- 哪些工具结果要摘要,哪些必须保留原始引用,比如 traceId、错误码、日志路径。
- 上下文快满时,是压缩历史、清理旧工具结果,还是把进度写进外部状态文件。
上下文管理没做好,Loop 很快就会变成高频率烧 Token。Agent 每一轮都重新读项目、重新猜规则、重新解释错误,最后越来越像一台很贵的复读机器。
Harness Engineering:模型外面的执行环境
我之前在 Harness Engineering 里用过一个说法:Agent = Model + Harness。模型负责推理和生成,Harness 负责环境、工具、反馈、沙箱、权限、观测和恢复。
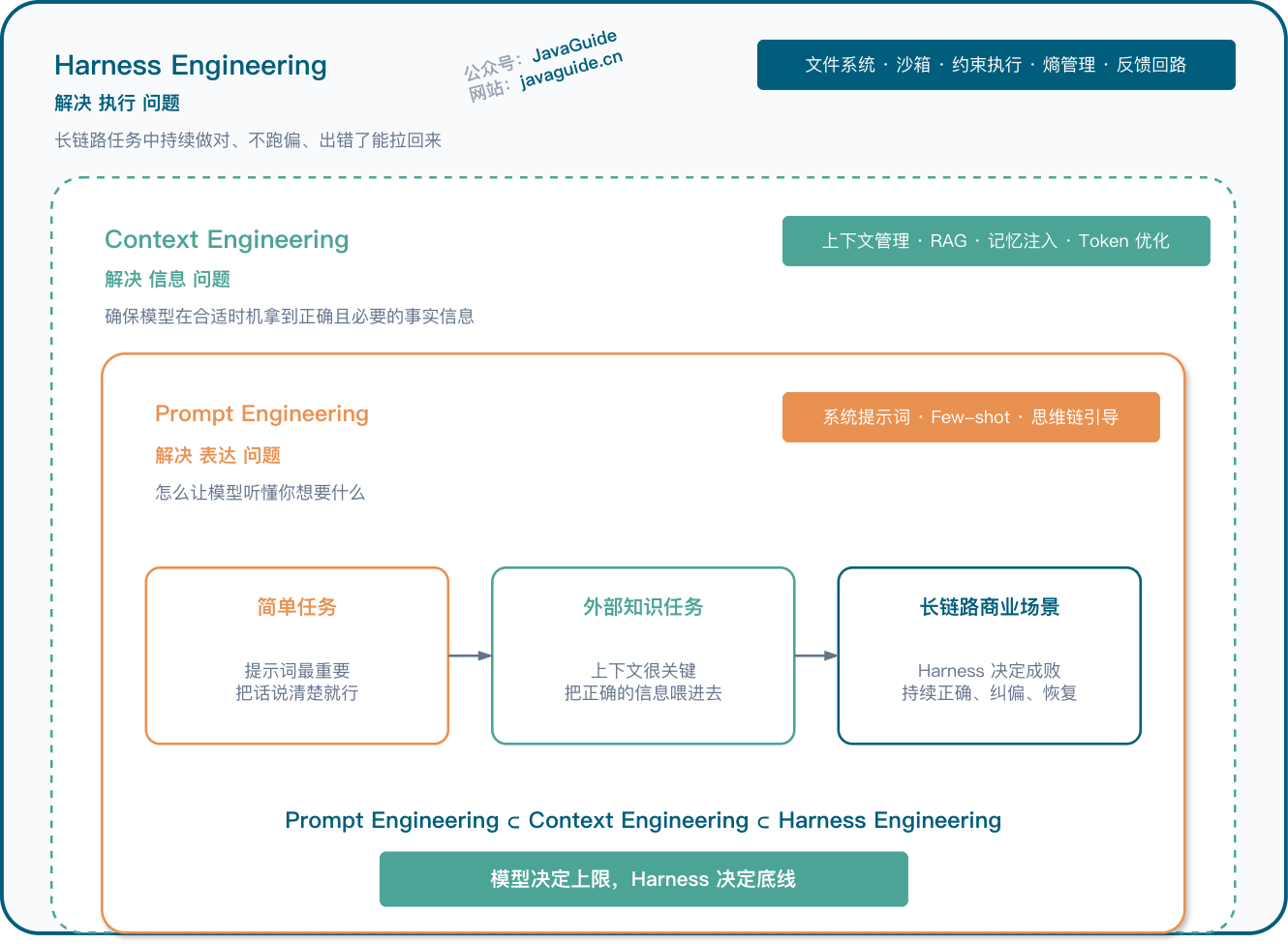
放到这套说法里,Loop Engineering 更像 Harness 外面的一层调度。Harness 解决一次任务怎么稳定执行;Loop 解决这套执行环境什么时候再启动、状态放在哪里、任务要不要分给多个 Agent。
