CLAUDE.md 最佳实践:该写什么、不该写什么、项目变大后怎么拆
你好,我是小 G。前几天分享 Claude Code 使用技巧 的时候,我提到了一个很重要的文件 CLAUDE.md,并简单介绍了一下。
有 G 友在评论区留言:这个文件既然这么重要,能不能单独写一篇来讲?
非常可以,而且真值得单独讲!
很多朋友第一次看到 CLAUDE.md,总会和 README 联系起来。其实两者根本不是一回事。
README 主要是写给人看的,重点是介绍项目信息;CLAUDE.md 则是专门写给 Claude 看的。你可以把它理解成:在 Claude 开始干活之前,先坐在旁边提醒它几句,比如项目怎么启动、哪些文件别乱动、接口返回格式怎么定、团队以前踩过哪些坑。这些话你当然可以每次开新会话都重新说一遍,但说多了真的烦,而且还容易漏。
CLAUDE.md 要解决的问题很简单:把那些长期有效、又容易被 Claude 猜错的规则提前写好。这样它每次进项目时,不至于一上来就从零开始摸索。
这篇我就结合 Claude Code 官方文档和自己的使用经验,把 CLAUDE.md 这件事从头捋一遍:该写什么、不该写什么、项目变大后怎么拆、后面又该怎么维护。
还有个小提醒:Claude Code 迭代很快,.claude/rules/ 和 Auto Memory 这两块尤其容易随版本变化。本文按 2026 年 6 月前后的官方文档和实测来写,实际落地前,最好先用 claude --version、/memory 看一下你本机版本和当前会话到底加载了哪些内容。
什么是 CLAUDE.md?
CLAUDE.md 是 Claude Code 的项目/用户级指令文件,是给 Claude Code 的持久指令和上下文,用于告诉 AI 助手如何在这个项目中工作,本质是一份 AI 行为规范。
我一般只往里面放几类东西:
- Claude 容易猜错的规则
- 代码里读不出来的约定
- 团队必须遵守的规范
- 技术栈版本、常用命令、架构取舍、项目坑点
我自己判断一条内容该不该放进去时,会用一个很土但好用的问题:
这行删掉后,Claude 会不会更容易犯错?
如果会,就保留;如果不会,它大概率只是在浪费上下文。
CLAUDE.md 和其他规则文件有什么区别?
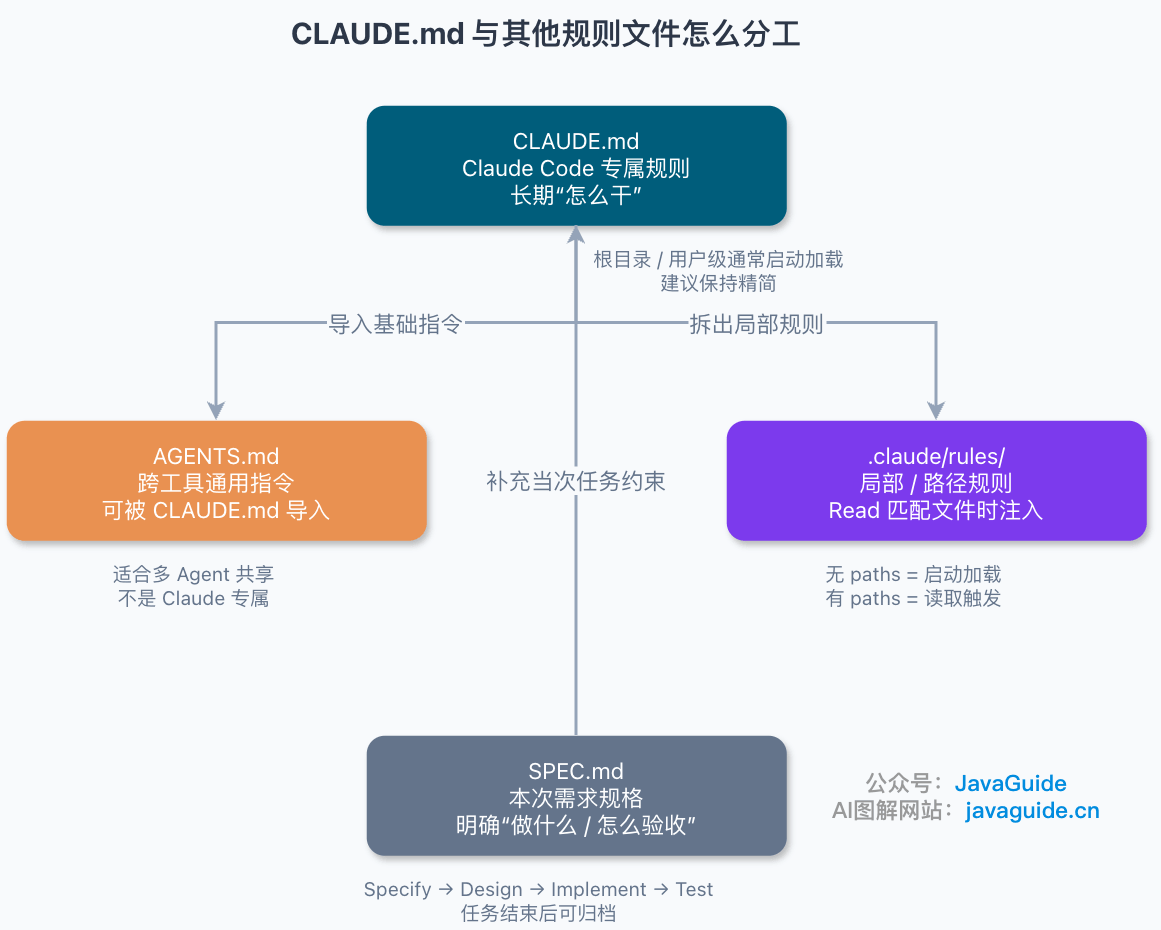
CLAUDE.md vs AGENTS.md
| CLAUDE.md | AGENTS.md | |
|---|---|---|
| 谁读 | Claude Code 专属 | 跨工具开放标准,OpenAI Codex、Cursor、Google Jules 等也采用 |
| 定位 | Claude Code 的项目规则文件 | 跨工具通用的 Agent 指令文件 |
简单说:通常来看 AGENTS.md 是跨工具标准,CLAUDE.md 是 Claude Code 专属入口。两者可以复用同一份基础指令。
在一些场景下,AGENTS.md 也可以作为 Agent 的错误笔记,Agent 在犯错之后,可以自动记录这次错误的原因,下次就不会再犯。
如果仓库已经用 AGENTS.md 给其他编码 Agent 提供指令,可以创建一个导入 AGENTS.md 的 CLAUDE.md,让两个工具复用同一份基础指令,不用重复维护。
