Vibe Coding 实用技巧总结:Git、Spec、上下文管理与多 Agent 协作
你好,我是小 G。上个周末,我通过文字消息分享了一些 Vibe Coding 的小技巧,不少 G 友反馈说分享的经验非常有用,甚至要把我的建议做成一个skill。还有一些朋友非常想要详细版。
于是,我爆肝了一篇,前后反复优化完善很多遍,把我这几年所有积累的 AI 编程经验都总结分享了出来,真心希望对你有帮助。
正文开始之前,想问问大家:你还记得自己第一次 Vibe Coding 的感觉吗?
我反正是特别上头,24 年第一次接触 Cursor,真是惊为天人。那种感觉就像小时候刚接触游戏一样,但比游戏还爽一些。每天最开心的事情就是 Vibe Coding,看着代码一行一行被自动写出来。就感觉自己一天做的事情比过去一周还要多。
那段时间是真的游戏都不想碰了,就想着 AI 能帮我多干点活。
但爽完之后,翻车情况也越来越多,经常会遇到一些莫名其妙的问题。这让我意识到,单纯凭感觉去 Vibe Coding 是不太可行的。
下面这些,是小 G 这几年用 AI 编码踩出来的一些经验。不花哨,但都挺管用。
先把 Git 准备好
如果只选一个最重要的 Vibe Coding 技巧,小 G 会选 Git。
原因很简单:AI 写错一行代码不可怕,可怕的是它一口气改了 20 个文件,等你发现方向不对,已经不知道哪一块该留、哪一块该扔。Git 不是写完代码之后再补的仪式,它应该站在 AI 动手之前。
让 Agent 改代码前,先看工作区:
git status --short如果当前目录里已经有改动,先弄清楚这些改动是谁的、要不要保留。多人协作或多 Agent 并行时,这一步尤其重要。不要让 AI 回滚它没写的东西,也不要把别人的半成品混进自己的任务里。
确认干净后,再给当前任务单独开分支:
git switch -c feat/order-export任务很小也建议开分支。主分支上裸跑 Vibe Coding,心理负担会越来越大;分支隔离之后,AI 就算写歪了,也只是当前任务分支的问题。
AI 改完后,别急着看它的总结,先看仓库自己怎么说:
git diff --stat
git diffgit diff --stat 看影响面,git diff 看细节。确认没问题之后,再分块暂存和提交:
git add -p
git commit -m "feat: add order export"一个提交只做一件事。能分块提交就分块提交,后面 Review、回滚、定位问题都会轻很多。AI 说“我只改了导出逻辑”,不如 diff 可信。
改坏了也尽量用可控回滚:
# 丢弃某个未提交文件的修改
git restore path/to/file
# 撤销已经暂存的文件
git restore --staged path/to/file