如果 Harness 没做好,Loop 也跑不稳。Agent 不知道能不能改文件,不知道怎么验证,不知道失败后该重试还是停止,也不知道哪些操作必须等人确认。
Skills:把每轮都要重复解释的经验写下来
Skills 这块很容易被低估。
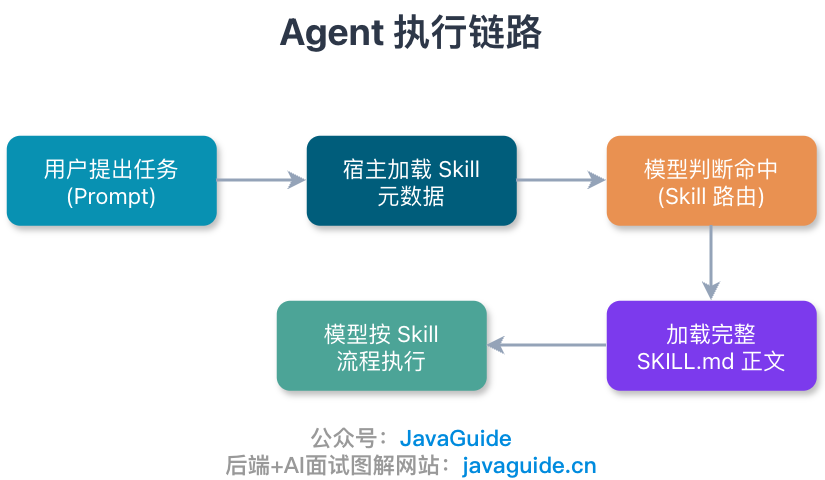
如果每天早上都有一个自动 Loop 去处理 CI 失败,它不能每次都从零开始理解你的项目:
- 这个仓库怎么跑测试?
- 哪些目录不能乱改?
- 生成代码后要跑哪些格式化命令?
- PR 描述按什么模板写?
- 碰到数据库迁移要不要先问人?
这些东西全靠 Prompt 现写,成本很高,也不稳定。更合适的做法是写成 Skill:用 description 做路由,用 SKILL.md 写流程、边界、命令和失败处理。Agent 命中任务时再加载正文,不需要每轮都把规则重新塞进上下文。
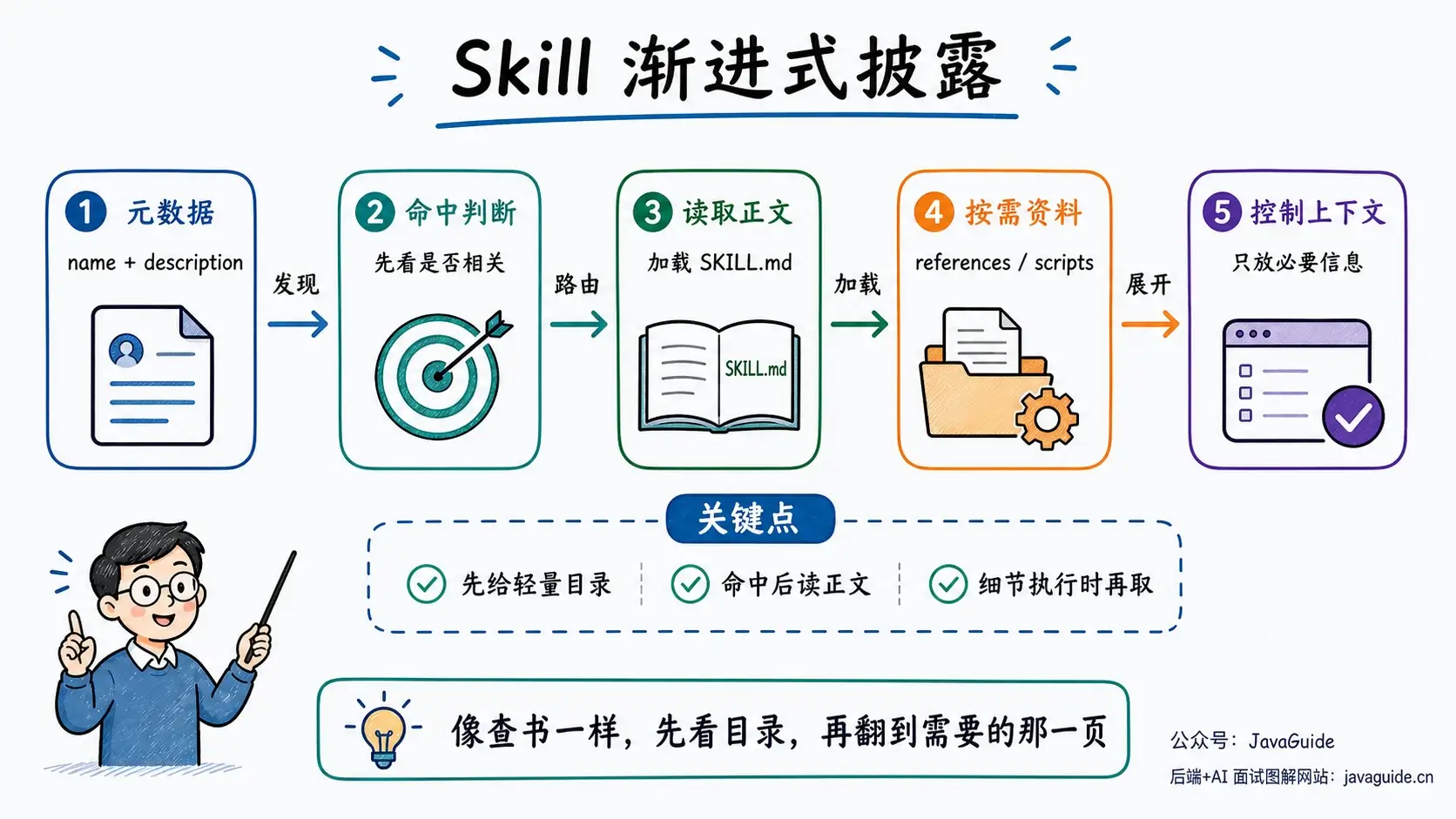