@AGENTS.md
## Claude Code 特定指令
- 使用 plan mode 处理 `src/billing/` 下的改动以及在我的 一文搞懂 Harness Engineering 这篇文章也提到过:OpenAI 的 AGENTS.md 大约只有 100 行,作用更像目录,指向 docs/ 目录下更深层的设计文档、架构图、执行计划和质量评级。这就是渐进式披露:先给最关键的信息,需要更多细节时再加载。
CLAUDE.md vs .claude/rules/
| CLAUDE.md | .claude/rules/ | |
|---|---|---|
| 加载方式 | 根目录/项目级文件通常在会话启动时加载;子目录文件在读取对应目录时按需加载 | 不带 paths 的规则启动时加载;带 paths 的规则在 Claude 读取匹配文件时加载 |
| 适用场景 | 全局通用规则 | 只针对特定文件/目录的规则 |
| 上下文消耗 | 根目录/项目级规则会持续消耗上下文 | 只有 path-scoped rules 按需消耗;全局 rules 仍会持续消耗上下文 |
规则只针对特定目录(如后端 API 规范、测试配置)时,优先用 rules,不要继续往 CLAUDE.md 里堆。
要注意两点:
.claude/rules/不是 Claude Code 安装后默认一定会出现的目录,需要时可以手动创建。.claude/rules/不是天然省上下文。只有带pathsfrontmatter 的路径规则才更接近按需加载;没有paths的规则仍然会像全局规则一样进入上下文。
CLAUDE.md vs SPEC.md
| | CLAUDE.md | SPEC.md |
|---|---|---|
| 用途 | 项目规则(怎么干活) | 需求规格(做什么) |
| 内容 | 编码规范、常用命令、踩坑记录、团队约定 | 需求边界、功能定义、验收标准,类似面向 AI 的 PRD |
| 谁用 | AI 编码助手(日常编码) | Spec Coding 流程(需求驱动开发) |
SPEC.md 来自 Spec Coding 流程(Specify → Design → Implement → Test),核心是先搞清楚做什么再动手。
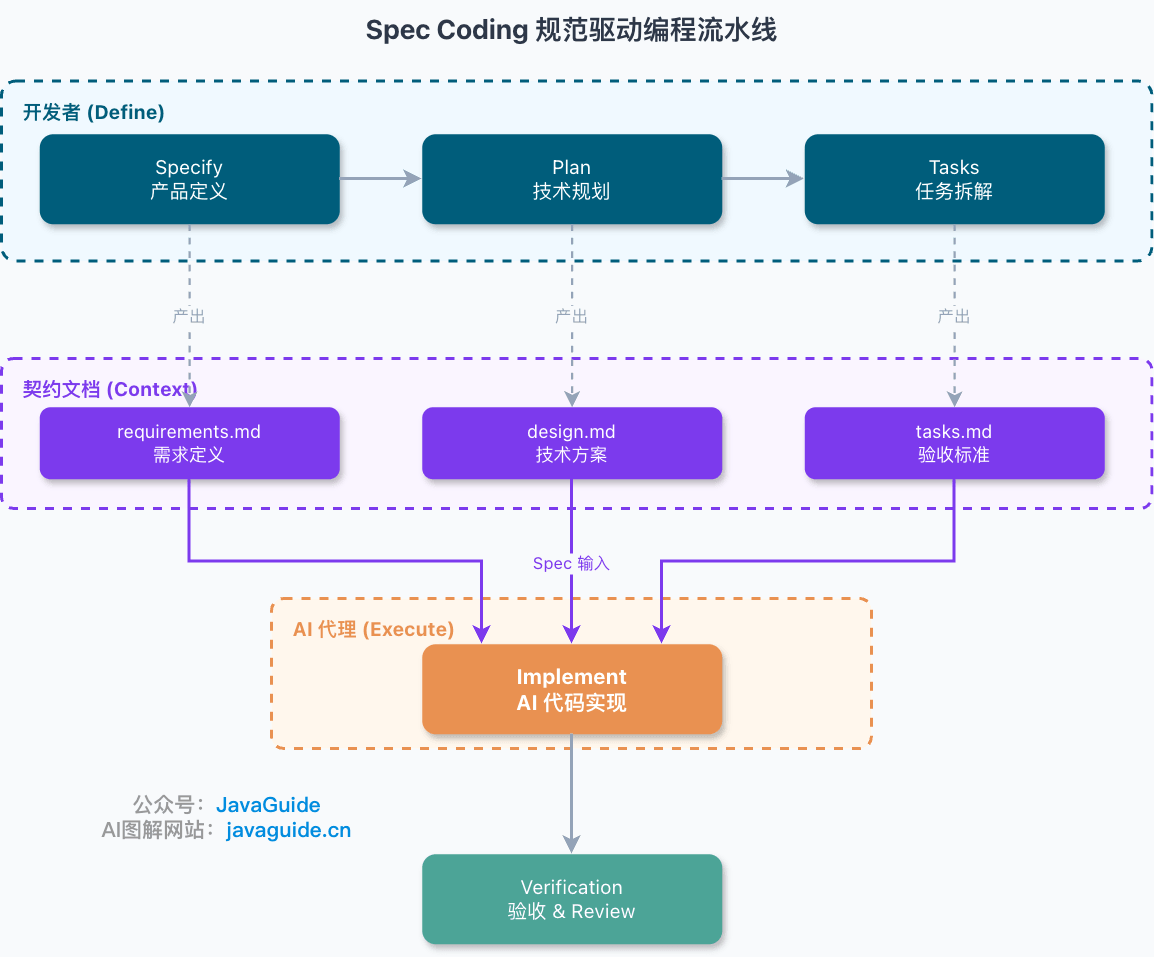
上图中的 requirements.md 就是 Specify 阶段的产物,也被称为 SPEC.md 。
我在Spec Coding 规范驱动编程实战:从 Vibe Coding 到 AI 代码规范这篇文章中有详细介绍。
一句话简单理解就是:CLAUDE.md 管长期行为规范,Spec 管当次任务约束。
一句话总结
- CLAUDE.md:Claude Code 专属的行为规范;根目录/用户级通常在会话开始时加载,子目录规则按需生效。
- AGENTS.md:跨工具通用的“怎么干”规则,可被
CLAUDE.md导入复用。 .claude/rules/:局部规则目录;不带paths更像全局规则,带paths才会在处理匹配文件时生效。- SPEC.md:需求规格文件,定义这次做什么,属于 Spec Coding 流程中的一环。
CLAUDE.md 到底该写什么?