# 已经提交并推送过,优先生成反向提交
git revert <commit>git reset --hard 不是什么禁术,但别随手交给 Agent。除非当前分支就是一次性实验分支,否则它很容易把没保存好的改动一起抹掉。
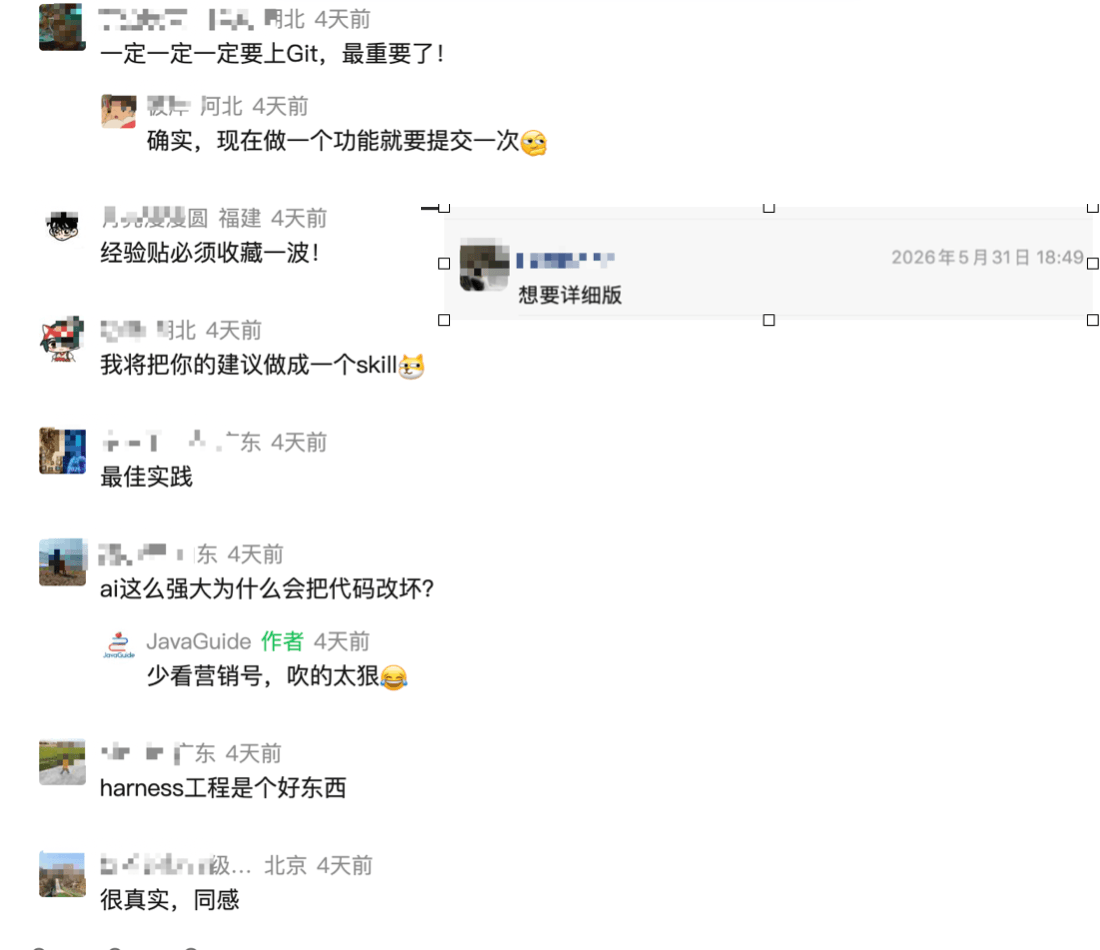
并行任务可以用 git worktree 隔离:
git worktree add ../project-order-export -b feat/order-export
git worktree add ../project-refactor-user -b feat/refactor-user一个 Agent 一个目录、一个分支、一个任务。这样它们即使乱改,也只会乱在自己的工作区里。
开工前先把范围写窄
你需要让 AI 做什么,尽量说得具体一些,不要让它自己猜。
以订单场景为例,你说一句:帮我实现导出订单功能。
这句话太宽泛了,AI 不知道每次导出几条,导出什么格式,导出哪些字段,字段顺序是怎样的。
信息没给够,它就会自己猜。猜出来的结果能跑,但未必是你想要的。
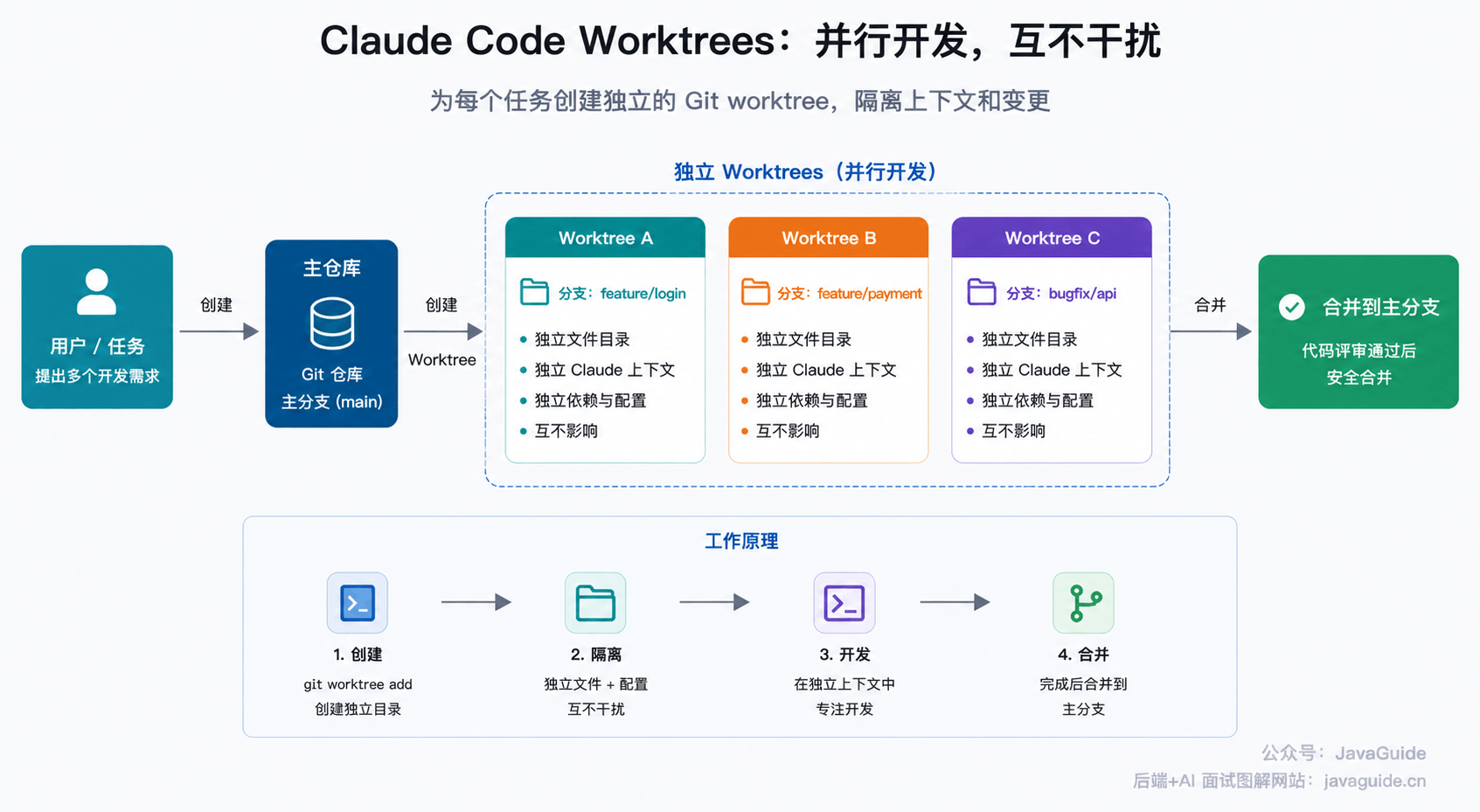
不如在开工前花几分钟写轻量 Spec,通常比后面返工便宜得多:
## 目标
实现订单导出接口,支持按时间范围导出 CSV。
## 约束
- 单次最多导出 5000 条
- 时间范围不能超过 31 天
- 只能导出当前租户的数据
- 查询必须走 order_tenant_time_idx
- 导出失败要记录失败原因,不能只返回 unknown error
## 验收
- 正常导出 CSV,字段顺序为 order_no、amount、status、created_at
- 超过 5000 条返回明确错误
- 越权租户数据不能被导出
- 单元测试覆盖无数据、越权、超过条数、超过时间范围 4 种情况这份东西不用写得像方案评审文档。
小任务写清楚目标、约束和验收就够了;中等任务再补接口格式、错误码、表结构;大一点的需求,再拆成 requirements.md、design.md、tasks.md。没必要一上来就把流程拉满,不然你会先被文档劝退。
关于 Spec Coding 的详细介绍,可以参考我写的这篇,质量非常高:Spec Coding 规范驱动编程实战:从 Vibe Coding 到 AI 代码规范。
还有一招,比抽象规范更管用:给 AI 看项目里写得好的代码。
先阅读 UserController、UserService、UserRepository 和对应测试。参考它们的分层方式、异常处理、返回体包装、日志风格和测试写法。然后实现 OrderExportController。
