MiniMax M3 + Claude Code 实战:Redis 故障排查、SCAN 算法复刻与监控面板搭建
你好,我是小 G。MiniMax M3 前几天发布了,不少朋友第一时间用上,反馈都还不错,也有不少朋友留言让我实测一波。
不是不想测,前几天确实太忙了,想赶在秋招之前对 JavaGuide 进行一波优化,这是每一年都会做的事情。
根据官方介绍,M3 是首个同时具备 Coding Frontier/SOTA + 1M 上下文窗口 + 原生多模态 三个核心能力的开源模型,直接把闭源模型级别的编程与长任务能力开放出来。
实测分数:项目级修复 59.0%,终端任务 66.0%,MCP 工具链 74.2%。
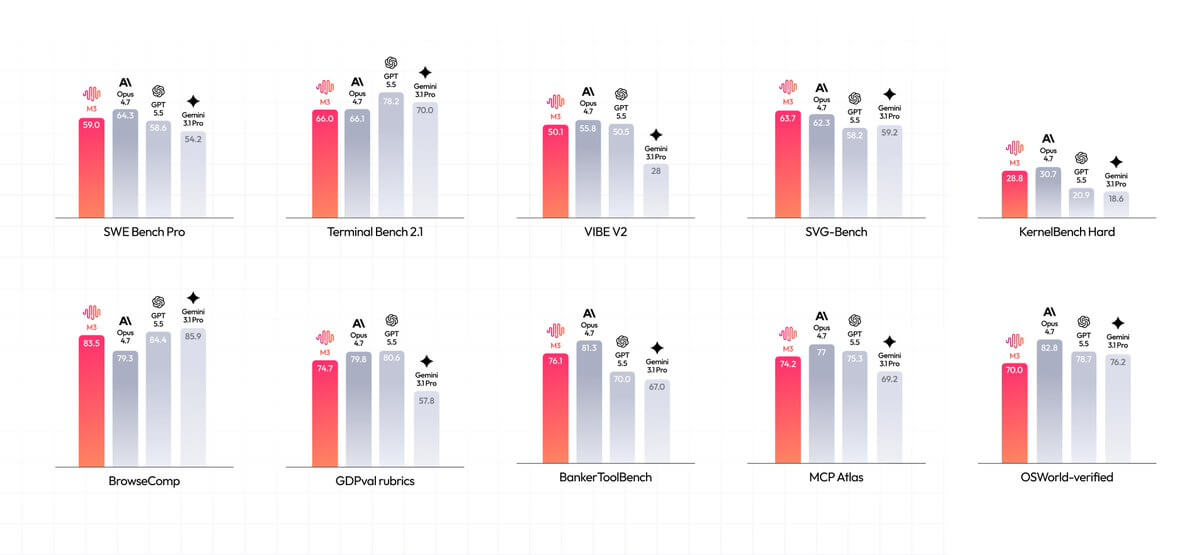
但 Benchmark 分数归分数,真实工程场景里表现如何才是最应该关心的,大家都清楚这个道理。
对此,我用一个过去遇到的线上故障来检验——一个业务高峰期因隐藏颇深的后台异步任务中的一次 Redis SCAN 操作引发的事故来测评。
该案例涉及复杂业务链路推理和全局诊断。同时,我会在完成故障定位和止血后,继续用 M3 尝试 Redis 源码(C)到 Go 的功能复刻、以及前后端 Redis 监控面板搭建,从异构语言重构和全链路交付两个维度继续观察。
下面按如下顺序展开:
- 故障排查
- 底层复刻
- 监控落地
准备工作
