Claude Code 使用指南:配置、工作流与进阶技巧
你好,我是小 G。前几天那篇 Vibe Coding 实用技巧总结,公众号阅读两天时间到了 6w+,评论区里问 Claude Code 的朋友不少。
这篇就来单独聊聊 Claude Code。
不知道大家和我是不是有同样的感觉,刚开始用的时候真挺别扭,甚至有点抵触:已经习惯了 Cursor、IDEA 里的侧边栏、文件树、diff 面板,再回到终端里跟 AI 协作,真心不顺手。
后来用多了,反而觉得 CLI 这层很适合长任务。它能在本地跑,也能搬到远程机器、临时环境、CI/CD 里跑;同一套命令、权限和验证方式可以复用,不用为了 GUI 再改一遍步骤。
现在我用 Claude Code,直接先把目录、目标和验收方式说清楚,让它自己去读代码、跑命令,最后我再看 diff 和测试结果。
麻烦也在这里。CLAUDE.md 写太满、权限放太宽、上下文塞爆、Sub-Agent 拆错边界,都会让它越跑越偏。
下面这些内容基本来自我这一年多的使用记录,偏实战,不追求把官方文档重新讲一遍。
PS:Claude Code 迭代非常快,本文按 2026 年 6 月前后的官方文档和个人使用经验整理。命令、权限模式、插件、Auto Mode、Sub-Agent 和 Worktree 行为,可能受版本、平台、账号套餐、provider 和安装渠道影响。实际使用前,最好先看 claude --version、claude --help、/help 和官方文档。比如 /run、/verify 需要 v2.1.145+;/code-review 支持 effort 等级、--comment 和 --fix;/simplify 当前更适合理解成 cleanup-only review,不是完整的 correctness bug review。
国内使用还要考虑账号、网络、成本和第三方中转稳定性。GLM、MiniMax、Kimi、DeepSeek 这类国产模型可以作为替代或补充;但碰到大规模代码修改、复杂重构、长链路排错,Claude 目前仍然值得单独研究。
CLAUDE.md 非常重要
CLAUDE.md 最好别写成第二份 README。它更像是写给 Claude Code 的项目备忘录:哪些规则代码里看不出来、哪些命令经常被它猜错、哪些目录不要碰、改完某类代码必须跑哪条测试。
我的项目文件里通常只留这些东西:Claude 容易猜错的规则、代码里读不出来的约定、团队必须遵守的规范,以及技术栈版本、常用命令、架构取舍、项目坑点。
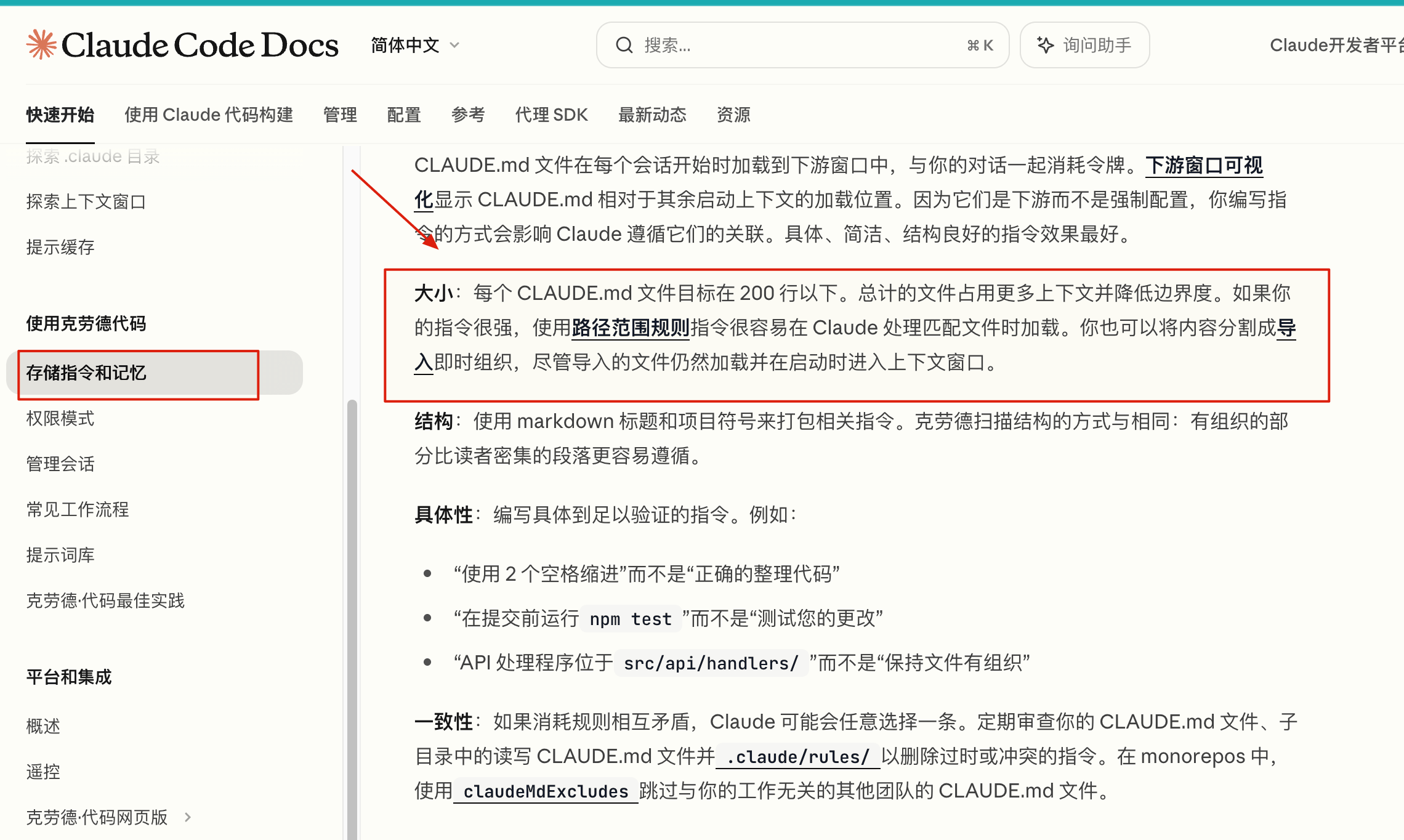
官方文档建议每份 CLAUDE.md 目标控制在 200 行以内。文件太长会消耗更多上下文,也可能降低规则遵守度。内容继续膨胀时,再拆到带 paths 的 .claude/rules/,低频参考内容放进 Skills。
我判断一条规则该不该留,会问一句:
这行删掉后,Claude 会不会更容易犯错?