不要引入新的响应格式。
不要新增全局异常处理器。
不要绕过现有权限校验逻辑。“代码要优雅、可维护、符合最佳实践”这种话,放在 Prompt 里看着很认真,实际约束力很弱。
模型更擅长模仿具体样板。你让它看一段项目里真正合格的代码,它反而更容易写出同一套风格。
把项目坑点写进规则文件
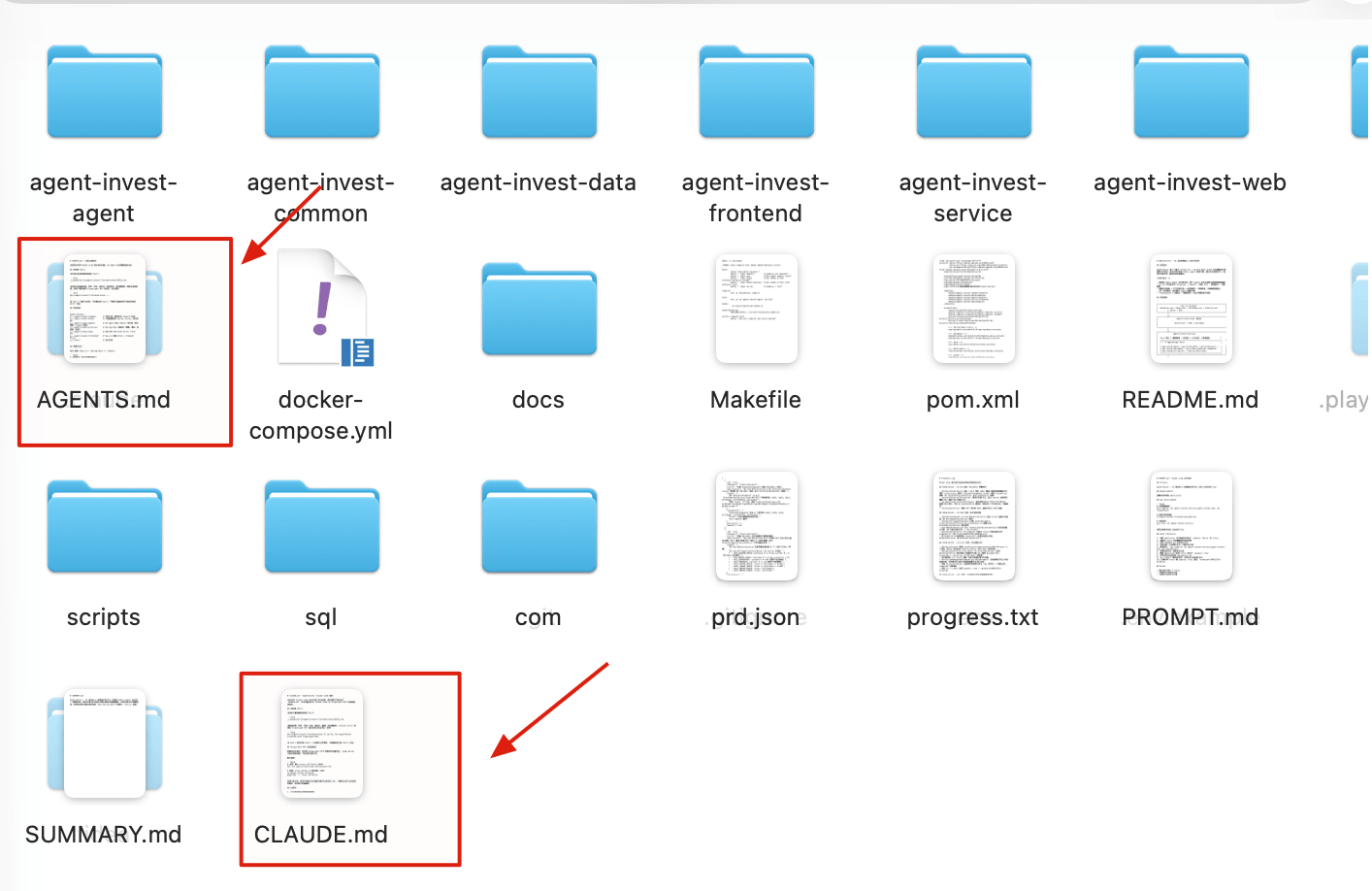
长期项目可以把这些规则放到 AI 工具能稳定读取的位置。比如:
- Claude Code:
CLAUDE.md - Codex:
AGENTS.md - Cursor:Project Rules、
.cursor/rules/*.mdc,也可以配合AGENTS.md - GitHub Copilot / VS Code:
.github/copilot-instructions.md
千万别写成项目说明书!应该写 Claude 容易猜错、代码里读不出来、团队又必须遵守的规则。重点放技术栈版本、常用命令、架构取舍、团队约定和项目坑点;别塞空话、默认行为和大段文档。
判断标准很简单:这行删掉后,Claude 会不会更容易犯错?
每次 AI 犯了重复错误,也别只在聊天里训它一句。
聊天记录会散,规则文件会跟着仓库走。你把坑补进规则里,下一次它才更可能绕过去。
善用 Skill,把套路沉淀下来
规则文件和 Skill 解决的问题不太一样。
规则文件更适合放这个项目一直要遵守什么,比如:技术栈版本、启动命令、目录结构、错误码格式、哪些文件不能碰。
Skill 更适合放遇到某类任务时应该怎么做。比如做代码审查、写测试、改前端页面、网页调研、写技术文章,这些任务每次流程都差不多,就没必要每次都在聊天里重新提醒一遍。
小 G 之前写过两篇相关的文章:Agent Skills 是什么?和 Prompt、MCP 到底差在哪? 和 AI 编程必备 Skills 推荐。
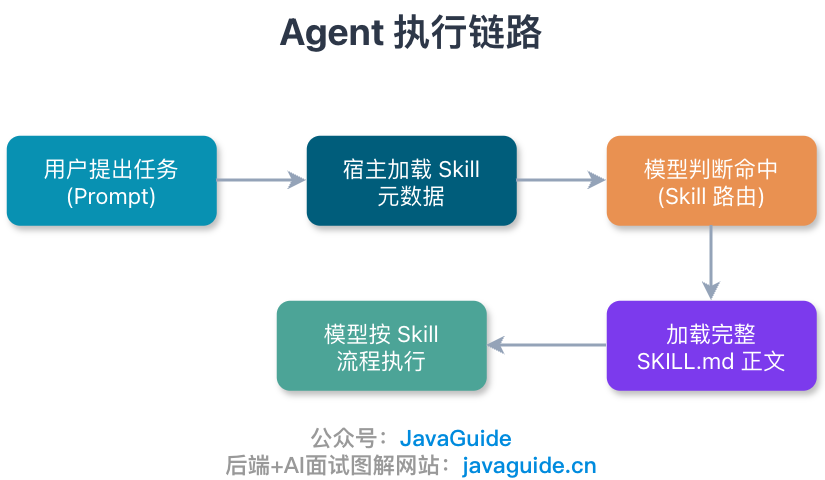
简单说,Skill 就是一份能被 Agent 按需加载的任务说明。它不是插件,也不是 MCP 工具本身,而是把某类任务的流程、约束、检查项和踩坑经验写进 SKILL.md。。
比如这些事情,就很适合沉淀成 Skill:
- 写功能前走 TDD:先写失败测试,再写实现。
- 做代码审查时固定检查安全、事务、性能、边界条件和项目约定。
- 写前端页面时固定检查响应式、hover 状态、可访问性和设计系统。
- 做网页调研时固定选择搜索、抓取、浏览器自动化这些工具的顺序。
- 写技术文章时固定检查事实来源、引用、标题层级和 AI 味。
为什么要用 Skill? 因为这些流程每次靠聊天提醒都很烦。你今天提醒它先写测试,明天换个会话它又忘了;你这次让它 Review 权限风险,下次它可能只看命名和格式。Skill 的价值就在这里:把重复提醒变成可复用的工作手册。