先看一个我经常见到的写法。很多人跑完 /init,看到 Claude 生成了一份 CLAUDE.md,觉得“有总比没有好”,于是基本没改就提交了:
# 项目说明
这是一个 Spring Boot 项目,使用 Java 17 和 Maven。
# 代码风格
- 写干净的代码
- 遵循最佳实践
- 确保代码可读性
# 工作流
- 提交前运行测试
- 保持良好的代码组织这份文件有没有错?其实没有。
问题在于,它对 Claude 几乎没什么约束力。比如“写干净的代码”这句,删掉以后 Claude 会少做什么吗?大概率不会。
这种正确废话留在文件里,最后只会占上下文。
Claude Code 的系统指令在会话开始前就已经占了一部分上下文。Anthropic 在官方文档中指出:随着上下文窗口被填满,Claude 的整体表现会下降。
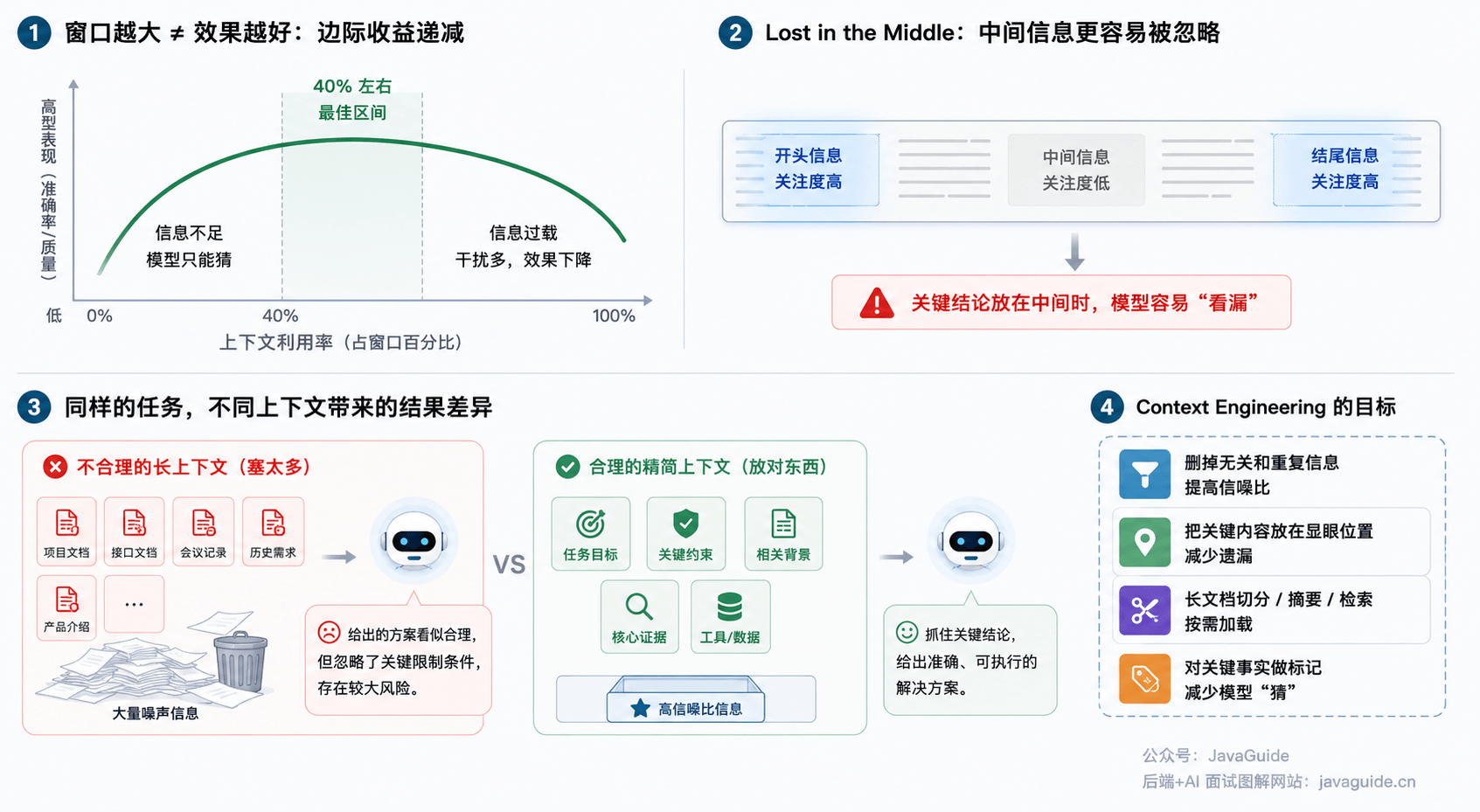
这意味着 CLAUDE.md 如果过于臃肿,重要规则更容易被忽略。CLAUDE.md 的每一行都在消耗上下文窗口中的有限空间,留给后续对话和文件读取的余量就更少,所以必须精打细算。
Anthropic 建议保持 CLAUDE.md 精简不超过 200 行,只保留 Claude 无法轻易从代码中推断的信息。如果内容继续膨胀,可以拆到带 paths 的 .claude/rules/,或者把不是每次会话都需要的参考内容放到 Skills 里。
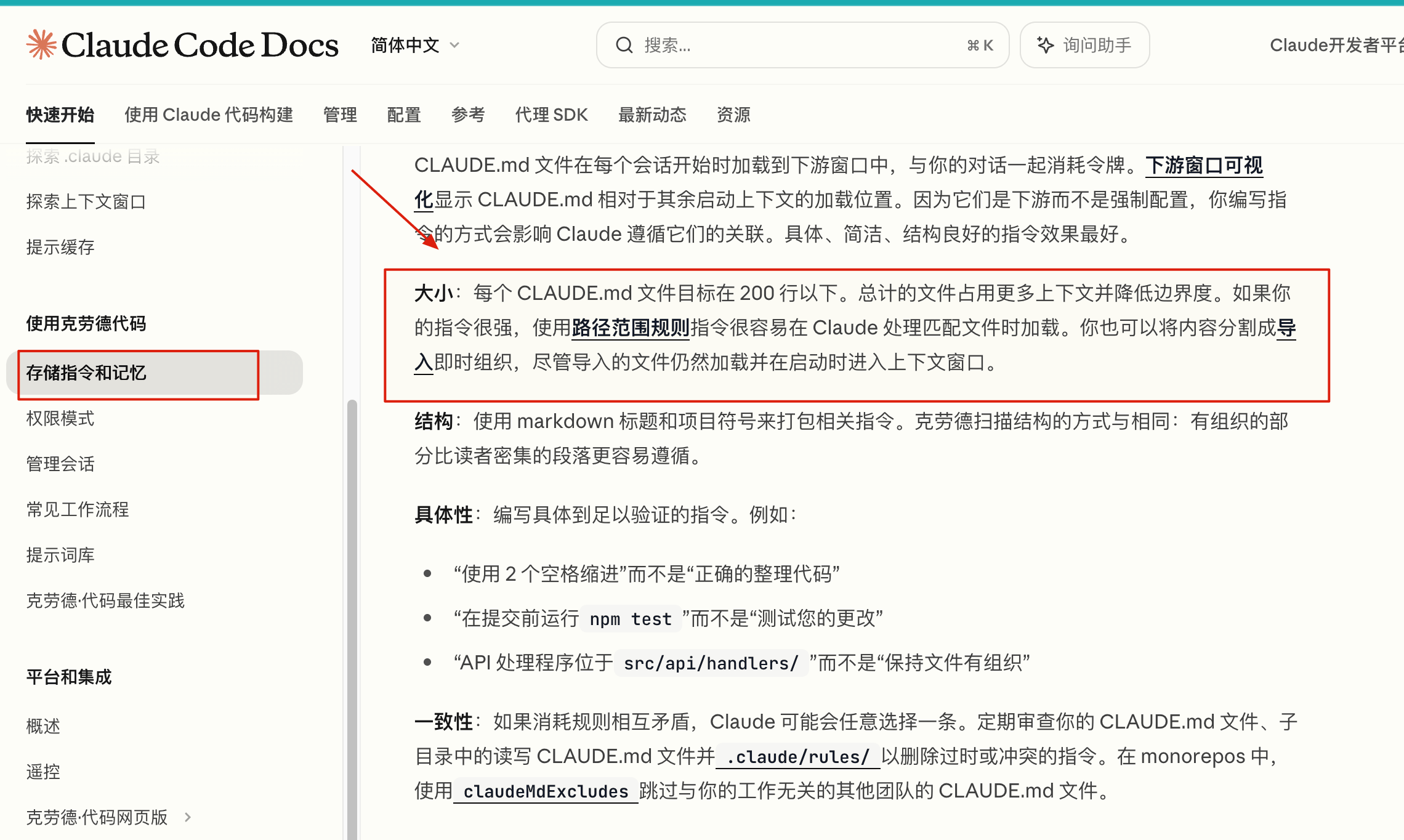
一句话判断标准:逐行过一遍 CLAUDE.md,问自己“如果删掉这行,Claude 最近是不是更容易犯同类错误?”。如果答案是“会”,留下;如果答案是“好像不会”或者“不确定”,先删掉。CLAUDE.md 最怕的不是少写两条规则,而是正确废话太多,把真正重要的规则淹掉。
该写的东西
小 G 的经验是,值得写进 CLAUDE.md 的内容大概分五类:
1. 技术栈和版本信息。
这不是给 Claude 做“项目介绍”——框架版本差异往往是 AI 犯错的源头。比如 Spring Boot 2 和 3 在配置方式上差别很大,你不标注版本,它会倾向于生成训练数据中更常见的版本用法,可能与你的实际版本不一致。再比如你选了 MyBatis-Plus 而不是 JPA,这种选型信息 Claude 从 pom.xml 里能读到,但选择背后的原因它读不出来。
2. 常用命令。
构建、测试、lint、启动开发服务器——全部放在代码块里。我的经验是:代码块里的命令 Claude 更倾向于照着跑,写在自然语言里的命令它有时会根据自己的理解改写。 想要减少偏差,就用代码块。
# Commands
- 构建:`mvn clean package -DskipTests`
- 测试:`mvn test -pl module-name`
- 启动:`mvn spring-boot:run -pl bootstrap`
- 代码检查:`mvn checkstyle:check`3. 架构决策和背后的理由。
光写规则不够,写清楚“为什么”能让 Claude 举一反三。举个例子,之前我的项目里有条规则是“不要直接写 SQL,用 QueryWrapper”。一开始只写了这句话,Claude 还是时不时直接写 SQL。后来改成:“不要直接写 SQL,使用 MyBatis-Plus 的 QueryWrapper,因为我们的 SQL 审计系统依赖 Wrapper 的解析来记录操作日志。”加上理由之后,Claude 不只是不写裸 SQL 了,在其他需要生成查询的地方也自觉用 Wrapper。
4. 团队约定和项目特有的坑。