有了 Skills,Loop 不用每次重新学习你的项目。
MCP:让 Loop 能接触真实工具
一个只能读写本地文件的 Loop,能做的事情比较有限。实际能派上用场的 Loop,往往要查 GitHub、看 CI、读 Sentry、操作 Linear、访问数据库、发 Slack 消息。
这些能力如果全靠每个 Agent 平台单独适配,维护成本会很高。MCP 处理的就是工具接入碎片化问题。
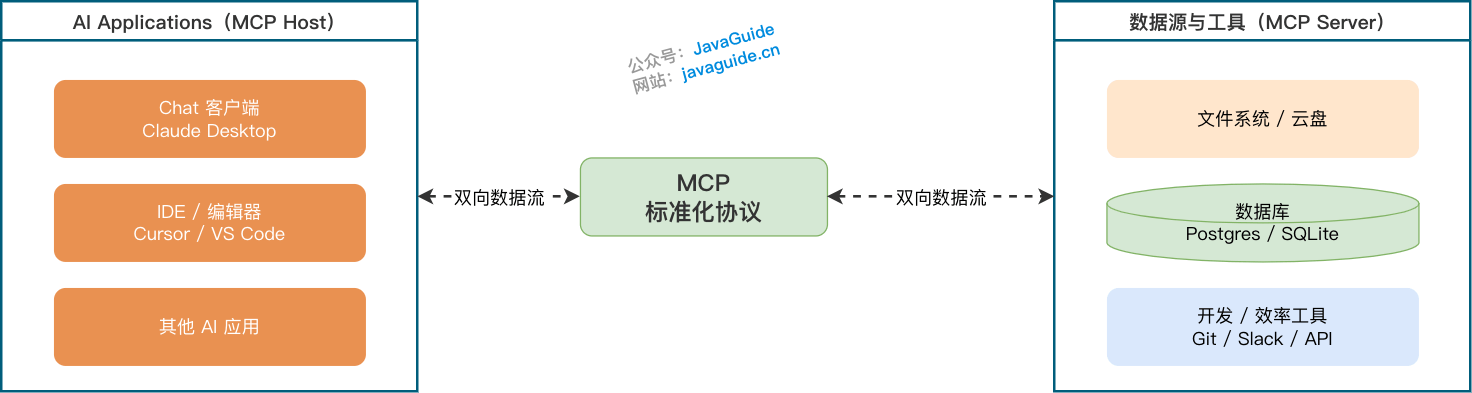
MCP 不负责让模型变聪明,它负责让工具以统一方式被发现和调用。GitHub、Issue 系统、日志平台、内部文档、数据库这些连接器,都可以通过 MCP Server 暴露出来。
风险也跟着来了。无人值守的 Loop 拿到过大的写权限,可能改错数据、发错消息、重复调用昂贵接口,甚至被提示词注入诱导去读不该读的文件。MCP 接进 Loop 之后,权限、审计、限流、脱敏和人工确认都要补上。
那它到底新在哪?