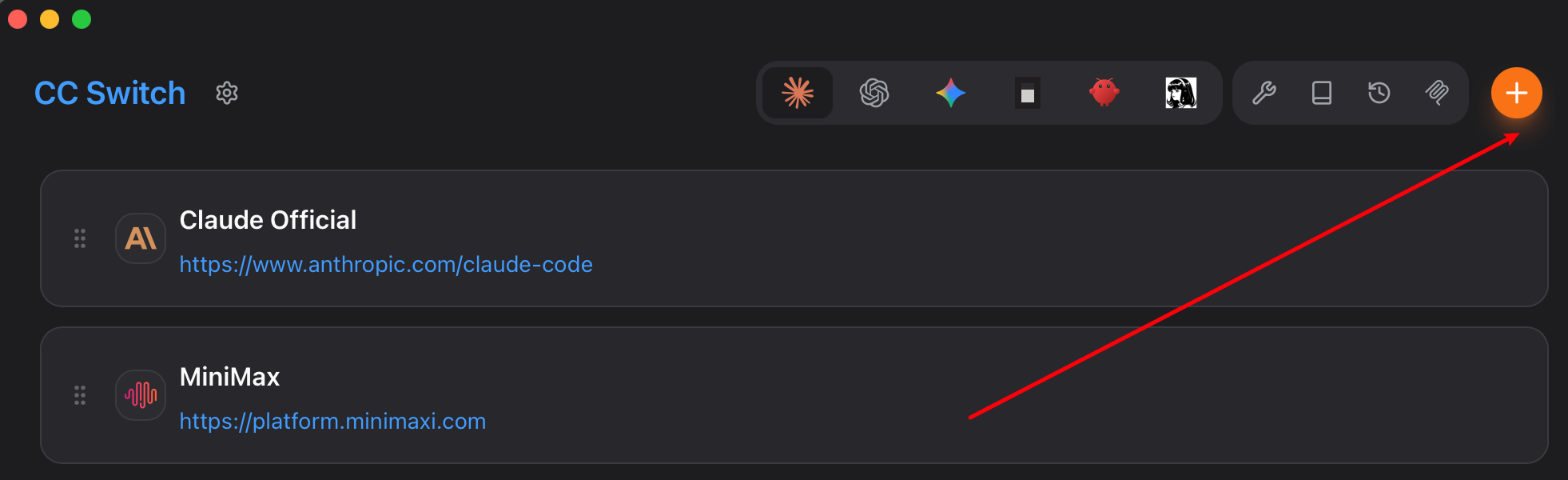
小 G 日常使用 Claude Code 开发,通过 cc-switch 统一管理模型。以下为 MiniMax M3 的配置步骤。首先打开 cc-switch 点击加号添加模型配置:
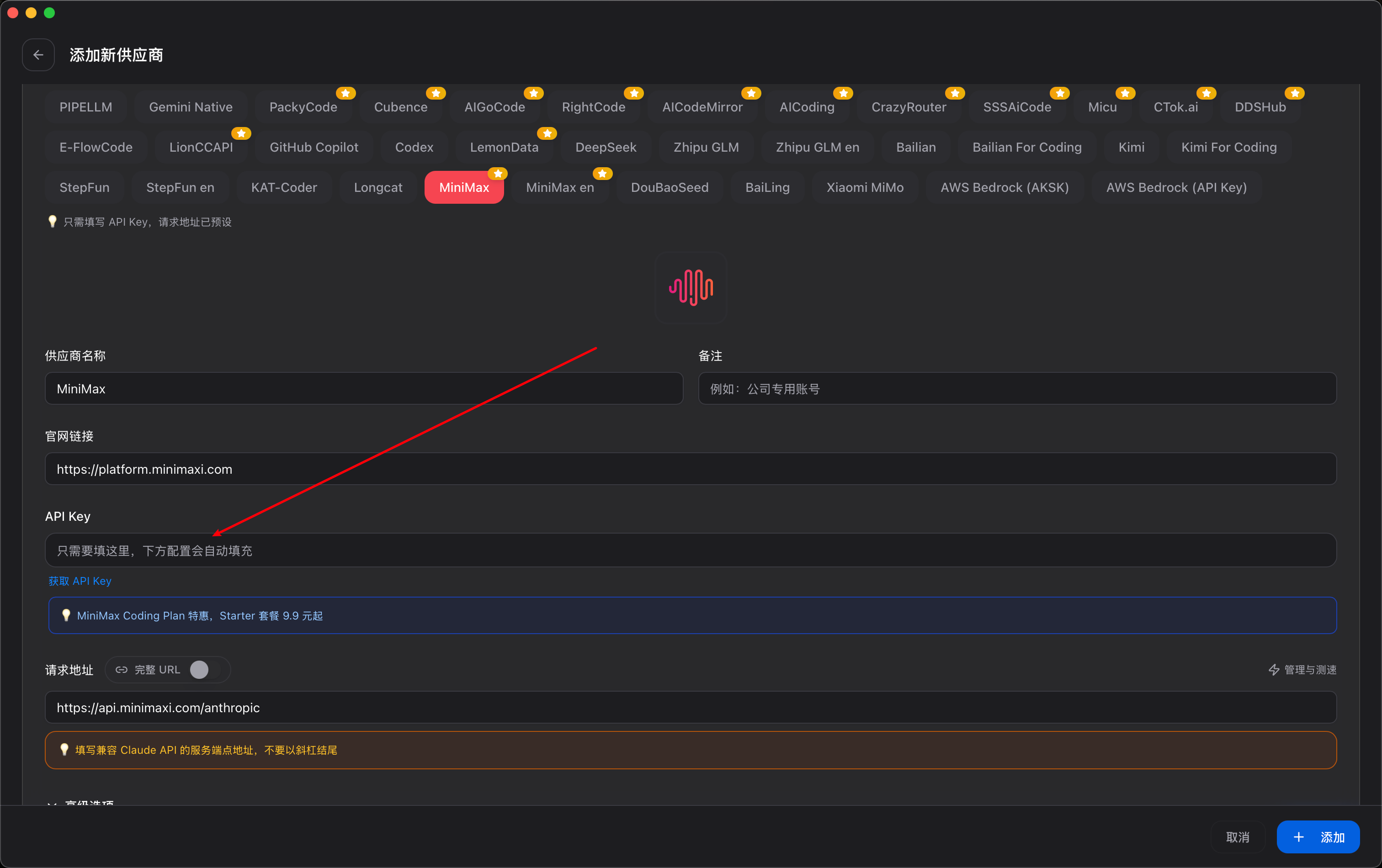
选择 MiniMax M3,将自己的 key 填充到 api key 选项中:
最后点击获取模型列表,完成模型的配置,以我的为例,直接将主模型设置为 MiniMax M3:

配置完成后打开 Claude Code,通过对话面板验证当前模型是否生效:
故障排查:线上 Redis SCAN 指令引发的性能雪崩
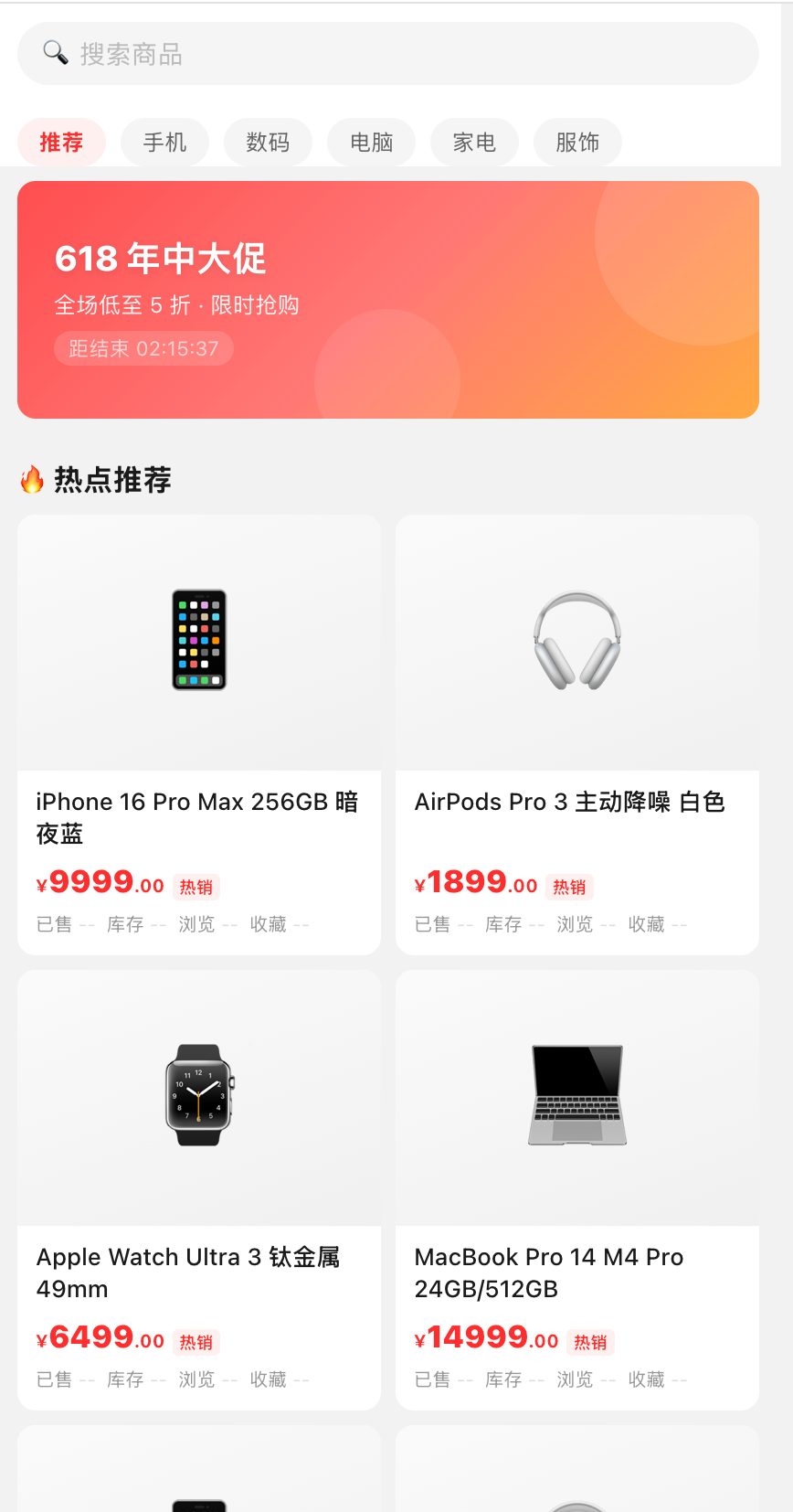
第一个案例复刻自我过去经历过的一次线上故障。为降低理解负担,这里用一个经典的电商场景来还原:该场景是大促期间“超时订单自动取消”的异步任务在跑,同时大量用户正在浏览商品。某一刻,页面大面积超时——已售、库存、浏览、收藏,所有热点数据全加载不出来:
为了评测 MiniMax M3 对于这类复杂业务链路的排查能力,我将系统表象的截图(Claude Code 中可通过 Ctrl+V 粘贴截图,Win 系统为 Alt+V)和错误描述一并提交:
经过片刻分析,MiniMax M3 结合代码上下文中所有涉及 Redis 操作的链路进行推断,直接定位到根因:SCAN 操作导致 Redis 服务端阻塞,进而引发日常读写操作大面积排队:

为进一步验证其对业务链路的理解程度,我要求 MiniMax M3 用 ASCII 图绘制故障流转链路。M3 梳理出了完整的调用链——从超时订单异步任务触发 SCAN,到 keyspace 遍历阻塞主线程,再到页面请求排队超时——非零散症状罗列,而是一条端到端的因果链:

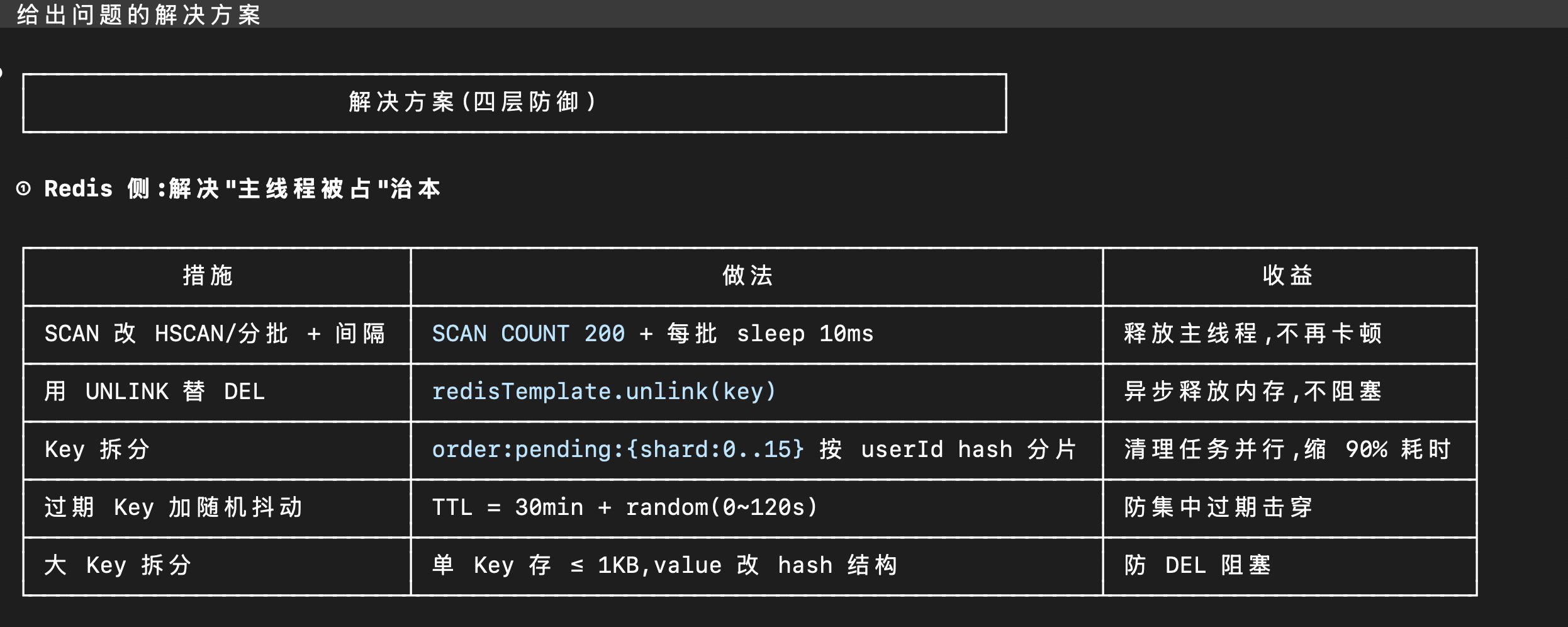
解决方案方面,M3 没有止步于“换一个数据结构”,而是从四个维度同时给出建议——Redis 层面的数据结构调整、接口层面的原子性优化与降级策略:
针对受影响的业务接口,M3 将串行 Redis 指令优化为一条原子操作,并附上降级策略,以控制极端情况下的影响面:
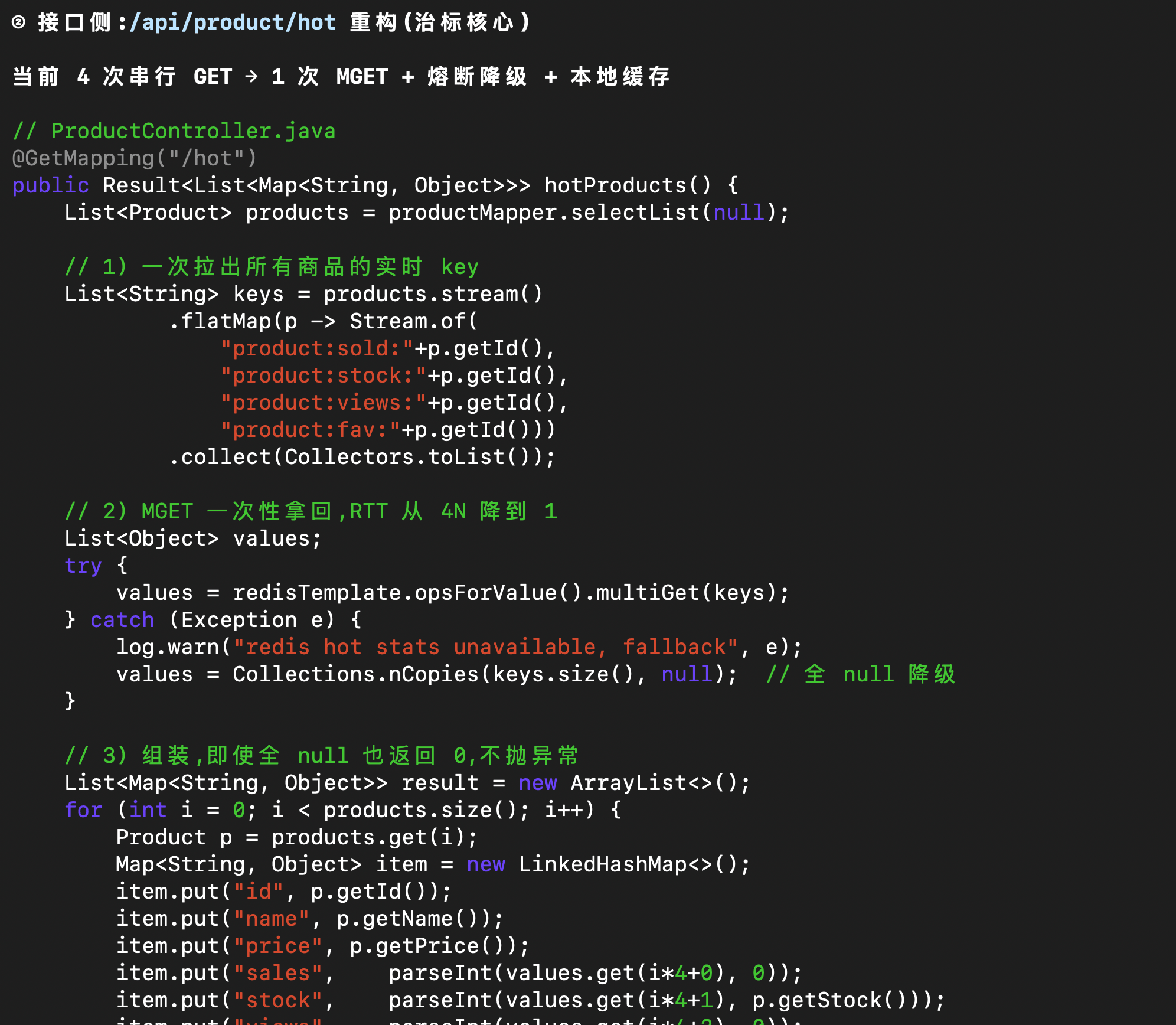
在工程侧,M3 还给出了监控埋点建议和告警阈值参考,例如将 SCAN 操作的监控红线设在 200 ms——人类感知停顿的最大延时阈值——超出即触发告警:

以下是本次修改的 diff:

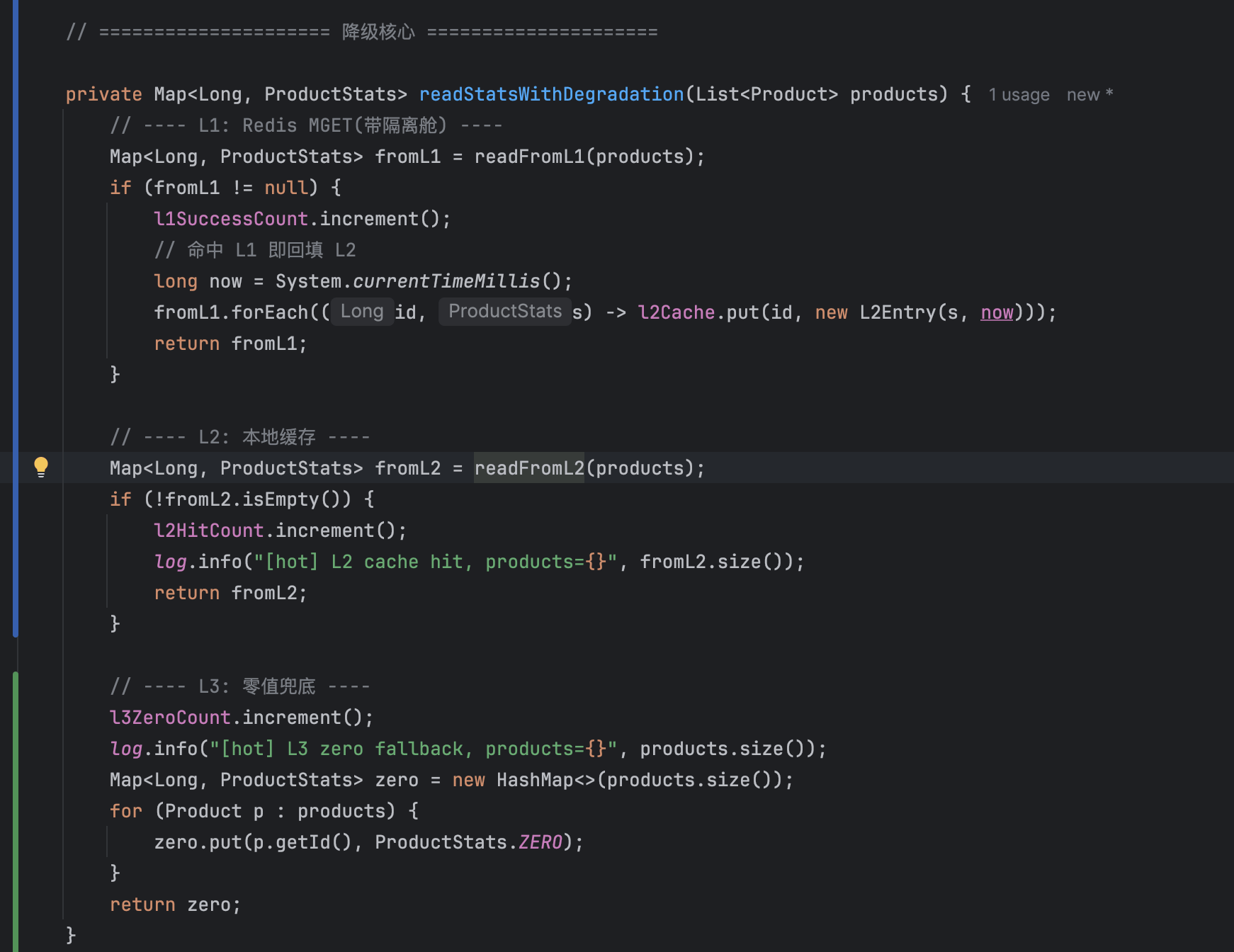
以下为核心降级代码。M3 使用并发原子类保障多级缓存操作链路的线程安全,并对缓存一致性的边界条件做了处理:
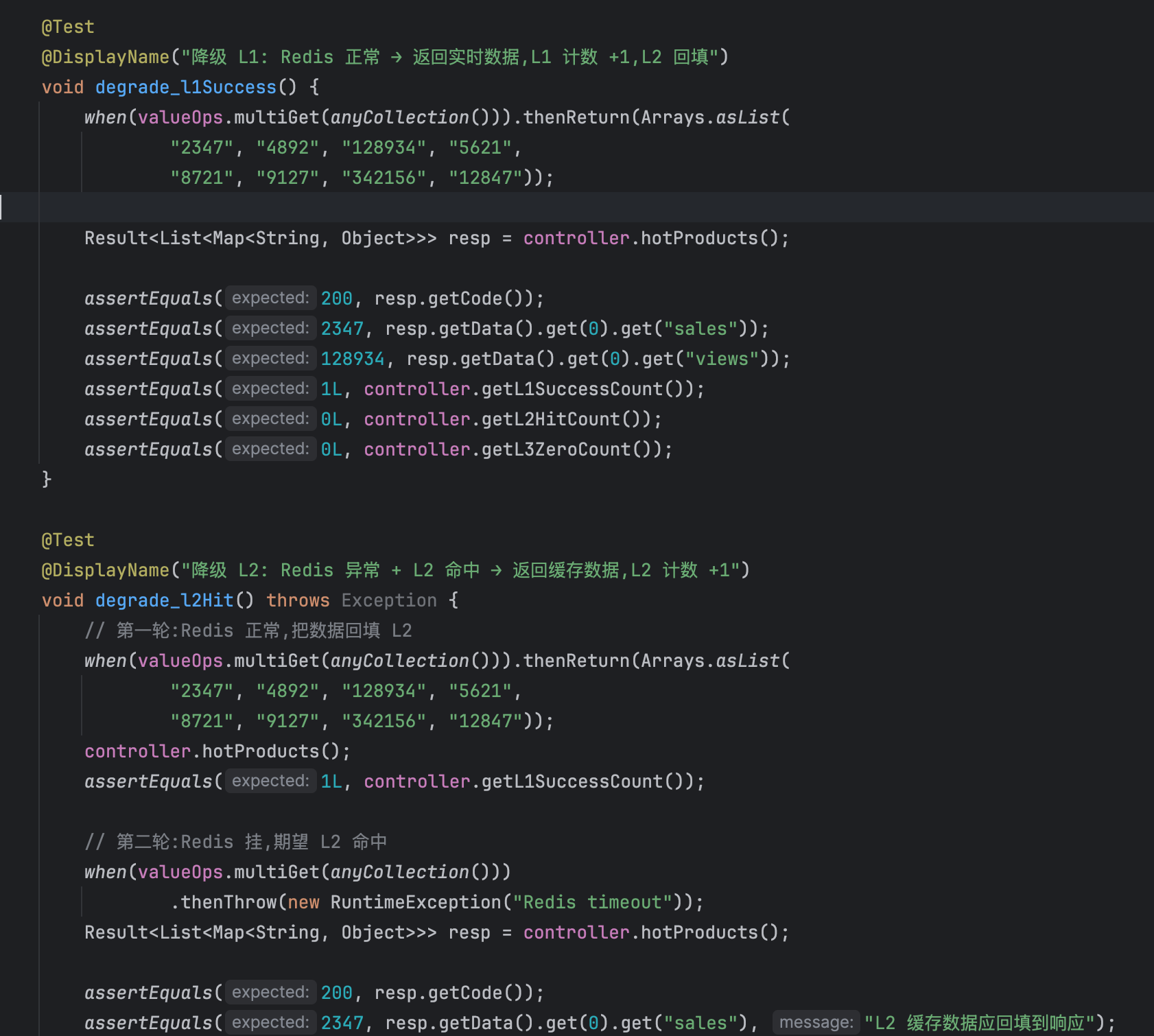
