TCP Keepalive 和 HTTP Keep-Alive 有什么区别?
你好,我是小 G。TCP Keepalive 和 HTTP Keep-Alive 的对比,经常作为面试题出现在技术面试中。这篇文章来详细聊一聊。
简单来说,这俩只是后缀名字一样,但完全不是一回事,毕竟一个在应用层,一个在传输层,根本不在同一层:
- HTTP Keep-Alive 是应用层的机制,解决的问题是:一个 TCP 连接能不能被多个 HTTP 请求复用,别每次请求都重新握手。
- TCP Keepalive 是传输层的机制,解决的问题是:一条 TCP 连接长时间没有数据往来,怎么判断对端还在不在,要不要把连接占用的资源回收掉。

一个管“连接要不要复用”,一个管“连接还活不活着”。协议层不同,目的也不同,只是名字撞了。
下面分开讲。
HTTP 的 Keep-Alive 是什么?
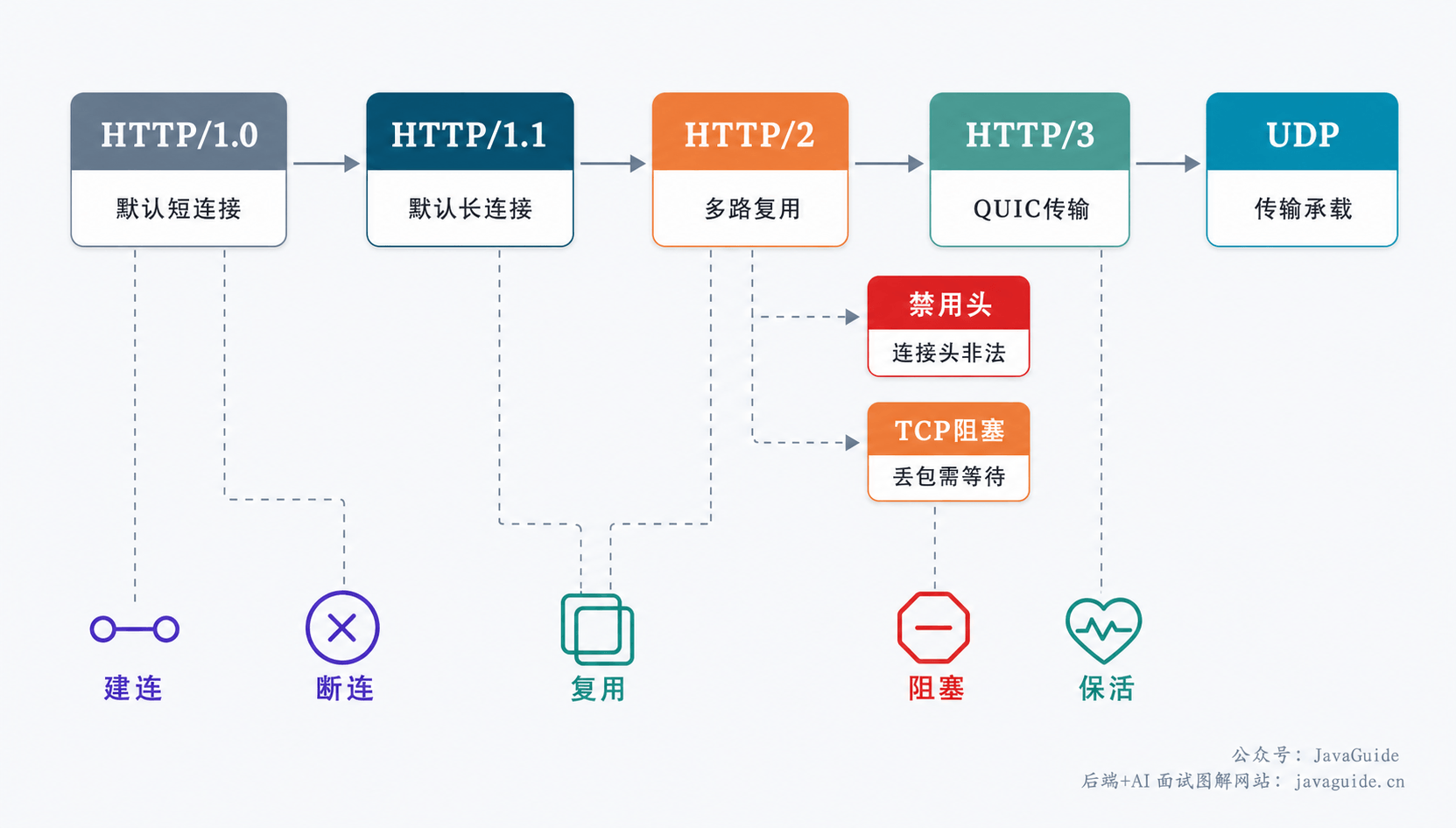
先说问题。HTTP 1.0 的默认行为是:每个 TCP 连接只服务一次 HTTP 请求和响应。服务器发完响应,马上发起关闭连接的请求,客户端跟着关,TCP 连接就双向断开了。
你打开一个网页,HTML、CSS、JS、图片可能有几十个资源要加载。如果每个资源都独立建连接再销毁,光三次握手和四次挥手的开销就不小,TCP 连接的利用率很低。