循环本身没什么新意。TDD 有循环,CI 有循环,ReAct 有循环,工作流图里也有循环。
这次被单独拿出来讲,主要是因为“谁来提示 Agent”开始变成工程问题。
以前大家更关心一句 Prompt 怎么写。现在要多想一步:这句 Prompt 由谁生成,什么时候生成,带哪些上下文,跑完以后用什么证据验收。
以前的代码 Agent 使用方式通常是这样:
- 你告诉它要做什么。
- 它改代码。
- 你跑测试。
- 测试失败,你把报错贴回去。
- 它再改。
- 你再看 diff、再判断要不要继续。
这中间有不少动作很机械:读错误、定位文件、重跑测试、更新待办、生成 PR 摘要。Loop Engineering 想处理的就是这部分重复劳动:
- 定时发现工作。
- 自动创建独立工作区。
- 调用项目 Skill。
- 让实现 Agent 处理。
- 让验证 Agent 检查。
- 写状态。
- 该继续就继续,该转人工就转人工。
这里麻烦的是循环边界:哪些步骤能自动化,哪些步骤必须停下来让人看。
Claude Code 的 /loop、/goal 可以怎么理解?
我在 Claude Code 核心命令详解 里专门写过 /loop。这里顺手把 /loop 和 /goal 分开说一下,这俩都和 Loop Engineering 有关,但用法差得挺远。

/loop 主要解决“过一会儿再看一次”的问题。它会在当前 session 里重复运行一个 prompt。你可以给固定间隔,比如每 5 分钟检查一次部署;也可以不给间隔,让 Claude 根据观察结果自己选择下一次等待多久。
裸 /loop 会运行内置 maintenance prompt,或者读取 .claude/loop.md、~/.claude/loop.md 作为默认 prompt。
/loop 5m "检查部署是否完成,并汇报当前状态"
/loop 30m /code-review
/loop "检查 PR 的 CI 和 review comments,有变化就处理,没有变化就延后"/goal 主要解决“这个目标有没有完成”的问题。你给它一个可验证完成条件,Claude 会一轮一轮推进;每轮结束后,由一个独立的小模型基于对话里已经出现的证据判断条件是否满足。不满足就继续,满足就停止。
/goal auth 模块所有单元测试通过,并且 npm test -- tests/auth 退出码为 0;最多 5 轮,连续 2 次失败原因相同就停止并汇报
/goal src/legacy 下组件迁移完成,npm run build 通过,且 git diff 只包含 src/legacy 和对应测试文件我自己的记法是:/loop 管下一次什么时候醒,/goal 管什么时候算做完。
Stop hook 或 Agent SDK 里的控制循环会再往前走一步。每轮结束后,用脚本、Prompt 或外部 evaluator 决定要不要继续。团队里做自动化时,通常更需要这类东西:确定性检查、权限拦截、状态落盘,都不能只交给模型口头判断。
“直到测试通过、最多尝试 5 次”这类任务,放在 /goal 里更顺;/loop 更适合部署轮询、PR babysit、长构建检查、定时 code review 这类“隔一段时间再看一次”的任务。
不过 /loop 也有限制。它更像 session-scoped 的临时调度:任务只在 Claude Code 运行且空闲时触发;关闭终端、会话退出、新开会话都会影响它;--resume 或 --continue 只能恢复未过期的任务;循环任务最多 7 天自动过期。
任务必须跨机器、跨重启、长期稳定运行时,还是应该考虑 Routines、Desktop scheduled tasks、GitHub Actions、CI/CD 或自己的任务调度系统。
我的使用习惯是:跑 /loop 前先收紧权限,写清楚轮询目标和停止条件;跑 /goal 前把完成条件写成可验证结果,并要求 Claude 展示测试、构建或 diff 检查结果。
关键路径先 commit,再让 Agent 自动改,方便回滚。
Loop 可以分成几类?