如果会,就保留;如果不会,直接删掉。
放在哪里
CLAUDE.md 可以放在多个位置。官方的加载顺序大致从全局到局部,别只盯着项目根目录那一份:
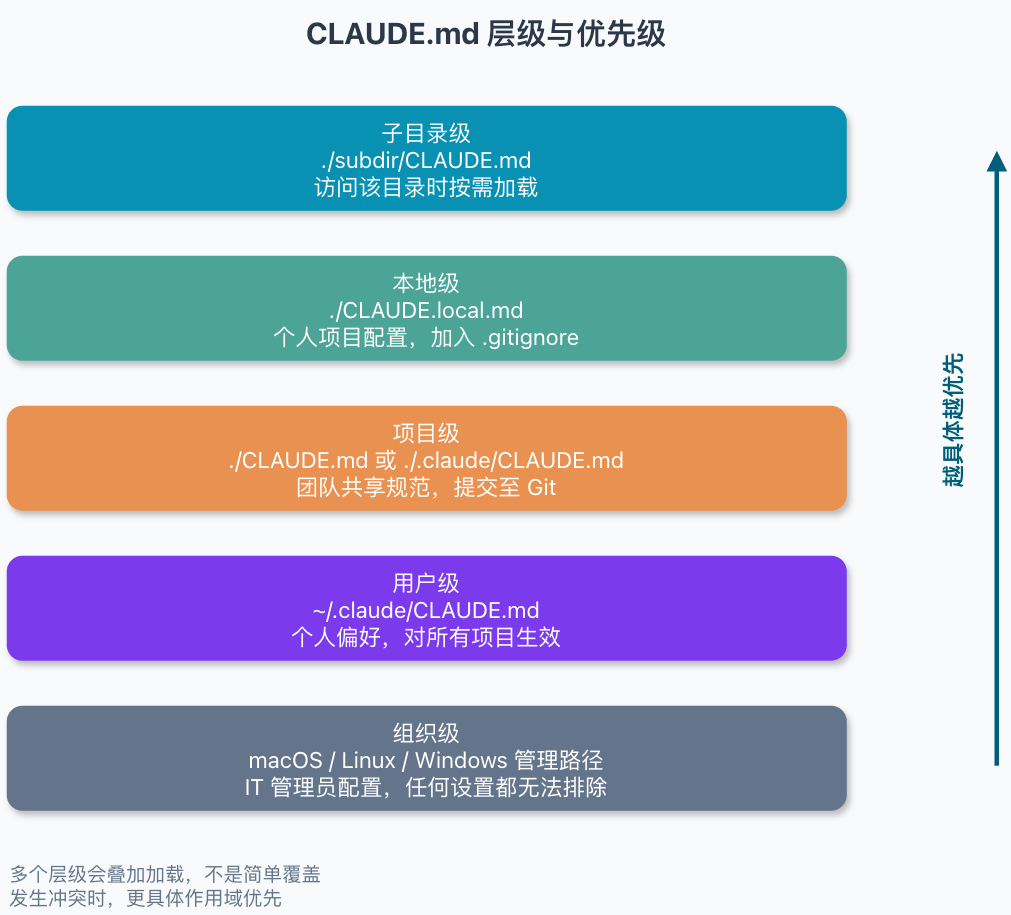
最外层是组织级文件,通常给 IT 或 DevOps 统一下发规范。macOS 路径是 /Library/Application Support/ClaudeCode/CLAUDE.md,Linux/WSL 是 /etc/claude-code/CLAUDE.md,Windows 是 C:\Program Files\ClaudeCode\CLAUDE.md。这类规则一般不是个人项目里要动的东西。
再往下是用户级 ~/.claude/CLAUDE.md,适合放自己的通用偏好。项目级文件放在 ./CLAUDE.md 或 ./.claude/CLAUDE.md,应该提交到 Git,让团队都看到。本地级 ./CLAUDE.local.md 只留个人配置,记得加进 .gitignore。子目录里的 CLAUDE.md 不会一开局就全塞进上下文,Claude 访问到对应目录时才按需加载。
这些文件会一起进入上下文,后加载的文件不会把前面的内容整块覆盖掉。只是越靠近当前项目、作用范围越具体的规则,会排在更后面,Claude 通常也更容易采纳。
比如用户级规则写“统一用空格缩进”,项目级规则写“这个仓库使用 Tab”,那在这个项目里,Claude 通常会优先按项目规则来。官方文档里的加载顺序也是从组织级、用户级,一直到项目级和本地级。
我的习惯是把项目级 CLAUDE.md 提交到 Git,只写团队共同遵守的规则。只和自己有关的偏好,比如某个项目里想让提交信息用中文,放进 CLAUDE.local.md,再加到 .gitignore。
项目规模大时,可以拆开:
my-project/
├── CLAUDE.md
├── backend/
│ └── CLAUDE.md
├── frontend/
│ └── CLAUDE.md
└── .claude/
├── rules/
├── skills/
└── agents/根目录放全局约定,子目录放局部规则。Claude 读取到某个子目录文件时,会按需加载对应目录下的说明。这个机制对 monorepo 很友好,后端、前端、管理台不用挤在一份文件里。
@path 引用也别误会。它不会凭空省上下文,被引用的内容最终还是会进来,只是维护起来更清楚。某些规则只对特定目录生效时,优先考虑 .claude/rules/ 这类按路径加载的规则,别继续往根目录文件里塞。
初始化和维护
新项目可以先运行:
/initClaude 会读仓库,生成一份初始 CLAUDE.md。这份文件只能当草稿,别直接提交。它可能猜错 build 命令,也可能把 README 里已经写清楚的内容又抄一遍。
维护时最容易失控的是越写越多。
Claude 偶尔犯一次错,先别急着加规则。等同类问题出现两三次、你也能用一句明确指令挡住它,再写进去。反过来,代码里一眼能读出来的事实、模型本来就会做的事、已经过时的历史约定,都应该删掉。规则太多时,最该看的几句会被冲淡。
如果 Claude 明明读到了规则却没照做,先看规则写得是否太软。“尽量保持测试完整”就很虚;“修改 Service 后必须运行对应单测,并贴出命令和结果”更好执行。同一条规则在多个会话里反复失效,再去检查文件太长,或者规则放错了位置。
我会把规则分成两类:团队级、长期有效、必须共享的要求写进 CLAUDE.md;个人偏好、阶段性调试经验、临时提醒,交给 Auto Memory 或本地配置。CLAUDE.md 最好来自真实错误,也要定期删掉失效内容。
写完规则后,也别默认它已经生效。可以用 /memory 看当前会话到底加载了哪些 CLAUDE.md、CLAUDE.local.md 和 rules 文件;如果某个文件不在列表里,Claude 这轮就看不到。复杂项目里用了带 paths 的 .claude/rules/,还可以用 InstructionsLoaded Hook 记录规则文件什么时候被加载、为什么被加载,别等出了问题才发现某条规则根本没进上下文。
权限管理要重视
分层授权
Claude Code 默认会对敏感操作弹确认,比如写文件、执行 Bash、调用 MCP 工具。刚开始会觉得麻烦,但在你还不熟悉它的执行习惯时,先保留确认更安全。
我一般先只放开那些看了也不会出事、跑了也不会破坏现场的命令。比如 git diff、git status、rg 这类只读命令,可以少拦一点;mvn test、pnpm test、npm run lint 这类固定验证命令,也可以按项目情况放行。
反过来,rm -rf、git push --force、修改 .git/ 这类操作默认不要放。.env、secrets/、生成产物、证书目录和各种 dump 文件,也尽量用 deny 规则先挡住。
权限可以通过 /permissions 配,也可以写进 .claude/settings.json:
{
"permissions": {