提交信息格式(如 feat(scope): message)、分支命名规范、环境变量依赖。这些信息 Claude 从代码里读不出来,但一个新入职的工程师一定会问——把 CLAUDE.md 当成给新人写的 onboarding 文档来写就对了。
5. 当前任务的关键信息。
有时候 CLAUDE.md 不仅仅是“静态规范”,也可以作为“动态工作台”,来明确当前需要完成的任务和优先级,这通常要和静态规范的文件分离开(其实也不一定以 CLAUDE.md 命名,你叫 AGENTS.md 还是其他的都可以)。主要写:任务描述、验收标准、优先级、截止时间、依赖关系、阻塞问题、技术实现要点等关键信息。你可以将其作为 Agent 的持久化任务手册,这样即使跨会话也不会忘了该做什么。
不该写的东西
1. 代码风格规则。
缩进用几个空格、import 怎么排序、要不要尾分号——这类事交给格式化工具。项目里没配 Checkstyle 或者 Prettier 的,先配工具,别用自然语言去干代码格式化的活。
2. 语言或框架的默认行为。
“Python 用 f-string 格式化字符串”这种在现代 Python 里理所当然的事写下来只是噪音。
3. 大段参考文档。
外部 API 文档、SDK 参数表这种内容,不要整段塞进来。放链接就够了,Claude 真用到时再读。
好的 CLAUDE.md 示例
用户级示例:先管住通用坏习惯
andrej-karpathy-skills 是一个第三方整理的 Claude Code 规则/Skills 项目,灵感来自 Andrej Karpathy 对 LLM 编码问题的公开观察。我不会把它当成项目规范看,更愿意把它当成一组用户级提醒:不绑定具体仓库,只管 Claude 写代码时最容易跑偏的地方。
下图是这个仓库里的 CLAUDE.md 示例:
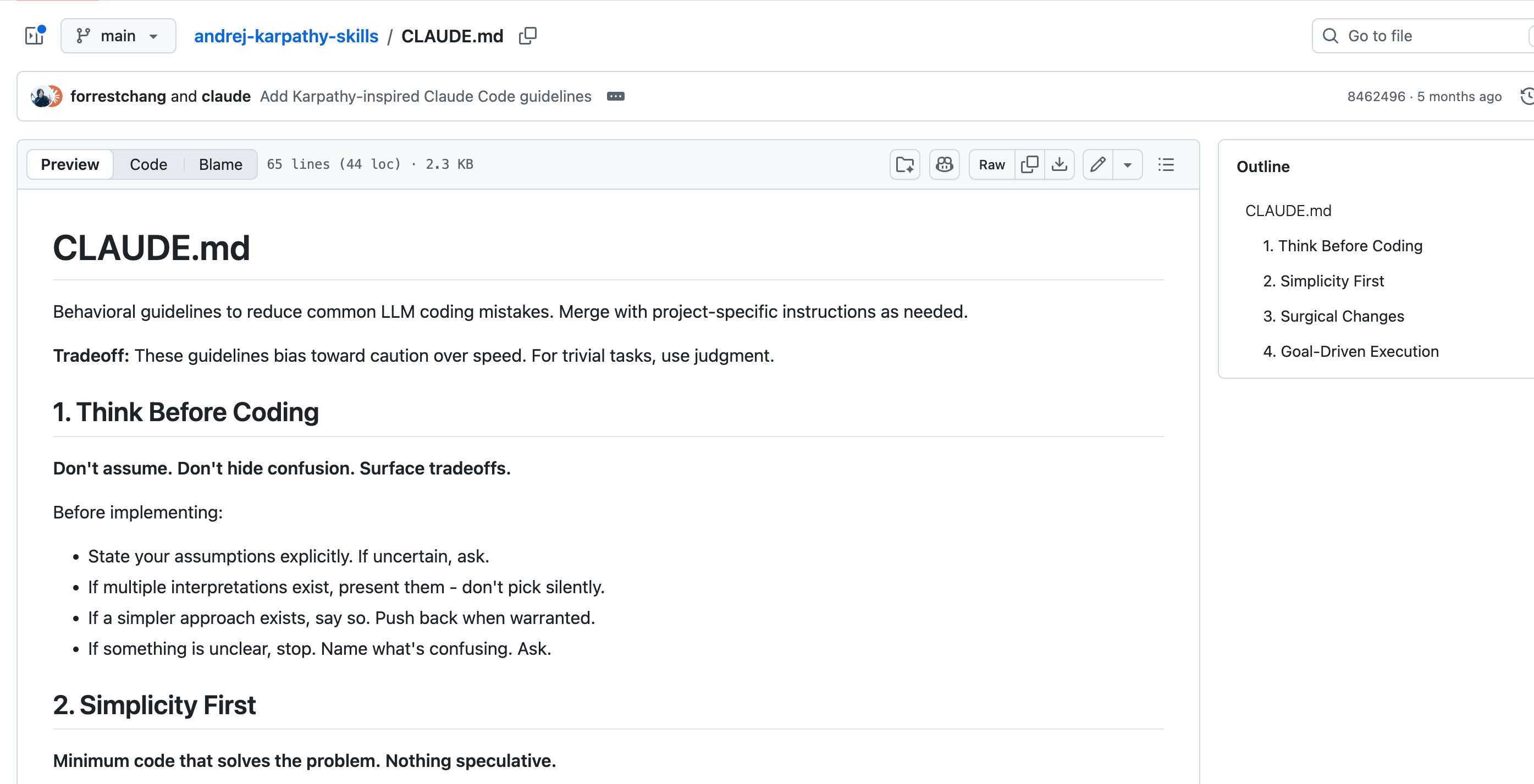
我读下来,最值得借鉴的不是某一句具体措辞,而是它的取舍:只盯着几个高频问题打。
比如先思考再编码,主要是防止 Claude 带着错误假设一路写下去;强调简洁,是为了压住它过度抽象、越改越重的毛病;要求精准修改,是为了避免它顺手动一堆无关文件;最后再用测试和验收标准把结果收住,别写完就算完成。
建议直接去 GitHub 读原文。这里就不整段贴了,重点看它的写法:规则不多,但每条都很有指向性,管的是 Claude 在不同项目里都可能犯的通用错误。
项目级示例:把仓库规矩写成速查卡
另一个例子是我的 interview-guide。它属于项目级 CLAUDE.md,重点不是把文档写长,而是把 Claude 容易猜错、代码里又读不完整的信息放到一眼能扫到的位置:技术栈版本、分层边界、命名后缀、异常处理、事务规则、禁止清单。
下面是一个更适合放在根目录 CLAUDE.md 的精简版。主文件只保留技术栈、命令、核心边界和禁止清单;更细的规范,交给 .claude/rules/ 按需加载。
# AI Interview Platform Rules
Spring Boot 4.0 + Java 21 + Spring AI 2.0 + React 面试平台。
## Tech Stack
- Backend: Spring Boot 4.0 / Java 21 / Gradle / Spring AI 2.0
- Database: PostgreSQL + pgvector(1024 维 COSINE)
- Cache & MQ: Redis / Redisson / Redis Stream
- Frontend: React 18 + TypeScript + Vite + TailwindCSS 4(`frontend/`)