把 /loop 和 /goal 分开后,Loop Engineering 会好理解很多。它覆盖的是一组循环模式,不只是某一个命令。
| 类型 | 触发方式 | 适合任务 | 代表工具 |
|---|---|---|---|
| 时间驱动 Loop | 每 N 分钟、每天、每周 | PR babysit、CI 检查、日志巡检 | /loop、Codex Automations、cron |
| 事件驱动 Loop | CI 失败、Issue 创建、PR 更新 | 故障分拣、评论处理、告警摘要 | GitHub Actions、Webhook、Claude Code Channels |
| 目标驱动 Loop | 上一轮结束后检查目标是否满足 | 修测试、迁移 API、补覆盖率 | /goal、Stop hook、Agent SDK |
| 人工审批 Loop | 关键动作前停下来确认 | 高风险改动、发布、权限变更 | approval gate、draft PR、review queue |
这张表也能解释我前面那句“新瓶装旧酒”。触发、调度、验证、审批这些工程动作都不新,只是现在被重新摆到了代码 Agent 周围。
一个可落地的 Loop 长什么样?
下面这个例子按常见 CI 排查流程整理,不对应某家公司公开出来的完整实战案例。
假设目标是“每天自动处理 CI 失败”,个人建议第一版别上来就让 Agent 自动修代码,更不要自动合并。先做 triage 就够了。
第一版只看三件事:Agent 能不能找到正确证据,能不能区分事实和猜测,能不能按统一格式记录状态。这三件事都稳定了,再给它低风险修复权限。
我会把第一版压得很保守:
- 触发器:每天上午 9 点启动,或者 CI 失败后触发。
- 输入:读取最近一次 CI 失败、相关 PR、最近提交、失败测试日志。
- 上下文:加载项目
AGENTS.md和ci-triageSkill,只读取相关模块文件。 - 行动:分析失败原因,判断是环境抖动、测试不稳定、代码回归,还是依赖问题。
- 验证:如果能在本地复现,就跑最小测试集;不能复现就保留证据。
- 状态:把结论写入
TODO.md、GitHub Issue 或 Linear 卡片。 - 输出:生成一份简短报告,标记“可自动修复”“需要负责人确认”“疑似偶发”。
- 停止:不直接推送代码,不改生产配置,不连续重试超过 3 次。
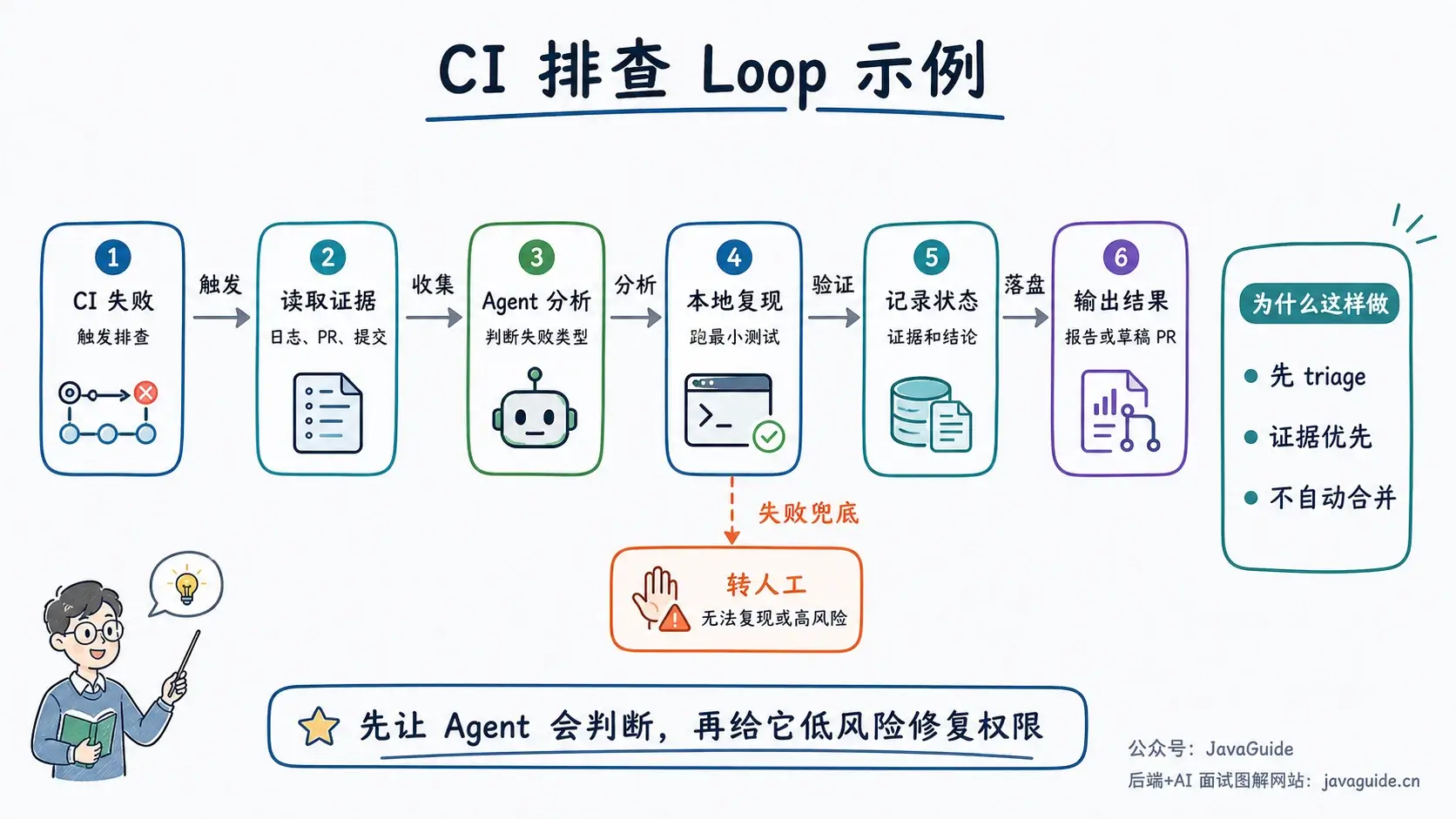
等这个版本稳定之后,再逐步加自动修复:
- 对“依赖版本冲突”“格式化失败”“明显的测试快照更新”这类低风险问题,可以开独立 worktree 让 Agent 尝试修。
- 修完后必须跑目标测试。
- 通过后只创建 PR,不自动合并。
- 另一个审查 Agent 根据项目 Skill 和 diff 做二次检查。
- 失败或不确定时回到人工队列。