"allow": ["Bash(git status*)", "Bash(git diff*)", "Bash(rg *)"],
"deny": [
"Read(./.env)",
"Read(./.env.*)",
"Read(./secrets/**)",
"Bash(rm -rf *)"
]
}
}规则会被 Claude Code 的执行层处理。也就是说,就算 prompt 里写了“请一定不要读 .env”,那仍然只是建议;deny 规则才会拦住对应操作。
Auto Mode 的分类器也会参考你在对话里写下的边界,但这不是硬保证。不能丢的边界,最好写进 permissions.deny,或者用 Hook 在工具调用前拦住。长会话压缩以后,聊天里临时说过的限制也可能被压掉。
Auto Mode
如果频繁确认已经影响节奏,可以考虑 Auto Mode。
当前官方文档里,CLI 会通过 Shift+Tab 切换权限模式;当账号、模型、provider 和组织设置都满足要求时,auto 才会出现在模式循环里。Team / Enterprise 环境下,管理员还可能把它打开或锁掉。
它的原理是用一个单独的分类器判断操作风险,低风险操作自动放行;下载并执行陌生代码、向外部端点发送敏感内容、生产部署、强推、直接 push 到 main 这类动作,会被阻断或转人工确认。
不过 Auto Mode 不提供安全沙箱,也不保证不会误判。它解决的是“少点确认”,不负责隔离文件系统、网络和凭据。高风险任务还是要靠容器、临时账号、最小权限、deny 规则、Hooks 和人工 Review。
想默认进入 Auto Mode,也别把 "defaultMode": "auto" 写到项目级 .claude/settings.json 或 .claude/settings.local.json 里。v2.1.142+ 会忽略这些来源里的 auto 设置,避免仓库自己给自己打开 Auto Mode。应该放到用户级 ~/.claude/settings.json 或组织 managed settings。Bedrock、Vertex AI、Microsoft Foundry 这类 provider 还可能需要额外设置 CLAUDE_CODE_ENABLE_AUTO_MODE=1。
启动参数也不要写死。不同版本、安装渠道和 provider 对 permission mode 的支持可能不同,脚本里最好先用 claude --help 或官方文档确认当前可用值。交互使用时,我更倾向于在会话里用 Shift+Tab 切换模式,而不是把高权限模式写进脚本。
--dangerously-skip-permissions 我不建议在日常项目里用。除非你已经把文件系统、网络、凭据都隔离好了,否则一次误操作就可能改到不该改的文件,或者读到不该读的凭据。
安全边界
生产凭据、数据库密码、云厂商长期 token,不要直接暴露给 Claude;生产环境也别让它直接碰,除非这件事本来就有审批和审计。
Git 这边也要收紧。不要允许它默认 push 到 main,更不要让强推远端分支变成一个随手能执行的动作。来源不明的远程脚本,尤其是 curl | bash 这种写法,最好只在隔离环境里试。
文件读取范围同样要管住。.env、secrets/、证书目录、SSH key、数据库 dump、生产日志,这些都不该默认进 Claude 的可读范围。
不只是 .env。像 ~/.aws/、~/.gcp/、~/.kube/、~/.ssh/、Maven settings.xml、npm token、生产日志和数据库 dump,都不应该随便暴露给 Claude。真要让它看日志,也尽量先脱敏、截取和限定范围。
真的需要自动化高权限任务时,放进容器、临时凭据、最小权限账号里跑。这样即使命令执行错了,影响范围也更可控。
MCP、Skills、Sub-Agent 和插件怎么分
Claude Code 周边东西很多,刚接触时确实容易混在一起。我自己的分法大概是这样:
| 机制 | 解决什么问题 | 适合放什么 | 不适合放什么 |
|---|---|---|---|
CLAUDE.md | 每次会话都要知道的背景 | 构建命令、目录约定、团队规则 | 多步骤任务流程 |
| Rules | 按路径加载局部规则 | 前端规则、后端规则、安全规则 | 全项目都要看的核心约定 |
| Skills | 可复用任务步骤 | TDD、Code Review、写文章、前端实现 | 永久背景知识 |
| MCP | 连接外部系统 | GitHub、Sentry、Notion、Figma、数据库 | 本地普通文件规则 |
| Sub-Agent | 隔离支线任务上下文 | 代码搜索、专项审查、并行研究 | 边界很小的一次性修改 |
| Hooks | 固定执行动作 | 禁止危险命令、编辑后格式化、结束前测试 | 仅供参考的建议 |
| 插件 | 打包分发一组扩展 | Skills、MCP、Hooks、脚本的组合 | 没审查过的第三方权限包 |