- Mapping & Docs: MapStruct / OpenAPI / iText 8 / Apache Tika
## Commands
- 构建:`./gradlew build`
- 测试:`./gradlew test`
- 后端启动:`./gradlew bootRun`
- 前端启动:`cd frontend && npm run dev`
- 前端检查:`cd frontend && npm run lint`
## Architecture
- 单模块 Gradle 项目,按功能分包。
- 后端遵循 `Controller -> Service -> Repository` 分层。
- 基础设施能力放在 `common/`,包括限流、AI 调用、异步任务、配置、异常、统一响应。
- 前端代码放在 `frontend/`。
- 详细项目结构见 `docs/architecture.md`。
## Must Follow
- Controller 只做参数校验和响应包装,不写业务逻辑。
- Service 承担业务编排,`@Transactional` 只放 Service 层。
- Repository 只负责数据访问,不写业务逻辑。
- 对外响应统一使用 `Result<T>`。
- 业务异常必须使用 `BusinessException(ErrorCode.XXX, "描述信息")`。
- Entity 映射使用 MapStruct,禁止手写重复转换逻辑。
- LLM、S3、外部 HTTP 调用不得放在数据库事务内。
- 统一通过 `LlmProviderRegistry` 获取 `ChatClient`。
- 结构化输出统一使用 `StructuredOutputInvoker` 做重试包装。
- Redis Stream 生产/消费使用 `AbstractStreamProducer` / `AbstractStreamConsumer` 模板。
- 限流使用 `@RateLimit`,不要手写散落的 Redis 限流逻辑。
- 数据库向量搜索使用 PostgreSQL + pgvector,维度为 1024,距离类型为 COSINE。
## Never Do
- 不要 `throw new RuntimeException(...)`,必须用 `BusinessException`。
- 不要直接返回 Entity 给前端。
- 不要把 `@Value` 散落在 Service 中,配置集中到 `@ConfigurationProperties`。
- 不要内联全限定类名,使用 import。
- 不要事务内调用 LLM、S3 或外部 HTTP。
- 不要同类内部调用 `@Transactional` 方法。
- 不要 `catch (Exception e) {}` 静默忽略。
- 不要循环调用 DB,优先批量操作。
- 不要硬编码密钥。
- 不要使用 `Executors.newXxxThreadPool()`,使用显式 `ThreadPoolExecutor`。
## More Rules
- 错误码规范:`.claude/rules/error-handling.md`
- 限流规范:`.claude/rules/rate-limit.md`
- Redis Stream 规范:`.claude/rules/redis-stream.md`
- AI 服务调用规范:`.claude/rules/ai-service.md`
- 数据库规范:`.claude/rules/database.md`
- 前端规范:`.claude/rules/frontend.md`怎么写才能让 Claude 真正遵守?