不过,Skill 也别写成 README。
README 是给人看的,可以讲背景、原理和安装说明;Skill 是给 Agent 执行任务时看的,重点是:什么时候用、按什么顺序做、哪些情况别做、失败了怎么兜底。
正文越长,越容易占上下文。写 Skill 时可以问自己一句:这段话会不会直接影响 Agent 下一步怎么做?不会,就别塞进去。
Anthropic 的建议是,SKILL.md 正文最好控制在 500 行以内;如果超过这个长度,就把细节拆到单独文件里,通过渐进式披露的方式让 Agent 按需读取。
现成 Skill 也可以直接用,比如 Superpowers 把 TDD、Code Review、Spec-Driven、Git Worktree、子 Agent 协作这些流程封装好了。
我在 AI 编程必备 Skills 推荐:TDD、代码审查与网页自动化实战这篇文章中有详细推荐。
但第三方 Skill 不要拿来就跑。SKILL.md 也是指令,里面如果带了危险命令、奇怪脚本、过宽权限,Agent 会照着做。装之前至少看一眼正文、scripts/ 和 references/,确认它没有越权操作。
贵模型别拿来搬砖
不要什么事都丢给最贵的模型。
这就像请了一个资深架构师,结果天天让他改字段名、补 getter、调 CSS,钱花了,价值没用出来。反过来也一样,为了省钱把系统设计、安全边界、复杂重构全交给便宜模型硬扛,最后返工成本可能更高。
小 G 更常用的是“贵模型把方向定清楚,便宜模型去干活,最后再让贵模型验一遍”。
第一步,让 Claude Opus 4.6 / Opus 4.7 这类顶级模型读需求和代码库。
只让它做方案、列风险、拆任务,不让它急着写代码。
第二步,方案确认后,把一个个 Task 丢给 DeepSeek V4-Pro / GLM5.1 或同级低价模型。
让它按任务编码、补测试、跑命令,做完之后给出 diff 摘要。
第三步,把 git diff 交回 Claude Opus 4.6 / Opus 4.7。
这次只让它 Review:Bug、越权风险、事务边界、性能问题、测试缺口。代码审计也可以这么干。先让便宜模型扫一遍项目,把疑似问题列出来;再让强模型复核这些问题到底成不成立。直接让高价模型全量扫,当然也不是不行,就是钱烧得快,收益未必成比例。
别听它说修好了,看证据
AI 最爱说“已修复”“已优化”“没问题”。
听听就行,别直接信。
小 G 更愿意看三样东西:测试、命令输出、diff。
比如你让它修一个订单导出 Bug,不要只问“修好了吗?”。可以直接这样要求:
先不要改实现。
先根据 Spec 补测试,覆盖正常路径、参数非法、权限不足、无数据、并发重复请求。