比如“每次编辑后必须跑 formatter”,写进 CLAUDE.md 只能提醒 Claude 记得,写成 Hook 才能在文件改完后触发。再比如“修 GitHub Issue 的步骤”,放进 CLAUDE.md 会污染所有会话,做成 Skill 更合适。
Code Intelligence:让 Claude 少靠全文搜索硬读
项目能用 Code Intelligence 的话,尽量配上。它相当于给 Claude 接了一套语言服务器:看类型错误、找符号定义、查引用关系,不必每次都靠 rg 搜一大片文件。
拿 Java 或 TypeScript 项目来说,Claude 想知道某个类在哪里定义、被谁调用,不一定非得先搜关键词,再挨个打开文件确认。借助 LSP,它可以直接跳到定义、查看引用,改完代码后还能马上发现类型错误。
它不能替代全文搜索,但能少读很多无关文件。项目一大,上下文会干净不少,Claude 也不容易被一堆候选文件带偏。Claude Code 官方也建议类型化语言安装 Code Intelligence 插件,因为一次符号跳转,往往能省掉一次搜索加多文件读取。
不过,Code Intelligence 插件不是“装上就完事”。它还需要本机有对应的 language server binary,比如 Java 对应 jdtls,TypeScript 对应 typescript-language-server。如果 /plugin 的 Errors 页里出现 Executable not found in $PATH,通常就是这个依赖没装好。
MCP:让 Claude 接上真实世界
MCP(Model Context Protocol,模型上下文协议)管连接外部系统。外部系统提供一个 MCP Server,Claude Code 这类客户端连上来后,就能看到并调用里面的工具。
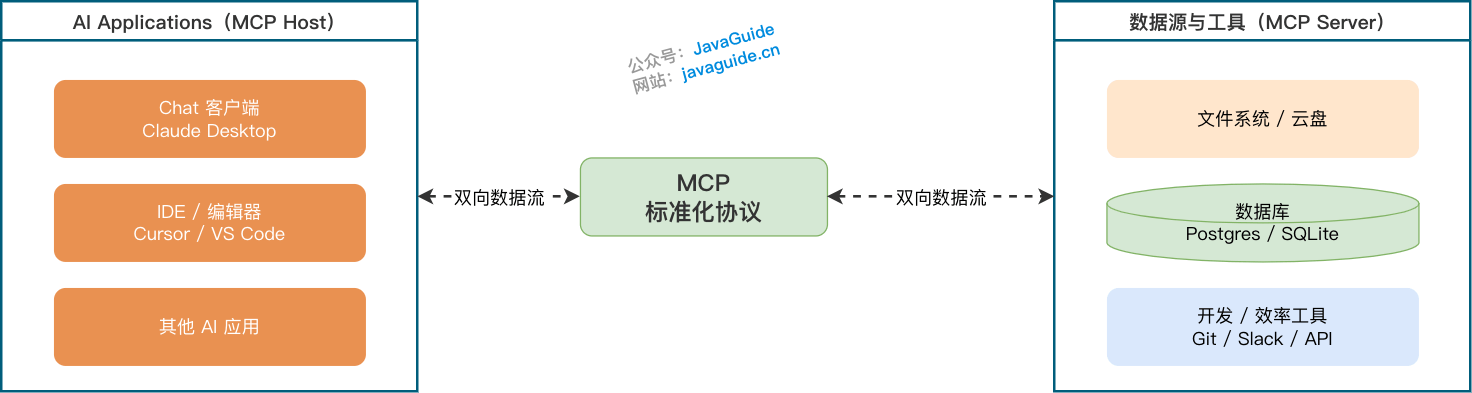
这是 Claude Code 接外部工具的主要方式。查数据库、读 Sentry 报错、访问浏览器、拉 Notion 文档、取 Figma 设计稿,都属于这一类。
添加远程 MCP 服务器的命令大概长这样:
claude mcp add --transport http notion https://mcp.notion.com/mcp \
--header "Authorization: Bearer your-token"这里的 your-token 只是示意。真实项目里尽量别直接把 token 写进 shell history。
团队项目里,能共享的 MCP 配置可以放到 .mcp.json,再提交到仓库。比如某个项目统一要接 Notion、Sentry、内部文档系统,就把 server 名称、URL、transport 这些公共配置沉淀下来。
带 token、密钥、数据库连接串的配置,不要提交到 .mcp.json。更稳的做法是放用户级配置、本地环境变量、密钥管理系统,或者使用对应 MCP server 支持的 OAuth 流程。
MCP Server 要克制。工具越多,Claude 越容易选错,也越难审计。平时可以用 /mcp 看当前连接状态,启用或禁用 server;成本和用量拆分更适合看 /usage,它会展示 skill、subagent、plugin、MCP server 等维度的使用情况。不常用的 server 先断开。
Skills:把重复动作存下来
规则文件和 Skill 不要混着用。
规则文件放长期约束,比如技术栈版本、启动命令、目录结构、错误码格式、哪些文件不能碰。
Skill 放任务步骤,比如代码审查、写测试、改前端页面、网页调研、写技术文章。这些任务每次走法都差不多,不必在聊天里反复提醒。
小 G 之前写过两篇相关的文章:Agent Skills 是什么?和 Prompt、MCP 到底差在哪? 和 AI 编程必备 Skills 推荐。
Skill 就是一份按需加载的任务说明。某类任务怎么做、有哪些约束、要检查哪些点、踩过哪些坑,都写进 SKILL.md。
它和 CLAUDE.md 的一个区别在于加载时机。Claude 默认只看到 Skill 的名称和描述,用来判断是否该调用;调用这个 Skill 时,SKILL.md 正文和相关资源才会进入上下文。用户级 Skill 放在 ~/.claude/skills/,项目级 Skill 放在 .claude/skills/。
还有一个版本变化要注意:Claude Code 里 custom commands 已经合并进 Skills。.claude/commands/deploy.md 和 .claude/skills/deploy/SKILL.md 都能创建 /deploy 这类命令;旧的 .claude/commands/ 还能用,新内容更推荐按 Skill 组织。
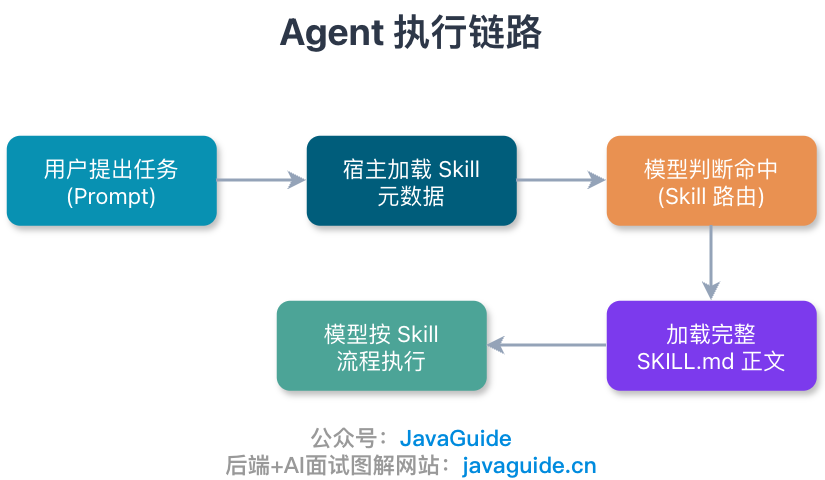
重复性很强的步骤都可以沉淀成 Skill。写功能前固定走 TDD,先写失败测试再实现;代码审查时固定检查安全、事务、性能和边界条件;写技术文章时固定核对事实来源、引用、标题层级和 AI 味。