M3 交付的不只是降级代码,还附带了一套测试用例——覆盖了正常降级路径、异常回退路径以及并发竞态场景。降级策略的逻辑覆盖达到 100%,用例结构工整。经调试与验收,编译通过、单测全绿:
深入底层:复刻 Redis SCAN 游标算法,理解 rev 二进制翻转
近期 Google 技术总监 Addy Osmani 在《Don't Outsource the Learning》一文中提出了一个值得警惕的现象:让 AI 写代码而自己跳过学习太容易了——错误被修复,但你的心智模型没有进步。他引用了 Anthropic 的一项随机实验:同样是学习新库,AI 辅助组完成任务的速度与手动组持平,但后续理解测试中得分仅为 50%,远低于手动组的 67%。有趣的是,AI 组内部也存在分化——用 AI 提问概念问题的工程师得分超过 65%,直接复制粘贴代码的则不到 40%。Osmani 的结论是:工具不会替你学习,区别在于你的使用方式:

回到本次事故。故障排查和降级止血是第一步,但如果不深入 SCAN 的底层实现,很多细节容易被忽略:SCAN 是如何对 dict 字典进行遍历的?count 设为 10 是否意味着只遍历 10 个元素?rev 二进制翻转在游标推进中到底起什么作用?这些问题靠读文档回答不了。所以我换了一种方式:借助 MiniMax M3 辅助复刻 Redis SCAN 的核心算法,从源码层面搞清楚 SCAN 在 dict 上的扫荡机制。