这个问题很明显:为什么一个 TCP 连接不能服务多次 HTTP 请求呢?
于是 HTTP 引入了 Connection 头部。以 HTTP/1.0 为例,客户端可以在请求头里带上:
Connection: Keep-Alive服务器如果也在响应头里确认这个字段,就表示双方都同意这次 HTTP 交易用到的 TCP 连接是一个长连接(Persistent Connection)——请求/响应结束后先别关,后续其他 HTTP 请求还可以接着复用这条连接,直到连接空闲超时、达到请求次数上限,或者被任意一方主动关闭。
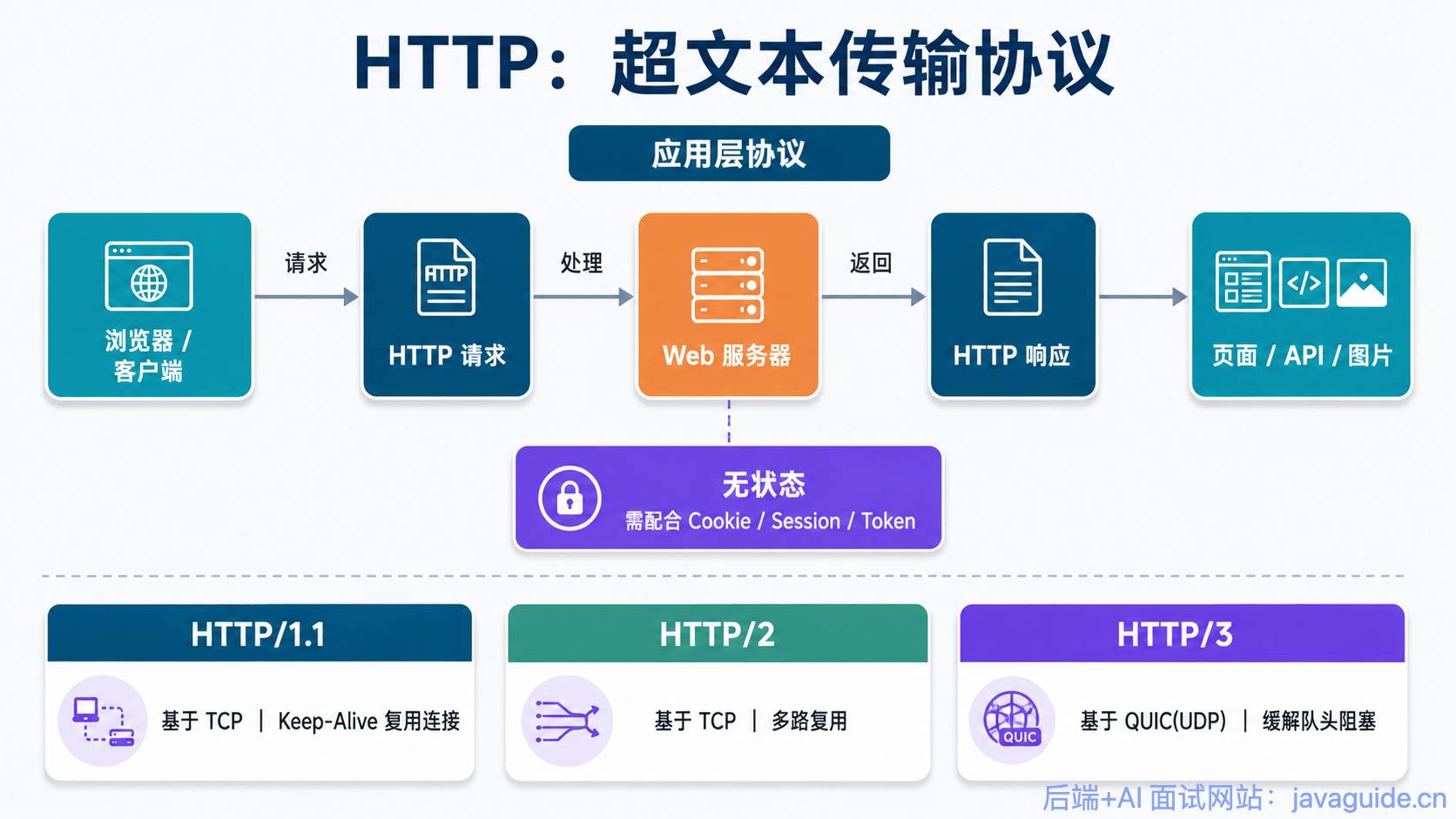
在不同 HTTP 版本里,Keep-Alive 的默认行为不一样:
- HTTP 1.0:默认是短连接。要用长连接,请求头里得显式带上
Connection: Keep-Alive,而且服务器也要在响应头里带上这个字段才算生效。 - HTTP 1.1:默认就是长连接,不需要额外声明。如果希望请求结束后关闭连接,需要显式指定:
Connection: close。这也是为什么 HTTP/1.1 相比 HTTP/1.0 能明显减少 TCP 建连和挥手开销。 - HTTP/2:HTTP/2 不再沿用 HTTP/1.x “一个连接串行处理多个请求”的方式,而是引入了多路复用(Multiplexing),也就是说一个 TCP 连接上可以同时并发多个 Stream,请求和响应可以交错传输,不再互相阻塞,解决了 HTTP/1.1 应用层的队头阻塞问题。不过,HTTP/2 依然跑在单条 TCP 连接上,一旦底层 TCP 出现丢包,后续数据仍然要等待重传,因此它依然会受到 TCP 层队头阻塞的影响。这种基于 HTTP/1.x 的连接控制方式在 HTTP/2 中已经没有意义了。更严格地说,
Connection、Keep-Alive、Transfer-Encoding等 connection-specific headers 在 HTTP/2 中是被禁止使用的,带有这些头部的消息会被视为不合法。 - HTTP/3:HTTP/3 基于 QUIC,运行在 UDP 之上,不再依赖 TCP 连接,也不使用 HTTP/1.x 的
Connection: Keep-Alive这套连接控制方式。QUIC 自己负责连接管理、保活和多路复用,并在传输层面缓解了 TCP 队头阻塞问题。
一句话总结:HTTP/1.0 需要显式 Keep-Alive,HTTP/1.1 默认连接复用,HTTP/2 从“连接复用”升级成了“单 TCP 连接上的多路复用”,而 HTTP/3 则直接换成了基于 QUIC 的连接管理。
HTTP 长连接怎么关闭和回收?