这比每次在 prompt 里补一长串提醒稳定得多。官方对 Skill 的定义也接近这个意思:一组可复用的指令、脚本和资源,让 Claude 按固定步骤处理某类任务。
现成 Skill 也可以用,比如 Superpowers 把 TDD、Code Review、Spec-Driven、Git Worktree、子 Agent 协作这些步骤封装好了。
我在 AI 编程必备 Skills 推荐:TDD、代码审查与网页自动化实战 这篇文章中有详细推荐。
第三方 Skill 不要拿来就跑。SKILL.md 本身就是指令,里面如果带了危险命令、奇怪脚本、过宽权限,Agent 可能会照着做。装之前至少看一眼正文、scripts/ 和 references/,确认它没有越权操作。
插件:先看官方 marketplace
不想自己从零配 Skills、MCP、Hooks,可以先去 Claude Code 的官方插件市场 claude-plugins-official 翻一翻。
安装也很直接:
/plugin install <name>@claude-plugins-official插件省的是组装时间。一个插件里可能已经打包好了 Skill、MCP Server、Hooks 和一些辅助脚本,装完 Claude 就多了一套现成工作流。
但插件最终还是会在你本地跑,有些还会碰文件系统、浏览器、GitHub、数据库或第三方服务。装之前至少看一眼说明、权限和源码来源;不用了就卸掉,减少不必要的工具入口。具体安装和发现方式可以看官方的 Discover plugins 文档。
Sub-Agent:让主会话保持干净
Sub-Agent 我用得比较多。
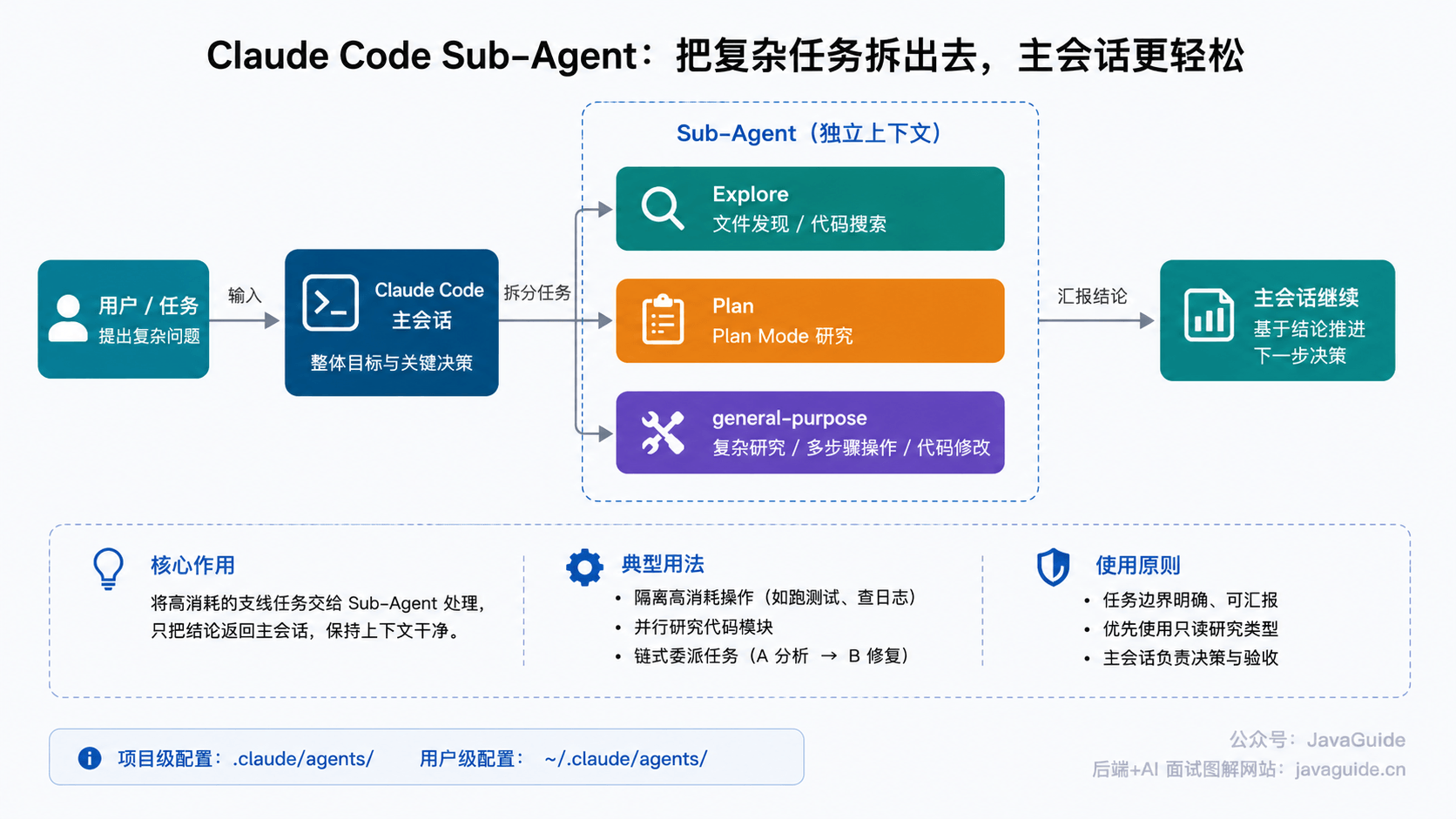
排查复杂问题时,Claude 经常要读几十个文件、搜一堆代码、跑几条命令。主会话很快被日志、搜索结果和文件内容塞满,后面再继续写代码,就容易飘。
这种支线任务可以丢给 Sub-Agent。它有自己的上下文,可以单独读代码、查日志、分析问题,结束后只把结论汇报回主会话。
Claude Code 内置的 subagent 里,我最常见到的是 Explore、Plan 和 general-purpose。这些内置 subagent 都继承父会话权限,但会叠加各自的工具限制:
| 子代理 | 模型 | 工具/权限 | 用途 |
|---|---|---|---|
| Explore | Haiku,偏快速低延迟 | 只读,无 Write / Edit | 文件发现、代码搜索、代码库探索 |
| Plan | 继承主对话模型 | 只读,无 Write / Edit | Plan Mode 下的代码库研究 |
| general-purpose | 继承主对话模型 | 继承主会话可用工具,仍受权限约束 | 复杂研究、多步骤操作、代码修改 |
Explore 和 Plan 更偏只读研究,不负责直接改代码。官方文档里还有个细节:Explore 和 Plan 会跳过 CLAUDE.md 文件和父会话的 git status,所以更适合快速做代码搜索和上下文收集;其他内置 subagent 和自定义 subagent 会加载这些内容。
general-purpose 边界更宽,可能会探索、执行命令、修改代码。用它之前最好明确哪些目录可读、哪些文件不能改、是否允许写入、最终只需要结论还是要直接动手实现。真要做强约束,不能只靠提示词,要配合 subagent 的 tools / disallowedTools、权限模式、permissions.deny 或 Hooks。
你也可以创建自己的 subagent。项目级配置放在 .claude/agents/,给团队共享;用户级配置放在 ~/.claude/agents/,自己跨项目复用。每个 subagent 都可以配置系统提示词、工具权限、模型,以及触发条件。
我比较常用的场景是让 subagent 跑测试套件,只把失败用例和错误信息带回来;或者让不同 subagent 分别研究认证、数据库、API 模块,最后把结论合并到主会话。更复杂的任务,也可以先让 code-reviewer subagent 找性能问题,再让 optimizer subagent 尝试修复。
任务太小、边界不清、代码还在剧烈变化时,不一定要拆 subagent。主会话保留目标、决策和验收,subagent 只处理局部、明确、能汇报结果的专项任务。
后续用到 Agent teams 时,可以把它看成多会话协作的玩法。Sub-Agent 用来隔离支线任务,Agent teams 用来让多个独立会话围绕共享任务协作。刚上手不用急,先把 Worktree、小步提交和验证节奏跑顺。
一个自定义安全审查子代理可以这么写:
---
name: security-reviewer
description: Reviews Java and Spring Boot code for security risks.