正好我的好友 sharkchili 在维护 mini-redis 这个开源项目(一个用 Go 复刻 Redis 核心功能的学习型项目),我直接拉取其代码分支进行复刻。
为了提供充足的上下文,我直接将 Redis SCAN 相关的源码文件通过 add-dir 传入 mini-redis 项目:
然后直接键入需求。M3 扫描传入的 Redis 源码后,判断这是一个长任务,调用了 plan-with-files 技能进行任务拆解和规划:
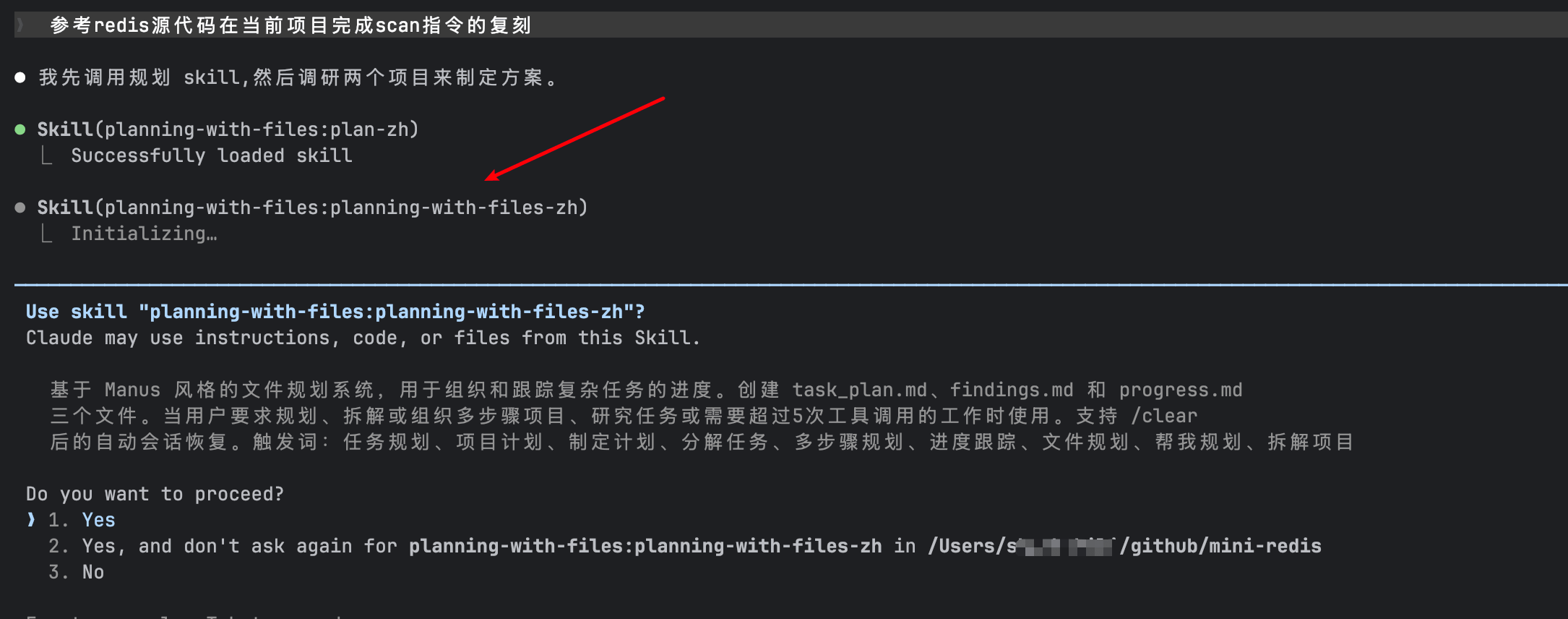
规划完成后,M3 主动发起澄清。第一点是确认需求范围,我选择复刻 SCAN 指令:

第二点是算法选型,M3 在扫描项目代码时发现,mini-redis 复刻了 Redis 的 dict 数据结构(而非直接使用 Go 原生 map)。基于这一发现,M3 推荐完整复刻 Redis 的 SCAN 游标实现——在已有 dict 的基础上做游标推进,保证了 SCAN 底层迭代的基调与 Redis 一致:同样的哈希桶遍历顺序、同样的内存局部性。如果另起一套独立的 map 做 SCAN 扫描,不仅增加非必要工作量,内存局部性也无法保证,迭代效率会明显下降:

经过多轮的交互和澄清之后,我们得出如下规划:
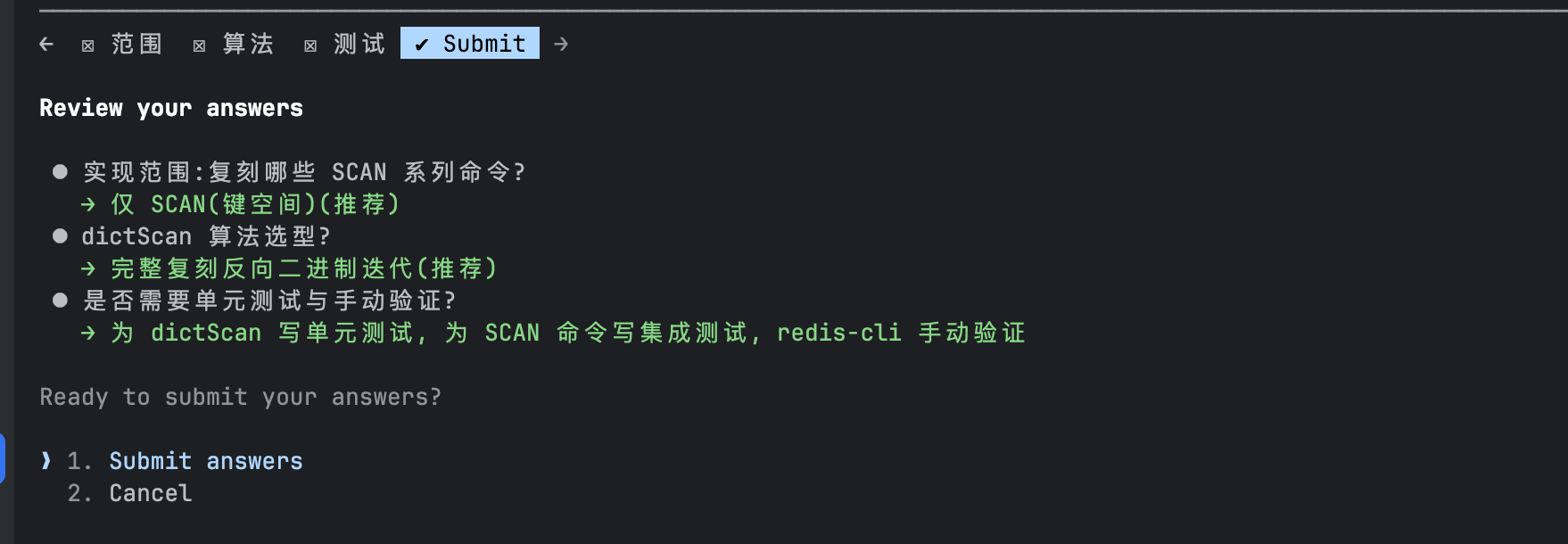