内容选对了还不够,写法也得让 Claude 看得懂、做得到。
我这边最有用的经验就两条:能验证,能落地。
规则要具体可验证
“注意代码可读性”太虚了,Claude 看了也不知道具体要改哪里。
换成“函数名使用动词开头、单个函数不超过 40 行”,就好很多。它能照着做,你也能一眼看出来它到底有没有做到。
禁令要搭配替代方案
只写“不要做 X”,Claude 很容易绕出另一种奇怪写法。更稳的方式是顺手把替代方案也写上:不要做 X,遇到这种情况应该做 Y。
举个我自己项目里的例子。之前 Claude 经常写 @Autowired 字段注入,但团队规范是构造器注入。
一开始我只写了“不要用 @Autowired 字段注入”。效果很一般:它确实不用字段注入了,但有时改成手写构造器,有时又绕到别的注入方式上。后来我把规则补完整:
# 依赖注入
- 不要使用 @Autowired 字段注入
- 使用构造器注入,配合 Lombok 的 @RequiredArgsConstructor
- 参考示例:UserController.java 中的写法这就不是单纯说“不许做什么”了,而是把正确写法直接摆出来。后面再遇到类似场景,Claude 基本就会照这个模板走。
善用标记词但别滥用
如果某条规则 Claude 反复违反,可以在前面加 IMPORTANT: 或 YOU MUST: 提醒它。但这招别用太勤。整篇文件到处都是“重要”,最后就没有哪条真的重要了。
工程提示:如果 Claude 反复忽略某条规则,不要急着加感叹号。更大的可能性是文件太长了,这条规则被其他内容稀释了。解决方案是精简文件,不是加强调。
标题用常规名字
用 Commands、Structure、Conventions、Testing 这类在 README 里常见的标题。Claude 训练数据里有大量标准结构的 README,它对“这个标题下面通常写什么”有稳定的预期。取太花哨的名字反而增加理解成本。
Hooks
有时候即使你写了 Claude 也不会遵守文件的指令,这个时候你就需要在重要的地方加上 Hook,而不是仅仅靠指令约束,比如 PreToolUse,在 tool 执行前检查权限、风险评估等,通过了再执行 tool。
下面这张图展示了整个过程,图源 Claude Code 官方文档对 Hooks 的介绍。

这里有一个来自 OpenAI 的经验:能用工具强制执行的规则,不要写成自然语言。CLAUDE.md 是软约束,Linter/Hook/CI 才是硬约束。一条规则如果没法机械化验证,Agent 迟早会偏离。
比如你想阻止 Claude 修改敏感文件,写一百遍“不要改 .env”都不如加一个 PreToolUse Hook。
适合做 Hook 的事情:
- 编辑后自动格式化。
- 会话结束前跑测试。
- 禁止改
migrations/或.github/workflows/。 - 拦截
curl | bash、rm -rf、向外部端点发送敏感内容。 - 在 Sub-Agent 启动时注入额外上下文。
判断标准很简单:这件事如果漏掉一次会出问题,就用 Hook;如果只是希望 Claude 知道,才写进 CLAUDE.md。
CLAUDE.md 放在哪里?
Claude Code 支持 CLAUDE.md 放在多个位置。按加载顺序和影响范围,可以先这样看:
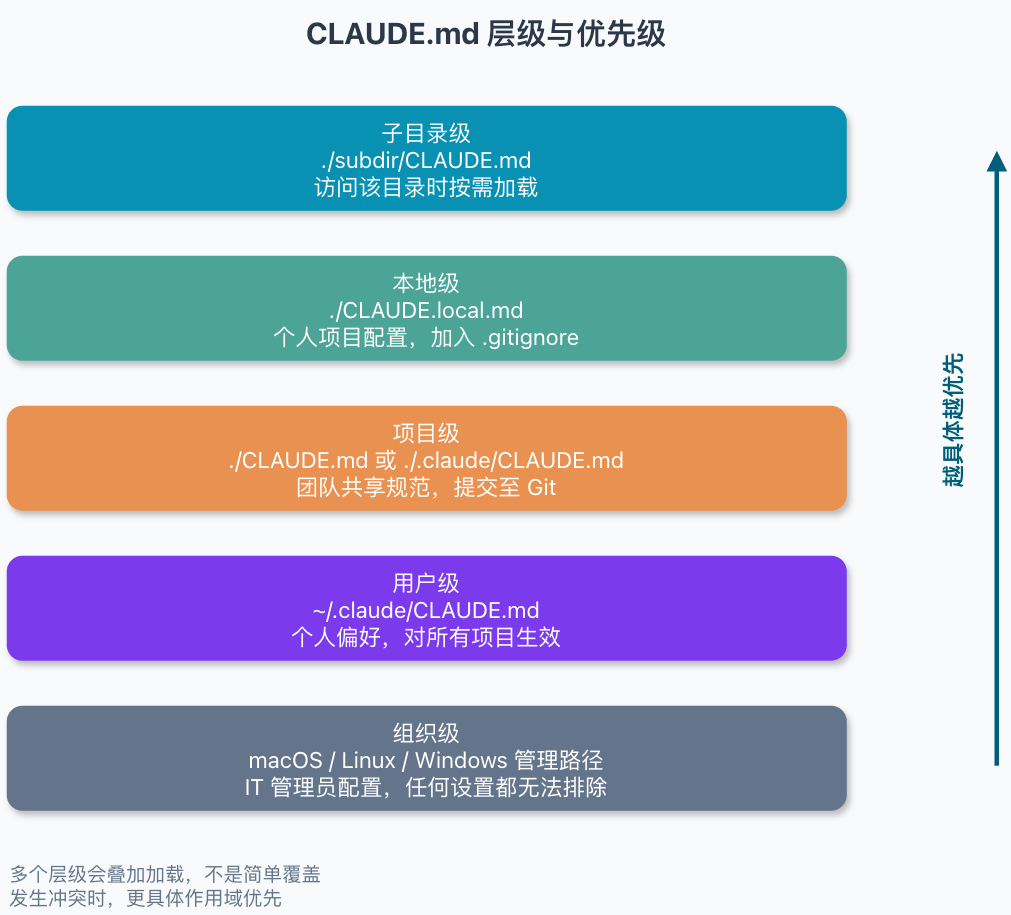
| 位置 | 路径 | 用途 |
|---|---|---|
| 组织级 | macOS: /Library/Application Support/ClaudeCode/CLAUDE.md,Linux/WSL: /etc/claude-code/CLAUDE.md,Windows: C:\Program Files\ClaudeCode\CLAUDE.md | IT/DevOps 统一下发的编码规范、合规要求和数据处理说明,不能通过个人配置排除。 |
| 用户级 | ~/.claude/CLAUDE.md | 你的个人偏好,对所有项目生效 |
| 项目级 | ./CLAUDE.md 或 ./.claude/CLAUDE.md | 团队共享规范,提交至 Git |
| 本地级 | ./CLAUDE.local.md | 个人的项目特定配置,加入 .gitignore |
| 子目录 | ./subdir/CLAUDE.md | Claude 访问该目录文件时按需加载,不在会话开始时注入 |
Claude Code 会把不同层级的 CLAUDE.md 一起加载,不是后面的文件把前面的直接覆盖掉。不过,越靠近当前项目、作用范围越具体的规则,会排在更后面,也更贴近当前任务。
比如用户级规则写“统一用空格缩进”,项目级规则写“这个仓库使用 Tab”,那在这个项目里,Claude 更可能按项目规则来。官方文档里的加载顺序也是从组织级、用户级,一直到项目级和本地级。真遇到互相打架的规则,最好直接删掉冲突项,不要指望 Claude 每次都选对。
我的做法比较简单:项目级 CLAUDE.md 提交到 Git,放团队都要遵守的规则;只和自己有关的偏好,比如当前项目里希望提交信息用中文,就放进 CLAUDE.local.md,再加到 .gitignore,别把个人习惯混进团队文件。
项目变大了,CLAUDE.md 怎么管?