测试一开始应该失败。
我确认测试合理之后,你再改实现,直到测试通过。这个做法有点像 TDD,但不用搞得很教条。重点是别让 AI 一边改代码、一边补一个永远会通过的测试。先让测试失败,再让实现通过,心里会踏实很多。
不想完整 TDD,至少也要让它列清楚验收项:
- [ ] 新增接口有权限校验
- [ ] 错误返回符合统一格式
- [ ] 数据库查询命中指定索引
- [ ] 空值、越界、重复请求都有测试
- [ ] 日志不打印 token、password、api key
- [ ] 所有测试通过还要让它贴运行过的命令和结果:
mvn test
npm test
go test ./...
pnpm lint没跑就写“未运行”,并说明原因。比如依赖没装、数据库没起、测试环境缺配置,都可以接受;最怕的是它没跑,但写一句“已验证”糊弄过去。
性能优化更不能只听它说。它说“速度提升明显”,你就让它把证据贴出来:优化前后的 SQL、EXPLAIN、测试数据量、P95/P99 或接口耗时。没有真实压测结果,就只写预期收益和待验证项,别让它编数字。
上下文别越堆越乱
小 G 之前写过一篇 Context Engineering,里面有个观点放到 Vibe Coding 里也很适用:上下文窗口大不等于效果好——窗口能装更多东西,但模型能不能稳定找到重点,是另一回事。
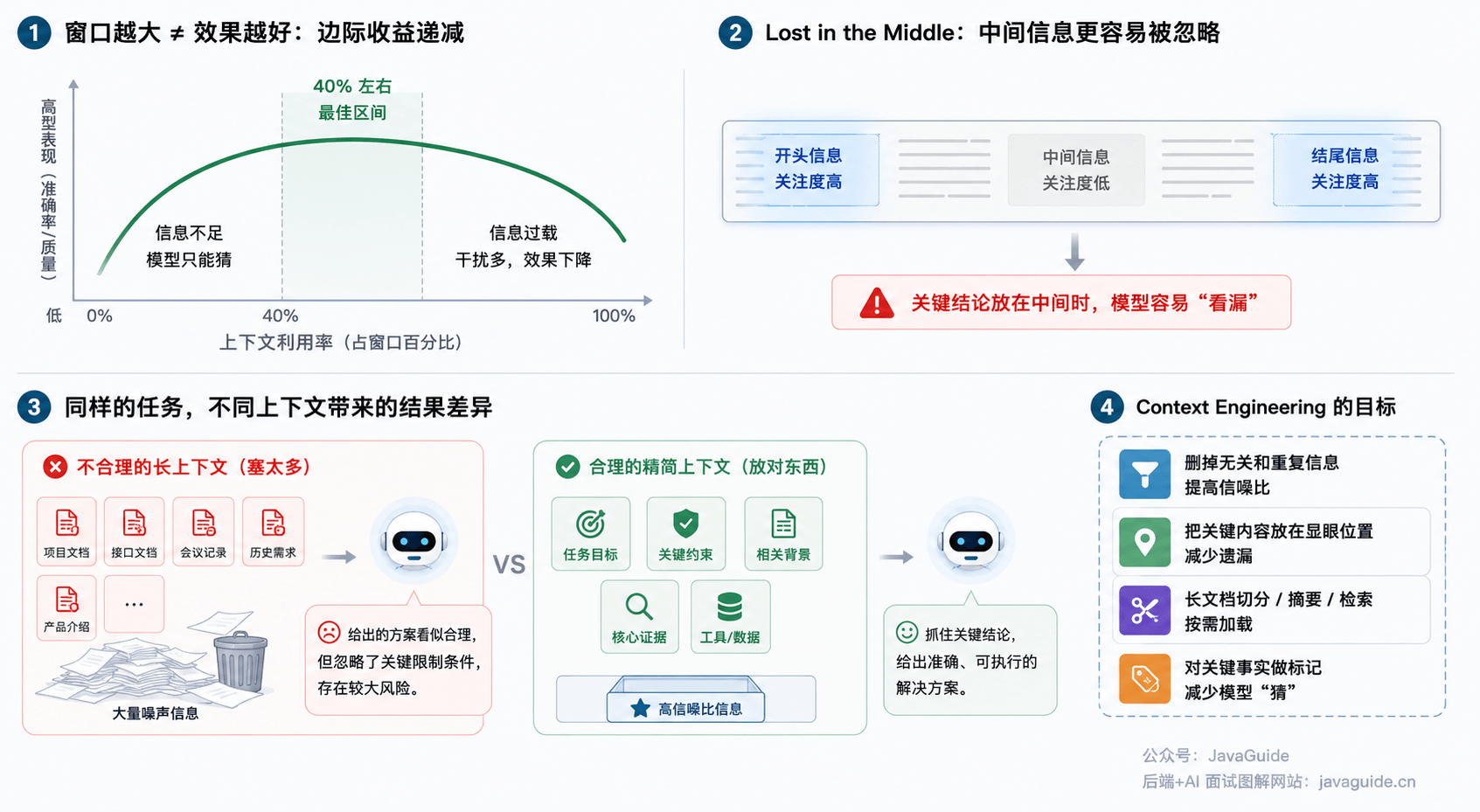
一个会话里先写登录,再改支付,再重构缓存,最后又问为什么测试挂了,模型迟早把旧约束、失败尝试和废弃方案混在一起。你以为自己给了它完整历史,它拿到的可能是一堆噪声。
Vibe Coding 里,上下文要管三件事。
第一,别把仓库一股脑塞进去。 当前任务只需要 Spec、相关文件、报错日志、验收命令和少量参考实现。其他内容先用路径、文件名、目录结构挂着,等需要时再让 Agent 去读。Claude Code 分析大仓库时也是这种思路:先用搜索和目录定位,再逐步读具体文件,而不是上来吞全量代码。
第二,长任务要及时压缩。 Claude Code 可以用 /compact 压缩上下文,用 /clear 清空上下文(详细用法参考 Claude Code 核心命令详解);Codex 或其他 Agent 也有类似的摘要、压缩、重开机制。压缩是为了保留重点(如:架构决策、已改文件、未解决问题、失败命令和下一步任务),丢掉重复对话和已经消化过的工具输出。
第三,关键进展要落到文件里。 比如让 Agent 在长任务中维护一份 NOTES.md 或任务 handoff,记录:
## 已完成
- 修改了哪些文件
- 哪些测试已经跑过
- 哪些问题已经确认不是 Bug
## 剩余任务
- 还没修的失败用例