方案对齐后,M3 自底向上逐层完成函数实现,先搭好 dict 遍历的基础框架,再衔接游标推进和参数解析,最后更新了项目的 README 计划表:

最终交付的代码结构如下。SCAN 实现覆盖了 match、count 参数解析以及游标循环逻辑:
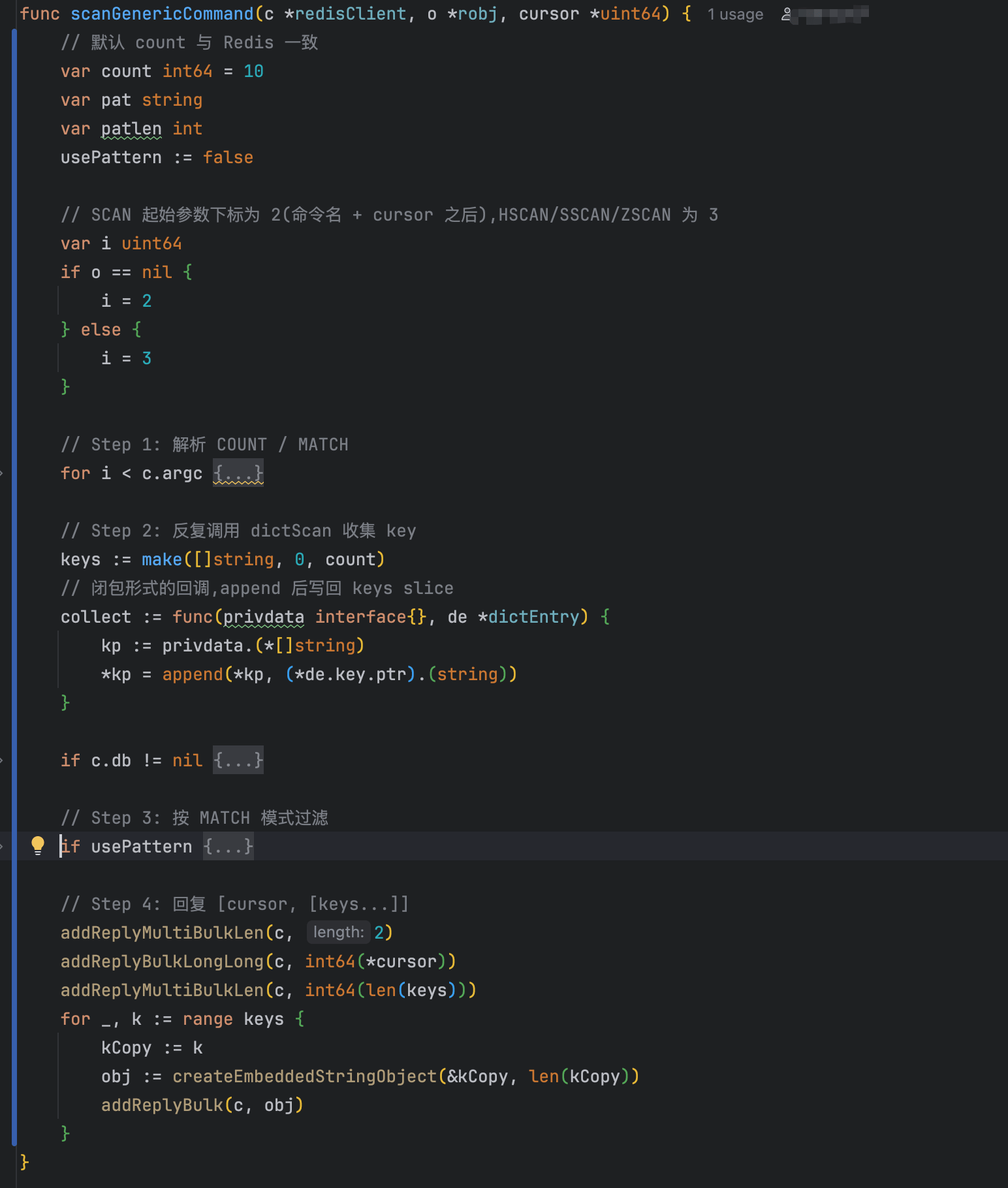
通过这次复刻结合代码注释,我很直观地看到了 SCAN 的一些容易踩坑的细节——例如 dictScan 在扫描时会将实际遍历的桶数量扩大到 count × 10,以避免因非命中桶过多导致单次返回数量不足:
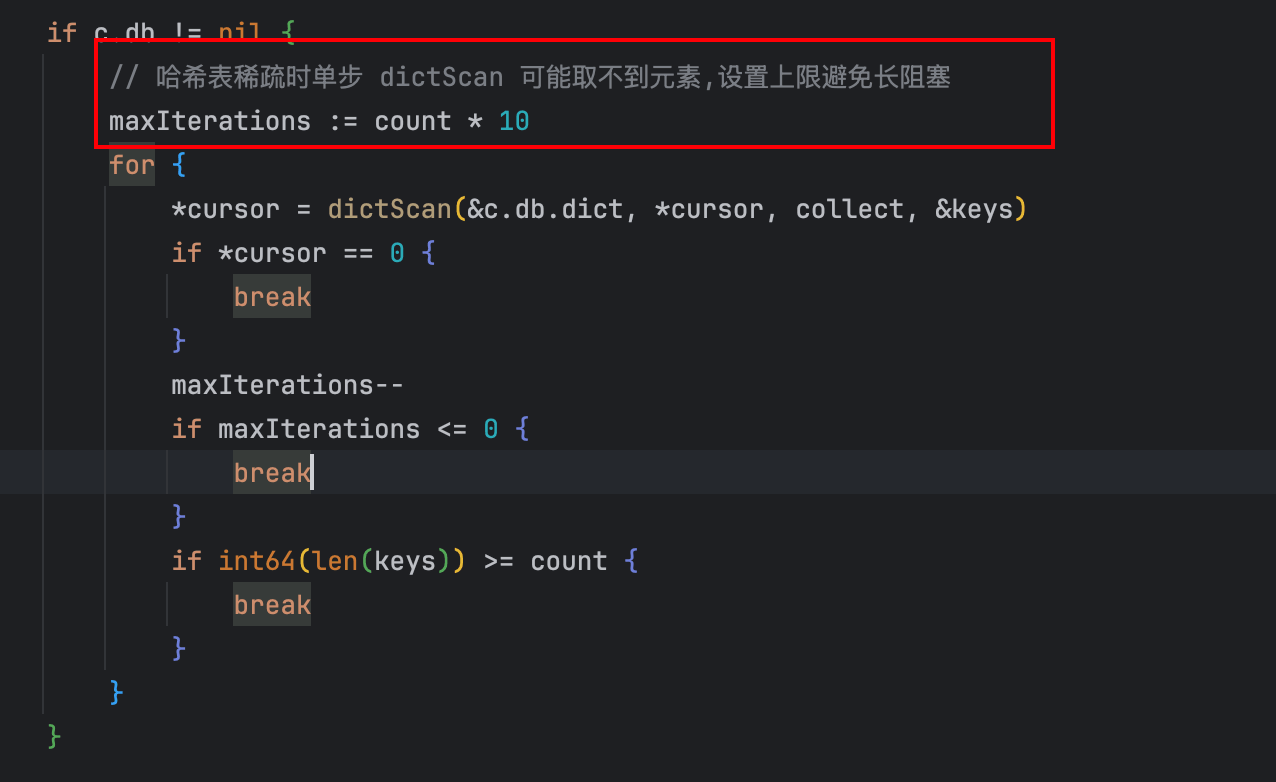
其中一个值得注意的细节:Go 语言中 ^ 同时承担异或(XOR)和按位取反(NOT)两种语义,而 C 语言中两者分别是 ^ 和 ~。rev 算法涉及大量二进制翻转操作,每一步都必须精确区分“翻转某一位”和“翻转整个二进制数”——语义搞混一步,游标推进就会全部跑偏。这部分需要重点 Review,确认 M3 有没有把 ~ 机械替换为 ^:
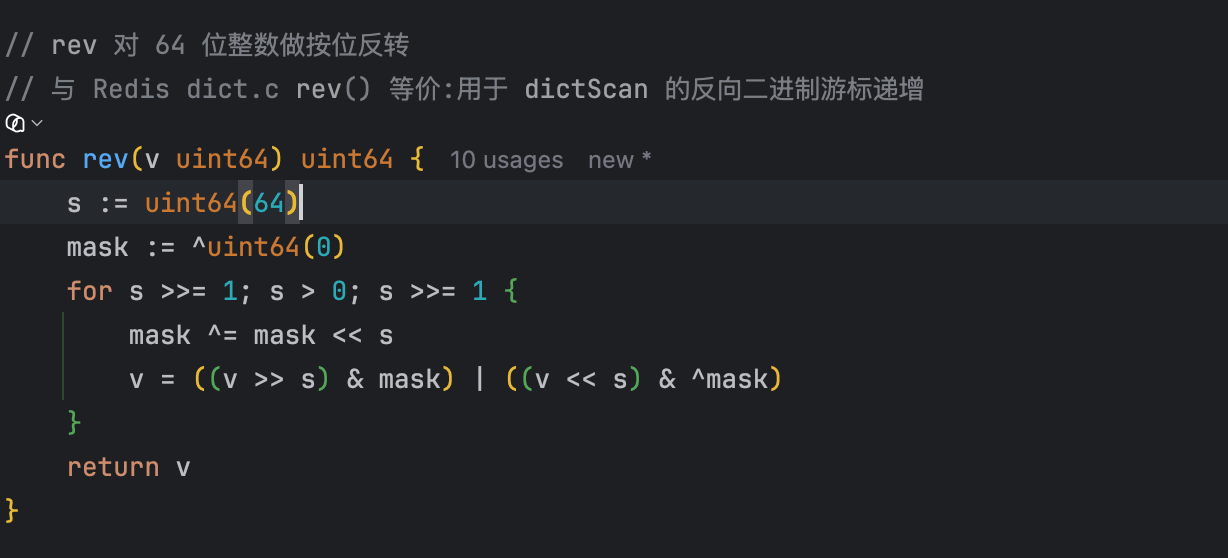
基于上述实现质量,编译和单测均一次通过:
学以致用:构建轻量级 Redis 监控面板
完成止血和复盘之后,还需要针对既有架构补上监控能力,确保后续能实时观测 Redis 运行状态,并在问题复发时快速定位和止血。