一个人的项目,一份 CLAUDE.md 够用。但项目一变大、团队一介入,单文件就撑不住了。
这时候就可以从单文件过渡到分层了。
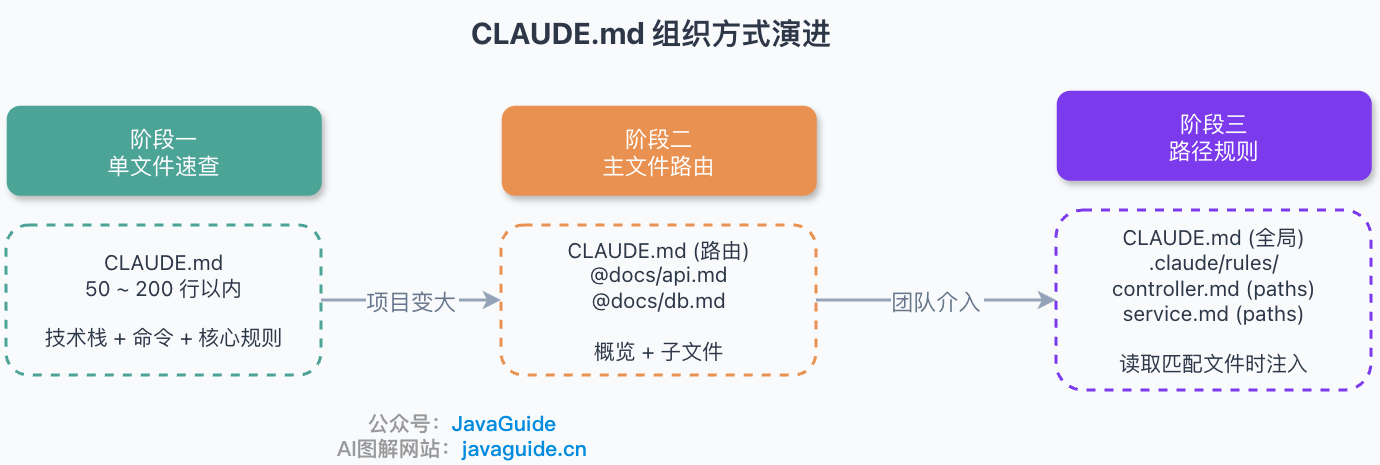
参照社区实践和我的观察,CLAUDE.md 的组织方式大致经历几个阶段:
起步:一份文件,几行核心规则。 大部分中小项目停在这里就够了。关键是保持精简——我自己的 CLAUDE.md 很少超过 50 行。
拆分:主文件做路由,规则分文件管理。 根目录的 CLAUDE.md 只放项目概述和常用命令,架构规范、API 约定、测试要求分别放在独立文件里,用 @path/to/file 引用:
## Project
Spring Boot 3.2 + MyBatis-Plus + MySQL 8.0 的订单管理服务。
## Commands
- 构建:`mvn clean package`
- 测试:`mvn test`
## Rules
- API 约定:@docs/api-conventions.md
- 数据库规范:@docs/database-rules.md按工作区域加载不同规则。 在 .claude/rules/ 里用 frontmatter 做路径匹配:
---
paths:
- "src/main/java/**/controller/**/*.java"
---
# Controller 规范
- 统一使用 Result<T> 包装返回值
- 所有接口必须添加 Swagger 注解这样编辑 Controller 时只加载 Controller 的规则,编辑 Service 时只加载 Service 的规则——不用在每个会话里塞全套规则。
不过这块有几个边界必须提前知道。
第一,path-scoped rules 是在 Claude 读取匹配文件时注入的,不是每次工具调用前都注入。也就是说,如果你直接让 Claude 新建一个匹配路径的新文件,创建期规则可能还没进入上下文。像“新建 Controller 必须带某个文件头”这类规则,不适合只放在带 paths 的规则里,应该放到无 paths 的全局 rules、根目录 CLAUDE.md,或者用 Hook 做硬约束。
第二,/compact 之后,根目录的 CLAUDE.md 会重新注入,但子目录 CLAUDE.md 和路径规则需要等 Claude 再次读取匹配文件才会重新加载。如果压缩后直接继续写文件,要先用 /memory 或 /context 看看规则是否还在。
第三,别凭感觉判断规则有没有生效。Claude Code 的 /memory 会列出当前会话加载的 CLAUDE.md、CLAUDE.local.md 和 rules 文件;更细的排查可以用 InstructionsLoaded Hook 记录哪些指令文件在什么时候被加载。
我目前在用的就是主文件 + 按路径匹配的规则文件这一层级。更高阶的玩法(比如引入 Skills 和 MCP 做动态能力加载)还在探索中。
工程提示:
@path/to/file会把整个文件内容嵌入到上下文中。如果被引用的文件很大(几百行),每个会话启动时都会把这些内容全部塞进去,直接烧掉一大块指令预算。官方文档目前限制递归导入最多 4 层。大文件改为自然语言引用——"架构细节参见docs/architecture.md",Claude 需要时会自己读取。
怎么维护?