- 还没确认的边界场景
- 下一个 Agent 需要先读哪些文件这样就算开新会话,也不用重新解释半天。聊天记录会变长、变乱、变旧,结构化笔记反而更稳定。
小 G 的习惯是:一个会话只处理一个任务;超过两次纠正还不对,就开新会话;新会话只带当前 Spec、相关文件、失败日志、验收命令和上一轮 handoff。对多数编码任务来说,3000 到 8000 tokens 的高质量上下文,通常比几十万 tokens 的杂乱对话更可靠。
上下文包可以写得很朴素:
## 当前任务
实现订单导出接口。
## 必读文件
- src/main/java/.../UserController.java
- src/main/java/.../OrderRepository.java
- docs/spec/order-export.md
## 禁止修改
- 数据库已有字段名
- 全局异常格式
- 登录鉴权逻辑
## 验收命令
- mvn test
- mvn -Dtest=OrderExportServiceTest test文档也可以当上下文用。AI 改了多个模块后,让它补一份变更说明:新增了什么接口,改了哪些表或索引,关键业务规则是什么,如何验证,如何回滚。这样就可以下次继续开发时能直接喂给 AI。
历史包袱多的项目里,哪个字段不能改、哪个接口兼容老客户端、哪个枚举值被外部系统写死,这些口口相传的规则都该进文档。
多 Agent 先串行再并行
多 Agent 分工协作的玩法,确实很香,但真心不建议大家上来就尝试多 Agent 并行(例如,一个写代码,一个补测试,一个做 Review,一个写文档),很容易把项目搞乱。
你刚开始就串行着跑就好了:
- Plan Agent 只读代码,输出方案和任务拆分;
- Code Agent 只负责一个 Task,不碰其他任务;
- Test Agent 补测试并运行验证;
- Review Agent 只看 diff,找问题,不直接大改。
一定不要一上来就让多个 Agent 同时改代码,让们在同一个 feature 分支上按顺序提交:
git commit -m "[plan] add order export design"
git commit -m "[code] implement order export api"
git commit -m "[test] add order export tests"
git commit -m "[review] fix tenant permission check"等流程跑顺以后,也比较熟练之后,再考虑 worktree 并行、Agent View 这类玩法。

并行最怕的不是 Git 冲突,那种至少能看到。真正麻烦的是不冲突——两个 Agent 同时改同一个公共 DTO,一个为了导出加字段,一个为了查询删字段,合并时看起来没问题,但接口语义、序列化结果、前端依赖可能已经变了。