长连接提高了 TCP 利用率,但也带来一个新的问题:客户端打开一个页面,TCP 连接建好了,结果用户就把页面扔在那里不管了。这条连接一直空闲着,服务器不能无限等下去,但也不能完全靠客户端自觉关闭。
如果这类空闲连接堆积多了,服务器的 TCB(TCP Control Block)资源会被白白占掉。
HTTP 的解决办法是在 Keep-Alive 头部里带两个参数:
Keep-Alive: timeout=5, max=10- timeout=5:连接空闲超过 5 秒,服务器就可以关闭。
- max=10:这条连接最多服务 10 次 HTTP 请求,到了次数上限就强制关闭。
这里有个点容易忽略:到了 timeout 或 max 的阈值,不管客户端当时在不在线,服务器都可以关闭连接。 如果客户端刚好复用这条旧连接发送新请求,就可能遇到连接已经关闭、请求失败后需要重试的情况。
也就是说,HTTP Keep-Alive 的空闲连接回收通常由服务器配置主导。客户端当然可以主动关闭连接,但服务器不会一直等客户端“表态”。
在实际的 Web 服务器配置中,这些参数由服务端决定。比如 Nginx 的 keepalive_timeout 默认值是 75 秒,keepalive_requests 默认值是 1000(Nginx 1.19.10 之前的版本默认是 100)。
TCP 的 Keepalive 是什么?
TCP Keepalive 要解决的问题完全不一样:它不关心连接上跑不跑 HTTP 请求,它关心的是——对端到底还在不在。
考虑这样一个场景:客户端和服务器之间建了一条 TCP 连接,但客户端突然断电了、网线被拔了、或者系统直接崩了。这时候服务器这边完全不知道对面已经没了,因为 TCP 又不像打电话,没有“忙音”。这条连接就变成了一条“半打开”(Half-Open)的死连接,白白占着服务器内存中的 TCB 资源。
TCP Keepalive 就是用来发现这种情况的。它的工作流程如下:
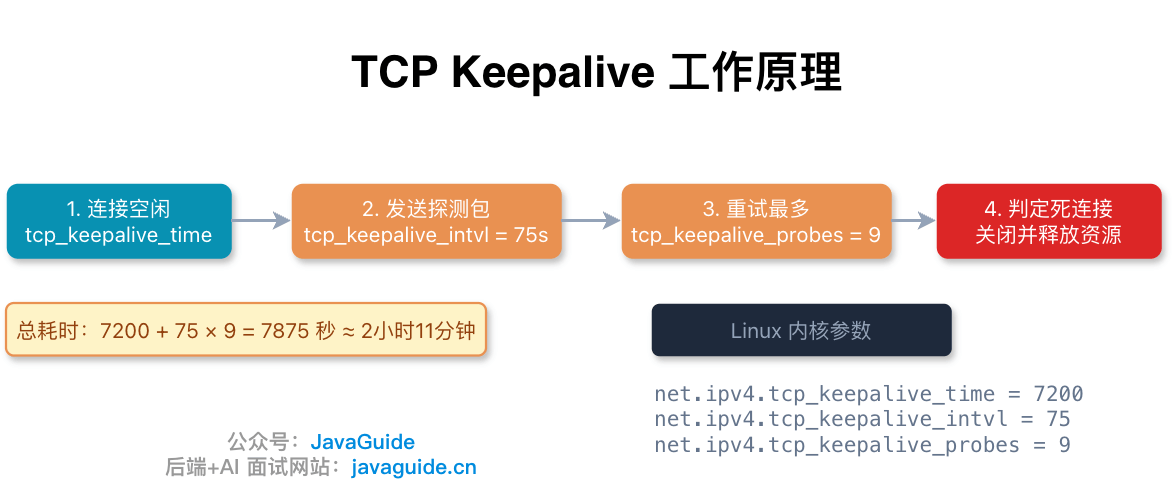
- 一条 TCP 连接上如果一段时间没有任何数据往来(默认 7200 秒,也就是 2 小时),内核会自动给对端发一个探测报文(Probe)。
- 如果对端正常在线,会回复一个 ACK,然后计时器重置,再等 2 小时。
- 如果对端没有回复,每隔 75 秒 重发一个探测包,最多重试 9 次。
- 9 次都没回复,内核判定连接已死,发 RST 关闭连接,释放资源。
这三个参数在 Linux 上对应的内核配置是:
| 参数 | 含义 | Linux 默认值 |
|---|---|---|
tcp_keepalive_time | 连接空闲多久后开始发送探测包 | 7200 秒(2 小时) |
tcp_keepalive_intvl | 两次探测包之间的间隔 | 75 秒 |