这个环节我把既有工程作为上下文传入一个新项目,让 M3 从零设计并实现一套可视化的 Redis 监控面板,看看它在前后端全链路交付上的表现。

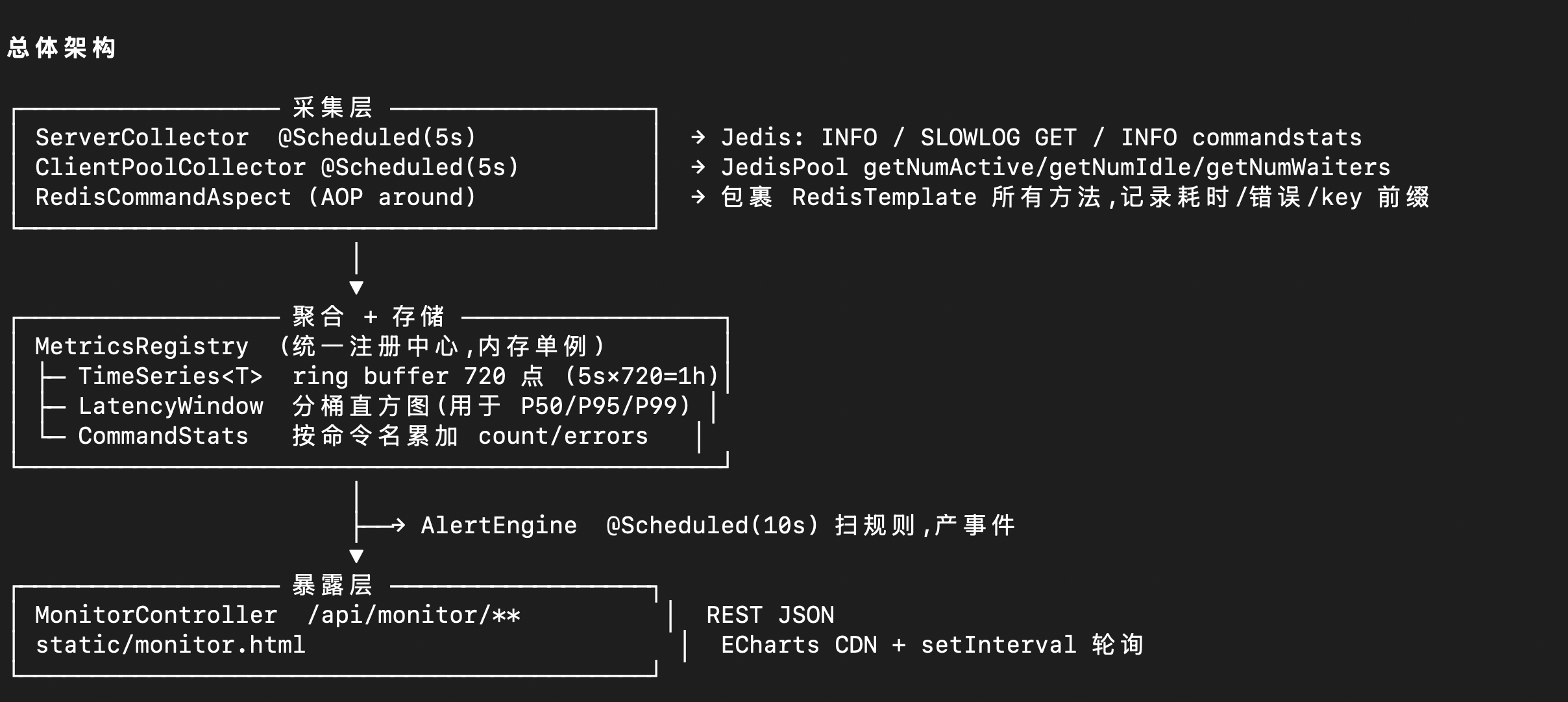
经过简单的问题澄清后,M3 给出了监控系统的架构 ASCII 图,理清了数据流向:
- 采集层(埋点上报)
- 缓冲层(环形缓冲区削峰)
- 展示层(HTTP 接口 + 前端面板)
三层之间职责清晰,耦合度低:
代码结构:
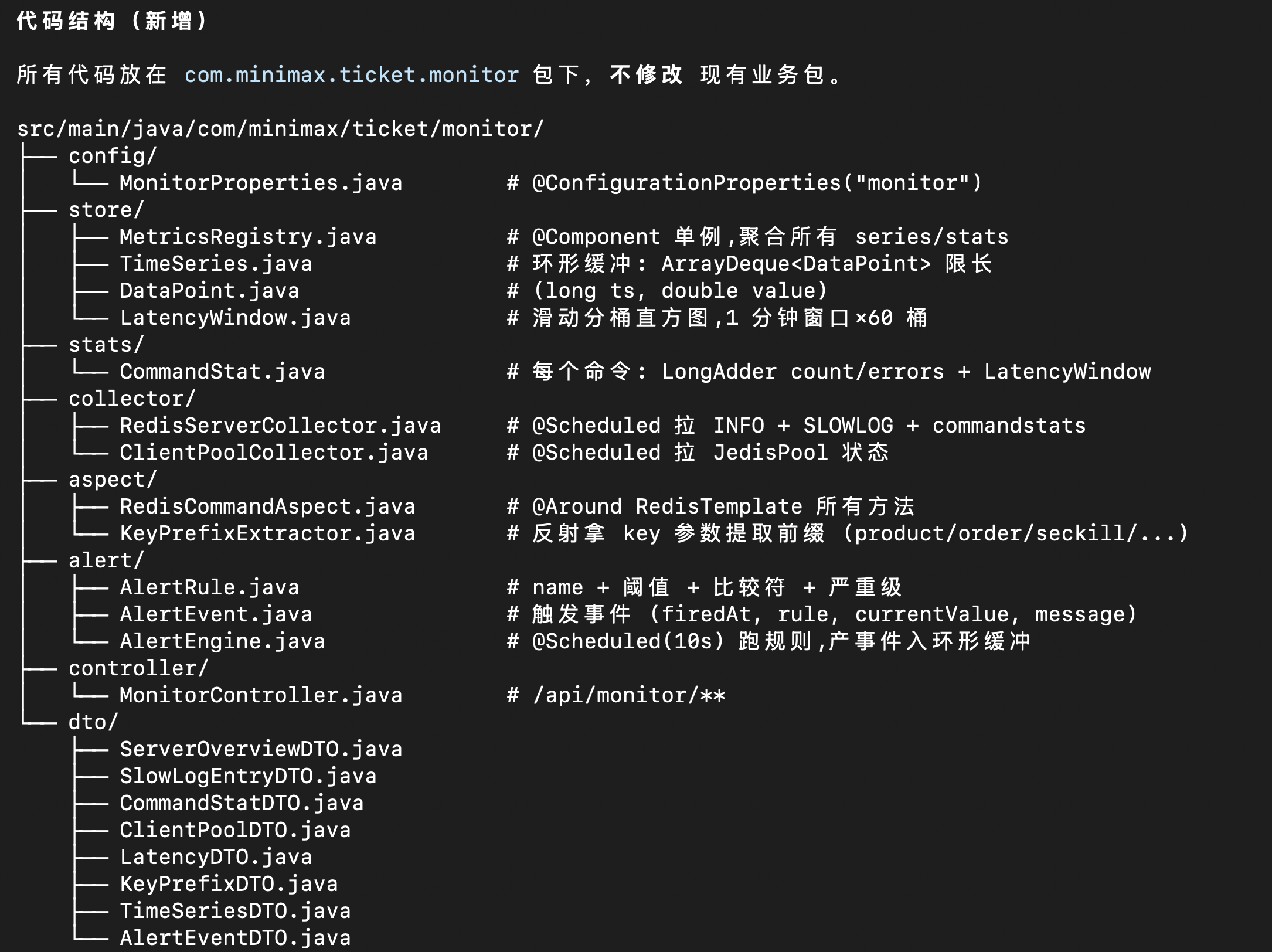
尽管是 MVP 快速原型,底层监控埋点的环形缓冲区数据结构设计值得一看——包括预分配的固定大小数组、互斥锁保护的并发读写,以及缓冲区满时自动覆盖最旧数据:
最终生成的监控面板如下。整体采用深色主题,布局上分成了多个面板:Redis 实例的实时状态(内存占用、连接数、QPS)、命令类型的分布统计图、以及慢查询的时间线排列:
对于 Redis 服务端,面板也针对慢查询和 key 分布进行了详尽的输出与展示,可直接用于日常观测:
小结
回顾这次完整闭环:从一个线上故障的表象截图出发,用 M3 完成了三件事——链路推理与根因定位、Redis SCAN 核心算法的跨语言复刻、以及一套前后端联动的监控面板搭建。
三个环节分别考验了模型的不同能力:
- 故障排查:长链路推理和多维度方案覆盖(数据结构 + 原子性 + 降级 + 监控,一个 prompt 下覆盖代码、架构、可观测性三个视角)