所以多 Agent 不能靠运气,要靠任务边界、分支隔离和验收项管住。哪些文件能改、哪些模块不能碰、改完要跑哪些测试、哪些 diff 必须人工看,都要提前写清楚。
subagent 适合做专项任务
这里也可以顺手提一下 subagent。
以 Claude Code 为例,subagent 可以理解成一个“专门干某类活的小助手”。它有自己的上下文、系统提示词和工具权限,适合处理边界比较清楚的任务,比如代码审查、测试补齐、日志分析、文档整理。官方文档里也提到,subagent 可以在独立上下文中运行,减少主会话的上下文压力,并且可以为不同任务配置不同的工具访问权限。
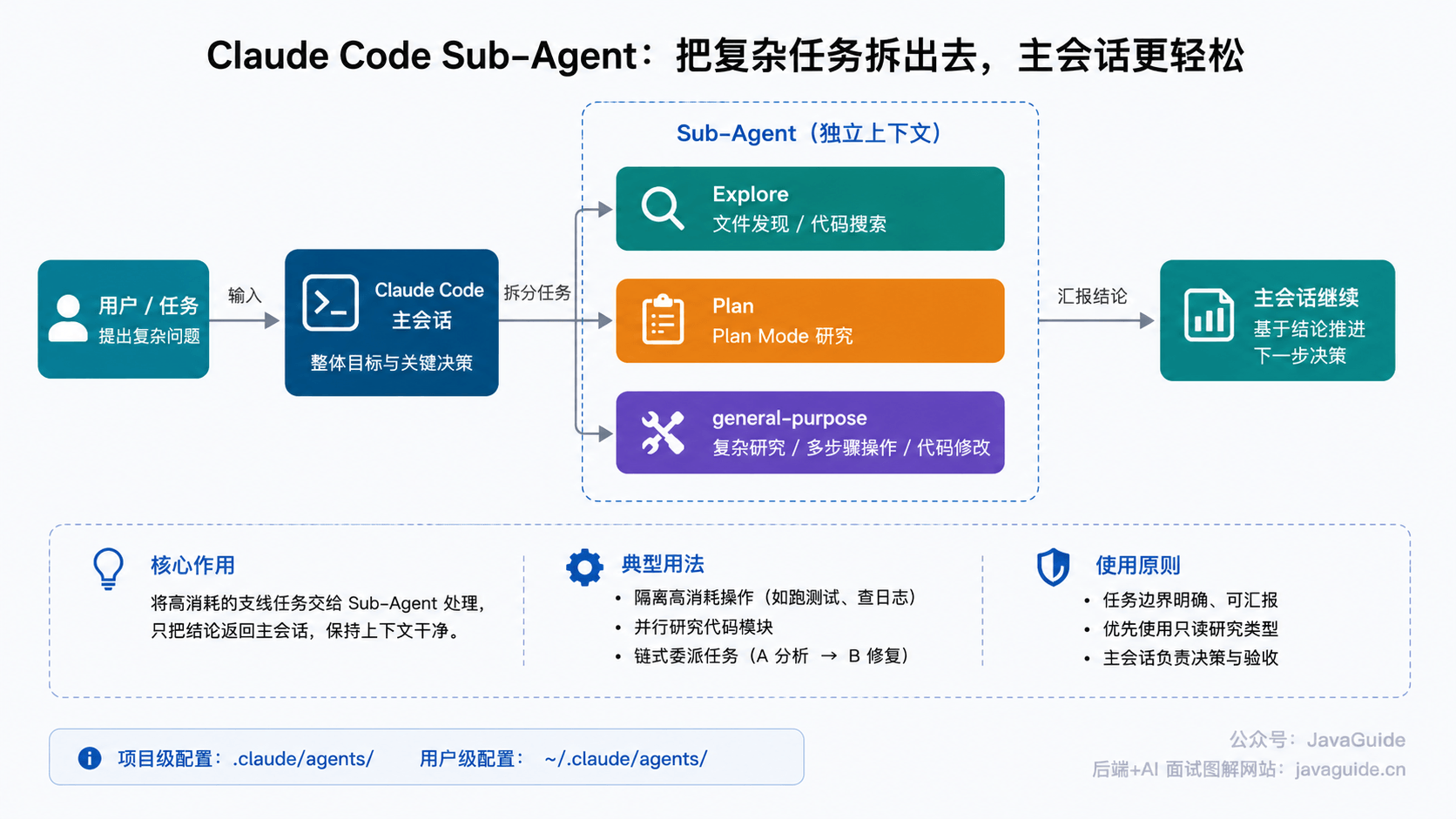
它和前面说的多 Agent 并行不是一回事。多 Agent 更偏协作方式,subagent 更偏任务委派。比如主会话正在实现订单导出功能,你可以把“检查这次 diff 有没有权限绕过风险”交给 Review subagent,把“根据当前代码补单元测试”交给 Test subagent。它们各自做完后,把结论返回给主会话。
但 subagent 也别滥用。任务太小、边界不清、代码还在剧烈变化时,拆出去反而容易增加沟通成本。比较稳的用法是:主 Agent 负责整体上下文和决策,subagent 负责局部、明确、可验收的任务。
权限控制很重要
AI Coding 不能只靠 Prompt 里写一句:“请你谨慎一点,别做危险操作”。
Claude Code 这类工具已经不只是回答问题了,它会读文件、改代码、执行命令,也可能通过 MCP 调内部工具或外部服务。风险自然也不再只是代码写错,更严重的问题可能误删文件、改坏配置、跑错迁移、推送到远程,甚至碰到密钥、证书、生产配置这类敏感信息。
所以权限要提前收住。
.env.production、密钥、证书这类文件,默认就不应该让 AI 读取或修改;删除文件、数据库迁移、推送远程、改 CI 配置这类操作,必须人工确认;登录、支付、权限、上传、Webhook 这类模块,改完要单独做安全 Review。
Claude Code 官方其实也提供了对应的权限机制。比如可以用 /permissions 查看和管理工具权限;权限规则里可以配置 allow、ask、deny,分别表示允许执行、执行前询问、直接拒绝。像 git diff、跑单测这类低风险命令,可以放得宽一点;git push、删除文件、读取 .env、访问 secrets/** 这类操作,就应该放到 ask 或 deny 里。