tools: Read, Grep, Glob, Bash
model: opus
---
Review the target diff for:
- SQL injection and unsafe dynamic queries.
- Authentication and authorization bypass.
- Secrets or credentials committed to code.
- Unsafe deserialization or command execution.
Return concrete file and line references. Do not rewrite code unless explicitly asked.实际项目里,subagent 的 tools 尽量收窄。如果只做代码审查,通常不需要 Edit / Write。同时设置 tools 和 disallowedTools 时,disallowedTools 会先应用;同一个工具同时出现在两边,最后会被移除。
Hooks:处理必须执行的规则
Hooks 很容易被忽略,但真实项目里很有用。它能在 Claude Code 的生命周期节点上执行动作,比如工具调用前、文件编辑后、会话结束前、上下文压缩前后。
举个例子,假设 Claude Code 准备执行:
rm -rf /tmp/buildPreToolUse Hook 会先拿到这次 Bash 调用,判断它是否危险;命中规则后返回 deny,Claude Code 会取消这次工具调用,并把拒绝原因反馈给 Claude。
下面这张图来自 Claude Code 官方 Hooks 文档,展示的就是这条链路。

我会把几类动作交给 Hook:编辑后自动格式化,会话结束前跑测试,禁止改 migrations/ 或 .github/workflows/,拦截 curl | bash、rm -rf、向外部端点发送敏感内容,或者在 Sub-Agent 启动时注入额外上下文。
需要固定执行的动作适合放进 Hook;只作为背景参考的内容,再写进 CLAUDE.md。
如果写的是 HTTP Hook,还要注意一个坑:不能靠返回 4xx / 5xx 阻断工具调用。HTTP Hook 的非 2xx、连接失败和超时都会被当成非阻塞错误,执行会继续。要拦住工具调用,需要返回 2xx,并在 JSON 里写 decision: "block",或者在 hookSpecificOutput 里写 permissionDecision: "deny"。
最常用的工作流
探索、计划、执行、验证
复杂任务别一上来就让 Claude 写代码。先让它读仓库,暂时不要修改文件:
进入 plan mode。先阅读 src/auth 和相关测试,搞清楚登录态刷新链路。
不要写代码,只汇报当前链路、相关文件和可能的修改点。读完以后再让它给计划:
我要修复用户 session 超时后刷新 token 失败的问题。
基于刚才的阅读,列出要改的文件、测试策略和风险点。你确认计划后再执行:
按这个计划实现。优先补一个能复现问题的测试,再改实现。
完成后运行相关测试,把命令和结果贴出来。这个节奏前面会慢一点,但后面省返工。尤其是你不熟悉代码库,或者改动跨多个模块时,先让 Claude 把调用链、风险点和测试策略说清楚,后面少很多“改完才发现方向错了”的尴尬。
小改动可以跳过计划。比如改一个文案、加一条日志、补一个一眼能看出来的空指针判断,直接让它做就行。过度规划也会浪费上下文。
TDD 测试驱动开发
AI 写代码最麻烦的地方在于,它很会写“看起来合理”的代码。TDD 能先把预期行为钉住,再让实现往测试上靠。
提示词不用绕:
先不要改实现。为 TokenRefreshService 写一个失败测试,
覆盖 session 已过期但 refresh token 仍有效的场景。
测试失败后再修改实现,直到测试通过。如果测试没有先失败过,就很难确认后面的实现到底修到了哪个问题。否则它可能直接改一堆代码,然后告诉你“已修复”。
AI 编程必备 Skills 推荐中推荐的 Superpowers 就把 TDD 给封装好了。
让 Claude 自己验证
Anthropic 官方最佳实践里有一句我很认同:给 Claude 一个能运行的检查。测试、build、lint、截图对比、脚本输出都可以。
比如别只说:
写一个邮箱校验函数。写成下面这样会少很多猜测:
写一个邮箱校验函数。测试用例:
- hello@gmail.com 应该通过
- hello@ 应该失败
- @domain.com 应该失败
- a@b.co 应该通过
写完后运行测试,把命令和结果贴出来。验收标准越具体,Claude 越不容易停在“看起来完成了”。
如果任务会跑很久,可以再加一句“最多尝试 3 轮,仍失败就停下来汇报阻塞点”,避免它在错误方向上消耗太多 Token。
代码库问答
接手陌生项目时,我会先把 Claude Code 当临时向导用。别急着让它改文件,先问调用链:
用户登录的完整链路是什么?从 HTTP 请求进来到 session 写入为止,
列出相关类和方法,不要修改文件。或者:
这个项目里订单状态机在哪里定义?每个状态之间怎么流转?