这个 Loop 里能看到前面提到的几个部件:
| 部件 | 在这个例子里做什么 |
|---|---|
| Automation | 每天或 CI 失败时启动 |
| Skill | 固化 CI 排查流程、测试命令、仓库规则 |
| MCP / Connector | 读取 GitHub、CI、Issue、日志平台 |
| Context Engineering | 只加载失败相关日志、文件和规则 |
| Worktree | 隔离自动修复分支,避免污染主工作区 |
| Sub-agent | 一个负责实现,一个负责验证 |
| Memory / State | 记录已尝试方案、失败原因和下一步 |
| Stop Condition | 测试通过、达到重试上限、遇到高风险操作 |
“每天 9 点运行”只是触发器。支撑这个 Loop 的,是每一步的外部证据:CI 链接、失败日志、最小复现命令、测试结果、PR diff、人工确认状态。没有这些证据,Loop 只是自动重复 Prompt。
这块的价值不在“Agent 会写代码”本身。模型、上下文和工具决定代码写得怎么样;Loop 负责把反馈、记录和停止条件放进流程里。
什么场景值得做 Loop?
我一般看三点:任务会不会重复,验收信号硬不硬,失败后能不能回滚。
比较适合的场景:
- CI 失败初步排查:有日志、有测试结果、有明确失败信号。
- 依赖升级:可以在独立分支里改,靠测试和构建验证。
- 测试覆盖率补齐:目标可以量化,比如某模块覆盖率从 62% 提到 75%。
- 文档同步:根据最近 diff 更新用户文档或 API 文档,最后走人工 review。
- 大规模机械迁移:例如 CommonJS 到 ESM、旧组件 API 替换、格式化修复。
- PR / Issue 分拣:读信息、归类、补充摘要、标记优先级。
不太适合的场景:
- 目标很虚,比如“让产品体验更好”“想一个增长策略”。
- 验证信号很弱,只能靠 Agent 自己说“我觉得可以了”。
- 一旦做错影响很大,比如生产数据库写操作、权限系统变更、支付链路改造。
- 强依赖人的审美和业务判断,比如品牌文案定调、复杂产品取舍。
- 没有测试、没有日志、没有回滚方式的老项目大改。
有个很现实的判断:你自己都说不清怎么验收,就别急着 loop。先把目标拆小,把验收标准写出来。
最容易踩的坑
目标写得太虚
Loop 最怕“继续优化一下”这种指令。它会努力优化,但不知道该在哪里停。
不好的写法:
/goal "优化这个项目,让代码质量更好"更稳的写法:
/goal "auth 模块失败的单元测试全部通过,只允许修改 src/auth 和 tests/auth;每轮修改后运行 npm test -- tests/auth 并展示退出码;最多 5 轮;如果连续 2 次失败原因相同,停止并汇报"后者虽然长,但范围、验证命令、轮次上限、失败退出条件都写出来了。Agent 不需要猜。