如果只是配置权限规则还不放心,可以继续加 Hooks 和 Sandbox。Hooks 可以在工具调用前后执行自定义检查,比如拦截危险命令、检查是否改了敏感路径、在提交前跑格式化和测试;Sandbox 则更偏执行环境隔离,用来限制 Bash 命令能访问的文件系统和网络范围。
举个例子,假设 Claude Code 准备执行:
rm -rf /tmp/buildPreToolUse Hook 会先拿到这次 Bash 调用,判断它是不是危险命令;如果命中规则,就返回 deny,Claude Code 会取消这次工具调用,并把拒绝原因反馈给 Claude。
下面这张图展示了整个过程,图源 Claude Code 官方文档对 Hooks 的介绍。

更稳的做法,是把这些规则固化到工程里:
- 哪些命令可以自动执行;
- 哪些命令必须人工确认;
- 哪些路径禁止读取或修改;
- 哪些 MCP 工具不能随便调用;
- 哪些 CI 任务必须人工审批;
- 哪些测试不过就不能合并。
这里还有一个容易忽略的点:权限规则不是万能的。比如你只拦了 rm *,不代表一定拦得住 /bin/rm、find -delete 这类变体。所以高风险操作不能只靠一条命令黑名单兜底,最好结合路径限制、Hooks、Sandbox、CI 和人工 Review 一起管。
工程上的谨慎,肯定不能写在 Prompt 里,要落到命令、脚本、权限、测试、CI 和审批流程里。
分享下我常用的一套流程
日常写需求时,小 G 一般按这个节奏走:
- 新建分支,先确认工作区是干净的。
- 写一份轻量 Spec,把目标、约束、验收标准说清楚。
- 看看有没有合适的 Skill,比如 TDD、Code Review、前端设计、网页调研。
- 先让顶级模型出方案,只讨论方案,不急着写代码。
- 方案确认后,再让低价模型按 Task 一步步实现。
- 每完成一个 Task,就跑测试、看 diff,然后小步提交。
- 当前 diff 稳住后,再让顶级模型做一次 Review。
- 修掉 Review 里合理的问题,再跑一遍测试。
- 合并前,人工看关键 diff。涉及数据、权限、支付、定时任务这类改动时,再补一下文档、回滚方案或者灰度说明。
这个流程比“一句话生成代码”慢一点。
但慢的这点时间,通常会在后面赚回来。至少能少很多返工、回滚和线上排雷。
短期原型可以大胆 Vibe,先把东西跑起来再说;但只要代码要长期维护,还是得回到工程流程里。GitHub Flow 本身也是围绕分支、Pull Request、Review 和合并来组织协作,不是让人直接往主分支怼代码。Codex 这类工具也支持通过 AGENTS.md 放项目级规则,让 AI 按仓库里的约定做事,而不是每次都靠聊天临时提醒。
说白了,AI 写代码越快,Git、测试、Review、Spec 这些老东西越不能丢。
以前它们是为了约束人,现在还得顺手约束 AI。