CLAUDE.md 写完之后别放着不管。项目一变,里面的规则也会过期。
这里先把 CLAUDE.md 和 Auto Memory 分开看。CLAUDE.md 是你主动写给 Claude 的长期指令,适合放“必须遵守的规则”和“每个会话都要知道的项目事实”;Auto Memory 是 Claude Code v2.1.59+ 内置的自动记忆机制,更适合记住协作过程中学到的调试结论、偏好和工作习惯。
我的习惯是:会影响团队协作、每次会话都应该遵守的,写进 CLAUDE.md;只是在排查过程中学到的小经验,就交给 Auto Memory。
比如“所有接口返回 Result<T>”应该写进 CLAUDE.md;“这个项目的 Redis Stream 测试需要本地先启动 Redis”这种调试发现,让 Auto Memory 记住就够了。Auto Memory 默认开启,可以在 /memory 里查看、编辑、关闭;它会为每个项目维护独立的 memory 目录,但它不是团队共享规范,不能替代提交到仓库里的 CLAUDE.md。
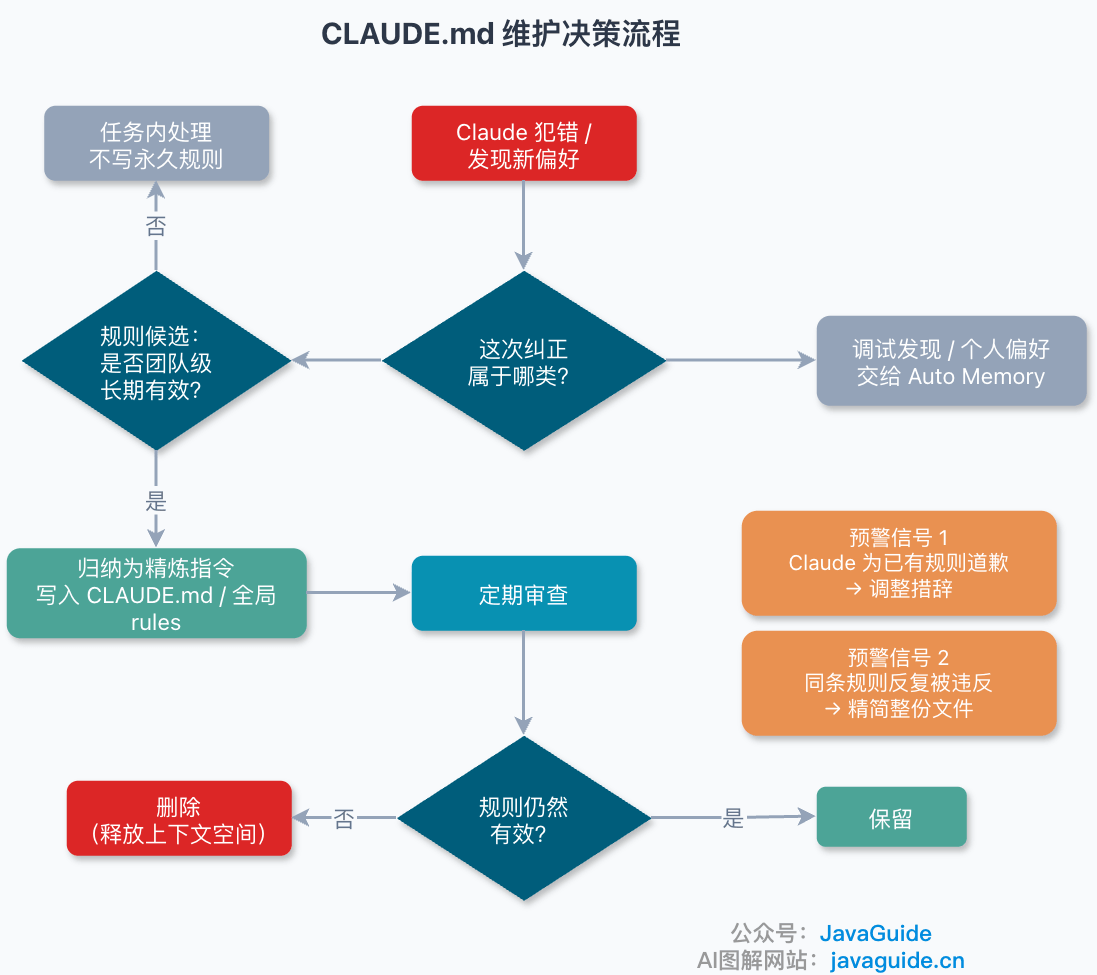
添加规则要慢
一条新规则只有在 Claude 确实犯了一个错误、且这条规则能防止同类错误再次发生时,才值得写进去。为还没发生过的事预设规则,往往是在浪费空间。
删规则要果断
如果某条规则已经存在很久了,但删掉后 Claude 的行为没有变化,说明这条规则从一开始就没起作用——Claude 本来就会这么做。果断移除,把空间留给真正需要的规则。
两个预警信号
信号一:Claude 为已经写在文件里的规则道歉。 比如“抱歉,我刚才忽略了 XX 规则”。这说明这条规则的措辞有问题——Claude 读到了但没当回事。换个更直接的表述。
信号二:同一条规则在不同会话中反复被违反。 这通常不是措辞问题,而是整份文件太长了,这条规则在上下文中被稀释了。解决方案不是改措辞,而是压缩整份文件。
两个实用的维护习惯
对话式审查。 每隔几周,找几个 CLAUDE.md 里的规则,问 Claude:“如果我删掉这条规则,你会改变行为吗?”如果它说不会,那这条规则可能就可以删。这种审查方式比自己逐行过效率高很多,但要注意:Claude 对自身行为的预判并不完全可靠,最终还是要以实际行为验证为准。对于拿不准的规则,更靠谱的做法是在两个平行会话中分别使用含/不含该规则的 CLAUDE.md,给出相同 prompt,观察输出差异。
错误驱动的持续进化。 以前我也喜欢一出错就让 Claude “更新 CLAUDE.md,下次别再犯”。现在会克制一点。
先看这个错误值不值得变成团队规则。如果它是长期有效、多人都要遵守的东西,再归纳成一句精炼指令写进 CLAUDE.md。如果只是我本机的偏好、某次调试时发现的小坑,交给 Auto Memory 就够了。
更稳的节奏是:同类错误出现几次后,再把它收敛成一条规则。不要每次出错都加一条,不然 CLAUDE.md 很快就会变成垃圾桶。
常见踩坑
下面这些坑我都遇到过,社区里也经常有人反馈:
CLAUDE.md只进不出。文件越写越长,Claude 反而开始漏规则。这个时候加粗、加叹号都没用,真正有用的是删。@导入巨型文件。会话还没开始,就先烧掉一大块上下文。大文件最好改成自然语言引用,让 Claude 需要时自己读。- 用 path-scoped rules 管新建文件。这个很容易踩坑,因为新建文件时路径规则不一定会加载。创建期约束更适合放全局 rules、
CLAUDE.md,或者直接用 Hook。 - 多个规则文件互相打架。Claude 往往不会告诉你它选了哪条执行,所以要定期做全量审查,把冲突的规则清掉。
- 为偶发事故加永久规则。一次罕见事故就写一条长期规则,后面每个会话都要为它付上下文成本,通常不划算。
总结
CLAUDE.md 说到底就是写给 Claude Code 的项目工作卡。
别把它写成百科,也别把它当许愿池。它最该记录的,是 Claude 靠读代码不一定能猜准、但一旦猜错就会影响结果的东西。
自己写也好,让 AI 帮忙维护也好,先盯住几个问题:
哪些信息 Claude 真的猜不准?哪些规则删掉以后它会犯错?哪些内容应该交给格式化工具、文档链接或按需读取?哪些调试发现其实放 Auto Memory 就够了?
项目变大以后,就别再把所有规则都塞进一个文件了。根目录 CLAUDE.md 放全局规则和路由,细节拆到 .claude/rules/ 或独立文档里,再用 /memory 确认它们是不是真的进入了上下文。
最后还是那句话:你一定比 AI 更了解自己的项目。哪些约定 Claude 猜不到,哪些边界是团队踩过坑才知道的,把这些写清楚,Claude Code 才更容易从正确的位置开始工作。