把 Agent 自评当验收
让写代码的 Agent 自己判断“是否完成”,风险很高。它会倾向于相信自己的方案。
更稳的做法是 maker-checker 分离:一个 Agent 实现,另一个 Agent 审查;或者用更硬的信号,比如测试、类型检查、lint、截图对比、人工审批。越接近生产,越不能只靠自然语言自评。
可靠的 Loop 要靠外部信号兜底:测试退出码、CI 状态、lint、类型检查、截图对比、人工审批或独立评审 Agent。
忘了成本上限
Loop 会放大 Token 消耗。一次任务里,Agent 会读文件、跑工具、解释报错、压缩上下文、调用子 Agent、再让审查 Agent 看一遍。循环次数一多,账单很快就有存在感。
预算也要写进设计里:
- 最大迭代次数。
- 最大工具调用次数。
- 单日或单任务 Token / 金额预算。
- 无进展检测,比如两轮失败原因相同就停。
- 低价值任务只做摘要,不自动修复。
这属于架构约束,跟抠门没关系。
权限给得太大
Loop 可以自己跑,权限就不能像手动会话一样随意给。
本地文件、数据库、GitHub、Slack、CI、内部工单系统,全都要分清只读和写操作。读日志和开 PR 是两回事,开 PR 和自动合并又是两回事。删除文件、改生产配置、发外部消息、写数据库,这些最好默认需要人工确认。
MCP Server 也要审核来源和工具描述。工具 description、返回内容、Prompt 模板都可能携带注入内容,别把“能接入”当成“能放心接入”。
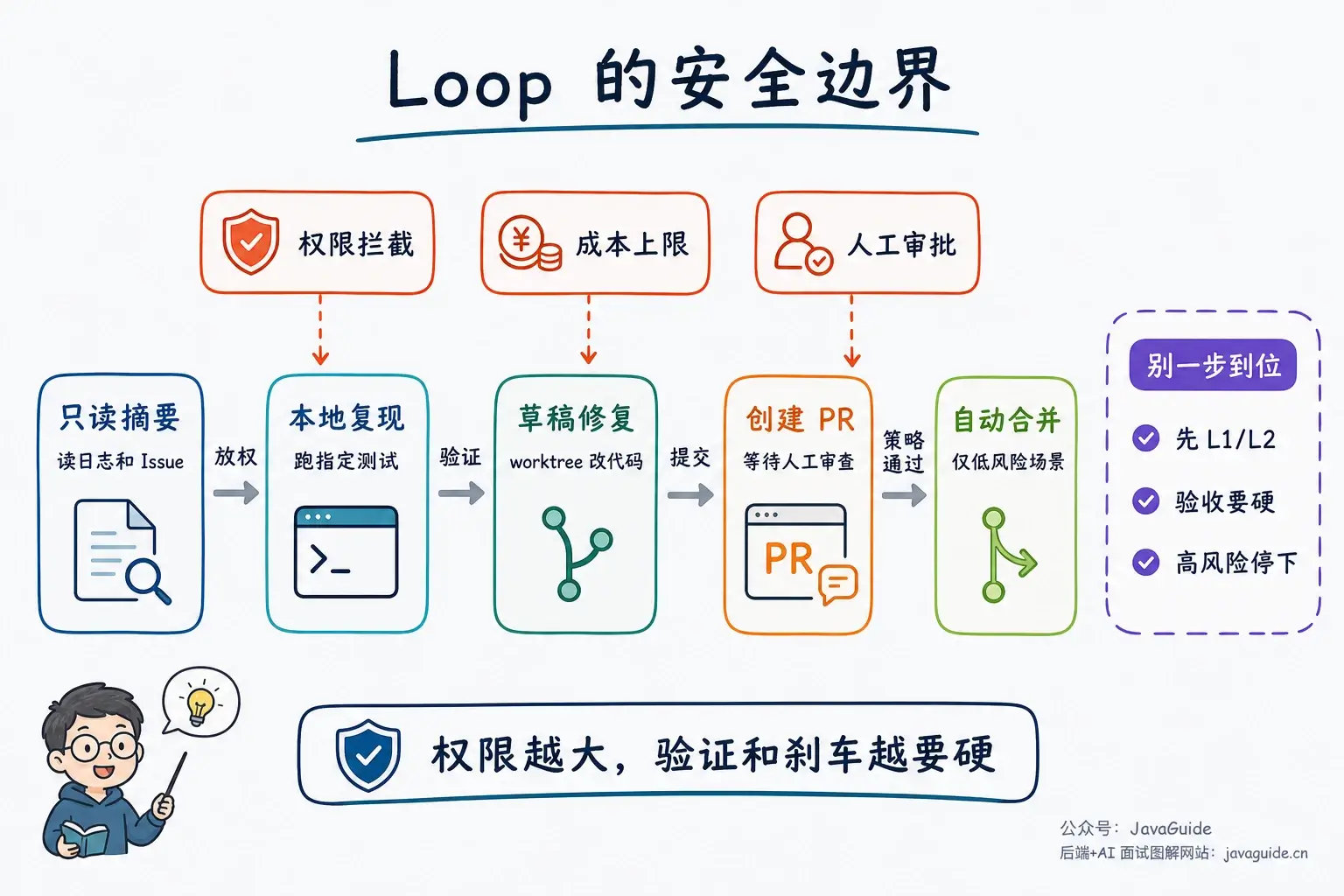
权限最好分级给,不要一步到位给写权限。
| 阶段 | Agent 能做什么 | 人负责什么 |
|---|---|---|
| L0 只读摘要 | 读日志、读 Issue、生成报告 | 判断是否采纳 |
| L1 本地复现 | 运行指定测试、定位失败 | 决定是否修复 |
| L2 草稿修复 | 在 worktree 里改代码、跑测试 | Review diff |
| L3 创建 PR | 提交分支、写 PR 描述 | 审查、合并 |
| L4 自动合并 | 通过策略后自动合并 | 只处理异常 |
绝大多数团队先做到 L1/L2 就已经有价值。L4 我会放得很晚:问题类型要固定,测试要能兜住,回滚也要顺手。只要牵到业务判断、权限、数据写入,就别急着自动合。
第一版先别急着自动修
第一次做 Loop,我不建议直接上无人值守自动修复。可以从只读 triage 开始。
第一版可以写得啰嗦一点,像这样放进 Skill 或任务描述里:
任务:每天看最近 24 小时的 CI 失败,产出排查摘要,供人处理。
允许做:
- 读 GitHub Actions、最近提交、失败测试日志,以及和报错直接相关的文件。