如果有隐式约束,也一起指出来。但它总结出来的内容仍然要抽查。跨服务调用、配置开关、历史兼容逻辑这几类地方,最容易被它说得很顺,实际漏掉一条分支。
Bug 修复需要提供错误信息
修 Bug 时最怕只丢一句:
登录有 bug,帮我修一下。这基本是在让 Claude 猜。把原始材料贴上去会稳很多:
下面是线上报错日志、复现步骤和相关请求参数。
请先定位可能原因,不要马上改代码。
找到根因后,补一个能复现的测试,再修复。日志、堆栈、Slack 讨论、Docker 输出、失败测试结果,都比你转述“好像是缓存问题”更有用。转述越多,Claude 越容易被你的猜测带偏。
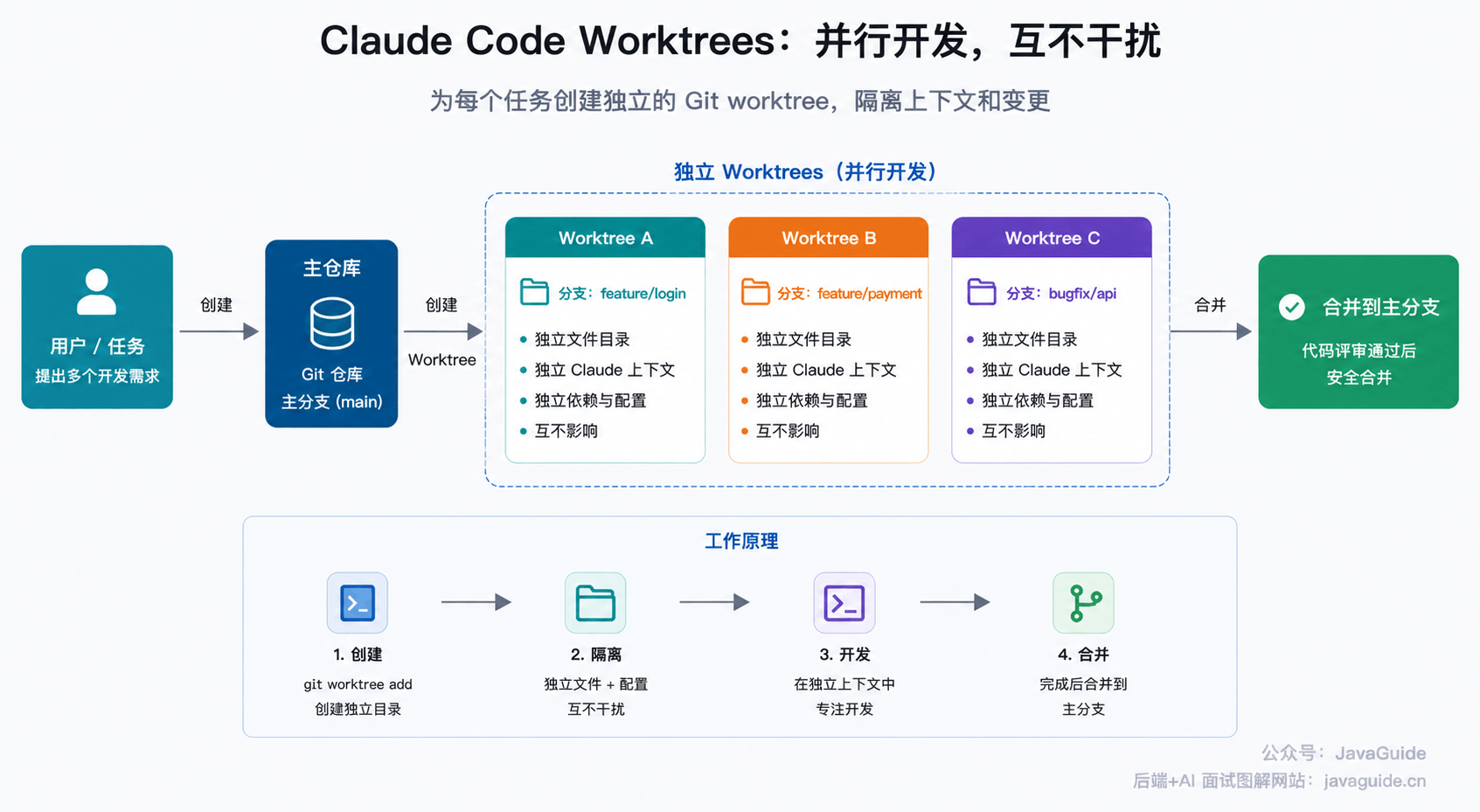
多实例和 Worktree
不要让一个 Claude 做所有事。互相独立的任务,可以拆到不同会话里并行跑。
Claude Code 支持用 Git Worktree 隔离不同会话:
claude --worktree feature-auth
claude --worktree bugfix-payment--worktree 是 Claude Code 官方支持的参数,会在仓库下创建隔离 worktree 并启动会话;默认目录在 .claude/worktrees/<name>/,分支名通常是 worktree-<name>。如果你想完全自己控制目录和分支,也可以先用 Git 原生命令创建:
git worktree add ../project-auth -b feature-auth
cd ../project-auth
claude每个 Worktree 有独立目录和分支。一个会话改认证模块,另一个会话修支付 bug,文件不会互相踩。官方桌面应用也会为新会话自动创建 Worktree,这个方向和 CLI 是一致的。
如果你已经有多个后台会话,可以用:
claude agentsAgent View 会把后台 session 放在一个界面里,看哪些在运行、哪些需要你确认、哪些已经完成。多会话用久了以后,比开一排终端窗口清爽很多。
这里有个容易踩的点:后台会话在动手改文件前,会自动把自己挪进 .claude/worktrees/ 下的独立 worktree,避免几个会话踩同一份工作区。但如果项目带大量生成产物,或者 pre-commit hook 很挑路径,反复隔离反而成了负担。这种情况可以在 .claude/settings.json 里把 worktree.bgIsolation 设成 "none"(需要 v2.1.143+),让后台会话直接改工作区。代价也摆在那儿:并发会话有概率互相踩,按项目情况权衡。
如果你用了 .worktreeinclude 把 .env、.env.local、config/secrets.json 这类 gitignore 文件复制到新 worktree,一定要确认里面只是本地开发凭据,不是生产凭据。Worktree 隔离的是文件改动,不等于隔离密钥风险。
Commit 和 PR 别一次塞太大
不要让 Claude 一次性提交一大坨改动。
我倾向于把它拆成小步提交。一个 commit 只做一件事,提交前让 Claude 给出 diff 摘要、验证命令和剩余风险,自己再过一遍 git diff --stat 和重点文件的 git diff。
Claude 写 commit message 和 PR 描述很快,但最后别只看它的总结。它说“只改了认证逻辑”,不如你自己看一眼 diff 可信。PR 描述写清三件事就够了:改了什么、怎么测的、还有哪些地方没完全兜住。
常用命令
命令不用背,真用的时候打 / 翻一下就行。我平时按两类记。
第一类是基础命令。/help 看当前环境到底有哪些命令;/diff 看 Claude 改了哪些文件、哪些行;长任务变慢、变飘时,先看 /context,上下文太满再用 /compact;权限相关看 /permissions,记忆和规则加载情况看 /memory,MCP 连接看 /mcp,用量拆分看 /usage。
第二类是 bundled skills / workflow 相关命令。/code-review 用来扫当前改动里的 correctness bug、边界条件和潜在风险,可以指定 effort,比如 /code-review high;加 --comment 可以把发现发成 GitHub PR 行内评论;加 --fix 会把 review findings 应用到工作区。
/simplify 当前更适合当成 cleanup-only review,用来处理复用、简化、效率这类清理项,并自动应用修复。它不是完整的 bug-hunting review。老版本里 /simplify 和 /code-review --fix 的关系变过,如果你看到的命令行为和本文不一致,优先看当前 /help 和官方 commands 文档。
/batch 用在边界清晰的多模块大改上,会把需求拆成多个工作单元,开后台 Worker 在隔离 worktree 里并行干。/loop 可以定时跑任务,也可以围绕一个目标反复执行、验证、修正,跑之前最好写清停止条件,比如最多尝试 5 次。/run 用来把应用启动起来,看改动是否生效;/verify 更轻,主要做 build 和运行验证,快速确认有没有编译或运行时问题。