tcp_keepalive_probes | 最多发送几次探测包 | 9 次 |
macOS 属于 BSD 系网络栈风格,没有 net.ipv4.*,对应的是:net.inet.tcp.*。

按默认值算,从连接开始空闲到最终被判死,最长要等 7200 + 75 × 9 = 7875 秒,差不多 2 小时 11 分钟。
可以通过 sysctl 查看和修改:
sysctl net.ipv4.tcp_keepalive_time
sysctl net.ipv4.tcp_keepalive_intvl
sysctl net.ipv4.tcp_keepalive_probes还有一个很容易踩的坑:TCP Keepalive 默认是关闭的。 应用程序必须在创建 socket 时通过 SO_KEEPALIVE 选项显式开启,否则内核不会发探测包。这在 RFC 1122 里有明确规定:Keepalive 是可选功能,必须默认不启用。
理解了工作原理之后,TCP Keepalive 的性质就很清楚了——它是一种“温和”的资源回收机制。它只能在确认对方不在线之后才回收资源。只要对方还在线、还能回 ACK,这条连接就只能继续维持着,定时器重置,再等下一个 2 小时。对方在线的时候,服务器没有任何办法通过 TCP Keepalive 来关掉这条连接。
这和 HTTP Keep-Alive 的“到时间就关,不管你在不在”形成了鲜明的对比。
TCP Keepalive 探测后会出现哪几种情况?
内核发出探测报文后,根据对端的实际状态,会走向不同的结果:
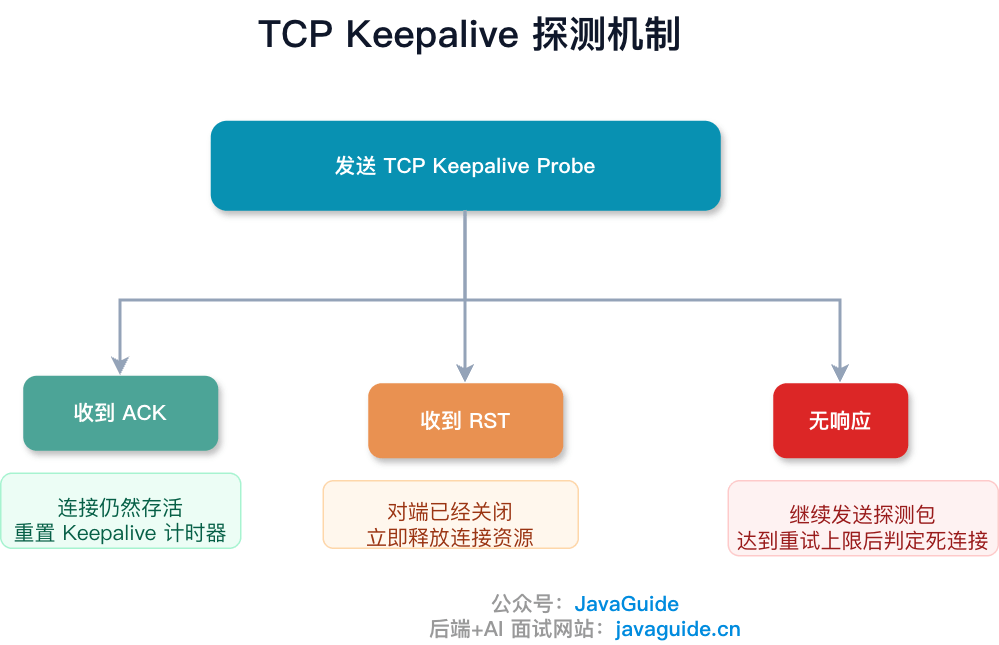
1. 对端正常在线
对端收到探测包,TCP 栈回复一个 ACK。发送方收到 ACK,把空闲计时器重置为 tcp_keepalive_time,继续等待。连接不会被关闭。
2. 对端曾经崩溃,但已经重启
对端虽然在线,但由于重启过,内核里已经没有这条连接的上下文了。收到探测包后,对端的 TCP 栈会回复一个 RST(因为它不认识这条连接)。发送方收到 RST,立即关闭连接。
3. 对端崩溃且未恢复,或者网络不可达
探测包发出去后得不到任何回复。发送方每隔 tcp_keepalive_intvl 秒重试一次,连续 tcp_keepalive_probes 次都没响应,判定连接已死,内核关闭连接并释放资源。
第 3 种情况也覆盖了一些中间网络设备导致的问题。比如 NAT 网关通常有会话超时机制,如果一条连接长时间没有数据传输,NAT 表项会被清掉。后续的探测包就没法到达对端,效果和对端崩溃一样——都是得不到回复,最终超时关闭。
TCP Keepalive 有什么局限?
这里的 TCP Keepalive 指的是 TCP 层的 keep-alive 探测机制,不是 HTTP 的 Keep-Alive 连接复用。它能检测死连接,但在生产环境中,光靠它通常不够,原因有几个:
默认探测太慢了。 以 Linux 默认配置为例,连接空闲 7200 秒后才开始发送探测;Windows 默认 keep-alive timeout 也是 2 小时。这个量级对大部分在线业务连接来说都偏长。Linux 的 net.ipv4.tcp_keepalive_* 是系统默认值,会影响未单独设置的连接;如果应用需要按连接区分策略,可以在支持的平台上逐 socket 设置 TCP_KEEPIDLE、TCP_KEEPINTVL、TCP_KEEPCNT。不过,这类选项不适合写成跨平台通用方案,具体还要看操作系统和语言运行时是否暴露。
只能检测连接存活,不能检测应用健康。 TCP Keepalive 的探测包是内核发的,对端的 TCP 栈收到后直接回 ACK,应用层完全不参与。所以它只能说明对端内核还能收到包并返回 ACK,不能说明对端应用线程池、事件循环、数据库连接池、业务依赖是否正常。这是它最大的盲区。
经过中间层时容易看错对象。 如果客户端和服务器之间有 NAT、四层负载均衡或反向代理,要先看 TCP 连接有没有被中间层终止。如果中间层只是做 NAT/连接跟踪,Keepalive 间隔需要小于中间设备的空闲超时,才可能避免表项被清掉;如果中间层终止了 TCP 连接,后端检测到的只是后端到中间层这一段连接是否存活,不代表真实客户端一定还活着。
各操作系统的实现和默认值不一致。 比如 Linux 默认是 7200 秒后开始探测、75 秒间隔、最多 9 次;Windows 默认 timeout 也是 2 小时,但 interval 默认 1 秒,Windows Vista 及之后 probe 次数固定为 10,不能改;macOS 属于 BSD 系网络栈风格,没有 Linux 的 net.ipv4.* 这组 sysctl,相关参数通常在 net.inet.tcp.* 下面。靠 TCP Keepalive 做跨平台连接健康检查,一致性很难保证,具体参数名、单位和默认值最好以目标系统实测为准。
不直接作用于 HTTP/3/QUIC。 对真正的 HTTP/3/QUIC 连接来说,TCP Keepalive 不参与连接存活检测;但客户端如果因为 UDP 被阻断等原因回退到 HTTP/1.1 或 HTTP/2,那回退后的 TCP 连接仍然可能受 TCP Keepalive 影响。HTTP/3 的连接存活和超时由 QUIC 处理,例如 QUIC 有 idle timeout,必要时可以发送 PING frame 做 liveness testing;HTTP/3 层关闭连接时还可以用 GOAWAY 协助优雅关闭。
所以实际工程中,TCP Keepalive 更多是作为兜底手段,帮你清理那些明确已经死掉的连接。如果需要更快速、更细粒度、且能感知应用层状态的健康检查,还是得在应用层自己做心跳,比如 WebSocket 的 Ping/Pong、gRPC 的 keepalive ping,或者业务自定义的心跳协议。