- 定位到具体测试时,可以跑对应测试确认是否复现。
- 把结论写进 TODO.md,带上 CI 链接、关键错误和建议负责人。
开始前:
- 先读取 AGENTS.md。
- 命中 CI 排查任务时加载 ci-triage Skill。
不允许做:
- 不改代码,不创建 PR,不发 Slack/邮件。
- 不读取整仓无关文件,不粘贴完整日志。
- 超过 10 个失败项就停;单个失败最多复现 2 次。
- 权限不足、日志缺失、需要业务判断时,直接标记人工处理。这个版本不花哨,但胜在稳。它不会乱改代码,也能帮你观察 Agent 会不会误读日志、会不会乱找文件、会不会重复调用工具。等它的 triage 稳了,再考虑给低风险修复权限。
如果这个 Loop 要跨天运行,还需要一份外部状态。不要指望下一轮对话还能完整记住前一天试过什么。最小状态文件不用复杂,能让人和 Agent 都看懂就行:
loop_id: ci-triage-2026-06-17
goal: "排查最近 24 小时 CI 失败"
status: running
scope:
repos: ["backend-service"]
max_items: 10
attempts:
- item: "auth-test failure"
evidence: "GitHub Actions run #12345"
action: "ran npm test -- tests/auth"
result: "reproduced locally"
next_step: "ask auth owner to review"
stop_condition:
max_attempts: 3
require_human_when:
["permission_missing", "production_change", "uncertain_root_cause"]这个文件可以是 Markdown、YAML、Issue comment、Linear 卡片或数据库记录。别纠结格式,重点是别只存在聊天记录里。
如果你要做自动修复,再补四条:
- 修改前创建独立 worktree 或分支。
- 修改范围白名单。
- 只允许跑指定测试和格式化命令。
- 通过后只开草稿 PR,不自动合并。
总结
Loop Engineering 这个词确实有包装味。它把很多早就存在的东西合在一起:Agent Loop、ReAct、Workflow Graph、Context Engineering、Harness、Skills、MCP、Memory、CI、测试、代码审查。
但它提醒了一个变化:Agent 能连续读文件、改代码、跑测试、开 PR 之后,工程师不能只盯着下一句 Prompt,还要设计它能在哪些边界里自己推进。
这里面最重要的是目标、工具、上下文、验证和刹车。刹车没写好,Loop 会更快地制造混乱;刹车写好了,它才有机会把重复劳动接过去。