- 底层复刻:跨语言上下文理解和代码实现的精准度(比如识别出项目复刻了 dict 而非使用 Go map,以及 Go 的
^语义区分对算法的影响) - 监控面板:前后端全链路架构设计和完整交付能力(从采集层到缓冲层再到展示层,包括环形缓冲区的数据结构设计)
在 Redis SCAN 从 C 到 Go 的复刻中,M3 识别出项目复刻了 dict 而非使用 Go map,并在此基础上推荐完整复刻 SCAN 游标;Go 语言 ^ 运算符兼具异或和取反两种语义,这部分也做了逐行区分。
而在监控面板场景中,M3 暴露了一个值得注意的边界:from-0-to-1 阶段,它给出的架构选择是“能跑的稳妥方案”而非“经过权衡的最优方案”。以环形缓冲区为例,为什么是环形缓冲区而不是无锁队列?缓冲区满了覆盖最旧数据在高 QPS 下会不会丢关键指标?这些决策点 M3 默认了一个标准答案,没有主动提出 trade-off。如果开发者不具备相关领域的知识储备,就没法在头脑风暴阶段完成最佳方案决策——最终拿到的只是一个“能跑”的原型,而非“设计合理”的原型。
所以,还是回到 Addy Osmani 的观点——工具不会替你学习。M3 生成了降级代码和 rev 算法,但如果不去读源码、不理解 count × 10 的设计意图,这些知识就留不在脑子里。AI 是加速器,但底层思维和工程判断力必须由自己完成。