应用层心跳也不是越频繁越好。心跳间隔太短会增加包量、服务端定时器压力和弱网误判概率;间隔太长又发现故障不及时。实际配置要结合连接规模、NAT/LB idle timeout、业务可接受的故障发现时间一起定。
TCP Keepalive 和 HTTP Keep-Alive 对比总结
| 对比维度 | HTTP Keep-Alive | TCP Keepalive |
|---|---|---|
| 所属层 | 应用层(HTTP 协议) | 传输层(TCP 协议) |
| 解决的问题 | 复用 TCP 连接,减少重复建连、挥手、慢启动等开销 | 探测长时间空闲的 TCP 连接,对端失联后释放连接资源 |
| 默认行为 | HTTP/1.0 默认短连接;HTTP/1.1 默认长连接 | 默认关闭,应用需要显式开启 SO_KEEPALIVE |
| 控制粒度 | 由 HTTP 客户端、Web 服务器或代理按连接策略控制 | 由操作系统内核控制,也可在部分平台逐 socket 调整 |
| 常见参数 | Connection、Keep-Alive: timeout/max、服务器超时配置 | tcp_keepalive_time/intvl/probes 或平台对应参数 |
| 关闭触发 | 到达空闲超时、请求次数上限,或任意一方主动关闭 | 空闲后发探测包,多次无响应或收到 RST 才关闭 |
| 对端在线时 | 服务端仍可按配置主动回收空闲连接 | 只要对端内核能回 ACK,连接通常继续维持 |
| 能否替代心跳 | 不能判断业务是否健康,只能管理 HTTP 连接复用 | 不能判断应用线程池、事件循环、业务依赖是否正常 |
| 中间层影响 | 代理、网关可独立管理前后两段 HTTP/TCP 连接 | NAT/LB/反向代理可能让你探测到的只是某一段 TCP 连接 |
| HTTP/2/3 关系 | HTTP/2 禁用连接级头;HTTP/3/QUIC 不使用这套机制 | 只作用于 TCP;真正的 HTTP/3/QUIC 连接不受它直接影响 |
如果从“谁来决定关连接”的角度看,两个机制的态度完全相反:
HTTP Keep-Alive 是“主动回收”——服务器到了超时或请求次数上限,就可以按自己的配置关闭连接,不需要先探测对方是否在线。它是一种比较主动的资源回收方式。
TCP Keepalive 是“被动回收”——它必须先发探测包去问“你还在吗?”。只要对方在线、能回 ACK,服务器就只能继续维持连接,刷新定时器。只有确认对方已经不在了,才能释放资源。这是一种温和的回收策略。
实际项目中,两者经常同时在跑,各管各的。HTTP Keep-Alive 管的是“一条连接最多用多久、服务多少次请求”,TCP Keepalive 管的是“如果长时间没数据,检查一下对方是不是已经消失了”。两者互不干扰,也不能互相替代。