这些命令和 bundled skills 迭代很快,不同版本、平台和套餐看到的列表可能不一样。写文章可以介绍经验,真到自己机器上用,还是先看 /help 和官方 commands 文档。某个版本里的行为不一定长期保持不变。
/compact 还有一个容易忽略的点:压缩之后,有些规则不会立刻回到上下文里。根目录的 CLAUDE.md 会重新注入,但子目录里的嵌套规则不一定马上回来。长任务压缩后,最好让 Claude 先复述一遍当前目标、已改文件、剩余风险和下一步验证命令,再继续往下跑。
命令细节我在 Claude Code 核心命令详解:simplify、code-review、loop、batch、run、verify 这篇里展开写过,这里就不重复铺太长了。
提示词怎么写
英文和中文各用在合适位置
编程任务里,英文通常稳一些。我不会把这件事上升成“中文不行”,只是代码、库名、错误信息、API 文档本来就大量使用英文。像 modal、debounce、retry policy、transaction boundary 这类词,硬翻成中文反而容易变味。
但业务背景、产品规则、中文文案,当然还是中文更准。我的习惯是:代码动作、技术约束和术语尽量用英文;业务语义、验收标准和中文文案用中文讲清楚。
限制范围
还要小心一句话:“调查一下这个项目”。Claude 会很认真地到处搜文件,读着读着,上下文就被填满了。
可以这样写:
只调查 src/payment 和 src/order 目录。
目标是确认订单支付成功后库存扣减在哪里触发。
不要修改文件,只列出调用链和相关类。范围、目标、禁止动作写清楚后,它搜索文件和修改代码的范围会收窄很多。
给金标准范例
让 Claude 按项目风格写代码,别只说“参考最佳实践”。这个范围太宽,它很容易写出一套看起来不错、但和你项目完全不搭的东西。
给它一份现有样板,效果通常更好:
阅读 UserController.java、UserService.java 和 UserDTO.java。
参考它们的分层方式、构造器注入、Result<T> 返回格式和异常处理。
为订单查询补一个 OrderController,不要引入新的返回结构。项目里的既有风格,往往比外面那套“最佳实践”更有约束力。尤其是老项目,分层、返回结构、异常处理、日志格式,很多都带着历史包袱和团队习惯。让 Claude 先读样板,再让它照着补,输出会更贴近当前仓库。
前端别只说“做得好看”
如果让 Claude 写前端,别只说“现代、简洁、高级”。
这类词太空,最后很容易得到一套熟悉的组合:Inter 字体、紫色渐变、大圆角卡片、满屏营销页味道。后台系统尤其容易翻车,本来是给运营同学高频使用的页面,结果做成了产品官网。
我一般会写得更硬一点:
使用现有 Ant Design 组件,不新增 UI 库。
页面是后台运营工具,信息密度优先,不要营销页风格。
主色沿用项目 CSS 变量,不要新增紫色渐变背景。
参考 src/pages/UserList.tsx 的筛选区和表格布局。设计规范也可以做成 Skill,让 Claude 每次写前端前先读项目视觉约束。先把不该出现的套路挡住。后台工具就按后台工具来,信息密度、可扫描性、操作反馈,比“氛围感”重要得多。
AI 编程必备 Skills 推荐中也有推荐前端相关的开源 Skills。
常见失败模式
我自己踩得最多的是会话太杂。一个会话里同时聊需求、排错、重构、发版,Claude 很快就开始带着前一个话题的惯性做下一个任务。切任务时直接 /clear,必要时写一份 HANDOFF.md,不要硬撑着同一个上下文继续聊。
第二种是纠正死循环。同一处错误纠正 3 次还不对,就别继续在原上下文里磨了。停下来,重新写起始 prompt,把目标、证据和禁止动作说清楚。
CLAUDE.md 膨胀也很常见。规则很多,Claude 反而不遵守,这时不要继续加规则,先删掉代码里能读出来的内容,只保留真实犯错后总结出的约束。
还有一种是无边界调查。让 Claude “看一下这个项目”,它可能一次读几百个文件,上下文很快耗尽。限定目录、目标和禁止动作,或者交给 Sub-Agent。
测试全绿也不代表行为正确。让 Claude 展示证据,对比 main 和 feature 分支,该看日志就看日志,该跑手工验证就跑手工验证。
权限过宽最危险。为了省确认直接 bypass,后面排查误操作会很麻烦。allow/deny、Auto Mode、容器隔离、临时凭据,尽量按风险分层配置。
总结
一开始很容易只盯着“让它多写点代码”。用久了会发现,影响结果的反而是那些很普通的工程习惯:CLAUDE.md 写清项目规矩,复杂任务先 plan,改动后必须 verify,长调查丢给 Sub-Agent,多任务用 Worktree 隔离,权限别一次放太开。
实际项目里,可以先从一个目录、一个模块、一条可验证的任务链开始,让 Claude 在小范围内稳定完成任务,再逐步增加任务复杂度。